什么是mapping
- mapping类似数据库中的scheme定义,作用如下
- 定义索引中的字段名称
- 定义字段的数据类型,例如:字符串,数字,布尔等
- 字段,倒排索引的相关配置,analyzed or not analyzed,analyzer
- mapping会把json文档映射成lucene所属要的扁平格式
- 一个mapping属于一个索引的type
- 每个文档都属于一个type
- 一个type有一个mapping定义
- 7.0开始,不需要在mapping定义中指定type的信息
字段的数据类型
- 简单类型
- text / keyword
- date
- integer / floating
- boolean
- ipv4 / ipv6
- 复杂类型 - 对象类型和嵌套类型
- 对象类型 / 嵌套类型
- 特殊类型
- geo_point & geo_shape / percolator
什么是dynamic mapping
- 在写入文档的时候,如果索引不存在,会自动创建索引
- dynamic mapping的机制,使得我们无需手动定义mappings,elasticsearch会自动根据文档信息,推算出字段的类型
- 但是有时候推算的会不对,例如地理位置信息
- 当类型如果设置不对的时候,会导致一些功能无法正常运行,例如range查询
mappings
类型的自动识别 dynamic mapping
| json类型 | elasticsearch类型 |
|---|---|
| 字符串 | 1、匹配日期格式,设置成Date 2、匹配数字设置为float或者long,改选项默认关闭 3、设置为text,并且增加keyword子字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型锁决定 |
| 空值 | 忽略 |
能否更改mapping的字段类型
- 两种情况
- 新增加字段
- dynamic设为true时,一旦有邢增字段的文档写入,mapping也同时被更新
- dynamic设置为false,mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在_source中
- dynamic设置为strict,文档写入失败
- 对已有的字段,一旦已经有数据写入,就不再支持修改字段定义
- lucene实现的倒排索引,一旦生成后,就不允许修改
- 如果希望改变字段类型,必须使用reindex api,重建索引
- 新增加字段
- 原因
- 如果修改了字段的数据类型,会导致已被索引的索引无法被搜索
- 但是如果是增加新的字段,则不会有这样的影响
控制dynamic mapping
| 状态 | "true" | "false" | "strict" |
|---|---|---|---|
| 文档可索引 | YES | YES | NO |
| 字段可索引 | YES | NO | NO |
| mapping被更新 | YES | NO | NO |

dynamic - false
- 当gynamic被设置成false的时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃
- 当设置成strict模式的时候,数据直接写入出错
示例
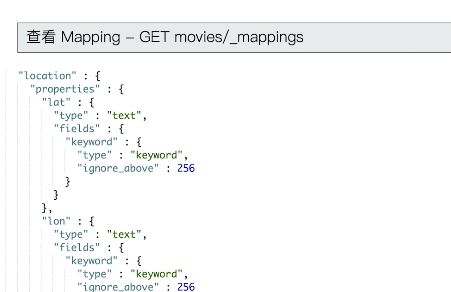
#写入文档,查看 Mapping
PUT mapping_test/_doc/1
{
"firstName":"Chan",
"lastName": "Jackie",
"loginDate":"2018-07-24T10:29:48.103Z"
}
#查看 Mapping文件
GET mapping_test/_mapping
#Delete index
DELETE mapping_test
#dynamic mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid" : "123",
"isVip" : false,
"isAdmin": "true",
"age":19,
"heigh":180
}
#查看 Dynamic
GET mapping_test/_mapping
#默认Mapping支持dynamic,写入的文档中加入新的字段
PUT dynamic_mapping_test/_doc/1
{
"newField":"someValue"
}
#该字段可以被搜索,数据也在_source中出现
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"newField":"someValue"
}
}
}
#修改为dynamic false
PUT dynamic_mapping_test/_mapping
{
"dynamic": false
}
#新增 anotherField
PUT dynamic_mapping_test/_doc/10
{
"anotherField":"someValue"
}
#该字段不可以被搜索,因为dynamic已经被设置为false
POST dynamic_mapping_test/_search
{
"query":{
"match":{
"anotherField":"someValue"
}
}
}
get dynamic_mapping_test/_doc/10
#修改为strict
PUT dynamic_mapping_test/_mapping
{
"dynamic": "strict"
}
#写入数据出错,HTTP Code 400
PUT dynamic_mapping_test/_doc/12
{
"lastField":"value"
}
DELETE dynamic_mapping_test
显式mapping - 如何显示定义一个mapping

显示定义mapping
自定义mapping的一些建议
- 可以参考api手册,纯手写
- 为了减少输入的工作量,减少出错概率,可以依照以下步骤
- 创建一个临时的index,写入一些样本数据
- 通过访问mapping api获得该临时文件的动态mapping定义
- 修改获取的动态mapping定义,使用该配置创建你的索引
- 删除临时索引
控制当前字段是否被索引
- index - 控制当前字段是否被索引。默认为true。如果设置成false,该字段不可被搜索
 index-false
index-false
![index-false]](https://upload-images.jianshu.io/upload_images/2486135-f9efacba31b0cd27.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
index options
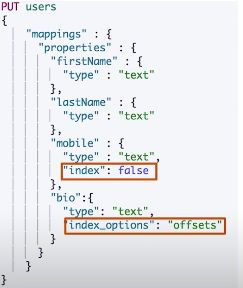
index options
- 四种不同级别的index options 配置,可以控制倒排索引记录的内容
- docs - 记录doc id
- freqs - 记录doc id和term frequencies
- positions - 记录doc id /term frequencies / term position
- offsets - doc id / term frequencies / term position / character offsets
- text类型默认记录positions,其他默认为docs
- 记录内容越多,占用存储空间越大
null value
- 需要对null值实现搜索
-
只有keyword类型支持设定null_value
 null value
null value
copy to设置
- _all在7中被copy_to所替代
- 满足一些特定的搜索需求
- copy_to将字段的数值拷贝到目标字段,实现类似_all的作用
- copy_to的目标字段不出现在_source中

copy to设置
- 数组类型
-
elasticsearch中不提供专门的数组类型,但是任何字段,都可以包含多个相同类型的数值
 数组类型
数组类型
#设置 index 为 false
DELETE users
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "text",
"index": false
}
}
}
}
PUT users/_doc/1
{
"firstName":"Ruan",
"lastName": "Yiming",
"mobile": "12345678"
}
POST /users/_search
{
"query": {
"match": {
"mobile":"12345678"
}
}
}
#设定Null_value
DELETE users
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
PUT users
多字段类型
- 多字段特性
- 厂商名字实现精确匹配
- 增加一个keyword字段
- 厂商名字实现精确匹配
- 使用不同的analyzer
- 不同语言
- pinyin字段的检索
-
还支持为搜索和索引指定不同的analyzer
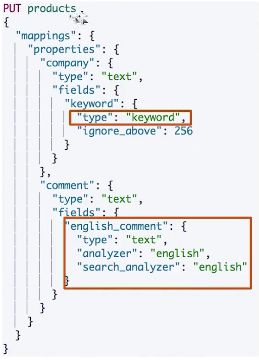 多字段类型
多字段类型
exact values vs full text (精确值和全文本)
- Exact values vs full text
- exact value:包括数字 / 日期 / 具体一个字符串(例如“apple store”)
- elasticsearch中的keyword
- exact value:包括数字 / 日期 / 具体一个字符串(例如“apple store”)
- 全文本,非结构化的文本数据
- elasticsearch中的text
exact values
自定义分词
- 当elasticsearch自带的分词器无法满足时,可以自定义分词器,通过自组合不同的组件实现
- character filter
- tokennizer
- token filter
character filters
- 在tokenizer之前对文本进行处理,例如增加删除及替换字符。可以配置多个character filters,会影响tokenizer的position和offset信息
- 一些自带的character filters
- html strip - 去除html标签
- mapping - 字符串替换
- pattern replace - 正则匹配替换
tokenizer
- 将原始的文本按照一定的规则,切分为词(term or token)
- elasticsearch内置的tokenizer
- whitespace / standard / uax_url_email / pattern / keyword / path hierarchy(路径层级)
- 可以用java开发插件,实现自己的tokenizer
token filters
- 将tokenizer输出的单词(term),进行增加,修改,删除
- 自带的token filters
- lowercase / stop / synonym(添加近义词)
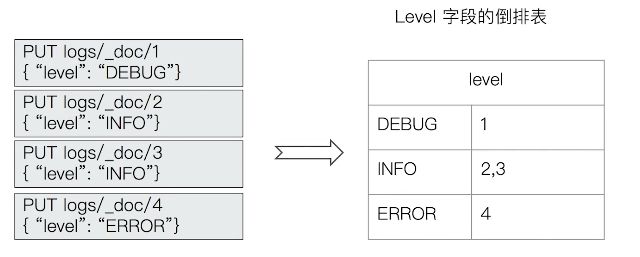
设置一个customer analyzer

customer analyzer
PUT logs/_doc/1
{"level":"DEBUG"}
GET /logs/_mapping
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "hello world"
}
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
#使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
//char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ ":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
// white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
// whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The rain in Spain falls mainly on the plain."]
}
//remove 加入lowercase后,The被当成 stopword删除
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
//正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}
自定义自己的analyzer 分词器
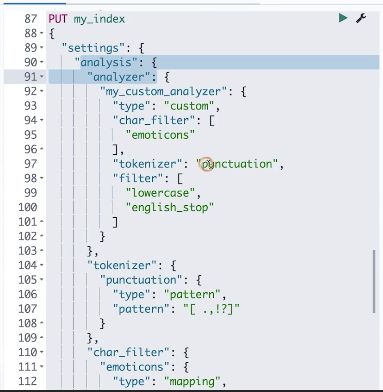
image.png
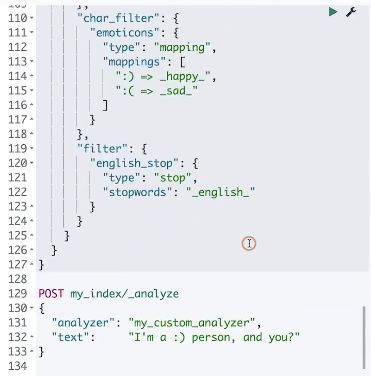
image.png