
论文地址:https://arxiv.org/abs/1808.06414
官方代码:https://github.com/cheungdaven/DeepRec
一 为什么读这篇
看完SASRec,接着看这篇。两篇文章都是用Self-Attention做推荐的,而且都是同一天发的。看看和SASRec有什么不同吧,能不能让效果有提升。
二 截止阅读时这篇论文的引用次数
2019.7.3 9次。
三 相关背景介绍
18年8月挂到arXiv上,后来稍微改了下名字,叫《Next Item Recommendation with Self-Attentive Metric Learning》,中了AAAI19的RECNLP。和SASRec一样,算是跟进比较及时的,transformer出来一年后就应用到自己工作的领域并发了paper。4个作者都是华人,分别来自新南威尔士大学和南洋理工大学。还是这4个人,写了篇《Deep Learning based Recommender System: A Survey and New Perspectives》的综述,引用已达210次。同时开源了一个基于tf实现的深度学习推荐算法包,DeepRec,本文的实现就在这个包里。
四 关键词
Sequential Recommendation
Self-Attention
五 论文的主要贡献
1 提出结合度量学习和Self-Attention的方法来解决序列推荐问题
2 显式的控制了长短期兴趣对模型的影响
六 详细解读
0 摘要
本文提出的模型利用了self-attention机制,通过用户历史行为来预测item-item关系。self-attention能够预测用户行为轨迹上每个item的相关权重,从而学习更好的用户短期兴趣表示。模型最终在度量学习框架上训练,且同时考虑了长短期意图。
1 介绍
CNN和RNN模型应用于推荐时,在整个用户历史行为上都存在无法明确捕获item-item交互的问题。基于用户历史上下文来对item-item的关系建模的动机是符合直觉的,因为理解item之间更精细的关系,而不是简单的统一对待,这通常更为重要。总之,本文假设为模型提供inductive bias将提升表示质量,并最终改进推荐系统的效果。
本文提出的模型不仅对连续的item建模,而且对当前窗口中的所有用户行为进行学习以表示序列。因此本文模型可以视为是『局部-全局』(local-global)方法。
本文模型采用度量学习框架的形式,在训练时使用户的self-attended表示与预期item之间的距离更近。(idea:user和item的vector用上CV中那些骚套路,比如加减乘除)。本文是第一个提出基于度量学习和基于attention方法的序列推荐方法。本文主要贡献如下:
1 提出用于序列推荐的新框架。模型将self-attention网络和度量embedding相结合,为用户短期和长期意图建模
2 本文提出的模型超过了当前的SOTA,如Caser,TransRec
3 对超参做了剥离研究
2 相关工作
2.1 序列感知的推荐系统
绝大多数方法是专门为评分预估任务设计的。除了马尔科夫链,度量embedding在序列感知的推荐上也有良好的表现。
2.2 用于推荐的深度神经网络
MLP可以在对user-item关系建模时引入非线性。CNN可以从user和item的文本,视觉,语音方面提取特征。Autoencoder可以从附加信息学习显著的特征表示来增强推荐质量。RNN能够对时间动态建模。
通常,CNN和RNN需要从大量数据中学习以获得有意义的结果,然而数据稀疏性使得模型学习相当困难。
2.3 神经Attention模型
最近将Attention应用到推荐的研究有hashtag recommendation,one-class recomendation,session based recommendation。这里作者有吹嘘到,『在推荐系统里使用self-attention并非直截了当的,这证明了作者工作的新颖性』
3 模型:ATTREC
本文提出的模型称之为AttRec。用self-attention对用户短期兴趣建模,用协同度量学习对用户长期兴趣建模。
3.1 序列推荐
定义为用户集合,为item集合,其中,。定义用户行为序列为
3.2 基于Self-Attention的用户短期兴趣建模

Self-Attention模块
不像基础attention那样只能通过对整个上下文有限的知识来学习表示,self-attention能够保持上下文序列信息,并无需考虑它们的距离来捕获序列上各元素的关系。
这里和原作Transformer不同的是对Query和Key都做了ReLU的非线性变换。保持Value不变,关于这点作者给出的解释是在其他领域value通常是预训练的,用的word embedding或图像特征。而在本文模型中value的值是需要学习的。无论是增加线性还是非线性变换都会增加参数学习的困难。因为query和key是作为辅助因素,所以不像value对变换那么敏感。
value和仿射矩阵的乘积生成self-attention模块的最终权重输出。。其中可以视为用户的短期兴趣表示。为了学习单一attentive表示,将L个self-attention的Embedding取平均值作为用户短期兴趣:
有时间信号的输入Embedding
如果没有序列信号,则输入退化为a bag of embedding,同时无法保留顺序模式。本文通过位置embedding给query和key增加时间信息。时间Embedding由两个正弦信号定义得到:
TE在非线性变换之前简单的加给query和key。
3.3 用户长期兴趣建模
本文为了避免点积的问题,采用欧式距离来衡量item和user的接近程度:
3.4 模型学习
目标函数
给定时间步的短期attentive隐因子和长期偏好后,任务为预测在时间步用户将产生交互的item()。为了保持一致,对短期和长期都用欧式距离建模,使用它们的和作为最终的推荐分数:
上式中第一项是长期兴趣推荐分数,第二项是短期兴趣推荐分数。注意和都表示下一个item的embedding,不过它们的参数不同。
在某些情况下,想要预测几个items而不是只预测一个item。这样能让模型捕获序列中的跳跃行为。定义为下个用户喜欢的item。本文采用pairwise排序方法学习模型参数。将定义为个用户无行为的负样本。为了鼓励区分正负user-item对,使用基于边界的hinge loss:
上式中,表示模型参数。是边界参数,用控制模型复杂度。在稀疏数据集上也是用归一裁剪策略来限制在一个单元欧式球上:
这种正则化方法对于稀疏数据集是有用的,它削弱了维度诅咒问题同时阻止了有的数据点扩散的太远。
优化和推荐
用adaptive gradient algorithm作为优化方法。推荐的为欧式距离最小的top N。
在推荐阶段,一次计算所有user item对的推荐分数,用有效的排序算法生成排序列表。
图2是整个模型的架构

4 实验
实验设计是为了回答这2个问题:
1 提出的self-attentive序列推荐模型是否达到了SOTA?是否能处理稀疏数据集?
2 有效的关键超参是什么?
4.1 数据集
注意这里对数据集的预处理操作,丢弃不足10个行为的用户,移除掉冷启动物品。

4.2 评估指标
用hit ratio和mean reciprocal rank。一个衡量预测准确率,一个衡量排序质量。
MRR考虑预测结果中groundtruth item的位置:
4.3 比较模型
POP,BPRMF,FMC,FPMC,HRM,PRME,TransRec,Caser
神经网络方法:HRM,Caser
度量Embedding方法:PRME,TransRec
因为Fossil和GRU的效果不如Caser和TransRec,所以没有比较了。
4.4 实现细节
学习率设置为0.05,没有更进一步调优。AttRec的(U,V,X)的隐式维度统一设置为100。因为Amazon,LastFm,Movietweetings数据集的稀疏性,用norm clipping代替L2对X, V, U的正则化。self-attention模块中的非线性层用L2正则化。
正则化参数范围在,Dropout范围在,权重因子范围在,Movielens的序列长度为5,MovieTweetings为3,其余数据集为2。MovieLens的目标长度为3,其余为1。hingle loss的边界固定为0.5。
4.5 效果比较

5 模型分析及讨论
这一小节回答第二个问题。
Self-Attention的影响
典型有Self-Attention比没有要好,另外发现即使没用Self-Attention,效果也比其他方法好

聚合方法的影响
平均方法效果最好

权重的影响
用于控制长短期兴趣的贡献。从图4-a可以发现,设置说明仅考虑短期兴趣,效果比仅考虑长期兴趣()要好。取值为0.2-0.4较好,说明短期兴趣在序列推荐中扮演一个更重要的角色。
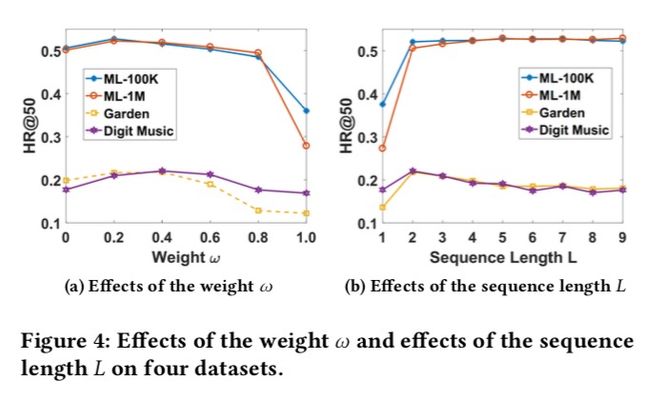
序列长度的影响
如图4-b所示,本文发现合适的高度依赖于数据集的密集程度。在MovieLens数据集上,平均每个用户有超过100个行为,设置越大效果越好。然而,在稀疏数据集上,应当设置的比较小,这也是合理的,因为随着的增加会导致训练样本的减少。
隐式维度大小的影响
从图5可以发现,本文模型在任何维度上均优于其他模型,更大的维度效果不一定更好,MC和Caser的表现是不稳定的。

模型效率

七 小结
读的过程中感觉和那篇SASRec简直就是姊妹篇,整个行文结构都非常像。本篇说白了就是在度量学习的基础上套了一个Self-Attention,不过提出的基于度量学习来做的做法相对更少见点。同时本文模型显式的利用了用户的长短期兴趣。
素质四连
要解决什么问题
序列推荐问题
用了什么方法解决
度量学习 + Self_Attention
效果如何
用HR@50和MRR做指标的SOTA,没和SASRec比
还存在什么问题
没有提预测时怎么做,感觉用到线上可能是坑。
算法背后的模式和原理
还是排列组合
八 补充
同一天在arXiv上发表的SASRec:Self-Attentive Sequential Recommendation