熊猫包是一个非常好用滴数据分析包~
加载数据
1、导入pandas库
import pandas as pd
2、导入CSV或者XLSX文件
(导入csv文件时,将header设置为None对于有表头的数据会报错,应改为header=0)
#此次导入的是泰坦尼克号数据集...
df = pd.read_csv("titanic.csv", header=0)
3、显示前5行数据
df.head() #head的默认size大小是5,所以会返回5个数据
探索性分析
1、叙述性分析
df.describe()
describle会输出一些统计性的数据,count、mean、std、min....

2、直方图
df["Age"].hist() #输出age的直方图

3、唯一值
df["Embarked"].unique() #输出Embarked独树一帜的量
df["embarked"].unique()
output:
array(['S', 'C', nan, 'Q'], dtype=object)
4、按列名查看
df["Name"].head()

5、筛选数据
df[df["sex"]=="female"].head() # only the female data appear
6、排序
df.sort(,) #第一个参数是某列,ascending(meaning:上升) =False代表降序输出
df.sort_values("age", ascending=False).head()
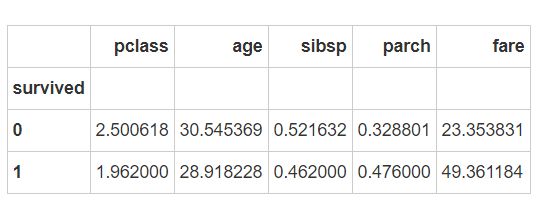
7、数据聚合
survived_group = df.groupby("survived")
survived_group.mean()
8、使用索引用 iloc 查看数据
df.iloc[0, :]
# iloc 函数通过索引中的特定位置查看某行或列的数据,所以这里的索引值应该只接受整数

9、获取指定位置的数据
df.iloc[0, 1]
'Allen, Miss. Elisabeth Walton'
10、根据索引值用 loc 查看
df.loc[0] # 用loc从索引中插卡具有特定标签的行或列

预处理
# 查看含有至少一个NaN值的数据
df[pd.isnull(df).any(axis=1)].head()
# 删除含有NaN值的数据行
df = df.dropna() # 删除含有NaN值的行
df = df.reset_index() # 重置行的索引
df.head()
# 删除多列
df = df.drop(["name", "cabin", "ticket"], axis=1) # 暂时不需要类型为文本的数据条目
df.head()
# 特征值映射
df['sex'] = df['sex'].map( {'female': 0, 'male': 1} ).astype(int)
df["embarked"] = df['embarked'].dropna().map( {'S':0, 'C':1, 'Q':2} ).astype(int)
df.head()
特征工程
# 用lambda表达式创建新特征
def get_family_size(sibsp, parch):
family_size = sibsp + parch
return family_size
df["family_size"] = df[["sibsp", "parch"]].apply(lambda x: get_family_size(x["sibsp"], x["parch"]), axis=1)
df.head()

# 重新组织表头
df = df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'family_size', 'fare', 'embarked', 'survived']]
df.head()

存储数据
# 把Dataframe存进CSV文件
df.to_csv("processed_titanic.csv", index=False)