1,检查是否装了JDK,JDK版本建议(必须)在1.8或以上,如果没有装JDK,sqoop提交运行的时候,使用的jre会报错
2,检查/etc/profile中有没有配置JDK的环境变量,如果没有配置,增加JDK的环境便量:
在profile最下面加一下内容
export JAVA_HOME=/opt/apps/jdk1.8.0_181
export PATH=JAVA_HOME/bin
然后source /etc/porfile(这个操作是让环境变量立即生效)
3,配置了以上内容,执行sqoop命令是还是会报错,因为此时你还没有把MySQL的驱动包拷贝到Hive/lib目录下,当然这个操作非常简单,你只需要使用 find / -name mysql-connector-java-5.1.34.jar ,如果查不到可以把-Java后边的替换成*即可,
我的操作是:
cp /opt/dataxUtil/datax/plugin/writer/mysqlwriter/libs/mysql-connector-java-5.1.34.jar /usr/hdp/2.6.5.0-292/hive/lib/
6,然后你再次去运行,感觉导数据已经十拿九稳了,但是我还是要很遗憾的告诉你,还需要配置一个环境变量:
在etc/profile最后边加需要加:export HADOOP_USER_NAME=hdfs
这个配置非常重要,因为从关系行数据库导入数据时,使用的root权限,然而HDFS不支持这样的操作作,你导数据的时候没有报错发现导入的数据都是null,无论如何,你把这个环境变量加上就对了
7,是不是觉得这次肯定不会出问题了,万事俱备只欠东风的感jiao啊,再次执行还是会报错,是不是很头疼,这次需要解决的时Hadoop的环境变量问题,因为Hadoop现在的环境变量还是默认的jre
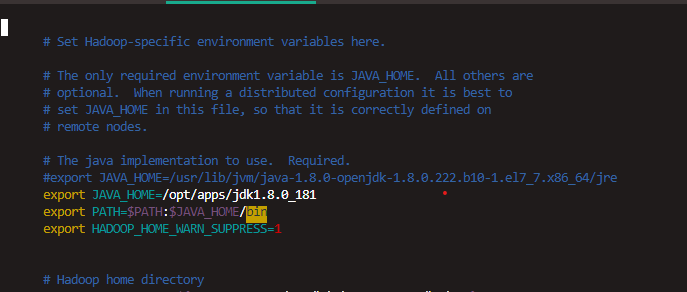
执行命令:vim /etc/hadoop/hadoop-env.sh
当然路径可能不要样,你还是需要使用:find / -name hadoop-env.sh 这个命令找一下,你可能会找到很多这样的脚本,这时候怎么办呢,别着急
[图片上传失败...(image-7f11fb-1594695388703)]
和此图匹配一下
打开后输入:/JAVA_HOME,查找出位置,然后注释掉那一行,一行,一行,不要做多余的操作
然后配置你JDK8的环境变量即可:(我的操作是)
export JAVA_HOME=/opt/apps/jdk1.8.0_181
export PATH=JAVA_HOME/bin
一定要和其他的对齐,对齐,对齐
8,如果你发现上面的配置都成功了,执行命令显示OK,但是hive表中的数据还是null,这个也不用着急,先看看你在hive中建表是分隔符用的是不是逗号,如果是,换成一个制表符就OK了“\t”,当然我还没有试过建表是没有规定制表符,就导入数据,大家可以尝试一下
9,
然后你执行正确的命令即可:我可以给大家提供几个模板,都是我测试环境可以使用的
Hive增量导出到MySQL
!/bin/bash
hive -e "drop table if exists test.t4"
col1=hive -e "desc test.users "|sed '1d'|awk '{printf $1","}'|sed 's/,$/\n/g'
hive -e "create table test.t4 as select ${col1} from test.users where times='20191203'"
echo "===================start export Job======================"
col2=hive -e "desc test.t4"|sed '1d'|awk '{printf $1","}'|sed 's/,$/\n/g'
sqoop export \
--connect jdbc:mysql://localhost:localhost/ada_test \
--username XXX \
--password XXX \
--table usress \
--export-dir /apps/hive/warehouse/test.db/t4 \
--columns ${col2} \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n' \
--input-null-string "\\N" \
--input-null-non-string "\\N"
hive -e "drop table if exists test.t4"
echo "==================end export Job ========================"
Hive全量导出到MySQL
!/bin/bash
echo "===================start export Job======================"
col2=hive -e "desc test.users" | awk '{printf $1","}'|sed 's/,$/\n/g'
sqoop export \
--connect jdbc:mysql://localhost:3306/ada_test \
--username XXX \
--password XXX \
--table usress \
--export-dir "/apps/hive/warehouse/test.db/users" \
--columns ${col2} \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n' \
--input-null-string "\\N" \
--input-null-non-string "\\N"
echo "==================end export Job ========================"
MySQL全量导入到hive
!/bin/bash
echo "===================start import Job======================"
sqoop import \
-Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect 'jdbc:mysql://localhost:3306/ada_test?tinyInt1isBit=false&useUnicode=true&characterEncoding=UTF-8' \
--username XXX \
--password XXX \
--table userss \
--hive-database test \
--hive-table tmps \
--hive-import -m 1 \
--incremental append \
--split-by name \
--check-column uid \
-last-value 5
echo "==================end import Job ========================"
MySQL增量导入Hive根据ID,导入的是大于规定的ID值的
!/bin/bash
echo "===================start import Job======================"
sqoop import \
-Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect 'jdbc:mysql://localhost/ada_test?tinyInt1isBit=false&useUnicode=true&characterEncoding=UTF-8' \
--username XXX \
--password XXX \
--table userss \
--hive-database test \
--hive-table tmps \
--hive-import -m 1 \
--incremental append \
--split-by name \
--check-column uid \
-last-value 5
echo "==================end import Job ========================"
增量抽取MySQL数据,建表语句可以应用在全量导入的场景下
!/bin/bash
echo "=======================================全量抽取,开始建表==============================================================="
sqoop create-hive-table \
--connect "jdbc:mysql://localhost/ada_test?tinyInt1isBit=false&useUnicode=true&characterEncoding=UTF-8" \
--username XXX \
--password XXX \
--table tru \
--hive-table test.sqoop_test
echo "=========================================建表完成======================================================================"
echo "=========================================开始抽取数据======================================================================"
sqoop import \
-Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect "jdbc:mysql://localhost:3307/ada_test?tinyInt1isBit=false&useUnicode=true&characterEncoding=UTF-8" \
--username XXX \
--password XXX \
-table tru \
-hive-database test \
-hive-table sqoop_test \
-hive-import -m -1 \
--incremental append \
--check-column times \
--split-by name \
--last-value "2019-12-06"
echo "=========================================数据抽取完成======================================================================"
根据sql语句进行导入
sqoop import
--connect jdbc:mysql://localhost:3306/test
--username xxx
--password xxx
--direct
--fields-terminated-by '\t'
--target-dir /data/sqoop/shop
--delete-target-dir
--hive-import
--hive-overwrite
--hive-database shop
--hive-table order
--create-hive-table
--query 'SELECT d.id,d.order_id,d.order_no,o.member_id,o.member_name,o.pay_status,o.pay_time,o.order_status,o.order_time,o.is_admin_order,o.source,o.ip_address,d.shop_id,ca2.id kz_id,ca2.category_name kz_name,ca1.id km_id,ca1.category_name km_name,d.category_id,d.goods_id,d.goods_type,d.goods_name,d.goods_sale_price,d.goods_num,d.goods_date FROM ec_order_detail d left join ec_order o on o.id = d.order_id LEFT JOIN ec_category ca ON ca.id = d.category_id LEFT JOIN ec_category ca1 ON ca1.id = ca.parentid LEFT JOIN ec_category ca2 ON ca2.id = ca1.parentid
WHERE $CONDITIONS' --split-by 'd.id'