tags:
- MovieLens 1M数据集
- 计算评分分歧
*更新了书中淘汰的方法
MovieLens 1M数据集
将常规分隔文件读入DataFrame【来源】
首先看下数据集说明
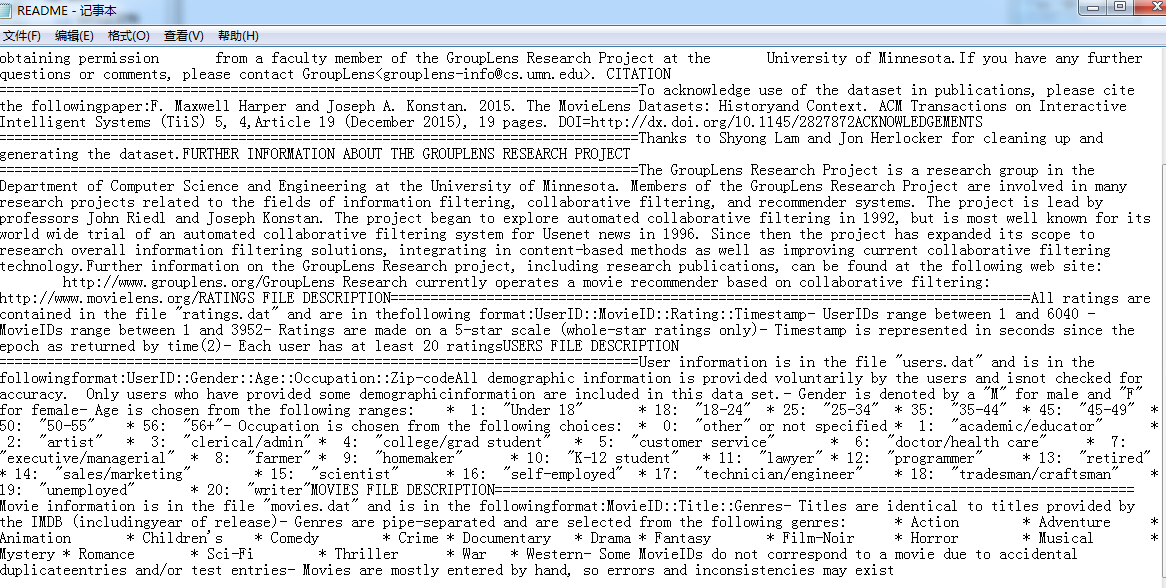
文件中数据集是以”::“作为分割的。
pandas.read_table( filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True,
skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
通过pandas.read_table将各表分别读到一个pandas DataFrame对象中:
import pandas as pd
unames=['user_id','gender','age','occupation','zip']
users=pd.read_table('D:/临时/ml-1m/users.dat',sep='::',header=None,names=unames)
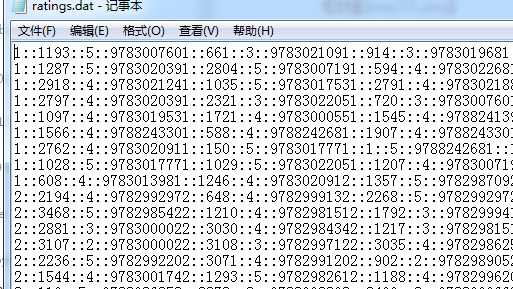
rnames=['user_id','movie_id','rating','timestamp']
ratings=pd.read_table('D:/临时/ml-1m/ratings.dat',sep='::',header=None,names=rnames)
mnames=['movie_id','title','generes']
movies=pd.read_table('D:/临时/ml-1m/movies.dat',sep='::',header=None,names=mnames)
利用python切片语法插卡每个DataFrame前几行:

为了根据三张表中多个属性计算电影平均得分,所以先合并几张表;
先用pandas的merge函数将ratings和users合并到一起,然后再将movies也合并进去。
data=pd.merge(pd.merge(ratings,users),movies)

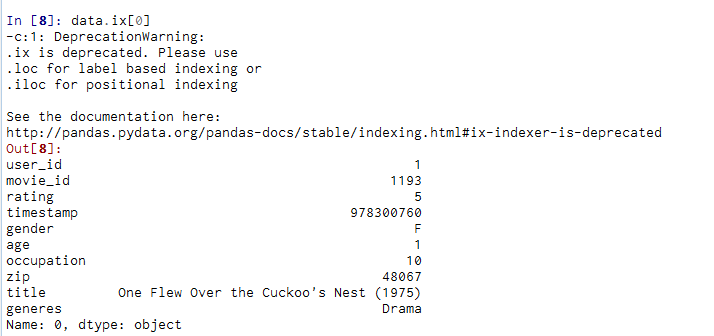
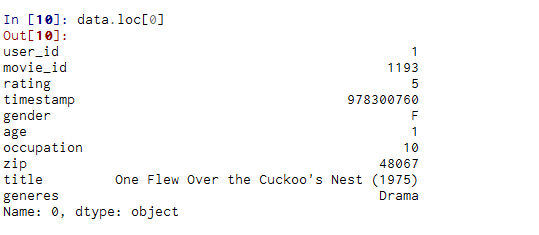
DataFrame.loc¶
通过标签或布尔数组访问一组行和列。
pandas.pivot_table(data,values = None,index = None,columns = None,aggfunc ='mean',fill_value = None,margin = False,dropna = True,_margins_name ='All' _)[source]
创建一个电子表格样式的数据透视表作为DataFrame。数据透视表中的级别将存储在结果DataFrame的索引和列上的MultiIndex对象(层次索引)中.
*注意书上的参数过旧,要按照当下查询到的函数参数来

该操作产生了另一个DataFrame,其内容为电影平均得分,行标为电影名称,列标为性别。
【目标】:过滤评分数据不够250条的电影。
【方式】:先对title进行分组,然后利用size()得到一个含有各电影分组大小的Series对象:
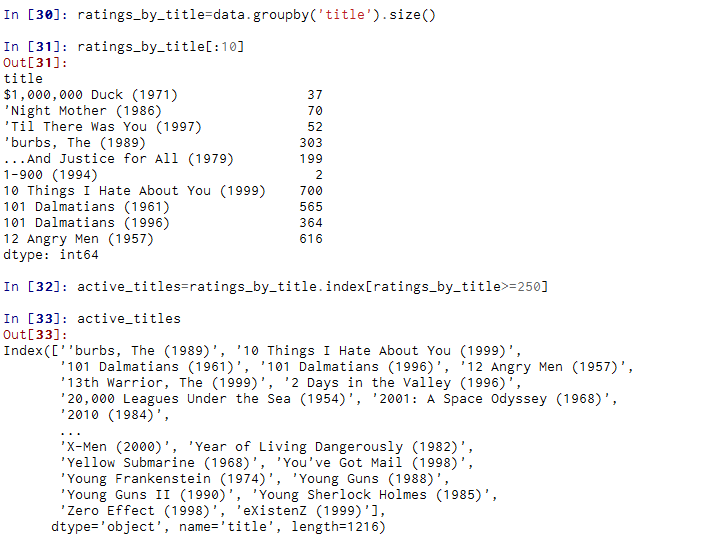
【目标】:为了解女性观众最喜欢的电影
【方式】:对F列进行降序排列:
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None)[source]
Sort object by labels (along an axis)

DataFrame.sort_values(by,axis = 0,ascending = True,inplace = False,_kind =' __quicksort _',_na_position ='last' _)[source] ¶
按任一轴的值排序

计算评分分歧
【目标】:找出男性和女性观众分歧最大的电影
【方式】:给mean_ratings加上一个用于存放平均得分之差的列,并对其进行排序。
按diff排序得到女性更喜欢的电影:

对排序结果反序并去除前15行,得到男性观众更喜欢的电影:

【目标】:不考虑性别因素找出分歧最大的电影
【方式】:计算分数数据的方差或者标准差:
