经常见到“描述一下从输入URL到页面加载的过程?”这样的题目吧,简单的一个问题,考的却是一整段前端知识体系。所以,让我们从在浏览器地址栏输入起,到页面完整的出现在屏幕前,回顾一下前端体系中很重要的一部分,浏览器。
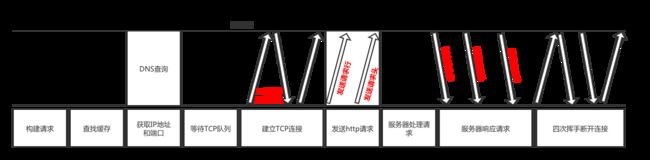
下面一张是自制流程图,从这张流程图开始,本文主要内容也是围绕整张图进行详细描述的。
竖向为请求流程,横向为详细描述

1、从用户输入开始
当用户在浏览器的地址栏中输入搜索文字后,地址栏会判断用户输入的搜索内容,如果搜索内容,那么会利用自身的搜索引擎合成带搜索内容的一系列url。
如果判断用户输入的是url,就会请求这个url地址,但是在请求url之前,会先在当前页面执行beforeunload,beforeunload允许用户在退出当前页面之前执行一些操作,比如询问是否有离开当前页面等,因此可以通过beforeunload来取消导航。如果用户确认离开当前页面,那么当前标签页上的图标会变成加载状态,此时页面还没有进行替换,等待着请求url的返回。
2、查找缓存
在真正发起网络请求之前,会先在浏览器缓存中查询是否有要请求的文件,也就是是否在本地保存了资源副本,如果保存了,那么可以拦截请求,返回该资源的副本,并直接结束请求,不会再重新请求服务器。这也是为什么很多站点第二次打开速度会很快。
浏览器缓存的优点:
1、减少服务器压力
2、获取资源的时间减少,提升性能,快速加载资源
如果没有缓存,那么会进入网络请求流程。
获取ip地址和端口
判断当前域名是否解析过,如果当前域名解析过,可以直接使用对应的ip进行网络请求,如果没有被解析过浏览器会请求 DNS 获取域名对应的 IP,多一次查询请求。
如果url中没有特意指明端口号,那么默认端口号是80
前后端的http交互中,使用缓存能很大程度上的提升效率,而且基本上对性能有要求的前端项目都是必用缓存的。
强缓存与弱缓存
缓存可以简单的划分成两种类型: 强缓存( 200fromcache)与 协商缓存( 304)。
区别简述如下:
强缓存(
200fromcache)时,浏览器如果判断本地缓存未过期,就直接使用,无需发起http请求协商缓存(
304)时,浏览器会向服务端发起http请求,然后服务端告诉浏览器文件未改变,让浏览器使用本地缓存
对于协商缓存,使用 Ctrl+F5强制刷新可以使得缓存无效。但是对于强缓存,在未过期时,必须更新资源路径才能发起新的请求(更改了路径相当于是另一个资源了,这也是前端工程化中常用到的技巧)。
缓存头部简述
上述提到了强缓存和协商缓存,那它们是怎么区分的呢?答案是通过不同的http头部控制。
先看下这几个头部:
If-None-Match/E-tag、If-Modified-Since/Last-Modified、Cache-Control/Max-Age、Pragma/Expires
这些就是缓存中常用到的头部,这里不展开。仅列举下大致使用。
属于强缓存控制的:
(http1.1)Cache-Control/Max-Age(http1.0)Pragma/Expires
注意: Max-Age不是一个头部,它是 Cache-Control头部的值。
属于协商缓存控制的:
(http1.1)If-None-Match/E-tag(http1.0)If-Modified-Since/Last-Modified
可以看到,上述有提到 http1.1和 http1.0,这些不同的头部是属于不同http时期的。
再提一点,其实HTML页面中也有一个meta标签可以控制缓存方案- Pragma。
不过,这种方案还是比较少用到,因为支持情况不佳,譬如缓存代理服务器肯定不支持,所以不推荐。
头部的区别
首先明确,http的发展是从http1.0到http1.1,而在http1.1中,出了一些新内容,弥补了http1.0的不足。
http1.0中的缓存控制:
Pragma:严格来说,它不属于专门的缓存控制头部,但是它设置no-cache时可以让本地强缓存失效(属于编译控制,来实现特定的指令,主要是因为兼容http1.0,所以以前又被大量应用)Expires:服务端配置的,属于强缓存,用来控制在规定的时间之前,浏览器不会发出请求,而是直接使用本地缓存,注意,Expires一般对应服务器端时间,如Expires:Fri,30Oct199814:19:41If-Modified-Since/Last-Modified:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-Modified-Since,而服务端的是Last-Modified,它的作用是,在发起请求时,如果If-Modified-Since和Last-Modified匹配,那么代表服务器资源并未改变,因此服务端不会返回资源实体,而是只返回头部,通知浏览器可以使用本地缓存。Last-Modified,顾名思义,指的是文件最后的修改时间,而且只能精确到1s以内
http1.1中的缓存控制:
Cache-Control:缓存控制头部,有no-cache、max-age等多种取值Max-Age:服务端配置的,用来控制强缓存,在规定的时间之内,浏览器无需发出请求,直接使用本地缓存,注意,Max-Age是Cache-Control头部的值,不是独立的头部,譬如Cache-Control:max-age=3600,而且它值得是绝对时间,由浏览器自己计算If-None-Match/E-tag:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-None-Match,而服务端的是E-tag,同样,发出请求后,如果If-None-Match和E-tag匹配,则代表内容未变,通知浏览器使用本地缓存,和Last-Modified不同,E-tag更精确,它是类似于指纹一样的东西,基于FileEtagINodeMtimeSize生成,也就是说,只要文件变,指纹就会变,而且没有1s精确度的限制。
Max-Age相比Expires?
Expires使用的是服务器端的时间,但是有时候会有这样一种情况-客户端时间和服务端不同步。那这样,可能就会出问题了,造成了浏览器本地的缓存无用或者一直无法过期,所以一般http1.1后不推荐使用 Expires。而 Max-Age使用的是客户端本地时间的计算,因此不会有这个问题,因此推荐使用 Max-Age。
注意,如果同时启用了 Cache-Control与 Expires, Cache-Control优先级高。
E-tag相比Last-Modified?
Last-Modified:
表明服务端的文件最后何时改变的
它有一个缺陷就是只能精确到1s,
然后还有一个问题就是有的服务端的文件会周期性的改变,导致缓存失效
而 E-tag:
是一种指纹机制,代表文件相关指纹
只有文件变才会变,也只要文件变就会变,
也没有精确时间的限制,只要文件一遍,立马E-tag就不一样了
如果同时带有 E-tag和 Last-Modified,服务端会优先检查 E-tag。
各大缓存头部的整体关系如下图:

3、等待TCP队列
虽然已经准备好了ip和端口,但是同一个域名同时最多只能建立 2-8个 TCP 连接,如果超过了数量,那么后续请求进入排队等待状态,直至进行中的请求完成。
如果没有超过限定数量,那么可以建立TCP连接。
4、建立TCP连接
在建立一个TCP连接时,需要经过三次握手,也就是说客户端和服务端总共需要发三个数据包确认连接的建立。
三次握手比较抽象的描述:
客户端:hello,你是server么?
服务端:hello,我是server,你是client么
客户端:yes,我是client
5、发送请求
建立连接以后,浏览器和服务器就可以进行通信了,浏览器会发送请求信息给服务器
请求报文的一般结构

请求行:包括了请求方法,请求url,以及http协议版本
请求头:浏览器的一些基础信息,浏览器版本,域名,cookie等
请求体:POST请求时,数据在请求体中传给服务器
发送请求行就是描述 用什么样的请求方式,请求什么资源。
常见的请求方法:get 和 post
区别1:使用场景
get 请求主要用于信息获取,安全且幂等,反复读取不会对访问的数据有副作用,可以对get请求的数据做缓存,这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),或者做到server端(用Etag,至少可以减少带宽消耗)
post请求主要用于给服务端发送信息,比如from表单等,所以post是有副作用的,不幂等的,不幂等也就意味着不能随意多次执行。因此也就不能缓存。比如通过POST下一个单,服务器创建了新的订单,然后返回订单成功的界面。这个页面不能被缓存。
幂等 (idempotent、idempotence)是一个数学或计算机学概念,常见于抽象代数中。幂等有以下几种定义:对于单目运算,如果一个运算对于在范围内的所有的一个数多次进行该运算所得的结果和进行一次该运算所得的结果是一样的,那么我们就称该运算是幂等的。比如绝对值运算就是一个例子,在实数集中,有abs(a) =abs(abs(a)) 。 对于双目运算,则要求当参与运算的两个值是等值的情况下,如果满足运算结果与参与运算的两个值相等,则称该运算幂等,如求两个数的最大值的函数,有在在实数集中幂等,即max(x,x) = x 。
区别2:携带数据格式
get请求携带参数会把参数信息拼接在url上,在地址栏可以明确看到
post请求携带参数时会被浏览器用编码到HTTP请求的body里。浏览器发出的POST请求的body主要有有两种格式,一种是application/x-www-form-urlencoded用来传输简单的数据,大概就是"key1=value1&key2=value2"这样的格式。另外一种是传文件,会采用multipart/form-data格式
区别3:传输数据的大小
http协议对传输的数据大小没有显示,也没有对url长度进行显示,但是特定的浏览器和服务器对url的长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
因此对于GET提交时,传输数据就会受到URL长度的限制。所以get不适合传输大型数据
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
为啥要限制呢?如果写过解析一段字符串的代码就能明白,解析的时候要分配内存。对于一个字节流的解析,必须分配buffer来保存所有要存储的数据。而URL这种东西必须当作一个整体看待,无法一块一块处理,于是就处理一个请求时必须分配一整块足够大的内存。如果URL太长,而并发又很高,就容易挤爆服务器的内存;同时,超长URL的好处并不多,我也只有处理老系统的URL时因为不敢碰原来的逻辑,又得追加更多数据,才会使用超长URL。
区别4、安全
post的安全级别比get的安全性高,这个安全指的是通过GET提交数据,参数将明文出现在URL上,可能造成Cross-site request forgery攻击
区别5:tcp/ip层面
get和post虽然本质都是tcp/ip,但是两者除了在http层面外,在tcp/ip层面也是有区别的,get会产生一个数据包,post产生两个。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
常见请求头中的参数详解:
Accept: 接收类型,表示浏览器支持的MIME类型(对标服务端返回的Content-Type)
Accept-Encoding:浏览器支持的压缩类型,如gzip等,超出类型不能接收
Content-Type:客户端发送出去实体内容的类型
Cache-Control: 指定请求和响应遵循的缓存机制,如no-cache
If-Modified-Since:对应服务端的Last-Modified,用来匹配看文件是否变动,只能精确到1s之内,http1.0中
Expires:缓存控制,在这个时间内不会请求,直接使用缓存,http1.0,而且是服务端时间
Max-age:代表资源在本地缓存多少秒,有效时间内不会请求,而是使用缓存,http1.1中
If-None-Match:对应服务端的ETag,用来匹配文件内容是否改变(非常精确),http1.1中
Cookie:有cookie并且同域访问时会自动带上
Connection:当浏览器与服务器通信时对于长连接如何进行处理,如keep-alive
Host:请求的服务器URL
Origin:最初的请求是从哪里发起的(只会精确到端口),Origin比Referer更尊重隐私
Referer:该页面的来源URL(适用于所有类型的请求,会精确到详细页面地址,csrf拦截常用到这个字段)
User-Agent:用户客户端的一些必要信息,如UA头部等
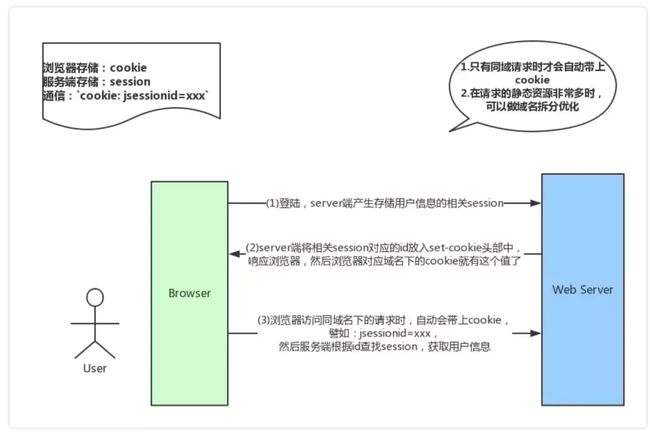
cookie也是在发送请求时比较重要的一环
简答来说,如果服务器发送的响应头中有set-cookie字段,那么浏览器会将该字段保存到本地,下次再请求服务器时会自动在请求头中加入cookie值之后再发送出去,服务器接收到客户端发送来的cookie后,会比对信息,得到用户状态或者信息。
一般来说,cookie是不允许存放敏感信息的(千万不要明文存储用户名、密码),因为非常不安全,如果一定要强行存储,首先,一定要在cookie中设置 httponly(这样就无法通过js操作了),另外可以考虑rsa等非对称加密(因为实际上,浏览器本地也是容易被攻克的,并不安全)。
关于cookie的交互,可以看下图总结:
https
发送请求还可以使用https,https就是安全版本的http,也就是在请求前,会建立ssl链接,确保接下来的通信都是加密的,无法被轻易截取分析
HTTP + 加密 + 认证 + 完整性保护 == HTTPS
https通信
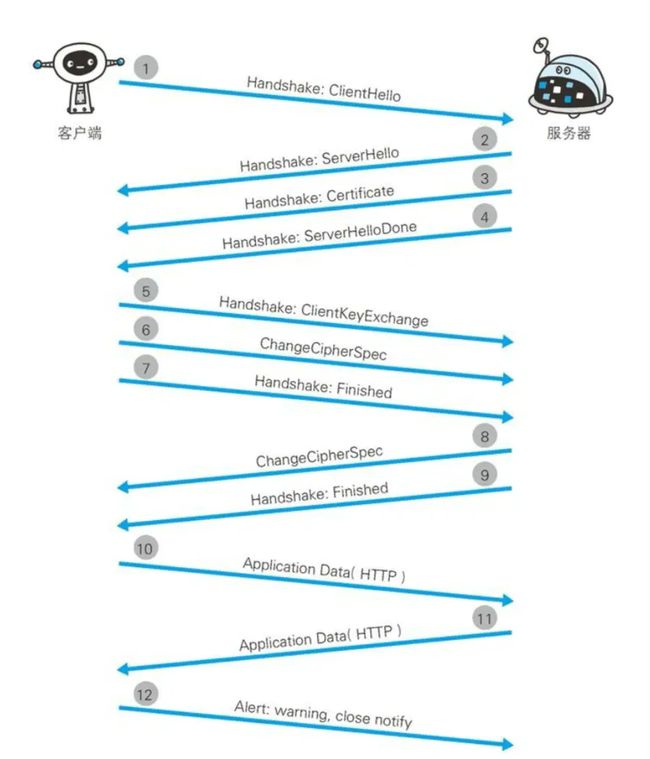
1、客户端用过发送Client Hello 报文开始SSL通信。报文中包含客户端支持的SSL的指定版本,加密组件列表(所使用的加密算法几密匙长度等)。
2、服务器可进行SSL时,会以Server Hello报文作为应答,和客户端一样,在报文中包含SSL版本以及加密组件,服务器的加密组件内容是从接收到的客户端加密组件内筛选出来的。
3、之后服务器发送Certificate报文,报文中包含公开密匙整数。
4、最后服务器发送Server Hello Done报文通知客户端,最初阶段的SSL握手协商部分结束。
5、SSL第一次握手结束之后,客户端已Client Key Exchange报文作为回应,报文中包含通信加密中使用的一种被称为Pre-master secret 的随机密码串,该报文已经用步骤3中的公开密匙进行加密。
6、接着客户端继续发送Change Cipher Spec报文,该报文提示服务器,在此报文之后的通信会采用Pre-master secret 密匙加密。
7、客户端发送Finished报文。该报文中包含连接至今全部报文的整体校验值,这次握手协商是否能成功,要以服务器是否能够正确解密该报文作为判定标准。
8、服务器同样发送Change Cipher Spec报文。
9、服务器同样发送Finished报文。
10、服务器和客户端的Finishd报文交换完毕之后,SSL连接就算建立完成,当然,通信会受到SSL的保护,从此处开始进行应用层协议的通信,即发生http请求。
11、应用层协议通信,即发送http响应。
12、最后由客户端断开连接,断开连接时,发送close notify报文。
HTTPS比HTTP慢2到100倍
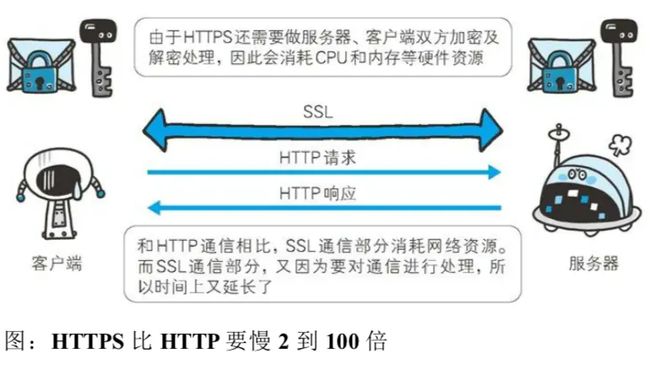
SSL的慢分两种,一种是指通信慢,另一种是由于大量消耗CPU及内存等资源,导致处理速度变慢。
6、服务端处理请求
一般有的后端是有统一的验证的,如安全拦截,跨域验证
如果这一步不符合规则,就直接返回了相应的http报文(如拒绝请求等)
然后当验证通过后,才会进入实际的后台代码,此时是程序接收到请求,然后执行(譬如查询数据库,大量计算等等)
等程序执行完毕后,就会返回一个http响应包(一般这一步也会经过多层封装)
然后就是将这个包从后端发送到前端,完成交互。
请求中的小插曲,就是浏览器在接收服务器返回的响应头后,如果发现返回的状态码是301或301,那么说明服务器需要浏览器重定向到其他url,这时会从响应头的Location 字段里面读取重定向的地址,然后再发起新的 HTTP 或者 HTTPS 请求,一切又重头开始了。
如果响应行是 200,那么表示浏览器可以继续处理该请求。
常见的响应数据结构
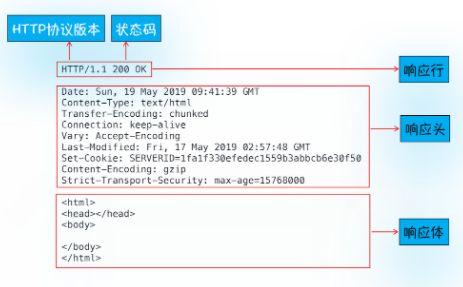
响应行:协议版本、状态码等
响应头:包含了服务器的一些信息,如果返回数据的时间,返回数据类型(JSON,HTML,流媒体等类型),以及服务器要在客户端保存的cookie等信息。
响应体:响应体通常是实际内容。
状态码
状态码是很重要的一部分,因为很多时候都是用过状态码来判断响应状态,当请求出错时,状态码能帮助快速定位问题
不同范围状态的状态码代表的大致含义:
1xx——指示信息,表示请求已接收,继续处理
2xx——成功,表示请求已被成功接收、理解、接受
3xx——重定向,要完成请求必须进行更进一步的操作
4xx——客户端错误,请求有语法错误或请求无法实现
5xx——服务器端错误,服务器未能实现合法的请求
当然不同范围还有更具体的解释,再详细列举几个常见的状态码,其他可自行百度
200(OK):表示从客户端发送来的请求在服务器端被正常处理了。
204(No Content):该状态码表示服务器接受的请求已成功处理,但在返回的相应报文中不含实体的主体部分,另外也不允许返回任何实体的主体,比如,当从浏览器发送请求处理后,返回204相应,那么浏览器显示的页面不发生更新。
206(Partial Content):该状态码表示客户端进行了范围请求,而服务器成功执行了这部分get请求,响应报文中包含了由Content-Range指定范围的实体内容。
301(Moved Permanently):永久性重定向,该状态码表示请求的资源已经被分配了新的URL,以后应使用资源现在所指的URL。
302(Found):临时性重定向,该状态码表示请求的资源已经被分配了新的URL,希望用户(本次)能使用新的URL访问。
303(See Other):该状态码表示由于请求对应的资源存在另一个URL,应使用GET方法定向获取请求的资源。303状态码和302状态码有着相同的功能,但是303状态码明确表示客户端应该采用GET方法获取资源,这点与302状态码有区别。
304(Not Modified):该状态码表示客户端发送附带条件的请求时,服务器运气请求访问资源但为满足条件的情况。304状态码返回时,不包含任何相应的主体部分。304虽然被划分在3xx类别中,但是和重定向没有关系。
307(Temporary Redirect):临时重定向,该状态码与302有着相同的含义,尽管302标准禁止post变为get,但实际上使用时大家并不遵守。
400 Bad Request:该状态码表示请求报文中存在语法错误,当错误发生时,需修改请求的内容后再次发送请求,另外,浏览器会像200一样
对待该状态码。
401 Unauthorized:该状态码表示发送请求需要通过HTTP认证的认证信息,另外若之前已经进行过一次请求,则表示用户认证失败。
403 Forbidden:该状态码表示对请求资源的访问被服务器拒绝了,服务器端没有必要给出拒绝的详细理由,但如果想作说明的话,可以在实体的主体部分对原因进行描述,这样就能让用户看到了。
404 Not Found:该状态码表明服务器上无法找到请求的资源,初次之外,可以在服务器端拒绝请求且不想说明理由时使用。
500 Internal Server Error:该状态码表明服务器端在执行请求时发生了错误。也有可能是web应用存在bug或某些临时故障。
503 Service Unavailable:改状态码表明服务器暂时处理超负载或正在进行停机维护,现在无法处理请求。
响应头
常见响应头
Access-Control-Allow-Headers: 服务器端允许的请求Headers
Access-Control-Allow-Methods: 服务器端允许的请求方法
Access-Control-Allow-Origin: 服务器端允许的请求Origin头部(譬如为*)
Content-Type:服务端返回的实体内容的类型
Date:数据从服务器发送的时间
Cache-Control:告诉浏览器或其他客户,什么环境可以安全的缓存文档
Last-Modified:请求资源的最后修改时间
Expires:应该在什么时候认为文档已经过期,从而不再缓存它
Max-age:客户端的本地资源应该缓存多少秒,开启了Cache-Control后有效
ETag:请求变量的实体标签的当前值
Set-Cookie:设置和页面关联的cookie,服务器通过这个头部把cookie传给客户端
Keep-Alive:如果客户端有keep-alive,服务端也会有响应(如timeout=38)
Server:服务器的一些相关信息
浏览器会根据响应数据做出不同的操作,比如返回响应头的Content-Type是text/html,说明返回的html格式,会进行页面展示,Content-Type值是application/octet-stream,显示数据是字节流类型的,通常情况下,浏览器会按照下载类型来处理该请求。
但如果是 HTML,那么浏览器则会继续进行导航流程。由于 Chrome 的页面渲染是运行在渲染进程中的,所以接下来就需要准备页面渲染,下一篇我们会具体介绍浏览器是如何渲染一个页面的。
7、断开连接
通常一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览器或者服务器在其头部加入了Connection:Keep-Alive,那么 TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度
keep-alive不会永远保持,它有一个持续时间,一般在服务器中配置(如apache),另外长连接需要客户端和服务器都支持时才有效。
等数据传输完毕,‘四次挥手’来断开连接。
四次挥手的步骤(抽象派)
主动方:我已经关闭了向你那边的主动通道了,只能被动接收了
被动方:收到通道关闭的信息
被动方:那我也告诉你,我这边向你的主动通道也关闭了
主动方:最后收到数据,之后双方无法通信
最后根据一张图,总结下今天的内容
参考文献
HTTP POST GET 本质区别详解
GET 和 POST 到底有什么区别?
从输入URL到页面加载的过程?由一道题完善自己的前端知识体系
《图解http》读书摘要
浏览器工作原理与实践