【转载请注明出处】:https://www.jianshu.com/p/6ae1229ec229
基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql。
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。
ps. 目前内部版本已经支持mysql和oracle部分版本的日志解析,当前的canal开源版本支持5.7及以下的版本(阿里内部mysql 5.7.13, 5.6.10, mysql 5.5.18和5.1.40/48)
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
1、Canal工作原理
mysql主备复制实现

从上层来看,复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
canal的工作原理:
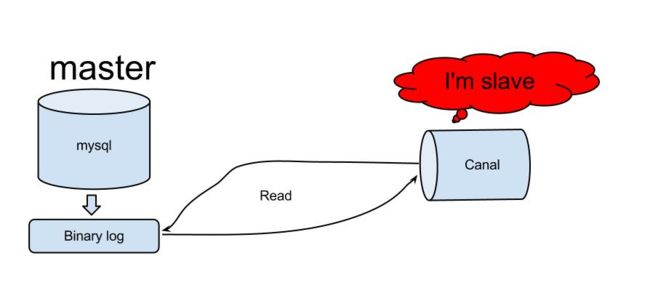
原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
架构
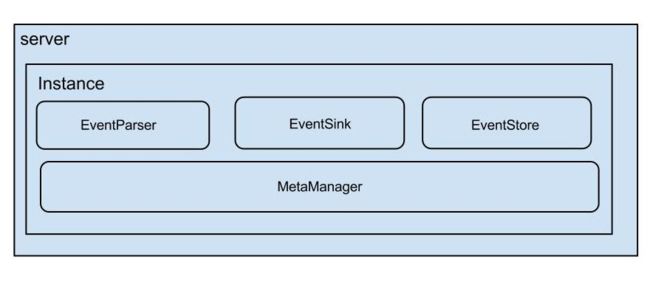
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
EventParser设计
大致过程:

整个parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,发送BINLOG_DUMP指令
// 0. write command number
// 1. write 4 bytes bin-log position to start at
// 2. write 2 bytes bin-log flags
// 3. write 4 bytes server id of the slave
// 4. write bin-log file name - Mysql开始推送Binaly Log
- 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
// 补充字段名字,字段类型,主键信息,unsigned类型处理 - 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
- 存储成功后,定时记录Binaly Log位置
mysql的Binlay Log网络协议:
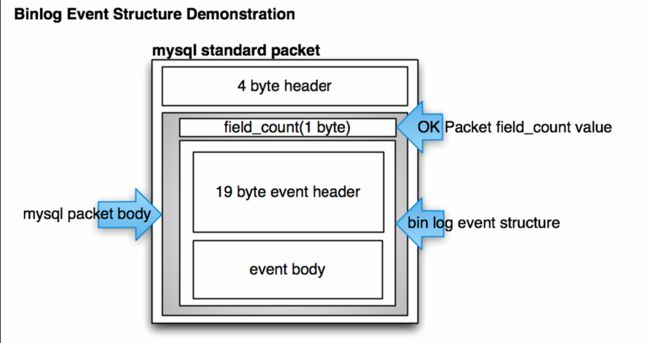
说明:
- 图中的协议4byte header,主要是描述整个binlog网络包的length
- binlog event structure,详细信息请参考:
https://dev.mysql.com/doc/internals/en/binary-log.html
https://dev.mysql.com/doc/internals/en/event-structure.html
https://dev.mysql.com/doc/internals/en/binlog-event.html
EventSink设计
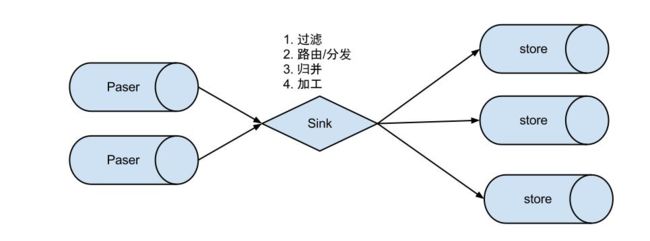
说明:
- 数据过滤:支持通配符的过滤模式,表名,字段内容等
- 数据路由/分发:解决1:n (1个parser对应多个store的模式)
- 数据归并:解决n:1 (多个parser对应1个store)
- 数据加工:在进入store之前进行额外的处理,比如join
数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注
数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.
EventStore设计
- 目前仅实现了Memory内存模式,后续计划增加本地file存储,mixed混合模式
- 借鉴了Disruptor的RingBuffer的实现思路
RingBuffer设计:
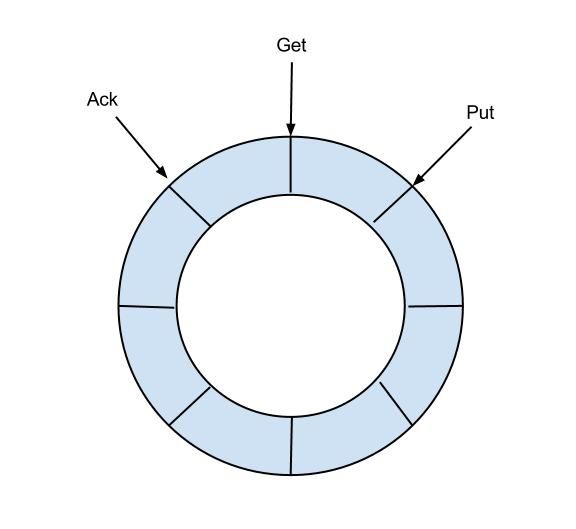
定义了3个cursor
- Put : Sink模块进行数据存储的最后一次写入位置
- Get : 数据订阅获取的最后一次提取位置
- Ack : 数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
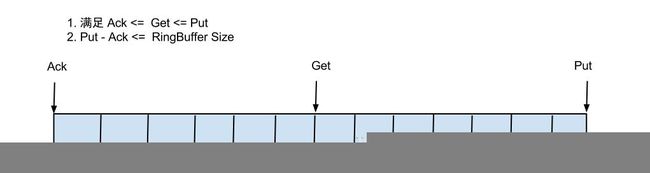
实现说明:
- Put/Get/Ack cursor用于递增,采用long型存储
- buffer的get操作,通过取余或者与操作。(与操作: cusor & (size - 1) , size需要为2的指数,效率比较高)
Instance设计
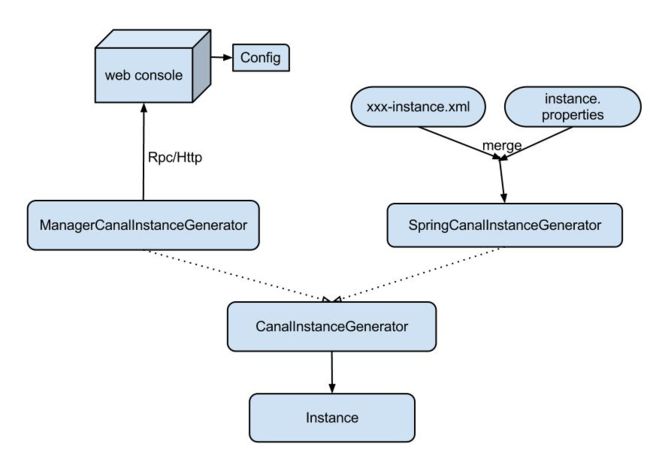
instance代表了一个实际运行的数据队列,包括了EventPaser,EventSink,EventStore等组件。
抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:
- manager方式: 和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用)
- spring方式:基于spring xml + properties进行定义,构建spring配置.
Server设计
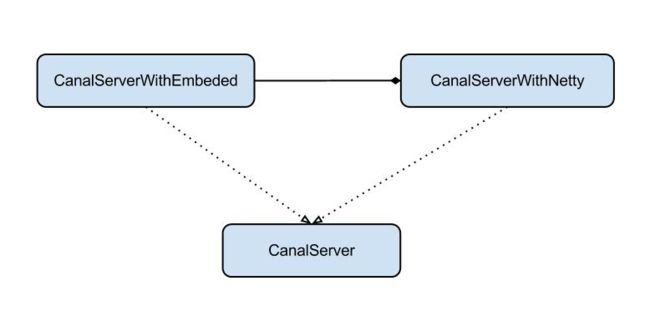
server代表了一个canal的运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式) / Netty(网络访问)的两种实现
- Embeded : 对latency和可用性都有比较高的要求,自己又能hold住分布式的相关技术(比如failover)
- Netty : 基于netty封装了一层网络协议,由canal server保证其可用性,采用的pull模型,当然latency会稍微打点折扣,不过这个也视情况而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠拢,push在数据量大的时候会有一些问题)
增量订阅/消费设计
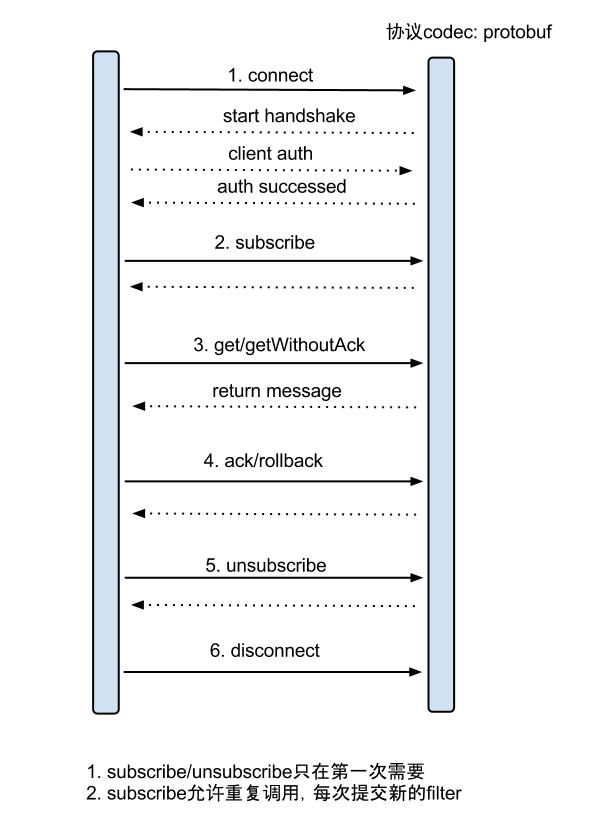
具体的协议格式,可参见: CanalProtocol.proto
get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto - void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
流式api设计:
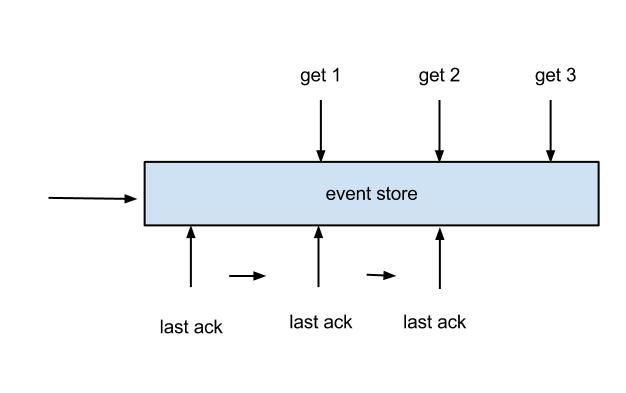
- 每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
- 每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
- 进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cusor
- 一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),可以看下我之前zookeeper的相关文章。
Canal Server:
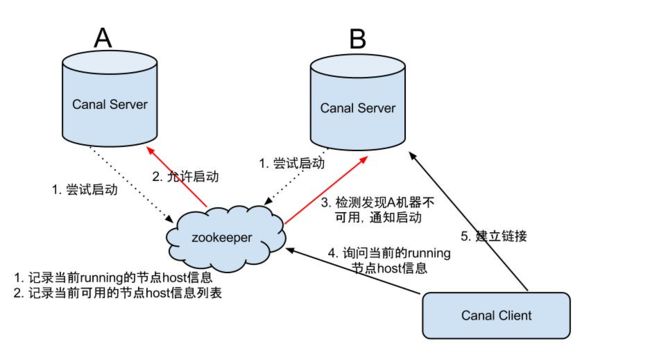
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
2、环境要求
- jdk建议使用1.6.25以上的版本
- 当前的canal开源版本支持5.7及以下的版本
ps. mysql4.x版本没有经过严格测试,理论上是可以兼容 - 开启mysql的binlog写入功能,并且配置binlog模式为row
检查配置是否有效[mysqld] log-bin=mysql-bin binlog-format=ROW #选择row模式 server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复#查看binlog的开启状态及文件名 mysql> show variables like '%log_bin%'; #查看binlog当前的格式 mysql> show variables like '%format%'; #查看binlog文件列表 mysql> show binary logs; #查看binlog的状态 mysql> show master status; - canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限
针对已有的账户可通过grants查询权限:mysql> CREATE USER canal IDENTIFIED BY 'canal'; mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; # -- mysql> GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; mysql> FLUSH PRIVILEGES;mysql> show grants for 'canal' ;
3、部署
获取发布包
方法1: (直接下载)
访问:https://github.com/alibaba/canal/releases,会列出所有历史的发布版本包
当前的最新版本是1.1.3
wget https://github.com/alibaba/canal/releases/download/canal-1.1.3/canal.deployer-1.1.3.tar.gz
方法2: (自己编译)
git clone [email protected]:alibaba/canal.git
git co canal-1.1.3 #切换到对应的版本上
mvn clean install -Denv=release
执行完成后,会在canal工程根目录下生成一个target目录,里面会包含一个 canal.deployer-1.1.3.tar.gz
配置介绍
介绍配置之前,先了解下canal的配置加载方式:
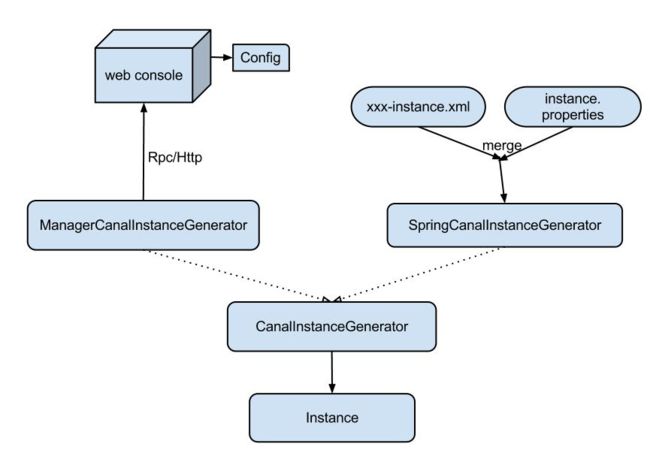
canal配置方式有两种:
- ManagerCanalInstanceGenerator: 基于manager管理的配置方式,目前alibaba内部配置使用这种方式。大家可以实现CanalConfigClient,连接各自的管理系统,即可完成接入。
- SpringCanalInstanceGenerator:基于本地spring xml的配置方式,目前开源版本已经自带该功能所有代码,建议使用
Spring配置方式介绍
spring配置的原理是将整个配置抽象为两部分:
- xxxx-instance.xml (canal组件的配置定义,可以在多个instance配置中共享)
- xxxx.properties (每个instance通道都有各自一份定义,因为每个mysql的ip,帐号,密码等信息不会相同)
通过spring的PropertyPlaceholderConfigurer通过机制将其融合,生成一份instance实例对象,每个instance对应的组件都是相互独立的,互不影响
properties配置文件
properties配置分为两部分:
- canal.properties (系统根配置文件)
- instance.properties (instance级别的配置文件,每个instance一份)
canal.properties介绍:
canal配置主要分为两部分定义:
- instance列表定义 (列出当前server上有多少个instance,每个instance的加载方式是spring/manager等)
- common参数定义,比如可以将instance.properties的公用参数,抽取放置到这里,这样每个instance启动的时候就可以共享. 【instance.properties配置定义优先级高于canal.properties】
instance.properties介绍:
-
在canal.properties定义了canal.destinations后,需要在canal.conf.dir对应的目录下建立同名的文件
比如:canal.destinations = example1,example2这时需要创建example1和example2两个目录,每个目录里各自有一份instance.properties.
ps. canal自带了一份instance.properties demo,可直接复制conf/example目录进行配置修改 如果canal.properties未定义instance列表,但开启了canal.auto.scan时
- server第一次启动时,会自动扫描conf目录下,将文件名做为instance name,启动对应的instance
- server运行过程中,会根据canal.auto.scan.interval定义的频率,进行扫描
- 发现目录有新增,启动新的instance
- 发现目录有删除,关闭老的instance
- 发现对应目录的instance.properties有变化,重启instance
instance.xml配置文件
目前默认支持的instance.xml有以下几种:
- spring/memory-instance.xml
- spring/default-instance.xml
- spring/group-instance.xml
在介绍instance配置之前,先了解一下canal如何维护一份增量订阅&消费的关系信息:
- 解析位点 (parse模块会记录,上一次解析binlog到了什么位置,对应组件为:CanalLogPositionManager)
- 消费位点 (canal server在接收了客户端的ack后,就会记录客户端提交的最后位点,对应的组件为:CanalMetaManager)
对应的两个位点组件,目前都有几种实现:
- memory (memory-instance.xml中使用)
- zookeeper
- mixed
- period (default-instance.xml中使用,集合了zookeeper+memory模式,先写内存,定时刷新数据到zookeeper上)
memory-instance.xml:
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点: 速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
default-instance.xml:
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点: 支持HA
场景: 生产环境,集群化部署.
group-instance.xml:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景: 分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
instance.xml设计初衷:
允许进行自定义扩展,比如实现了基于数据库的位点管理后,可以自定义一份自己的instance.xml,整个canal设计中最大的灵活性在于此
HA模式配置
修改canal.properties
canal.zkServers =127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
canal.destinations = example #当前server上部署的instance列表
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
修改instance.properties
canal.instance.mysql.slaveId=1234 #mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定)
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.filter.regex=.*\\..* #mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
注意: 其他机器上的instance目录的名字需要保证完全一致,HA模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置,canal.instance.mysql.slaveId应该唯一。
执行启动脚本startup.sh,启动后,你可以查看logs/example/example.log,只会看到一台机器上出现了启动成功的日志,其他的处于standby状态。
客户端消费数据
创建mvn工程,修改pom.xml,添加依赖:
com.alibaba.otter
canal.client
1.1.3
CanalClientTest代码
package com.stepper.canalclient;
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class CanalClientTest {
public static void main(String args[]) {
String zkServers="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
String destination="example";
CanalConnector connector = CanalConnectors.newClusterConnector(zkServers,destination,"","");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
// connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
// System.out.println(message.toString());
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================ binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
启动Canal Client后,操作数据库变更数据即可从控制台从看到消息。
更多参数及介绍可以参考官方wiki文档.
注意:
- 生产环境下尽量采用HA的方式。
- 关于Canal消费binlog的顺序,为保证binlog严格有序,尽量不要用多线程。
- 如果Canal消费binlog后的数据要发往kafka,又要保证有序,kafka topic 的partition可以设置成1个分区。
【转载请注明出处】: https://www.jianshu.com/p/6ae1229ec229