文本匹配一直是自然语言处理(NLP)领域一个基础且重要的方向,一般研究两段文本之间的关系。文本相似度计算、自然语言推理、问答系统、信息检索等,都可以看作针对不同数据和场景的文本匹配应用。
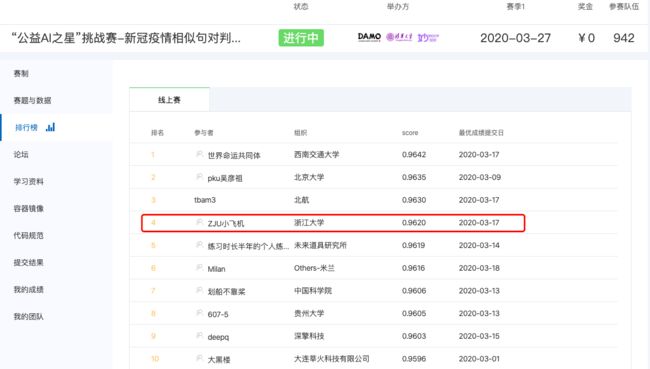
最近,我和小伙伴们参与了阿里天池““新冠疫情相似句对判定大赛”,比赛任务:根据真实场景下疫情相关的肺炎、支原体肺炎等患者提问句对,识别相似的患者问题,就是典型的文本相似匹配应用。截止3月18日,我们团队在942支参赛队伍中排名第四。
借助比赛的机会,我重新系统梳理、总结了文本匹配的经验方法。本文将着重介绍文本匹配任务中的经典网络Siamse Network,它和近期预训练语言模型的组合使用,一些论文提及的调优技巧以及在此次比赛数据集上的效果检验等。
1.Siamse 孪生网络
在正式开始介绍之前,我们先来看一个有趣的故事:孪生网络的由来!
“Siamse”中的“Siam”是古时泰国的称呼,中文译作暹罗,所以“Siamese”就是指“暹罗”人或“泰国”人。而“Siamese”在英语中是“孪生”的意思,这又是为什么呢?请看下图

十九世纪,泰国出生了一对连体婴儿“恩”和“昌”,当时的医学技术无法使两人分离出来,于是两人顽强地生活了一生。1829年他们被英国商人发现,进入马戏团,在全世界各地演出,1839年他们访问美国北卡罗莱那州成为“玲玲马戏团” 的台柱,最后成为美国公民。1843年4月13日跟英国一对姐妹结婚,恩生了10个小孩,昌生了12个。1874年,两人因病均于63岁离开了人间。他们的肝至今仍保存在费城的马特博物馆内。从此之后“暹罗双胞胎”(Siamese twins)就成了连体人的代名词,也因为这对双胞胎全世界开始重视这项特殊疾病。
由于结构具有鲜明的对称性,就像两个孪生兄弟,所以下图这种神经网络结构被研究人员称作“Siamese Network”,即孪生网络。
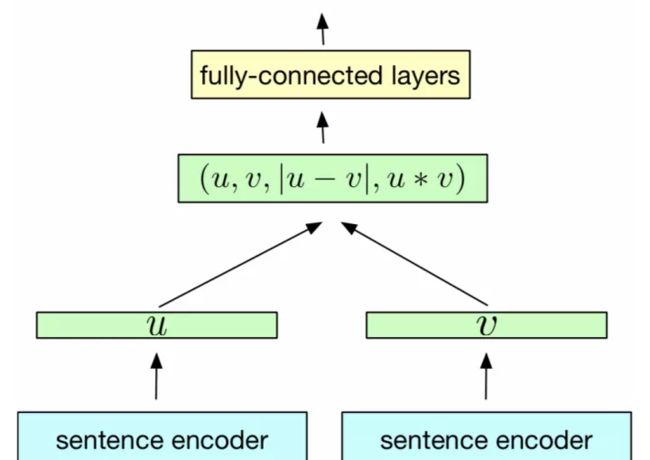
其中最能体现“孪生”的地方,在于网络具有相同的编码器(sentence encoder),即将文本转换为高维向量的部分(词嵌入)。网络随后对两段文本的特征进行交互,最后完成分类/相似预测。“孪生网络”结构简单,训练稳定,是很多文本任务不错的baseline模型。
孪生网络的具体用途是衡量两个输入文本的相似程度。例如,现在我们有两个文本 text1 和 text2,首先将文本分别输入 sentence encoder 进行特征提取和编码,将输入映射到新的空间得到特征向量 u和v;最终通过u、v的拼接组合,经过下游网络(比如全连接网络mlp)和激活函数来计算文本1和2的相似性。
整个过程有2个值得关注的点:
(1)在训练和测试过程中,模型的编码器(sentence encoder)部分是权重共享的,这也是“孪生”一词的体现之处。编码器的选择非常广泛,传统的CNN、RNN和Attention、Transformer都可以。
(2)得到特征u、v后,可以直接使用距离公式,如cosine距离、欧式距离等得到两个文本的相似度。不过更通用的做法是,基于u和v构建用于建模两者匹配关系的特征向量,然后用额外的模型(mlp等)来学习通用的文本关系函数映射;毕竟我们的场景不一定只是衡量相似性,可能还有问答、蕴含等复杂任务。
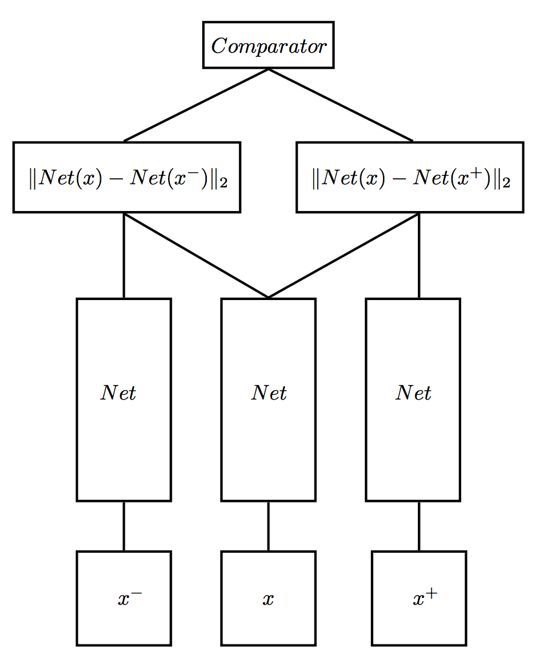
基于孪生网络,还有人提出了 Triplet network 三连体网络。顾名思义,输入由三部分组成,文本1,和1相似的文本2,和1不相似的文本3。训练的目标非常朴素,期望让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大,即减小类内距,增大类间距。
2.Sentence-Bert
自从2018年底Bert等预训练语言模型横空出世,NLP届的游戏规则某种程度上已经被大大更改了。在计算资源允许的条件下,Bert成为很多问题的优先选择;甚至有的时候,拿Bert跑一跑baseline,发现问题已经被解决了十之八九。
但是Bert的缺点也很明显,1.1亿参数量(base版本)使得预测、推理速度明显比CNN等传统网络慢了不止一个量级,对资源要求更高,也不适合处理某些任务。例如,从10000条句子中找到最相似的一对句子,由于可能的组合众多,需要完成49,995,000次推理计算;在一块现代V00GPU上使用Bert计算,将消耗65小时。
考虑到孪生网络的简洁有效,有没有可能将它和Bert强强联合取其精华呢?
当然可以,这正是论文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》的工作,首次提出了Sentence-Bert模型(以下简称SBert)。SBert在众多文本匹配工作中(包括语义相似性、推理等)都取得了最优结果。更让人惊讶的是,前文所述的从10000条句子找最相似pair的任务,SBert仅需5秒就能完成!
让我们简短回顾此前Bert是怎么处理文本匹配任务的。
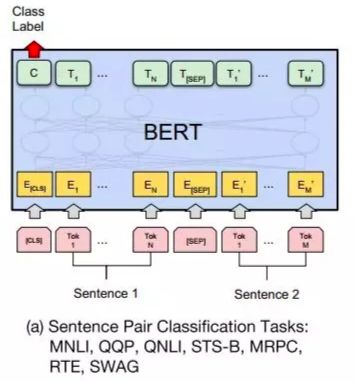
常规做法是将匹配任务转换成二分类任务(相似/不相似)。输入的两个文本拼接成一个序列(中间用一个特殊的符号“SEP”分割),经过12层(base-model)或24层(large-model)的multi-head Transformer模块编码后,将输出层的字向量取平均或者取第一个token位置“CLS”的特征作为句向量,经softmax完成最终分类。
但是论文作者 Nils Reimers 在实验中指出,这样的做法产生的结果并不理想(至少在处理语义检索和聚类问题时是如此),甚至往往比Glove词向量取平均的效果还差。

为了让Bert更好地利用文本信息,作者们在论文中提出了如下的SBert模型结构。是不是非常眼熟?对,这不就是之前见过的孪生网络嘛!
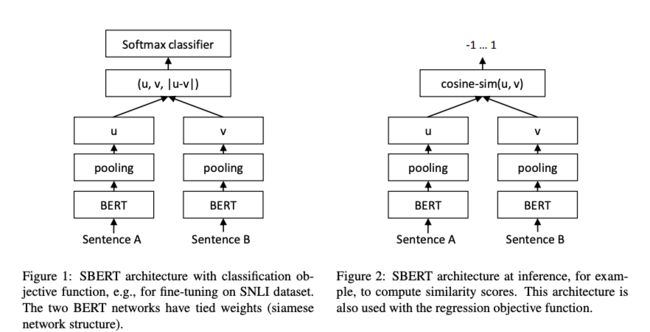
SBert沿用了孪生网络的结构,文本的encoder部分用同一个Bert来处理。之后,作者分别实验了CLS-token和2种池化策略(Avg-Pooling、Mean-Pooling),对Bert输出的字向量进行进一步特征提取、压缩,得到u、v。最后的u、v整合,作者提供了3种策略:
(1)针对分类任务,对u、v拼接组合,最后接入一个mlp网络,使用softmax进行分类输出,损失函数使用交叉熵;
(2)直接计算、输出余弦相似度;训练损失函数采取了均方根误差;
(3)如果输入的是三元组,论文种也给出了相应的损失函数。

总的来说,SBert直接使用Bert的原始权重进行初始化,在具体数据集上微调,训练过程和传统Siamse Network差异不大。但是这种训练方式能让Bert更好的捕捉句子之间的关系,生成更优质的句向量。在评估测试阶段,SBert直接使用余弦相似度来比较两个句向量之间的相似度,极大提升了推理速度。
有实验为证!作者在7个文本匹配相关的任务上做了对比实验,结果在其中的5个任务上,SBert都有更优表现。
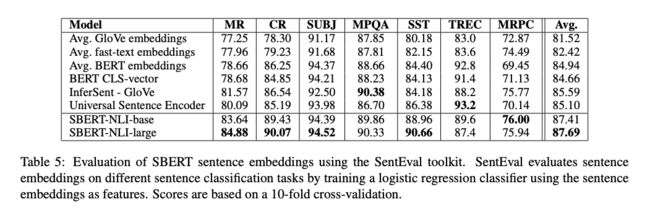
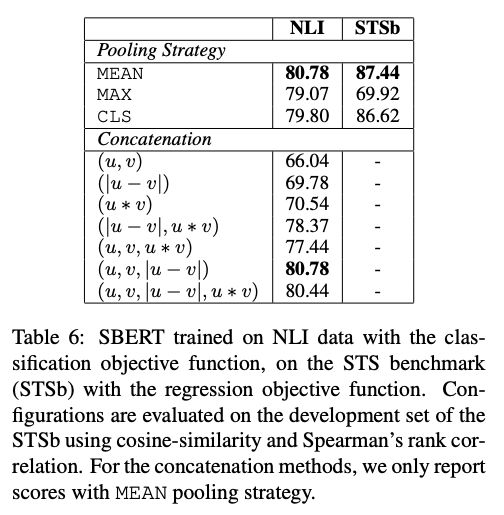
此外,作者还做了一些有趣的消融实验。使用NLI和STS为代表的匹配数据集,在进行分类目标函数训练时,作者们测试了不同的整合策略,结果显示“(u, v, |u-v|)”的组合效果最好,这里面最重要的组成部分是元素差:(|u - v|)。句向量之间的差异度量了两个句子嵌入的维度间的距离,确保相似的对更近,而不同的对更远。
此外,在Pool方法中,平均池化的效果要比另两种方法更好。
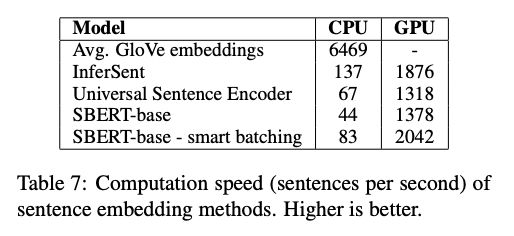
完善的实验过程帮助我们避免了不少坑。文章最后,作者对SBert和传统的一些句嵌入方法做了对比,SBert的计算效率要更高一些。其中的smart-batching是论文中的一个小trick,先将输入的文本按长度排序,这样同一个mini-batch的文本长度更加统一,padding填充处理时能显著减少填充的token。
3.在“疫情相似问句”数据集上的表现
我们将SBert模型在本次比赛的数据集上做了测试。使用数据增强后,线下的训练集和验证集数量分别是13,500和1000条句子组合。预训练模型权重选择的是roberta_wwm_large,训练过程中加入了对抗训练,通过在embedding层额外增加一些噪声点提升模型的泛化能力。
最终SBert单模型在线下验证集上的准确率是95.7%。直接使用Bert微调的方式,准确率为95.3%。
总的来说,我们做这次比赛的目的是为了积累更多的经验,尽可能将学术界的前沿算法和工业界结合,从而更好的将相关技术在实际项目中落地。
4.小结
本文总体介绍了文本匹配任务中常用的网络结构Siamse Network,以及在此基础上改进而来的Sentence-BERT模型。
Siamse Network 简洁的设计和平稳高效训练非常适合作为文本匹配任务的baseline模型,包括不限于问答对话、文本蕴含、文本相似等任务;如果孪生网络不能有效解决,可以再尝试其他更复杂的模型。SBert则充分利用了孪生网络的优点和预训练语言模型强大的特征抽取优势,在众多匹配任务上取得了最优实验结果。
抛开具体任务不谈,SBert 可以帮助我们生成更好的句向量,在一些任务上可能产生更优结果。在推理阶段,SBert直接计算余弦相似度的方式,大大缩短了预测时间;在语义检索、信息搜索等任务中预计会有不错表现。同时,得益于生成的高质量句嵌入特征,SBert也非常适合做文本聚类、新FAQ发现等工作。
Reference:Sentence-BERT pytorch开源版本
转载原文链接:https://www.jianshu.com/p/20c93094d4e9