关系型数据库和非关系型数据库特点对比
关系型数据库
1.二维表
2.Oracle传统企业,MySQL互联网企业
3.数据存取是通过SQL(Structured Query Language结构化查询语言)
4.最大特点数据安全性方面强(ACID)
非关系型数据库
不是否定关系型数据库,而是做关系型数据库的补充。
Oracle典型版本
| 大版本 | 经典版本号 |
|---|---|
| 7 | 7.3.4 |
| 8i(internet) | 8.1.7 |
| 9i | 9.2.0.8 |
| 10g(grid) | 10.2.0.4 |
| 11g | 11.2.0.3、11.2.0.4 |
| 12c(cloud) | None |
| 18c | None |
MySQL客户端与服务器模型
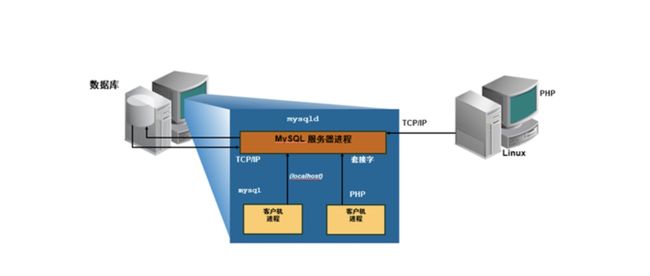
C/S结构的服务
client server
MySQL客户端:
1.mysql
2.mysqldump
3.mysqladmin
第三方:
navicat
sqlyog
phpmyadmin
MySQL的连接方式
1.TCP/IP
mysql -uroot -p123 -h10.0.0.52
2.Socket
mysql -uroot -p123 -S /tmp/mysql.sock
问题:
* mysql -uroot -p123
* socket
* mysql -uroot -p123 -h127.0.0.1
* TCP
* mysql -uroot -p123 -hlocalhost
* socket
* mysql -uroot -p123 -h127.0.0.1 -S /tmp/mysql.sock
* TCP
总结:
1.-h不一定都是tcp连接
2.MySQL默认使用socket连接
3.-S只允许本地连接,无法远程连接
4.tcp连接需要建立3次握手,所以MySQL默认使用socket(速度快)
MySQL服务器构成
什么是实例?
**一个进程+多个线程+与分配的内存结构**
MySQL的程序结构mysqld
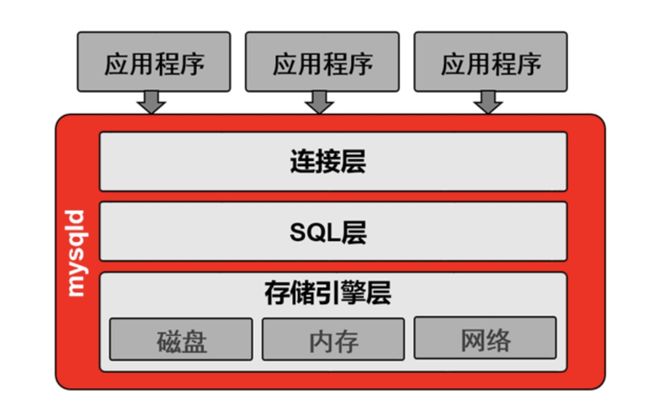
img
连接层
1.验证用户的合法性(用户名,密码,主机域)
2.提供了两种连接方式(TCP/IP Socket)
3.建立一个与SQL层连接的线程
SQL层
1.接收连接层传来的SQL语句
2.检测语法
3.检测语义(DDL,DML,DQL,DCL),检测是show还是select?还是update?还是insert?
4.解析器,解析整条SQL语句,生成多种执行计划
5.优化器,选择解析器生成的多种执行计划中,效率最高的一种
6.执行器,将优化器,优化的最优的一种执行方式,执行
* 和存储引擎层建立连接(提供一个线程)
* 接收存储引擎层传来的结构化成表的数据
7.写缓存
8.记录日志(binlog)
存储引擎层
1.接收SQL层传来的SQL语句
2.与磁盘交互,读取数据并结构化成表,返回给SQL层
3.建立一个与SQL层连接的线程
MySQL的结构
1.逻辑结构
数据库管理员,操作的对象
* 库
* 表:(真实数据+元数据)
* 元数据:列+其他属性(大小,行数...)
* 列:列名+(数据类型+约束(非空,默认值,主键,非负...))
2.物理结构
MySQL的物理结构,是最底层的数据文件
| MySQL | Linux |
|---|---|
| show databases; | ls -l / |
| show tables; | ls |
| use db | cd / |
| drop database | rm -fr |
| drop table | rm -f |
| create database | mkdir |
库名,表名,一律小写
create database ZLS;
create database zls;
insert into ZLS.ZLS1 values(1);
insert into zls.zls1 values(1);
MySQL单位
* 段:是由多个区组成的,一张表就是一个段
* 区:是由64个页组成的,一个区:1M=1024K
* 页(块):16k为一页
分区表:是由一个区构成一个段也就是一个表的表.
只要我有,从搭建数据库开始到现在,所有的binlog日志,那么我可以将MySQL的数据恢复到任意时刻.