学习R包
1.需要了解的知识
1.1iris指内置数据集
1.2 one_of()是用来声明选择对象的。比如one_of("x","y")就是表明选择x,y变量
1.3 stringsAsFactors = F意味着,“在读入数据时,遇到字符串之后,不将其转换为factors,仍然保留为字符串格式”。
1.4 cbind函数/横向追加
例如:ID<-c(1,2,3,4)
name<-c("A","B","C","D")
score<-c(60,70,80,90)
sex<-c("M","F","M","M")
student1<-data.frame(ID,name)
student2<-data.frame(score,sex)
total_student2<-cbind(student1,student2)
total_student2
当我们需要将不同的观测对象,相同的观测变量合并时,则采用rbind,也就是合并row。
1.5 rbind函数/纵向追加
例如:ID<-c(1,2,3,4)
name<-c("A","B","C","D")
student1<-data.frame(ID,name)
ID<-c(5,6,7,8)
name<-c("E","F","G","H")
student2<-data.frame(ID,name)
total_student3<-rbind(student1,student2)
total_student3
1.6 merge函数
两个数据框拥有相同的时间或观测值,但这些列却不尽相同。处理的办法就是使用
merge(x, y ,by.x = ,by.y = ,all = ) 函数。
例如:#merge/合并
ID<-c(1,2,3,4)
name<-c("A","B","C","D")
score<-c(60,70,80,90)
student1<-data.frame(ID,name)
student2<-data.frame(ID,score)
total_student1<-merge(student1,student2,by="ID")
total_student1
1.7 %in%筛选
2 dplyr五个基础函数
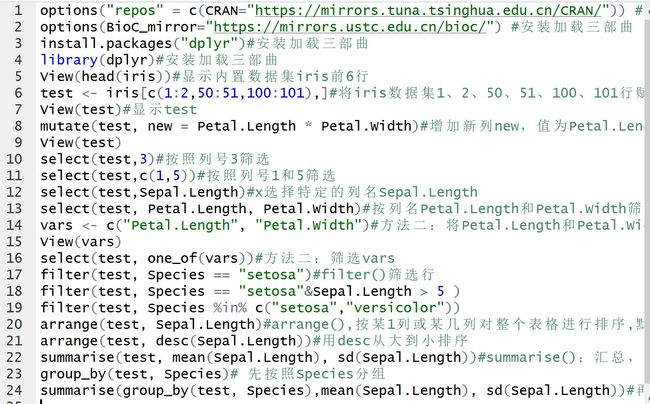
2.1 mutate(),新增列
mutate(test, new = Sepal.Length * Sepal.Width)
2.2 select(),按列筛选
select(test,1)
select(test,c(1,5))
select(test,Sepal.Length)
2.3 按列名筛选
select(test, Petal.Length, Petal.Width)
vars <- c("Petal.Length", "Petal.Width") select(test, one_of(vars))
2.4 filter()筛选行
filter(test, Species == "setosa")
filter(test, Species == "setosa"&Sepal.Length > 5 )
filter(test, Species %in% c("setosa","versicolor"))
2.5 arrange(),按某1列或某几列对整个表格进行排序
arrange(test, Sepal.Length)#默认从小到大排序
arrange(test, desc(Sepal.Length))#用desc从大到小
2.6 summarise():汇总
summarise(test, mean(Sepal.Length), sd(Sepal.Length))# 计算Sepal.Length的平均值和标准差
group_by(test, Species) summarise(group_by(test, Species),mean(Sepal.Length), sd(Sepal.Length))# 先按照Species分组,计算每组Sepal.Length的平均值和标准差
3 dplyr两个实用技能
3.1 管道操作 %>% (cmd/ctr + shift + M)
test %>%
group_by(Species) %>%
summarise(mean(Sepal.Length), sd(Sepal.Length))
3.2 count统计某列的unique值
count(test,Species)
4 dplyr处理关系数据
4.1內连inner_join,取交集
inner_join(test1, test2, by = "x")
4.2 左连left_join
left_join(test1, test2, by = 'x')
4.3 全连full_join
full_join( test1, test2, by = 'x')
4.4 半连接:返回能够与y表匹配的x表所有记录semi_join
semi_join(x = test1, y = test2, by = 'x')
4.5 反连接:返回无法与y表匹配的x表的所记录anti_join
anti_join(x = test2, y = test1, by = 'x')
4.6 简单合并
bind_rows(test1, test2)
bind_cols(test1, test3)