TangYuan之Ognl设计
前言:
本文中的内容需要读者对tangyuan框架和XCO对象有一定的了解和使用经验。如果您对此不太了解,可阅读下面两篇文件
通用数据对象XCO:https://my.oschina.net/xson/blog/746071
使用教程和技术设计:http://www.jianshu.com/p/ed92f6adca38
1. 引子
在tangyuan的使用过程中我们经常看到下面的场景:
select * from user where user_id = #{user_id}
其中#{user_id}是一个SQL占位变量,程序执行的时候,tangyuan将从用户请求参数中取出"user_id"所代表的真实值,替换或处理此处文本,组成正在需要执行的SQL语句,在这个过程中,tangyuan做了下面几件事情:
-
- 占位变量的解析
-
- 存储解析后的占位变量
-
- 根据占位变量取值
-
- 取到值后的处理
看到这里也许有些朋友会有疑问,我们用正则表达式直接截取user_id,然后取值替换不就可以了吗?也许上面的示例比较简单,如果是下面这些场景呢?
1. #{user_id}
2. #{user.user_id}
3. #{userList[0].user_id}
4. #{create_time|now()}
5. #{create_time|null}
6. #{user_id|0}
7. #{user_name|''}
8. #{x{xxx}x}
9. #{user{x{xxx}x}Name{xxx}}
10. #{money + 100}
11. #{money * 100}
12. #{'ST' + sn}
13. #{type + '-' + sn}
14. #{@function(ccc, 's', 0L)}
15. {DT:table, user_id}
16. {DI:table, user_sn}
17. ${xxxx}
看到这些使用场景,是不是感觉问题一下子变得复杂了,下面我们来看一下Tangyuan是如何来处理这些问题的。
2. 变量的存储和表示
对于上面众多复杂的场景,我们不能再用一些简单直接手段处理了,而需要一套统一的处理思路和方法来解决上面的问题。首先我们把上面的场景分一下类:
[1]: 简单的占位变量
[2-3]: 有层级关系的占位变量
[4-7]: 带有默认值的占位变量
[8-9]: 嵌套的占位变量
[10-13]: 带有运算表达式的占位变量
[14]: 含有方法调用的占位变量
[15-16]: 涉及分库分表的占位变量
[17]: 直接替换的占位变量
有了这些分类,我们就可以考虑如何描述或者说在Java中如何定义这些占位变量,应为这要涉及到后续的解析、取值以及使用,这是最重要的一步,如同定义数据结构一样。下面我们看看tangyuan中是如何定义他们的:
图片1:
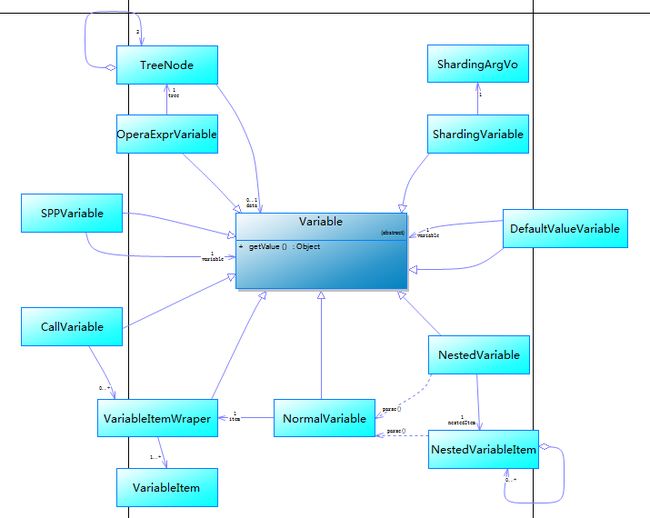
说明:
Variable 占位变量的基类
NormalVariable 普通占位变量,对应[1-3]
VariableItemWraper 占位变量单元包装类
VariableItem 占位变量最小单元
DefaultValueVariable 带有默认值的占位变量
NestedVariable 嵌套的占位变量
NestedVariableItem 嵌套占位变量单元
CallVariable 方法调用的占位变量
OperaExprVariable 带有运算表达式的占位变量
TreeNode 运算表达式的树节点
ShardingVariable 涉及分库分表的占位变量
SPPVariable SQL占位参数变量
图1中描述了tangyuan中变量的类关系模型,熟悉设计模式的读者已经看出来了,这里使用了装配模式,所有功能性的变量类都实现了Variable基类,如:DefaultValueVariable,NestedVariable等,内部持有一个具体的实现类。
下面我们从VariableItem说起。VariableItem是Tangyuan中占位变量的最小单元的描述。定义如下:
public class VariableItem {
// 属性表达式类型
public enum VariableItemType {
// 属性
PROPERTY,
// 索引
INDEX,
// 变量:有可能是属性, 有可能是索引. 需要看所属的对象类型, 主要针对于括号中的
VAR
}
// 此属性的类型
private VariableItemType type;
// 属性名称
private String name;
//索引
private int index;
......
}
场景1中#{user_id},我们就可以用一个VariableItem类来描述,如下:
new VariableItem(){
name: "user_id"
type: PROPERTY
}
由于VariableItem只是一个最小的描述单元,我们需要使用一个Variable的实现类来对其做一个封装,这里用到了VariableItemWraper类:定义如下:
public class VariableItemWraper extends Variable {
private VariableItem item = null;
private List itemList = null;
......
}
VariableItemWraper类中,item表示一个简单的占位变量,itemList表示有层级关系的占位变量,二者只会使用其一;针对#{user_id},我们就可以这样封装一下:
new VariableItemWraper(){
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
这样就是#{user_id}的完整描述吗,还不是,我们还需要用NormalVariable来进行一次封装,这是从功能角度考虑,用于区分比如带有默认值的占位变量、嵌套占位变量等。
NormalVariable类:
public class NormalVariable extends Variable {
private VariableItemWraper item;
....
}
利用NormalVariable我们再次进行封装:
new NormalVariable(){
item = new VariableItemWraper(){
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
}
最后用到了SPPVariable类,SPPVariable类本身表示此处占位变量为SQL占位参数变量,将用做PreparedStatement中参数占位符,定义如下:
public class SPPVariable extends Variable {
private Variable variable;
public SPPVariable(String original, Variable variable) {
this.original = original;
this.variable = variable;
}
@Override
public Object getValue(Object arg) {
return this.variable.getValue(arg);
}
}
利用SPPVariable我们进行最后的封装:
new SPPVariable(){
variable = new NormalVariable(){
item = new VariableItemWraper(){
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
}
}
到此,才是场景1中#{user_id}的完整描述。看到这里,有些读者会有疑问,需要这么复杂吗?其实,复杂不是目的,我们为是能通过这种设计来兼容和实现上述所有的场景功能。我们可以再看几个场景的描述:
比如场景2中#{user.user_id}的完整描述是这样:
new SPPVariable(){
variable = new NormalVariable(){
item = new VariableItemWraper(){
itemList = [
new VariableItem(){
name: "user"
type: PROPERTY
},
new VariableItem(){
name: "user_id"
type: PROPERTY
}
]
}
}
}
场景4中#{create_time|now()}的完整描述:
new SPPVariable(){
variable = new DefaultValueVariable(){
item = new VariableItemWraper(){
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
}
}
场景4使用到DefaultValueVariable类,其定义如下:
public class DefaultValueVariable extends Variable {
private Variable variable;
// 属性的默认值 #{abccc|0, null, 'xxx', now(), date(), time()}
private Object defaultValue = null;
// 默认值类型: 0:普通, 1:now(), 2:date(), 3:time()
private int defaultValueType = 0;
...
}
比如场景17中${xxxx}的完整描述:
new NormalVariable(){
item = new VariableItemWraper(){
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
}
场景17 ${xxxx}为直接替换的占位变量,所以不需要使用SPPVariable来分封装,只需要三层即可。
通过上述的几个场景分析,大家可以看到Tangyuan就是通过这种层次化和功能化相结合的方式对占位变量进行描述的。
3. 变量的解析
第二节我们对占位变量进行抽象的定义的描述,有了这个基础,这节中我们将探讨一下Tangyuan是否如何将文本字符串解析成变量对象的。
图片2:
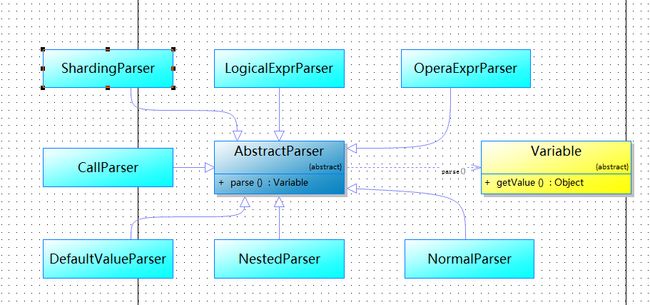
AbstractParser: 解析基类
NormalParser: 普通变量解析类
DefaultValueParser: 默认值变量解析类
NestedParser: 嵌套变量解析类
CallParser: 方法调用变量解析类
LogicalExprParser: 逻辑表达式变量解析类
OperaExprParser: 运算表达式变量解析类
ShardingParser: 分库分表变量解析类
上图中展示的解析器的类关系模型,我们可以看到,所有的解析类都实现了AbstractParser基类,parse方法返回的是一个具体的Variable类。接下来我们那一个具体的场景来分析一下,Tangyuan是如何将一个文本字符串解析成一个Variable变量的。我们以场景3中的#{userList[0].user_id}为例:
解析场景#{userList[0].user_id}设计到的解析器是NormalParser,其核心代码如下:
private List parseProperty0(String text) {
List list = new ArrayList();
int srcLength = text.length();
StringBuilder builder = new StringBuilder();
boolean isInternalProperty = false; // 是否进入内部属性采集
for (int i = 0; i < srcLength; i++) {
char key = text.charAt(i);
switch (key) {
case '.': // 前面采集告一段落
if (builder.length() > 0) {
list.add(getItemUnit(builder, isInternalProperty));
builder = new StringBuilder();
}
break;
case '[': // 进入括弧模式
if (builder.length() > 0) {
list.add(getItemUnit(builder, isInternalProperty));
builder = new StringBuilder();
}
isInternalProperty = true;
break;
case ']':
if (builder.length() > 0) {
list.add(getItemUnit(builder, isInternalProperty));
builder = new StringBuilder();
}
isInternalProperty = false;
break; // 退出括弧模式
default:
builder.append(key);
}
}
if (builder.length() > 0) {
list.add(getItemUnit(builder, isInternalProperty));
}
return list;
}
这段代码的主要工作就扫描文本字符串,根据既定的标记,将其解析成VariableItem类,我们看一下其解析流程:
图3
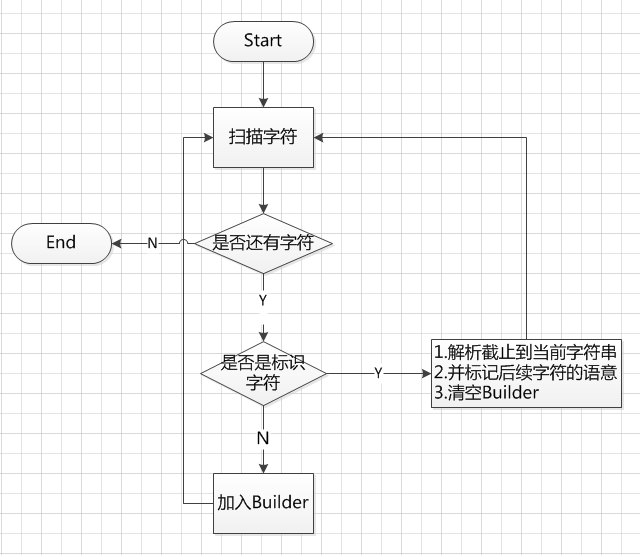
通过上述解析流程我们将#{userList[0].user_id}解析成下面的结构:
new VariableItemWraper(){
item = new VariableItem(){
name: "userList"
type: PROPERTY
}
item = new VariableItem(){
name: 0
type: INDEX
}
item = new VariableItem(){
name: "user_id"
type: PROPERTY
}
}
NormalParser只是负责将字符串解析成VariableItemWraper,而我们最终需要的是将#{userList[0].user_id}解析成SPPVariable,而这个工作是由解析封装系现实现。下面我们来看看其设计和实现。
图4
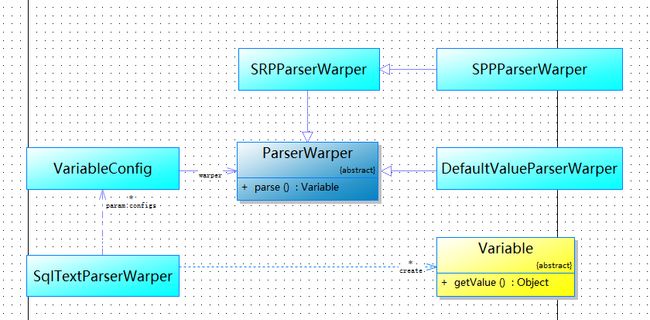
ParserWarper: 解析封装类基类
SRPParserWarper: SQL ${} 变量解析封装类
SPPParserWarper: SQL #{} 变量解析封装类
DefaultValueParserWarper: 默认值变量解析封装类
VariableConfig: 变量解析配置类
SqlTextParserWarper: SQL文本解析入口类
完整的解析流程是通过入口类SqlTextParserWarper,设置解析参数和具体功能解析封装类SPPParserWarper,最后返回解析后结果SPPVariable。下面是部分实现代码:
调用入口:
VariableConfig[] configs = new VariableConfig[7];
configs[6] = new VariableConfig("#{", "}", true, new SPPParserWarper());
List解析过程中(调用parseVariable方法):
public class SRPParserWarper extends ParserWarper {
protected NestedParser nestedParser = new NestedParser();
public NestedParser getNestedParser() {
return this.nestedParser;
}
protected Variable parseVariable(String text, VariableConfig config) {
text = text.trim();
// 嵌套
if (config.isExistNested()) {
config.setExistNested(false);
return nestedParser.parse(text);
}
// 是否是调用表达式
CallParser callParser = new CallParser();
if (callParser.check(text)) {
return callParser.parse(text);
}
// 是否是运算表达式, 只包含[+,-,*,/,%]
OperaExprParser exprParser = new OperaExprParser();
if (exprParser.check(text)) {
return exprParser.parse(text);
}
DefaultValueParser defaultValueParser = new DefaultValueParser();
if (defaultValueParser.check(text)) {
return defaultValueParser.parse(text);
}
// 普通变量
return new NormalParser().parse(text);
}
}
最后的封装:
public class SPPParserWarper extends SRPParserWarper {
@Override
public Variable parse(String text, VariableConfig config) {
return new SPPVariable(text, parseVariable(text, config));
}
}
通过上述执行流程,我们得到最终希望的SPPVariable实例,也就是#{userList[0].user_id}的描述。
4. 变量的取值
有了占位变量的定义和相应的解析器以及解析封装器,变量的取值的工作就相对简单了。我们还是那#{userList[0].user_id}这个场景来分析,在第3节中,我们最后得到是一个SPPVariable实例,那我们该如何取值呢?回顾一下之前的内容,所有的占位变量示例都实现了Variable基类,而Variable类中:
abstract public Object getValue(Object arg);
此方法就是我们取值的入口方法,为什么说是入口方法呢?因为其真正的取值操作是通过Ognl类来实现的,具体的代码如下:
public class Ognl {
public static Object getValue(Object container, VariableItemWraper varVo) {
if (null == container) {
return null;
}
if (XCO.class == container.getClass()) {
return OgnlXCO.getValue((XCO) container, varVo);
} else if (Map.class.isAssignableFrom(container.getClass())) {
return OgnlMap.getValue((Map) container, varVo);
} else {
throw new OgnlException("Ognl.getValue不支持的类型:" + container.getClass());
}
}
}
5. 变量的后续处理
到此,本文的内容基本要结束了,最后说一下变量的后续处理。所谓后续处理,是根据返回的Variable实例类型作不同的操作,比如:如果返回的是SPPVariable类型,Tangyuan则将通过SPPVariable实例取到的变量值整理后传给PreparedStatement;如果返回的是ShardingVariable类型,Tangyuan则会根据变量值作一些和分库分表有关的操作,等等。
- QQ群:518522232 *请备注关注的项目
- 邮箱:[email protected]
- 项目地址: https://github.com/xsonorg/tangyuan