使用kettle执行mapreduce#
机器:192.168.9.157 10G内存,4核CPU,centos6.5
hadoop版本:2.7.3
pdi:8.0
目的
使用pdi工具实现运行mapreduce的wordcount程序,不需要写任何java代码从而简化开发人员的工作量。
参考文档
http://www.pentaho.com/sites/default/files/webdetails-pentaho-evalpath/pdf/evaluation-experiences-pdf/EL7_PentahoMapReduce.pdf
https://wiki.pentaho.com/display/BAD/Using+Pentaho+MapReduce+to+Parse+Weblog+Data
https://wiki.pentaho.com/display/BAD/Using+Pentaho+MapReduce+to+Generate+an+Aggregate+Dataset/
准备工作
选择对应的hadoop发行版

hadoop cluster集群配置
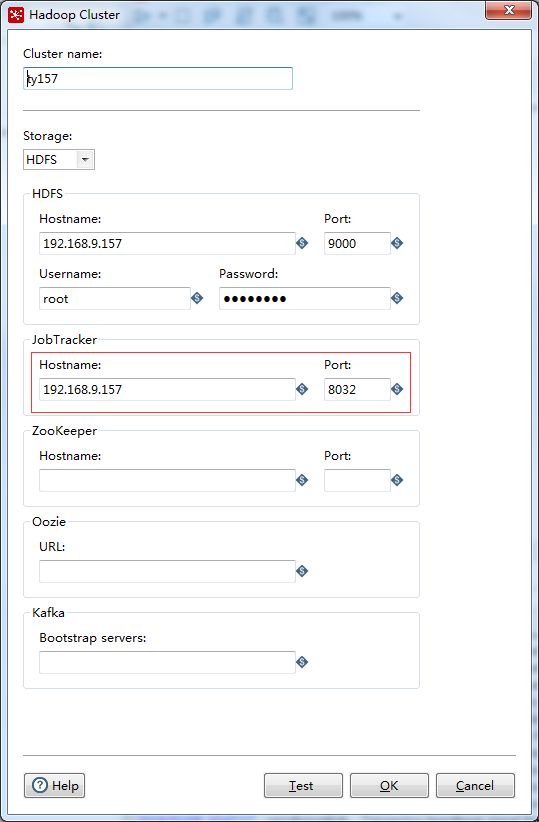
这里jobtracker实际上应该叫resourcemanger,在hadoop2.x的yarn中已经没有jobtracker概念了。
这个值与yarn-site.xml中yarn.resourcemanager.address对应。
修改config.properties
修改kettle\pdi-ce-8.0.0.0-28\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26\config.properties增加一行
authentication.superuser.provider=NO_AUTH
复制集群上的mapred-site.xml
复制集群上mapred-site.xml到\kettle\pdi-ce-8.0.0.0-28\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh512。如果在windows上提交任务需要增加mapreduce.app-submission.cross-platform配置。mapreduce.reduce.memory.mb,mapreduce.map.memory.mb 这两个值设置了每个container所需要的内存资源,java.opts一般设置memory.mb*0.8.
mapreduce.framework.name
yarn
mapreduce.app-submission.cross-platform
true
mapreduce.reduce.memory.mb
1024
mapreduce.map.memory.mb
1024
mapreduce.map.java.opts
-Xmx800m
mapreduce.reduce.java.opts
-Xmx800m
复制集群上的yarn-site.xml
复制集群上yarn-site.xml到\kettle\pdi-ce-8.0.0.0-28\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh512。
修改hostname为对应主机的地址,或者在本机配置host。
一定要配置yarn.nodemanager.resource.memory-mb,尽量配置大一点,这里配置了8G,因为nodemanager启动一个container就需约1.5G内存,如果给nodemanager的内存不够大,将会导致无法启动container从而无法运行mapreduce。
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
192.168.9.157
yarn.nodemanager.hostname
192.168.9.157
yarn.resourcemanager.address
192.168.9.157:8032
yarn.nodemanager.resource.memory-mb
8192
yarn.scheduler.minimum-allocation-mb
256
yarn.nodemanager.vmem-pmem-ratio
6
......
一、创建mapper的Transformation

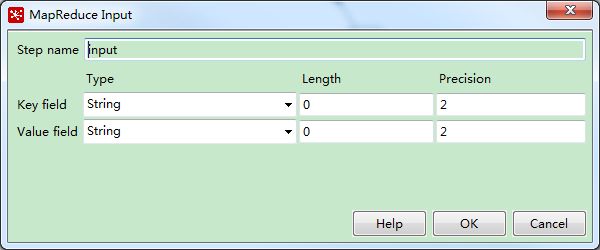
input
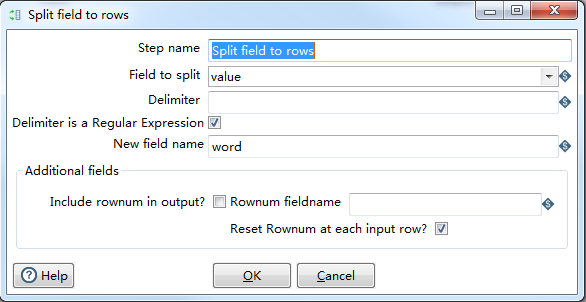
其中split field row,
delimiter 填写一个空格,用于如何分割一个单词。
add constants ,增加一列count统计单词出现的次数,map节点还没有统计,所以所有的单词次数都是1。

output

这一系列的过程相当于实现了wordcount的mapreduce的map方法,也就是
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
主要的目的就是将hdfs上的文件map操作成如下结果
word(key) count(value)
hello 1
world 1
hello 1
二、创建reduce的Transformation
[站外图片上传中...(image-83078a-1520563970869)]
input,这里的key,value其实就是来自于map阶段的word,count。
[站外图片上传中...(image-c4be5a-1520563970869)]
group by,
相当于执行了 select key,sum(value) as sum from table group by key;

out
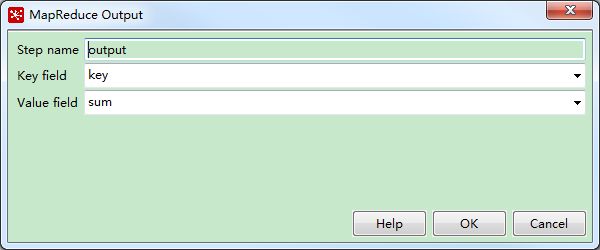
这一系列的操作相当于实现了wordcount的mapreduce的reduce方法,也就是
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
也就是将map阶段的数据reduce成如下结果。
hello 2
world 1
三、创建wordcount的job
新建一个job,创建一个start节点以及Pentaho MapReduce组件。
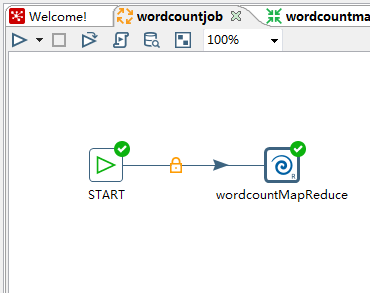
mapper,选择第一步创建的map Transformation文件,填写input,output stepname。
[站外图片上传中...(image-12949c-1520563970869)]
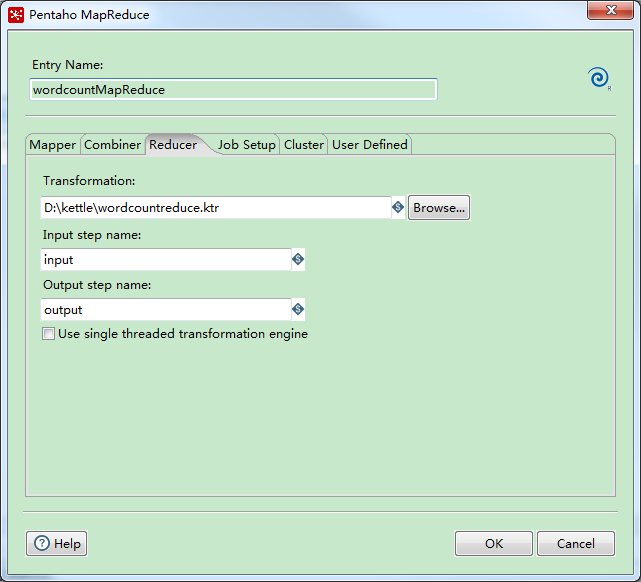
reducer,选择第二步创建的reduce Transformation文件,填写input,output stepname。
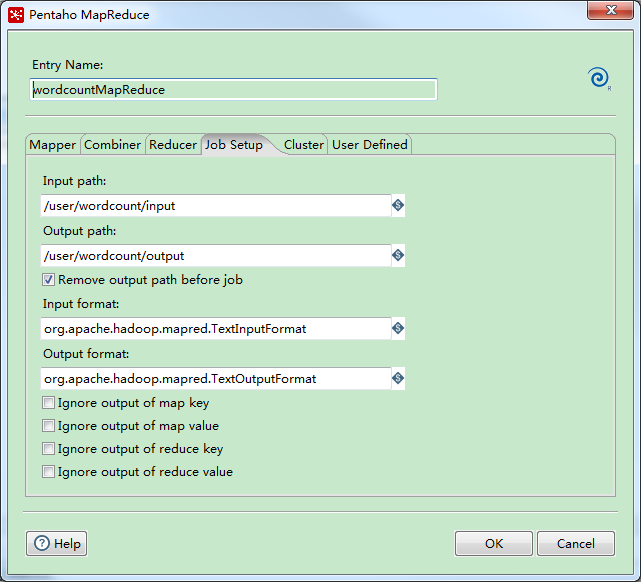
job setup,mapreduce的计算结果会存放在hdfs的/user/wordcount/output下。
cluster

四、运行job
F9运行这个job,如果顺利,在yarn的管理平台里,会看到这个作业在执行。

执行完成后会在/user/wordcount/output有输出

常见问题总结
1.作业的log一直报RMContainerAllocator: Going to preempt 1 due to lack of space for maps,作业一直是runing状态。###
这是由于nodemanager的内存设置的过小,yarn的container无法申请到足够的资源,参考
https://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
2.任务提交成功,但日志报Stack trace: ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job con
在maper-site.xml中配置mapreduce.app-submission.cross-platform=true
3pdi任务提交成功,但pdi的log一直报Triggering heartbeat signal for wordcountjob at every 10 seconds
这是没有正确配置hostname导致,从集群上复制下来的yarn-site.xml中的hostname可能是localhost等,复制下来后需要改成对应的ip地址。
4.yarn日志报 Invalid resource request, requested memory < 0, or requested memory > max configured
设置yarn.nodemanager.resource.memory-mb
5.pdi报:AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
客户端的pdi连接到集群的hadoop,要伪装成集群的用户,在spoon.bat增加一行。
set HADOOP_USER_NAME=root
6.limits. Current usage: 202.1 MB of 2 GB physical memory used; 5.3 GB of 4.2 GB virtual memory used. Killing container.
这是由于容器使用的虚拟内存超过了设定的值,这个值一般是mapreduce.reduce.memory.mb与yarn.nodemanager.vmem-pmem-ratio的乘积,yarn.nodemanager.vmem-pmem-ratio默认值是2.1,所以需要调大这个参数。
参考《hadop权威指南第四版》10.3.3章节。