Python爬虫实战- 爬取整个网站112G-8000本pdf epub格式电子书下载
(整个代码附在最后)
目录:
- 爬虫准备 - 某电子书网站内容架构分析
- 爬虫前奏 - 网站Html代码分析,如何获取需要的链接?
- 爬虫高潮 - 测试是否有反爬虫措施,测试是否能正常下载一个sample
- 爬虫论剑 - 根据需求编写爬虫函数代码,如正则表达式等。
- 爬虫测试 – 开始爬虫,根据问题点优化代码bug
- 爬虫总结 – 总结爬虫过程,记录问题点,分享爬虫经验等。
- 爬虫代码 - 白浪介绍以及分享整个爬虫代码
注:
- 本文档仅供学习Python之用,任何非法的活动引起的法律纠纷与本人无关。本人享有该文档最终解释权。
- 爬虫道德提醒:别人建一个网站也不容易,请不要用多线程爬虫,分分钟弄爆服务器可不是开玩笑的。
本文档适合Python初学者,以及有一定Python经验的人。代码注释很详细,不用担心看不懂。
1.爬虫准备 - 某电子书网站内容架构分析
爬取的目标网站有很多英文电子书,平时根据需求一本本下载太慢,担心哪天网站关了就下不到资料,于是Python爬虫技术就派上用场了。
网站内容介绍:网站首页如下:初步估算电子书达一万多本,涵盖IT的各行各业。
涉及的方向有:
Web技术, 各种编程语言(C,C++,Python,Java,CUDA…),数据库,大数据,图形图像设计,操作系统,网络与云计算,工商管理,各种证书认证,电脑与新技术,创业事业,游戏开发,硬件与DIY,市场SEO,网络安全黑客,各种软件使用(如PS等)
从硬件,DIY,树莓派,STM,嵌入式驱动到操作系统,Android,windows,linux,Mac等都有。再到应用层的开发,涉及各种编程语言,再到云计算,大数据等。还有适合产品经理,企业高管,创业者,学生考试认证,工程师考试认证等各个方面的资料。
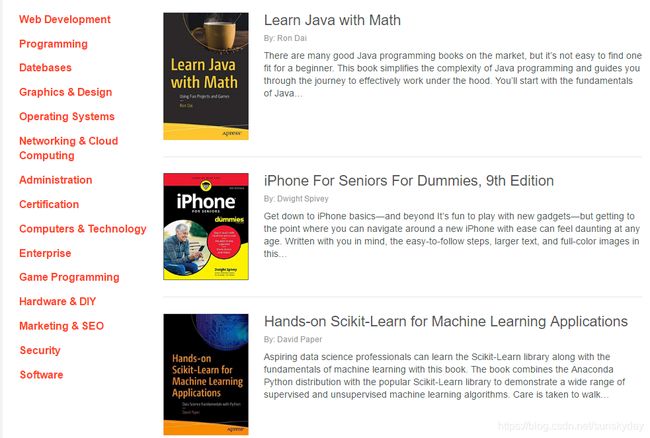
总而言之,我非常喜欢的一个网站,没有广告,各种资料点击进去就能下载。
1.2 如,点击第一本《Learn Java with Math》
如图,介绍了该版本书籍的出版年份,页数231页,文档格式支持pdf以及epub格式的下载,还有书籍的简述。非常的赞。
点击下方的 Download 就能下载pdf格式的文档,或者epub格式的文档。

2. 爬虫前奏 - 网站Html代码分析
2.1 网站下方有页码,一共840页,每页10本书。
url的页数命名也很简单: www.****.org/gage/2 ,每一页就改变后面的数字
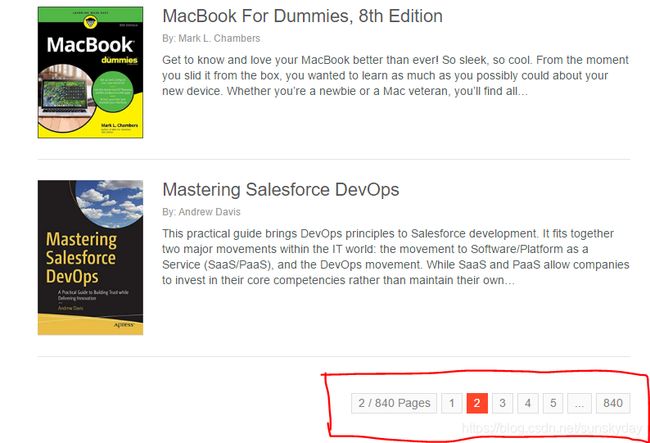
2.2 每一页Html代码分析:
如下图为第2页,每页10本书,浏览器按 F12按键,可以查看html代码,一级一级的解析,可以看到每本书介绍页面对应的URL。
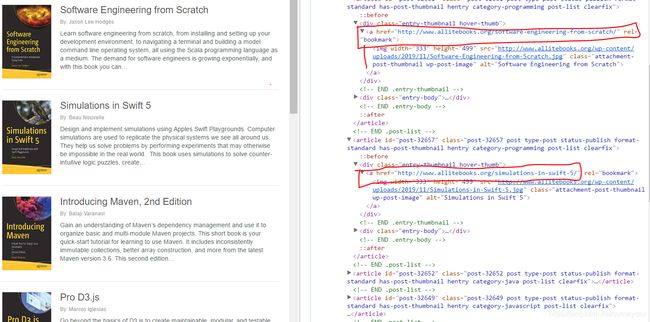
2.3 每本书页面的HTML代码代码而分析:
选取第一本书页面作为分析,按下F12,一级一级解析,可以看到该pdf本书对应的下载地址以及 epub书籍对应的下载地址。

2.4 至此该网站的HTML代码分析完了。如何在爬虫时候正则匹配这些URL也是非常关键的地方。
网站HTML总结一下:
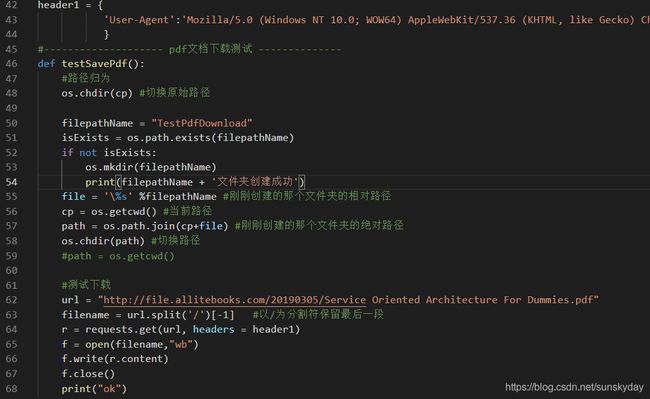
3. 爬虫高潮 – 编写代码测试是否能正常下载一个sample
第二节已经详细分析了该网站的架构以及HTML代码,下面就编写一个函数用来测试是否能正常根据URL下载pdf文档。(整个代码在最后)
该pdf下载测试函数主要分为两部分,一个是建立文件夹,一个是根据文档的URL下载地址看看是否能下载。若不能下载,修改 header 文件。通过测试,该header可以正常访问服务器资源,说明该网站没有什么反爬虫措施。
关于具有反爬虫措施导致的异常error问题,后续相关的文章会继续介绍。
4. 爬虫论剑 - 编写各个爬虫函数代码
4.1 import模块
import os
import requests
import re
from bs4 import BeautifulSoup
import time
import logging4.2 logging模块
记得用log,因为你永远不知道你的爬虫程序会遇到什么bug,记录log是个非常好的习惯,当爬虫遇到bug异常时候,log能够帮助你分析问题。
#--------------------log记录---------------
# 创建一个logger
logger = logging.getLogger(__name__)
logger.setLevel(level = logging.INFO)
# 创建一个handler,用于写入日志文件
handler = logging.FileHandler("log.txt")
handler.setLevel(logging.INFO)
'''
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)'''
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(handler)
#logger.addHandler(ch)
4.3 Pdf文件下载函数
根据每个pdf文件的URL来下载文件。
# 下载文件
def DownloadPdf(url):
#print("1")
try:
filename = url.split('/')[-1] #以/为分割符保留最后一段
#如果文件不存在
if (not os.path.exists(filename)):
r = requests.get(url, headers = header1)
f = open(filename,"wb")
f.write(r.content)
f.close()
print("download ok")
logger.info("download ok") #log记录
else:
print("文件已经存在,跳过下载")
logger.info("文件已经存在,跳过下载") #log记录
except Exception as reason:
logger.info("出错原因:%s" %str(reason)) #log记录
print("出错原因:%s" %str(reason))4.4 爬虫重点程序(重点注意事项都在代码里)
getPage(url):用来解析每个URL界面,返回HTML代码。
getPdfPage(bookurl):获取每本书介绍页面的pdf下载地址,然后调用DownloadPdf()函数来下载书籍。
getPageList(html):获取每个页面10本书的 URL地址,然后调用getPdfPage()函数。
makedir(dirNum):创建文件夹,文件太多,该函数很有用。
Main(): 主函数完成840页的循环,每一页里面调用getPageList()函数。
程序逻辑:main()- getPageList()- getPdfPage()- DownloadPdf()
# books网站一共840页面
def getPage(url):
try:
page = requests.get(url, headers = header1) #获取每一页的html,每一页的html没有pdf文档
html = page.content
return html
except e as reason:
logger.info("出错原因:%s" %str(reason)) #log记录
#获取每本书页面的pdf
def getPdfPage(bookurl):
html2 = getPage(bookurl)
#print(html)
soup2 = BeautifulSoup(html2,"lxml",from_encoding='utf-8') #网页为lxml格式
#查找pdf文件下载的节点
tags2 = soup2.find_all('span', class_="download-links")
logger.info("pdf tags:%s" %str(tags2)) #log记录
#print(tags2)
#move_list = []
#re测试
'''print("re测试")
for list2 in tags2:
move = list2.a.span.text.strip()
move_list.append(move)
print(move_list)'''
for list2 in tags2:
try:
herf2 = list2.find_all('a')
#正则匹配,每本书介绍页面的url
bookDownloadUr = str(re.findall("http?://(?:[-\w.])+/(?:[-\w.])+/(?:[-\w.,'\s.])+", str(herf2)))
print(bookDownloadUr)
logger.info(bookDownloadUr) #log记录
#移除字符串首尾的[]'"
bookDownloadUrl = bookDownloadUr.strip("[']")
bookDownloadUrl = bookDownloadUrl.strip('"')
except Exception as reason:
logger.info("出错原因:%s" %str(reason)) #log记录
#匹配 pdf文档
if '.pdf' in bookDownloadUrl:
if '.epub' in bookDownloadUrl:
print('')
else:
print("下载书籍网址:"+bookDownloadUrl)
logger.info("下载书籍网址:%s" %str(bookDownloadUrl)) #log记录
DownloadPdf(bookDownloadUrl)
#return bookDownloadUrl
else:
print('epub文件,跳过下载')
logger.info('epub文件,跳过下载') #log记录
#获取每页的10本书的url
def getPageList(html):
soup = BeautifulSoup(html,"lxml",from_encoding='utf-8') #网页为html格式
#查找所有有关的节点
tags = soup.find_all('h2', class_="entry-title")
#tags = soup.find('h2', class_="entry-title")
for list1 in tags:
try:
herf = list1.find_all('a')
bookname = herf[0].string #每页书籍的名称
logging.info("书籍名称:%s" %str(bookname))
#正则匹配,每本书介绍页面的url
booku = str(re.findall('http?://(?:[-\w.])+/(?:[-\w.])+', str(herf)))
#移除字符串首尾的[]
bookurl = booku.strip("[']")
getPdfPage(bookurl)
except Exception as reason:
logger.info("出错原因:%s" %str(reason)) #log记录
#bookurl = re.findall('https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+', str(herf))
#print(bookurl)
#print(herf[0].string) #每页书籍的名称
#每次休眠4秒钟,防止对方服务器崩溃。
time.sleep(4)
#创建文件夹
def makedir(dirNum):
#路径归为
os.chdir(cp) #切换原始路径
filepathName = str(dirNum)
isExists = os.path.exists(filepathName)
if not isExists:
os.mkdir(filepathName)
print(filepathName + '文件夹创建成功')
logger.info(filepathName + '文件夹创建成功')
file = '\%s' %filepathName #刚刚创建的那个文件夹的相对路径
path = os.path.join(cp+file) #刚刚创建的那个文件夹的绝对路径
os.chdir(path) #切换路径
def main():
print('----爬虫下载程序----')
url = "http://www.allitebooks.org/page/"
#第一页目录
dirNum = 1
mkdir(dirNum)
#os.chdir(os.path.join(cp+ '\%s'%dirNum)) #切换路径
'''测试记录:5页ok,6-31 linux下载'''
for pageNum in range(1,840): #从第1页到第2页,有840页。每页10本书
'''创建文件夹,每5页,即50本书创建一个文件夹'''
if pageNum%5 == 0:
dirNum = dirNum+1
makedir(dirNum)
#爬虫网址
print("pageNum = " + str(pageNum))
logger.info("pageNum = " + str(pageNum))
urlNew = url + str(pageNum)
getPageList(getPage(urlNew))
#testSavePdf()
if __name__=="__main__":
main()
5. 开始爬虫
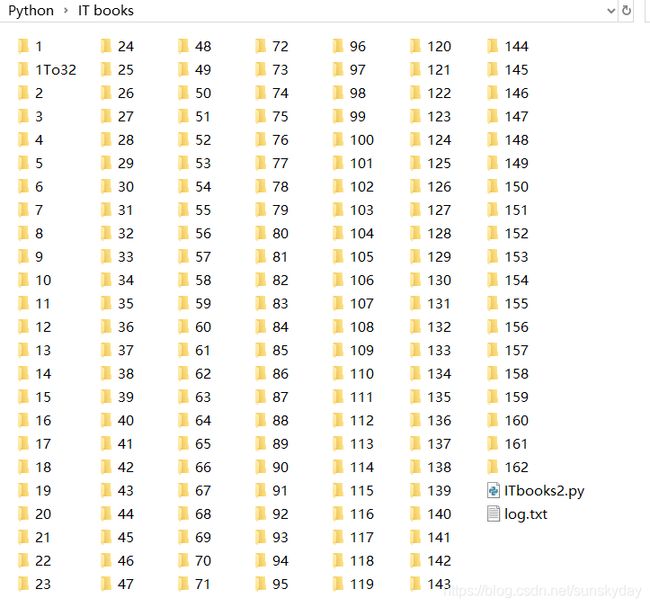
上述代码爬虫,秀一下爬虫结果。前面几个文件夹文件比较多,后面每个文件夹约50本书。有些书籍是upub文件,代码中设置了跳过下载,共有7700多本pdf资料。112G资料。建议硬盘空间够大再爬,或者只爬取一部分。

6.爬虫总结:
关注公众号可获取该次爬虫的pdf经验文档,以及爬虫代码。相关的书籍资料也可以加微信我会发给你。
白浪介绍(Geekxiaobai):
(1)关于射频、微波、天线、无线通信、智能硬件、软件编程、渗透安全、人工智能、区块链、大数据、Java、Android、C/C++、python等综合能力的培养提升。
(2)各种学习资料、学习软件分享。
========******=========******====END====******=========******==========