kafka简单使用
//1、consumer基本配置
Properties props = new Properties();
props.put("zookeeper.connect", zk);
props.put("group.id", groupid);
props.put("autooffset.reset", "largest");
props.put("autocommit.enable", "true");
props.put("client.id", "test");
props.put("auto.commit.interval.ms", "1000");
ConsumerConfig consumerConfig = new ConsumerConfig(props);
ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig);
//描述读取哪个topic,需要几个线程读,一个线程对应着一个KafkaStream
Map topicCountMap = new HashMap();
topicCountMap.put(topic, 1);
Map>> consumerMap =
consumerConnector.createMessageStreams(topicCountMap);
KafkaStream stream1 = consumerMap.get(topic).get(0);
ConsumerIterator it1 = stream1.iterator();
//遍历消息
while (it1.hasNext()) { //阻塞直到有消息
MessageAndMetadata messageAndMetadata = it1.next();
String message =
String.format("Consumer ID:%s, Topic:%s, GroupID:%s, PartitionID:%s, Offset:%s, Message Key:%s, Message Payload: %s",
consumerid,
messageAndMetadata.topic(), groupid, messageAndMetadata.partition(),
messageAndMetadata.offset(), new String(messageAndMetadata.key()), new String(messageAndMetadata.message()));
System.out.println(message);
}
问题
使用kafka consumer时候,让我比较好奇的一点是,consumer一旦开启后,可以不停地消费消息。
一般使用迭代器时候,比如list的迭代
while(it.hasNext()){
String text = it.next();
System.out.println("text:"+text);
//...
}
在迭代完已有数据之后,就会停止迭代了。那么kafka是如何做到迭代“未来”的数据呢。
阻塞
consumer启动之后,服务不会停止,而是会不断地消费数据,猜测consumer在某个地方阻塞住了。追下ConsumerIterator.hasNext()的源码
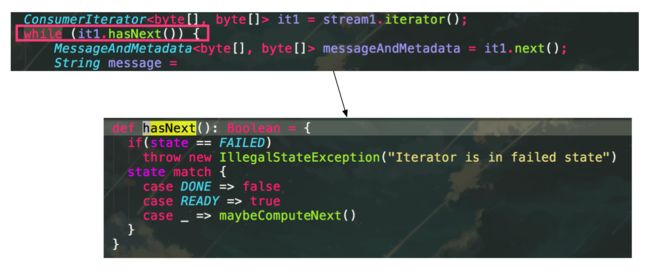
it.hasNext
state变量初始化时候,赋值为NOT_READY,
state
每次调用ConsumerIterator.next()时候,会将其再次重置为NOT_READY
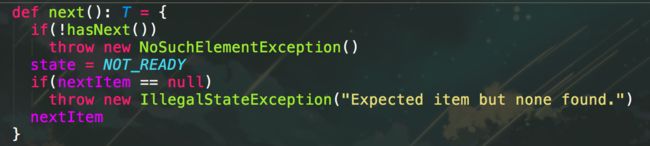
next
所以每次进行模式匹配时候,都会走到case _分支
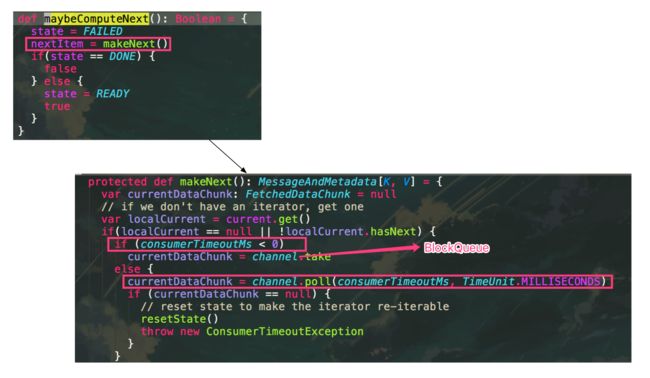
makeNext
consumer超时配置
val consumerTimeoutMs = props.getInt("consumer.timeout.ms", ConsumerTimeoutMs)
上文主要注意的有两点,超时时间的配置。(默认为-1)当配置为负数时候,会一直阻塞住,直到收到消息。
当配置大于0,比如100,会在100ms之后抛出ConsumerTimeoutException异常。
总结下
1)kafka consumer在ConsumerIterator.hasNext()阻塞获取消息,以实现消费“今后”的消息的功能。
2)当consumer.timeout.ms 配置大于0,这个阻塞会有个超时,比如配置100表示,如果100ms内没有收到消息,会抛出一个ConsumerTimeoutException异常。
默认会一直阻塞下去,直到收到一条消息。