超参的处理
基本原则:超参数而言,没有简单易行的方法来设置,只能依靠理论知识背景和调试经验,不断的试错,达到性能和准度的最佳配比。
常见参数:
学习率(learning rate)
批量大小(batch size)
动量( momentum)
权重衰减(weight decay)
基础背景知识:
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
一般性调优:
深度学习模型充满了超参数,在如此高维空间中找到这些参数的最佳值并不是一项容易的挑战。在讨论找到最佳超参数的方法之前,首先了解这些超参数:学习率、批量大小、动量和权重衰减。这些超参数类似于开关旋钮,可以在模型训练期间进行调整。为了使得模型能够获得最佳结果,需要找到这些超参数的最佳值。
梯度下降
梯度下降是训练机器学习算法中常用的优化技术。训练机器学习算法的主要目的是调整权重w以最小化损失函数或成本函数。通过最小化成本函数,就可以找到产生最佳模型性能的参数[1]。
回归问题的典型损失函数图类似于碗的形状,如下所示。

在梯度下降算法中,首先随机模型参数,并计算每次学习迭代的误差,不断更新模型参数以更接近导致最小成本的值。梯度下降算法将梯度乘以一个标量(学习率),以确定下一个点。
如果用dW和db作为更新参数W和b的梯度,梯度下降算法如下:

如果学习率很小,那么训练会更加可靠,但花费的时间也更多,因为每次移动的步长很小。
如果学习率很大,那么训练可能不收敛。权重变化可能很大,以至于优化器错失最优化并使得损失变大。因此,最终目标是找到可以快速获得最小损失的最佳学习率。

一般而言,可以将梯度下降视为在山谷中滚动的球。希望它能够在停留山脉的最深处,但有时可能会出错。

根据球开始滚动的位置,它可能会停留在山谷的底部。但不是最低的一个,这称为局部最小值。初始化模型权重的方式可能会导致局部最小值。为了避免这种情况,可以随机始化权重向量。
用2-D表示损失面,如下所示:

红点是全局最小值,希望能够达到这一点。使用梯度下降方法,更新将如下所示:

随着梯度下降的每次迭代,向上和向下振荡移动到局部最优。如果使用更大的学习率,那么垂直振荡将具有更高的幅度。这种垂直振荡会减慢梯度下降过程,并阻止设置更大的学习率,而学习速率太小会使梯度下降变慢。
目标是希望在垂直方向上学习更慢,在水平方向上学习更快,这将有助于更快地达到全局最小值。
为了实现这一点,可以使用具有动量的梯度下降 [2]。
梯度下降:

在动量方面,采用dW和db的指数加权平均值,而不是每个时期单独使用dW和db。

其中β是另一个称为动量的超参数,取值范围从0到1。它设置先前值的平均值与当前值之间的权重,以计算新的加权平均值。
计算指数加权平均值后更新参数。

通过使用dW和db的指数加权平均值,将垂直方向上的振荡平均化为接近零。然而,在水平方向上,所有导数都指向水平方向的右侧,因此水平方向上的平均值仍然相当大。它允许算法采用更直接的路径朝向局部最优并阻尼垂直振荡。基于此,算法最终会在局部最优处进行几次迭代。

有三种梯度下降的方法:
批量梯度下降(Batch gradient descent: )
使用所有的训练实例来更新每次迭代中的模型参数;
通过准确估计误差梯度来缓慢收敛;
随机梯度下降(Stochastic Gradient Descent)
在每次迭代中仅使用单个训练实例更新参数。训练实例通常是随机选择的;
通过估计错误梯度快速收敛;
小批量梯度下降(Mini-batch Gradient Descent)
一次取b个示例:训练时不是使用所有的示例,而是将训练集划分为称为批处理的较小尺寸,每次取b个示例用来更新模型参数;
小批量梯度下降试图在随机梯度下降的稳健性和批量梯度下降的效率之间找到平衡;
小批量梯度下降是深度学习领域中最常用的梯度下降方法。缺点是它引入了额外的超参数'b';
搜索最佳配置的方法:网格搜索和随机搜索
网格搜索
在网格搜索[3]中,尝试每个可能的参数配置。
步骤:
定义一个n维网格,其中每个都为超参数映射。例如n =(learning_rate, batch_size);
对于每个维度,定义可能值的范围:例如batch_size = [4,8,16,32],learning_rate = [0.1,0.01,0.0001];
搜索所有可能的配置并等待结果建立最佳配置:例如C1 =(0.1,4) - > acc = 92%,C2 =(0.01,4) - > acc = 92.3%等;
随着维度的增多,搜索将在时间复杂度上发生爆炸。当维度小于或等于4时,通常使用这种方法。虽然它最终能保证找到最佳配置,但它仍然不是优选的,最好是使用随机搜索。
随机搜索
随机搜索[4]首先从配置空间中随机选取一个点,使用随机搜索更广泛地探索超参数空间。这可以在更少的迭代次数中找到最佳配置。例如:

在网格布局中,很容易注意到,即使已经训练了9个模型,而每个变量只使用了3个值。然而,使用随机搜索,我们不太可能不止一次地选择相同的变量,将使用9个不同的值为每个变量训练9个模型。更多详细分析,请参阅该文。
尽管随机搜索比网格搜索表现更好,但这两种方法在计算上仍然是昂贵且耗时的。在2018年,Leslie在其经典论文中提出了关于识别最佳超参数的各种方法的详细报告[5]。其中最好的方法是基于通过检查测试/验证损失以寻找欠拟合和过拟合的曲线来找到二者之间的平衡,以便争取最佳的超参数集合。
超参数调整过程无异于在钢丝上走路,以实现欠拟合和过拟合之间的平衡。
方法
1.通过在训练早期监控验证/测试损失,观察分析训练曲线,通过几个时期来调整模型结构和超参数;
2.在训练过程早期测试或验证损失的欠拟合或过拟合对于调整超参数是有用的;
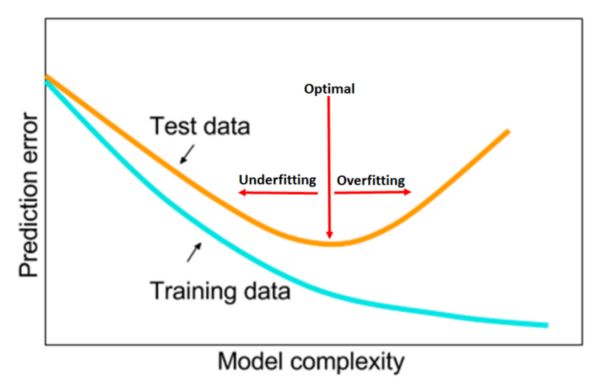
寻找最佳超参数
学习率(LR)
如果学习率太小,则可能发生过拟合。较高的学习率有助于正则训练,但如果学习率过大,训练就会出现误差。因此,可以进行短距离网格搜索以找到收敛或发散的学习率,但还有另一种方法称为“周期性学习率(CLR)”。
实验表明,训练期间使用不同的学习率总体上是有益的,因此建议在一个取值范围内周期性地改变学习率,而不是将其设定为固定值。让学习率在一定范围内变化,而不是采用逐步、固定或指数级减少学习率值。即设置好最小和最大边界,学习率在这些边界之间循环变化。

如何估算合理的最小和最大边界值?
LR范围测试:运行模型几个epoch,同时让学习率在高低学习率值之间线性增加。对于浅层的3层架构,最大设置为0.01,而对于resnet这样的网络,学习率最大可以设置为3.0。

从一轮循环确定最大学习速率,并将最大值的十分之一作为最小学习率的表现也不错[6]。
批量大小(Batch size)
与学习率不同,其值不影响计算训练时间。批量大小受硬件内存的限制,而学习率则不然。建议使用适合硬件内存的较大批量大小,并使用更大的学习速率。
如果服务器有多个GPU,则总批量大小是单个GPU上的批量大小乘以GPU的数量。
周期性动量(Cyclical Momentum)
动量和学习率密切相关。最佳学习率取决于动量,而动量又取决于学习率。与学习率一样,在不引起训练不稳定的情况下尽可能设置大的动量值是很有价值的。
查找学习率和动量组合的步骤
使用循环学习率:最佳训练步骤是循环增加学习率,初始化一个小的学习率,使其开始收敛,并减少周期动量。当学习率增加时,使用递减的循环动量加快收敛并且当稳定训练后,并设置更大的学习率;
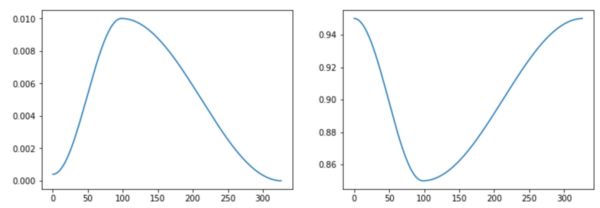
左:学习率周期,右:动量周期
使用恒定学习率:如果使用恒定的学习率,那么大的恒定动量(即0.9-0.99)将起到伪增加学习率的作用并加速训练。但是,使用过大的动量值会导致训练结果很差。
无论是循环学习速率还是恒定学习速率,可以尝试在0.9到0.99范围内设定动量值,并从中选择一个表现最佳值。
权重衰减
体重衰减是正则化的一种形式,它在训练中起着重要作用,因此需要适当设定[7]。权重衰减被定义为将每个时期的梯度下降中的每个权重乘以因子λ(0 <λ<1)。
一般而言,可以测试权重衰减值为1 /10³、1 /10⁴、1 /10⁵和0。较小的数据集和模型结构设置较大的权重衰减值,而较大的数据集和更深的模型结构设置较小的值。
如果使用恒定的学习率而不是使用学习率范围进行搜索,则最佳权重衰减会有所不同。由于较大的学习率提供正则化,因此较小的权重衰减值是最佳的。
总结
学习率:
执行学习率范围测试以确定“大”的学习率。
*一轮测试确定最大学习速率,将最小学习速率设置为最大学习速率的十分之一。
动量:
用短期动量值0.99、0.97、0.95和0.9进行测试,以获得动量的最佳值;
如果使用周期学习率计划,最好从该最大动量值开始循环设置动量,并随着学习率的增加而减小到0.8或0.85;
批量大小:
根据硬件条件使用尽可能大的批量大小,然后比较不同批量大小的性能;
小批量添加正规化的效果大,而大批量添加的正则化效果小,因此在适当平衡正规化效果的同时利用好它;
使用更大的批量通常会更好,这样就可以使用更大的学习率;
权重衰减:
网格搜索以确定适当的幅度,但通常不需要超过一个有效数字精度;
更复杂的数据集需要较少的正则化,因此设置为较小的权重衰减值,例如10^-4、10^-5、10^-6、0;
浅层结构需要更多的正则化,因此设置更大的权重衰减值,例如10^-2、10^-3、10^-4;