3.1 引言
本章开始讨论UNIX系统,先说明可用的文件I/O函数——打开文 件、读文件、写文件等。UNIX系统中的大多数文件I/O只需用到5个函 数:open、read、write、lseek以及close。然后说明不同缓冲长度对read和 write函数的影响。
本章描述的函数经常被称为不带缓冲的I/O(unbuffered I/O,与将 在第5章中说明的标准I/O函数相对照)。术语不带缓冲指的是每个read 和write都调用内核中的一个系统调用。这些不带缓冲的I/O函数不是ISO C的组成部分,但是,它们是POSIX.1和Single UNIX Specification的组成 部分。
只要涉及在多个进程间共享资源,原子操作的概念就变得非常重 要。我们将通过文件I/O和open函数的参数来讨论此概念。然后,本章 将进一步讨论在多个进程间如何共享文件,以及所涉及的内核有关数据 结构。在描述了这些特征后,将说明dup、fcntl、sync、fsync和ioctl函 数。
3.2 文件描述符
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述 符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向 进程返回一个文件描述符。当读、写一个文件时,使用open或creat返回 的文件描述符标识该文件,将其作为参数传送给read或write。
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述 符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向 进程返回一个文件描述符。当读、写一个文件时,使用open或creat返回 的文件描述符标识该文件,将其作为参数传送给read或write。
按照惯例,UNIX系统shell把文件描述符0与进程的标准输入关联, 文件描述符1与标准输出关联,文件描述符2与标准错误关联。这是各种 shell以及很多应用程序使用的惯例,与UNIX内核无关。尽管如此,如 果不遵循这种惯例,很多UNIX系统应用程序就不能正常工作。 在符合POSIX.1的应用程序中,幻数0、1、2虽然已被标准化,但应 当把它们替换成符号常量STDIN_FILENO、STDOUT_FILENO和 STDERR_FILENO以提高可读性。这些常量都在头文件
文件描述符的变化范围是0~OPEN_MAX-1, 这个可以通过ulimit看,对于FreeBSD 8.0、Linux 3.2.0、Mac OS X 10.6.8以及Solaris 10,文件描述符的变化范围几乎是无限的,它只受到系统配置的存储器 总量、整型的字长以及系统管理员所配置的软限制和硬限制的约束。
我们写一个简单的echo 程序,其中STDIN_FILENO,STDOUT_FILENO其实就是0 和1,默认的指向标准输入输出的文件描述符
#include
#include
#include
#include
#include
#define BUFFSIZE 4096
int main() {
int read_size = 0;
char buf[BUFFSIZE];
memset(buf,0,BUFFSIZE);
int total = 0;
int n = 0;
printf("ready to read\n");
while( (n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0) {
total +=n;
printf("read %d bytes, total %d bytes\n", n, total);
try {
if(write(STDOUT_FILENO, buf, n) < n) {
printf("write to stdout error\n");
exit(-1);
}
} catch(std::exception &e) {
std::cout << e.what() << std::endl;
} catch(...) {
std::cout << "unknown error\n" << std::endl;
}
}
return 0;
}

3.3 函数open和openat
调用open或openat函数可以打开或创建一个文件。
#include
int open(const char *path, int oflag,... /* mode_t mode*/);
int openat(int f d, const char *path, int oflag, ... /* mode_t mode */ );
两函数的返回值:若成功,返回文件描述符;若出错,返回−1 我们将最后一个参数写为...,ISO C用这种方法表明余下的参数的数 量及其类型是可变的。对于open函数而言,仅当创建新文件时才使用最 后这个参数(稍后将对此进行说明)。在函数原型中将此参数放置在注 释中。
path参数是要打开或创建文件的名字。oflag参数可用来说明此函数 的多个选项。用下列一个或多个常量进行“或”运算构成oflag参数(这 些常量在头文件
O_RDONLY 只读打开。
O_WRONLY 只写打开。
O_RDWR 读、写打开。
大多数实现将O_RDONLY定义为0,O_WRONLY定义为1,O_RDWR定义为 2,以与早期的程序兼容。
O_EXEC 只执行打开。
O_SEARCH 只搜索打开(应用于目录)。
O_SEARCH常量的目的在于在目录打开时验证它的搜索权限。对目录的文件描述符的后续操作就不需要再次检查对该目录的搜索权限。本书 中涉及的操作系统目前都没有支持O_SEARCH。
我们写一个简单的文件读取程序代码
#include
#include
#include
#include
#include
#include
#define BUFFSIZE 4096
int main(int argc, char* argv[]) {
if(argc < 2) {
printf("args is not enough, eg readfile xxx.txt\n");
return -1;
}
int fd = open(argv[1], O_RDWR);
int n =0;
char buf[BUFFSIZE];
memset(buf,0,sizeof(buf));
printf("start to read file %s", argv[1]);
try {
while((n = read(fd,buf,BUFFSIZE) ) > 0 ){
if(write(STDOUT_FILENO, buf, n) < n) {
printf("write error\n");
return -1;
}
}
} catch (std::exception &e) {
std::cout << e.what() << std::endl;
} catch(...) {
std::cout << "unknown error" << std::endl;
}
return 0;
}
编译后读取自己的源文件显示到标准输入输出:
这里write比printf快是因为printf有buffer
这个简单的文件读取程序和之前的echo程序类似,可以看到
只是通过open函数,打开了输入命令行的文件argv[1], read这个文件描述符即可。
在这5个常量中必须指定一个且只能指定一个。下列常量则是可选
的。
O_APPEND 每次写时都追加到文件的尾端。
O_CLOEXEC 把FD_CLOEXEC常量设置为文件描述符标志。3.14节中将 说明文件描述符标志。
O_CREAT 若此文件不存在则创建它。使用此选项时,open函数需同 时说明第3个参数mode(openat函数需说明第4个参数mode),用mode指 定该新文件的访问权限位(4.5 节将说明文件的权限位,那时就能了解 如何指定mode,以及如何用进程的umask值修改它)。
O_DIRECTORY 如果path引用的不是目录,则出错。
O_EXCL 如果同时指定了 O_CREAT,而文件已经存在,则出错。用 此可以测试一个文件是否存在,如果不存在,则创建此文件,这使测试 和创建两者成为一个原子操作。3.11节将更详细地说明原子操作。
O_NOCTTY 如果path引用的是终端设备,则不将该设备分配作为此 进程的控制终端。9.6节将说明控制终端。
O_NOFOLLOW 如果path引用的是一个符号链接,则出错。4.17节将 说明符号链接。
O_NONBLOCK 如果path引用的是一个FIFO、一个块特殊文件或一个 字符特殊文件,则此选项为文件的本次打开操作和后续的I/O操作设置 非阻塞方式。14.2节将说明此工作模式。
较早的System V引入了O_NDELAY(不延迟)标志,它与 O_NONBLOCK(不阻塞)选项类似,但它的读操作返回值具有二义性。如 果不能从管道、FIFO或设备读得数据,则不延迟选项使read返回0,这 与表示已读到文件尾端的返回值0冲突。基于SVR4的系统仍支持这种语
义的不延迟选项,但是新的应用程序应当使用不阻塞选项代替之。
O_SYNC 使每次write等待物理I/O操作完成,包括由该 write操作引起的文件属性更新所需的I/O。3.14节将使用此选项。
O_TRUNC 如果此文件存在,而且为只写或读-写成功打开, 则将其长度截断为0。
O_DSYNC 使每次write要等待物理I/O操作完成,但是如果该写操作 并不影响读取刚写入的数据,则不需等待文件属性被更新。
O_DSYNC 和 O_SYNC 标志有微妙的区别。仅当文件属性需要更新以 反映文件数据变化(例如,更新文件大小以反映文件中包含了更多的数 据)时,O_DSYNC标志才影响文件属性。而设置O_SYNC标志后,数据和 属性总是同步更新。当文件用O_DSYN标志打开,在重写其现有的部分内 容时,文件时间属性不会同步更新。与此相反,如果文件是用O_SYNC标 志打开,那么对该文件的每一次write都将在write返回前更新文件时 间,这与是否改写现有字节或追加写文件无关。
O_RSYNC 使每一个以文件描述符作为参数进行的read操作 等待,直至所有对文件同一部分挂起的写操作都完成。
FreeBSD(和 Mac OS X)设置 了另外一个标志(O_FSYNC),它与标志O_SYNC的作用相同。因为这两 个标志是等效的,它们定义的标志具有相同的值。
由open和openat函数返回的文件描述符一定是最小的未用描述符数 值。这一点被某些应用程序用来在标准输入、标准输出或标准错误上打 开新的文件。
这一点被某些应用程序用来在标准输入、标准输出或标准错误上打 开新的文件。例如,一个应用程序可以先关闭标准输出(通常是文件描 述符1),然后打开另一个文件,执行打开操作前就能了解到该文件一 定会在文件描述符1上打开。在3.12节说明dup2函数时,可以了解到有更 好的方法来保证在一个给定的描述符上打开一个文件。
fd参数把open和openat函数区分开,共有3种可能性。 (1)path参数指定的是绝对路径名,在这种情况下,fd参数被忽 略,openat函数就相当于open函数。 (2)path参数指定的是相对路径名,fd参数指出了相对路径名在文 件系统中的开始地址。fd参数是通过打开相对路径名所在的目录来获 取。
(3)path参数指定了相对路径名,fd参数具有特殊值 AT_FDCWD。在这种情况下,路径名在当前工作目录中获取,openat函 数在操作上与open函数类似。
openat函数是POSIX.1最新版本中新增的一类函数之一,希望解决 两个问题。第一,让线程可以使用相对路径名打开目录中的文件,而不 再只能打开当前工作目录。在第 11 章我们会看到,同一进程中的所有 线程共享相同的当前工作目录,因此很难让同一进程的多个不同线程在 同一时间工作在不同的目录中。第二,可以避免time-of-check-to-time-ofuse(TOCTTOU)错误。
TOCTTOU错误的基本思想是:如果有两个基于文件的函数调用, 其中第二个调用依赖于第一个调用的结果,那么程序是脆弱的。因为两 个调用并不是原子操作,在两个函数调用之间文件可能改变了,这样也 就造成了第一个调用的结果就不再有效,使得程序最终的结果是错误 的。文件系统命名空间中的TOCTTOU错误通常处理的就是那些颠覆文 件系统权限的小把戏,这些小把戏通过骗取特权程序降低特权文件的权
限控制或者让特权文件打开一个安全漏洞等方式进行。Wei和Pu[2005]在 UNIX文件系统接口中讨论了TOCTTOU的缺陷。
文件名和路径名截断 如果NAME_MAX是14,而我们却试图在当前目录中创建一个文件 名包含15个字符的新文件,此时会发生什么呢?按照传统,早期的 System V版本(如SVR2)允许这种使用方法,但总是将文件名截断为 14 个字符,而且不给出任何信息,而 BSD 类的系统则返回出错状态,并 将 errno 设置为ENAMETOOLONG。无声无息地截断文件名会引起问 题,而且它不仅仅影响到创建新文件。如果NAME_MAX是14,而存在 一个文件名恰好就是14个字符的文件,那么以路径名作为其参数的任一 函数(open、stat等)都无法确定该文件的原始名是什么。其原因是这 些函数无法判断该文件名是否被截断过。
在POSIX.1中,常量_POSIX_NO_TRUNC决定是要截断过长的文件 名或路径名,还是返回一个出错.
若_POSIX_NO_TRUNC有效,则在整个路径名超过PATH_MAX, 或路径名中的任一文件名超过NAME_MAX时,出错返回,并将errno设 置为ENAMETOOLONG。
3.4函数create
也可调用creat函数创建一个新文件。
#include
int creat(const char *path, mode_t mode);
返回值:若成功,返回为只写打开的文件描述符;若出错,返回−1 注意,此函数等效于:
open(path, O_WRONLY|O_CREAT|O_TRUNC, mode);
在早期的UNIX系统版本中,open的第二个参数只能是0、1或2。无 法打开一个尚未存在的文件,因此需要另一个系统调用creat以创建新 文件。现在,open函数提供了选项O_CREAT和O_TRUNC,于是也就不再需 要单独的creat函数。
creat的一个不足之处是它以只写方式打开所创建的文件。在提供 open的新版本之前,如果要创建一个临时文件,并要先写该文件,然后 又读该文件,则必须先调用creat、close,然后再调用open。现在则可用 下列方式调用open实现:
open(path, O_RDWR|O_CREAT|O_TRUNC, mode);
3.5函数close
可调用close函数关闭一个打开文件。
#include
int close (int fd);
返回值:若成功,返回0;若出错,返回−1 关闭一个文件时还会释放该进程加在该文件上的所有记录锁。
当一个进程终止时,内核自动关闭它所有的打开文件。很多程序都 利用了这一功能而不显式地用close关闭打开文件。
3.6函数lseek
每个打开文件都有一个与其相关联的“当前文件偏移量”(current file offset)。它通常是一个非负整数,用以度量从文件开始处计算的字 节数(本节稍后将对“非负”这一修饰词的某些例外进行说明)。通 常,读、写操作都从当前文件偏移量处开始,并使偏移量增加所读写的 字节数。按系统默认的情况,当打开一个文件时,除非指定 O_APPEND选项,否则该偏移量被设置为0。
可以调用lseek显式地为一个打开文件设置偏移量。
#include
off_t lseek(int fd, off_t offset, int whence);
返回值:若成功,返回新的文件偏移量;若出错,返回为−1
对参数offset的解释与参数whence的值有关。
•若whence是SEEK_SET,则将该文件的偏移量设置为距文件开始处 offset个字节。
•若whence是SEEK_CUR,则将该文件的偏移量设置为其当前值加 offset,offset可为正或负。
•若whence是SEEK_END,则将该文件的偏移量设置为文件长度加 offset,offset可正可负。
这种方法也可用来确定所涉及的文件是否可以设置偏移量。如果文件描述符指向的是一个管道、FIFO或网络套接字,则lseek返回−1,并 将errno设置为ESPIPE。
我们写个小程序从第100个字节读刚刚的文件
#include
#include
#include
#include
#include
#include
#include
#define BUFFSIZE 4096
int main(int argc, char* argv[]) {
if(argc < 2) {
printf("args is not enough, eg readfile xxx.txt\n");
return -1;
}
time_t start_time = time(NULL);
int fd = open(argv[1], O_RDWR | O_CREAT | O_SYNC);
lseek(fd,100,SEEK_SET);
printf("fd number: %lu\n", fd);
if(!fd) {
printf("file open error, not a directory\n");
}
int n =0;
char buf[BUFFSIZE];
memset(buf,0,sizeof(buf));
printf("start to read file %s", argv[1]);
try {
while((n = read(fd,buf,BUFFSIZE) ) > 0 ){
if(write(STDOUT_FILENO, buf, n) < n) {
printf("write error\n");
return -1;
}
}
} catch (std::exception &e) {
std::cout << e.what() << std::endl;
} catch(...) {
std::cout << "unknown error" << std::endl;
}
time_t end_time = time(NULL);
close(fd);
printf("cost time : %ld\n",end_time - start_time);
return 0;
}
结果:
通常,文件的当前偏移量应当是一个非负整数,但是,某些设备也
可能允许负的偏移量。但对于普通文件,其偏移量必须是非负值。因为 偏移量可能是负值,所以在比较 lseek 的返回值时应当谨慎,不要测试 它是否小于0,而要测试它是否等于−1。
在Intel x86处理器上运行的FreeBSD的设备/dev/kmem支持负的偏 移量。 因为偏移量(off_t)是带符号数据类型(见图2-21),所以文件 的最大长度会减少一半。例如,若off_t是32位整型,则文件最大长度 是231-1个字节。
lseek仅将当前的文件偏移量记录在内核中,它并不引起任何I/O操 作。然后,该偏移量用于下一个读或写操作。 文件偏移量可以大于文件的当前长度,在这种情况下,对该文件的 下一次写将加长该文件,并在文件中构成一个空洞,这一点是允许的。 位于文件中但没有写过的字节都被读为0。 文件中的空洞并不要求在磁盘上占用存储区。具体处理方式与文件 系统的实现有关,当定位到超出文件尾端之后写时,对于新写的数据需 要分配磁盘块,但是对于原文件尾端和新开始写位置之间的部分则不需 要分配磁盘块。
3.7函数read
调用read函数从打开文件中读数据。
#include
ssize_t read(int fd, void *buf, size_t nbytes);
返回值:读到的字节数,若已到文件尾,返回0;若出错,返回−1 如read成功,则返回读到的字节数。如已到达文件的尾端,则返回
0。
有多种情况可使实际读到的字节数少于要求读的字节数:
•读普通文件时,在读到要求字节数之前已到达了文件尾端。例 如,若在到达文件尾端之前有30个字节,而要求读100个字节,则read返 回30。下一次再调用read时,它将返回0(文件尾端)。
•当从终端设备读时,通常一次最多读一行(第18章将介绍如何改 变这一点)。
•当从网络读时,网络中的缓冲机制可能造成返回值小于所要求读 的字节数。
•当从管道或FIFO读时,如若管道包含的字节少于所需的数量,那 么read将只返回实际可用的字节数。
•当从某些面向记录的设备(如磁带)读时,一次最多返回一个记 录。
•当一信号造成中断,而已经读了部分数据量时。我们将在10.5节进 一步讨论此种情况。读操作从文件的当前偏移量处开始,在成功返回之 前,该偏移量将增加实际读到的字节数。
POSIX.1从几个方面对read函 数的原型做了更改。经典的原型定义是:
int read(int fd, char *buf, unsigned nbytes);
•首先,为了与ISO C一致,第2个参数由char *改为void *。在ISO C 中,类型void *用于表示通用指针。
•其次,返回值必须是一个带符号整型(ssize_t),以保证能够返回 正整数字节数、0(表示文件尾端)或−1(出错)。
•最后,第3个参数在历史上是一个无符号整型,这允许一个16位的 实现一次读或写的数据可以多达 65 534 个字节。
在 1990 POSIX.1 标准 中,引入了新的基本系统数据类型ssize_t以提供带符号的返回值,不带 符号的size_t则用于第3个参数
3.8 函数write
调用write函数向打开文件写数据。
#include
ssize_t write(int fd, const void *buf, size_t nbytes);
返回值:若成功,返回已写的字节数;若出错,返回−1
其返回值通常与参数nbytes的值相同,否则表示出错。write出错的 一个常见原因是磁盘已写满,或者超过了一个给定进程的文件长度限制
对于普通文件,写操作从文件的当前偏移量处开始。如果在打开该 文件时,指定了O_APPEND选项,则在每次写操作之前,将文件偏移 量设置在文件的当前结尾处。在一次成功写之后,该文件偏移量增加实 际写的字节数。
3.9I/O 的效率
使用read和write写一个文件
#include
#include
#include
#include
#include
#include
#define BUFFSIZE 4096
int main() {
int n = 0;
char buf[BUFFSIZE];
memset(buf,0,BUFFSIZE);
while ( (n = read(STDIN_FILENO, buf, BUFFSIZE) ) > 0) {
if (write(STDOUT_FILENO, buf, n) != n) {
std::cout << "write error" << std::endl;
}
}
return 0;
}
关于该程序应注意以下几点。
•它从标准输入读,写至标准输出,这就假定在执行本程序之前, 这些标准输入、输出已由shell安排好。确实,所有常用的UNIX系统shell 都提供一种方法,它在标准输入上打开一个文件用于读,在标准输出上 创建(或重写)一个文件。这使得程序不必打开输入和输出文件,并允 许用户利用shell的I/O重定向功能。
•考虑到进程终止时,UNIX系统内核会关闭进程的所有打开的文件 描述符,所以此程序并不关闭输入和输出文件。
•对 UNIX 系统内核而言,文本文件和二进制代码文件并无区别,
所以本程序对这两种文件都有效。
我们还没有回答的一个问题是如何选取BUFFSIZE值。在回答此问 题之前,让我们先用各种不同的BUFFSIZE值来运行此程序。图3-6显示 了用20种不同的缓冲区长度,读516 581 760字节的文件所得到的结果。
用图 3-5 的程序读文件,其标准输出被重新定向到/dev/null 上。此 测试所用的文件系统是Linux ext4文件系统,其磁盘块长度为4 096字节 (磁盘块长度由st_blksize表示,在4.12节中说明其值为 4 096)。这也证 明了图 3-6 中系统 CPU 时间的几个最小值差不多出现在BUFFSIZE为4 096及以后的位置,继续增加缓冲区长度对此时间几乎没有影响
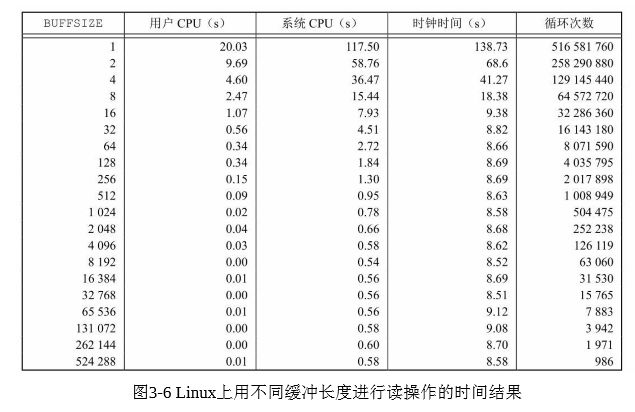
大多数文件系统为改善性能都采用某种预读(read ahead)技术。当 检测到正进行顺序读取时,系统就试图读入比应用所要求的更多数据, 并假想应用很快就会读这些数据。预读的效果可以从图3-6中看出,缓 冲区长度小至32字节时的时钟时间与拥有较大缓冲区长度时的时钟时间几乎一样。 我们以后还将回到这一实例上。3.14 节将用此说明同步写的效果, 5.8 节将比较不带缓冲的I/O时间与标准I/O库所用的时间。
应当了解,在什么时间对实施文件读、写操作的程序进行性能度 量。操作系统试图用高速缓存技术将相关文件放置在主存中,所以如若 重复度量程序性能,那么后续运行该程序所得到的计时很可能好于第一 次。其原因是,第一次运行使得文件进入系统高速缓存,后续各次运行 一般从系统高速缓存访问文件,无需读、写磁盘。(incore这个词的意 思是在主存中,早期计算机的主存是用铁氧体磁心(ferrite core)做 的,这也是“core dump”这个词的由来:程序的主存镜像存放在磁盘 的一个文件中以便测试诊断)。
3.10 文件共享
UNIX系统支持在不同进程间共享打开文件。在介绍dup函数之前, 先要说明这种共享。为此先介绍内核用于所有I/O的数据结构。
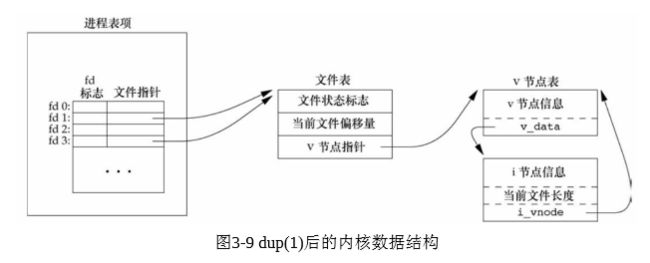
内核使用3种数据结构表示打开文件,它们之间的关系决定了在文 件共享方面一个进程对另一个进程可能产生的影响。
(1)每个进程在进程表中都有一个记录项,记录项中包含一张打 开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个 文件描述符相关联的是:
a.文件描述符标志(close_on_exec,参见图3-7和3.14节);
b.指向一个文件表项的指针。
(2)内核为所有打开文件维持一张文件表。每个文件表项包含:
a.文件状态标志(读、写、添写、同步和非阻塞等,关于这些标 志的更多信息参见3.14节);
b.当前文件偏移量;
c.指向该文件v节点表项的指针。
(3)每个打开文件(或设备)都有一个 v 节点(v-node)结构。v 节点包含了文件类型和对此文件进行各种操作函数的指针。对于大多数
文件,v节点还包含了该文件的i节点(i-node,索引节点)。这些信息是 在打开文件时从磁盘上读入内存的,所以,文件的所有相关信息都是随 时可用的。例如,i 节点包含了文件的所有者、文件长度、指向文件实 际数据块在磁盘上所在位置的指针等
Linux没有使用v节点,而是使用了通用i节点结构。虽然两种实现 有所不同,但在概念上, v节点与i节点是一样的。两者都指向文件系 统特有的i节点结构。

Linux没有将相关数据结构分为i节点和v节点,而是采用了一个与 文件系统相关的i节点和一个与文件系统无关的i节点。
两个进程打开同一个文件
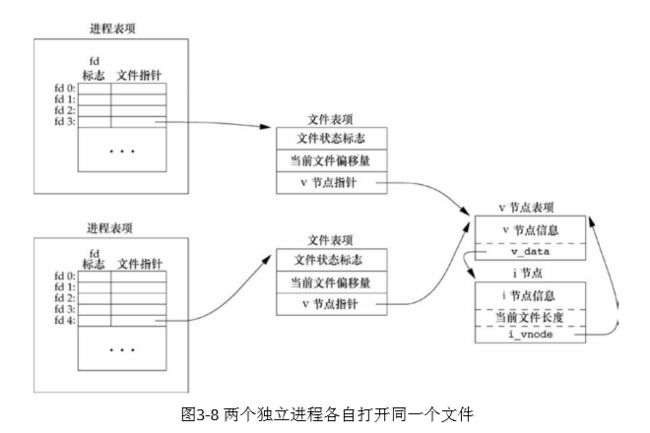
我们假定第一个进程在文件描述符3上打开该文件,而另一个进程 在文件描述符4上打开该文件。打开该文件的每个进程都获得各自的一 个文件表项,但对一个给定的文件只有一个v节点表项。之所以每个进 程都获得自己的文件表项,是因为这可以使每个进程都有它自己的对该 文件的当前偏移量。
给出了这些数据结构后,现在对前面所述的操作进一步说明。
•在完成每个write后,在文件表项中的当前文件偏移量即增加所写 入的字节数。如果这导致当前文件偏移量超出了当前文件长度,则将i 节点表项中的当前文件长度设置为当前文件偏移量(也就是该文件加长 了)。
•如果用O_APPEND标志打开一个文件,则相应标志也被设置到文 件表项的文件状态标志中。每次对这种具有追加写标志的文件执行写操 作时,文件表项中的当前文件偏移量首先会被设置为i节点表项中的文
件长度。这就使得每次写入的数据都追加到文件的当前尾端处。
•lseek函数只修改文件表项中的当前文件偏移量,不进行任何I/O操
作。
可能有多个文件描述符项指向同一文件表项
讨论dup 函数时,我们就能看到这一点。在fork后也发生同样的情况,此时父进 程、子进程各自的每一个打开文件描述符共享同一个文件表
注意,文件描述符标志和文件状态标志在作用范围方面的区别,前 者只用于一个进程的一个描述符,而后者则应用于指向该给定文件表项 的任何进程中的所有描述符。在3.14节说明fcntl函数时,我们将会了解 如何获取和修改文件描述符标志和文件状态标志。
本节前面所述的一切对于多个进程读取同一文件都能正确工作。每 个进程都有它自己的文件表项,其中也有它自己的当前文件偏移量。但 是,当多个进程写同一文件时,则可能产生预想不到的结果。为了说明 如何避免这种情况,需要理解原子操作的概念。
1.11原子操作
追加到一个文件
考虑一个进程,它要将数据追加到一个文件尾端。早期的UNIX系 统版本并不支持open的O_APPEND选项,所以程序被编写成下列形 式:
if (lseek(fd,OL, 2) < 0) /*position to EOF*/
if (write(fd, buf, 100) != 100) /*and write*/
err_sys("lseek error");
err_sys("write error");
对单个进程而言,这段程序能正常工作,但若有多个进程同时使用 这种方法将数据追加写到同一文件,则会产生问题(例如,若此程序由 多个进程同时执行,各自将消息追加到一个日志文件中,就会产生这种 情况)。
假定有两个独立的进程A和B都对同一文件进行追加写操作。每个 进程都已打开了该文件,但未使用O_APPEND标志。此时,各数据结 构之间的关系如图3-8中所示。每个进程都有它自己的文件表项,但是 共享一个v节点表项。假定进程A调用了lseek,它将进程A的该文件当前 偏移量设置为1 500字节(当前文件尾端处)。然后内核切换进程,进程 B运行。进程B执行lseek,也将其对该文件的当前偏移量设置为1 500字 节(当前文件尾端处)。然后B调用write,它将 B的该文件当前文件偏 移量增加至1 600。因为该文件的长度已经增加了,所以内核将v节点中 的当前文件长度更新为1 600。然后,内核又进行进程切换,使进程A恢 复运行。当A调用write时,就从其当前文件偏移量(1 500)处开始将数据写入到文件。这样也就覆盖了进程B刚才写入到该文件中的数据。
一般而言,原子操作(atomic operation)指的是由多步组成的一个 操作。如果该操作原子地执行,则要么执行完所有步骤,要么一步也不 执行,不可能只执行所有步骤的一个子集。在4.15节描述link函数以及在 14.3节中说明记录锁时,还将讨论原子操作。
问题出在逻辑操作“先定位到文件尾端,然后写”,它使用了两个 分开的函数调用。
解决问题的方法是使这两个操作对于其他进程而言成 为一个原子操作。任何要求多于一个函数调用的操作都不是原子操作, 因为在两个函数调用之间,内核有可能会临时挂起进程(正如我们前面 所假定的)。
UNIX系统为这样的操作提供了一种原子操作方法,即在打开文件 时设置O_APPEND标志。正如前一节中所述,这样做使得内核在每次 写操作之前,都将进程的当前偏移量设置到该文件的尾端处,于是在每 次写之前就不再需要调用lseek。
函数pread和pwrite
Single UNIX Specification包括了XSI扩展,该扩展允许原子性地定位 并执行I/O。pread和pwrite就是这种扩展。
#include
ssize_t pread(int fd, void *buf, size_t nbytes, off_t offset);
返回值:读到的字节数,若已到文件尾,返回0;若出错,返回−1
ssize_t pwrite(int fd, const void *buf, size_t nbytes, off_t offset);
返回值:若成功,返回已写的字节数;若出错,返回−1
调用pread相当于调用lseek后调用read,但是pread又与这种顺序调用 有下列重要区别。 •调用pread时,无法中断其定位和读操作。 •不更新当前文件偏移量。 调用pwrite相当于调用lseek后调用write,但也与它们有类似的区 别。
创建一个文件
对open函数的O_CREAT和O_EXCL选项进行说明时,我们已见到 另一个有关原子操作的例子。当同时指定这两个选项,而该文件又已经 存在时,open 将失败。我们曾提及检查文件是否存在和创建文件这两个 操作是作为一个原子操作执行的。如果没有这样一个原子操作,那么可 能会编写下列程序段:
if ((fd = open(pathname, O_WRONLY)) <0){
if (errno == ENOENT) {
if ((fd = creat(path, mode)) < 0)
err_sys("creat error"); }
else{
err_sys("open error");
}
}
如果在open和creat之间,另一个进程创建了该文件,就会出现问 题。若在这两个函数调用之间,另一个进程创建了该文件,并且写入了 一些数据,然后,原先进程执行这段程序中的creat,这时,刚由另一进 程写入的数据就会被擦去。如若将这两者合并在一个原子操作中,这种 问题也就不会出现。
3.12 dup和dup2
下面两个函数都可用来复制一个现有的文件描述符。
#include
int dup(int fd);
int dup2(int fd, int fd2);
两函数的返回值:若成功,返回新的文件描述符;若出错,返回−1 由dup返回的新文件描述符一定是当前可用文件描述符中的最小数 值。对于 dup2,可以用fd2参数指定新描述符的值。如果fd2已经打开, 则先将其关闭。如若fd等于fd2,则dup2返回fd2,而不关闭它。否则, fd2的FD_CLOEXEC文件描述符标志就被清除,这样fd2在进程调用exec 时是打开状态。
这些函数返回的新文件描述符与参数fd共享同一个文件表项。
#include
#include
#include
#include
#include
#define BUFFSIZE 4096
int main(int argc, char* argv[]) {
int new_fd = dup(1);
std::cout << "start new dup" << std::endl;
int n = 0;
char buf[4096];
memset(buf,0,BUFFSIZE);
int len = 0;
while((n = read(STDIN_FILENO,buf,BUFFSIZE)) > 0) {
if((write(new_fd, buf,n) != n)) {
std::cout << "new_fd error" << std::endl;
} else {
std::cout << "write " << n << "bytes" << std::endl;
}
}
return 0;
}
可以看到,像new_fd中写入内容还是写入了STDOUT
在此图中,我们假定进程启动时执行了:
newfd = dup(1); 当此函数开始执行时,假定下一个可用的描述符是3(这是非常可 能的,因为0,1和2都由shell打开)。因为两个描述符指向同一文件表 项,所以它们共享同一文件状态标志(读、写、追加等)以及同一当前 文件偏移量。
每个文件描述符都有它自己的一套文件描述符标志。正如我们将在 下一节中说明的那样,新描述符的执行时关闭(close-on-exec)标志总 是由dup函数清除。
每个文件描述符都有它自己的一套文件描述符标志。正如我们将在 下一节中说明的那样,新描述符的执行时关闭(close-on-exec)标志总 是由dup函数清除。 复制一个描述符的另一种方法是使用 fcntl 函数,3.14 节将对该函数 进行说明。
实际上,调用 dup(fd);
等效于 fcntl (fd, F_DUPFD, 0);
而调用 dup2(fd, fd2);
等效于 close(fd2); fcntl(fd, F_DUPFD, fd2);
在后一种情况下,dup2并不完全等同于close加上fcntl。
它们之间的 区别具体如下。
(1)dup2 是一个原子操作,而 close 和 fcntl 包括两个函数调用。 有可能在 close 和fcntl之间调用了信号捕获函数,它可能修改文件描述 符(第10章将说明信号)。如果不同的线程改变了文件描述符的话也会 出现相同的问题(第11章将说明线程)。
(2)dup2和fcntl有一些不同的errno。
3.13函数sync、fsync和fdatasync
传统的UNIX系统实现在内核中设有缓冲区高速缓存或页高速缓 存,大多数磁盘I/O都通过缓冲区进行。当我们向文件写入数据时,内 核通常先将数据复制到缓冲区中,然后排入队列,晚些时候再写入磁 盘。这种方式被称为延迟写(delayed write)(Bach[1986]的第3章详细讨 论了缓冲区高速缓存)。
通常,当内核需要重用缓冲区来存放其他磁盘块数据时,它会把所 有延迟写数据块写入磁盘。为了保证磁盘上实际文件系统与缓冲区中内 容的一致性,UNIX 系统提供了 sync、fsync 和fdatasync三个函数。
#include
int fsync(int fd);
int fdatasync(int fd);
返回值:若成功,返回0;若出错,返回−1
void sync(void); sync只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。
通常,称为update的系统守护进程周期性地调用(一般每隔30秒) sync函数。这就保证了定期冲洗(flush)内核的块缓冲区。命令sync(1) 也调用sync函数。
fsync函数只对由文件描述符fd指定的一个文件起作用,并且等待写 磁盘操作结束才返回。fsync可用于数据库这样的应用程序,这种应用程 序需要确保修改过的块立即写到磁盘上。
fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据
外,fsync还会同步更新文件的属性。
3.14 函数fcntl
fcntl函数可以改变已经打开文件的属性。
#include
int fcntl(int fd, int cmd, ... /* int arg */);
返回值:若成功,则依赖于cmd(见下);若出错,返回−1
在本节的各实例中,第3个参数总是一个整数,与上面所示函数原
型中的注释部分对应。但是在14.3节说明记录锁时,第3个参数则是指向 一个结构的指针。
fcntl函数有以下5种功能。
(1)复制一个已有的描述符(cmd=F_DUPFD或 F_DUPFD_CLOEXEC)。
(2)获取/设置文件描述符标志(cmd=F_GETFD或F_SETFD)。
(3)获取/设置文件状态标志(cmd=F_GETFL或F_SETFL)。
(4)获取/设置异步I/O所有权(cmd=F_GETOWN或
F_SETOWN)。
(5)获取/设置记录锁(cmd=F_GETLK、F_SETLK或
F_SETLKW)。 我们先说明这11种cmd中的前8种(14.3节说明后3种,它们都与记录锁有关)。参照图3-7,我们将讨论与进程表项中各文件描述符相关联 的文件描述符标志以及每个文件表项中的文件状态标志。
F_DUPFD 复制文件描述符fd。新文件描述符作为函数值 返回。它是尚未打开的各描述符中大于或等于第3个参数值(取为整型 值)中各值的最小值。新描述符与 fd共享同一文件表项(见图 3-9)。但是,新描述符有它自己的一套文件描述符标志,其 FD_CLOEXEC 文 件描述符标志被清除(这表示该描述符在exec时仍保持有效,我们将在 第8章对此进行讨论)
F_DUPFD_CLOEXEC 复制文件描述符,设置与新描述符关联的 FD_CLOEXEC文件描述符标志的值,返回新文件描述符。
F_GETFD 对应于fd的文件描述符标志作为函数值返回。当前只定 义了一个文件描述符标志FD_CLOEXEC。
F_SETFD 对于fd设置文件描述符标志。新标志值按第3个参数(取 为整型值)设置。
要知道,很多现有的与文件描述符标志有关的程序并不使用常量 FD_CLOEXEC,而是将此标志设置为0(系统默认,在exec时不关闭)或 1(在exec时关闭)。
F_GETFL 对应于fd的文件状态标志作为函数值返回。我们在说明 open函数时,已描述了文件状态标志。它们列在图3-10中。

遗憾的是,5个访问方式标志(O_RDONLY、O_WRONLY、 O_RDWR、O_EXEC以及O_SEARCH)并不各占1位(如前所述,由于 历史原因,前3个标志的值分别是0、1和2。这5个值互斥,一个文件的 访问方式只能取这5个值之一)。因此首先必须用屏蔽字O_ACCMODE 取得访问方式位,然后将结果与这5个值中的每一个相比较。
F_SETFL 将文件状态标志设置为第3个参数的值(取为整型值)。 可以更改的几个标志是:O_APPEND、O_NONBLOCK、O_SYNC、 O_DSYNC、O_RSYNC、O_FSYNC和O_ASYNC。
F_GETOWN 获取当前接收SIGIO和SIGURG信号的进程ID或进程 组ID。14.5.2节将论述这两种异步I/O信号。
开启了同 步写标志。
set_fl(STDOUT_FILENO, O_SYNC);
这就使每次write都要等待,直至数据已写到磁盘上再返回。在 UNIX系统中,通常write只是将数据排入队列,而实际的写磁盘操作则 可能在以后的某个时刻进行。而数据库系统则需要使用 O_SYNC,这样 一来,当它从 write 返回时就知道数据已确实写到了磁盘上,以免在系 统异常时产生数据丢失。
程序运行时,设置O_SYNC标志会增加系统时间和时钟时间。为了 测试这一点,先运行图3-5程序,它从一个磁盘文件中将492.6 MB的数据 复制到另一个文件。然后,对比设置了O_SYNC标志的程序,使其完成 同样的工作。在使用ext4文件系统的Linux上执行上述操作,得到的结果
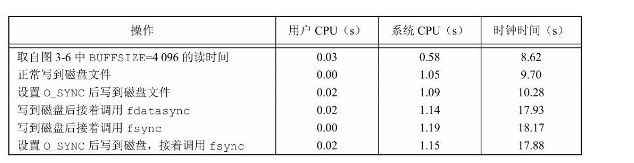
在写磁盘文 件时,系统时间增加了,其原因是内核需要从进程中复制数据,并将数 据排入队列以便由磁盘驱动器将其写到磁盘上。当写至磁盘文件时,我 们期望时钟时间也会增加。
当支持同步写时,系统时间和时钟时间应当会显著增加。但从第3 行可见,同步写所用的系统时间并不比延迟写所用的时间增加很多。这 意味着要么Linux操作系统对延迟写和同步写操作的工作量相同(这其 实是不太可能的),要么 O_SYNC 标志并没有起到期望的作用。在这 种情况下,Linux操作系统并不允许我们用fcntl设置O_SYNC标志,而是 显示失败但没有返回出错(但如果在文件打开时能指定该标志,我们还 是应该遵重这个标志的)。
在采用HFS文件系统的Mac OS X 10.6.8上运行同样的测试得到的计时结果。该计时结果与我们的期望相符:同步写比延迟写所 消耗的时间增加了很多,而且在同步写后再调用函数fsync并不产生测量 结果上的显著差别。还要注意的是,在延迟写后增加一个fsync函数调 用,测量结果的差别也不大。其可能原因是,在向某个文件写入新数据 时,操作系统已经将以前写入的数据都冲洗到了磁盘上,所以在调用函 数fsync时只需要做很少的工作。

比较fsync和fdatasync,两者都更新文件内容,用了O_SYNC标志, 每次写入文件时都更新文件内容。每一种调用的性能依赖很多因素,包 括底层的操作系统实现、磁盘驱动器的速度以及文件系统的类型。
在本例中,我们看到了fcntl的必要性。我们的程序在一个描述符 (标准输出)上进行操作,但是根本不知道由shell打开的相应文件的文 件名。因为这是shell打开的,因此不能在打开时按我们的要求设置 O_SYNC标志。使用fcntl,我们只需要知道打开文件的描述符,就可以 修改描述符的属性。
3.15 函数ioctl
ioctl函数一直是I/O操作的杂物箱。不能用本章中其他函数表示的 I/O操作通常都能用ioctl表示。终端I/O是使用ioctl最多的地方
#include /* System V */
#include /* BSD and Linux */ i
nt ioctl(int fd, int request, ...);
返回值:若出错,返回−1;若成功,返回其他值
ioctl函数是Single UNIX Specification标准的一个扩展部分,以 便处理STREAMS设备[Rago 1993],但是,在SUSv4中已被移至弃用状 态。UNIX系统实现用它进行很多杂项设备操作。有些实现甚至将它扩展 到用于普通文件。
在此原型中,我们表示的只是ioctl函数本身所要求的头文件。通 常,还要求另外的设备专用头文件。例如,除POSIX.1所说明的基本操 作之外,终端I/O的ioctl命令都需要头文件
每个设备驱动程序可以定义它自己专用的一组 ioctl 命令,系统则为 不同种类的设备提供通用的ioctl命令。图3-15中总结了FreeBSD支持的通 用ioctl命令的一些类别。

磁带操作使我们可以在磁带上写一个文件结束标志、倒带、越过指 定个数的文件或记录等,用本章中的其他函数(read、write、lseek 等) 都难于表示这些操作,所以,对这些设备进行操作最容易的方法就是使 用ioctl。
在18.12节中将说明使用ioctl函数获取和设置终端窗口大小,19.7节 中使用ioctl函数访问伪终端的高级功能。
3.16 /dev/fd
较新的系统都提供名为/dev/fd 的目录,其目录项是名为 0、1、2 等的文件。打开文件/dev/fd/n等效于复制描述符n(假定描述符n是打 开的)。
/dev/fd这一功能是由Tom Duff开发的,它首先出现在Research UNIX系统的第8版中,本书说明的所有4种系统(FreeBSD 8.0、Linux 3.2.0、Mac OS X 10.6.8和Solaris 10)都支持这一功能。它不是 POSIX.1的组成部分。
在下列函数调用中:
fd = open("/dev/fd/0", mode);
在下列函数调用中:
fd = open("/dev/fd/0", mode);
大多数系统忽略它所指定的 mode,而另外一些系统则要求 mode 必 须是所引用的文件(在这里是标准输入)初始打开时所使用的打开模式 的一个子集。因为上面的打开等效于
fd = dup(0);
所以描述符0和fd共享同一文件表项(见图3-9)。例如,若描述符0 先前被打开为只读,那么我们也只能对fd进行读操作。即使系统忽略打 开模式,而且下列调用是成功的:
fd = open("/dev/fd/0", O_RDWR);
我们仍然不能对fd进行写操作。
Linux实现中的/dev/fd是个例外。它把文件描述符映射成指向底层 物理文件的符号链接。例如,当打开/dev/fd/0时,事实上正在打开与 标准输入关联的文件,因此返回的新文件描述符的模式与/dev/fd文件 描述符的模式其实并不相关。
我们也可以用/dev/fd作为路径名参数调用creat,这与调用open时用 O_CREAT作为第2个参数作用相同。例如,若一个程序调用creat,并且 路径名参数是/dev/fd/1,那么该程序仍能工作。
注意,在Linux上这么做必须非常小心。因为Linux实现使用指向实 际文件的符号链接,在/dev/fd文件上使用creat会导致底层文件被截 断。
某些系统提供路径名/dev/stdin、/dev/stdout 和/dev/stderr,这些等 效于/dev/fd/0、/dev/fd/1和/dev/fd/2。
/dev/fd文件主要由shell使用,它允许使用路径名作为调用参数的程 序,能用处理其他路径名的相同方式处理标准输入和输出。例如,cat(1) 命令对其命令行参数采取了一种特殊处理,它将单独的一个字 符“-”解释为标准输入。例如:
filter file2 | cat file1 - file3 | lpr
首先cat读file1,接着读其标准输入(也就是filter file2命令的输 出),然后读file3,如果支持/dev/fd,则可以删除cat对“-”的特殊处 理,于是我们就可键入下列命令行:
filter file2 | cat file1 /dev/fd/0 file3 | lpr
作为命令行参数的“-”特指标准输入或标准输出,这已由很多程 序采用。但是这会带来一些问题,例如,如果用“-”指定第一个文 件,那么看来就像指定了命令行的一个选项。/dev/fd则提高了文件名 参数的一致性,也更加清晰。
本章说明了UNIX系统提供的基本 I/O函数。因为read和write都在内 核执行,所以称这些函数为不带缓冲的I/O函数。在只使用read和write 情况下,我们观察了不同的I/O长度对读文件所需时间的影响。我们也 观察了许多将已写入的数据冲洗到磁盘上的方法,以及它们对应用程序 性能的影响。
在说明多个进程对同一文件进行追加写操作以及多个进程创建同一 文件时,本章介绍了原子操作。也介绍了内核用来共享打开文件信息的 数据结构。在本书的稍后还将涉及这些数据结构。