上一篇文章简单介绍了如何集成Spring Batch,实际上Spring Batch有很多高级特性,上次的demo中没有体现。
1 Spring Batch 基本原理
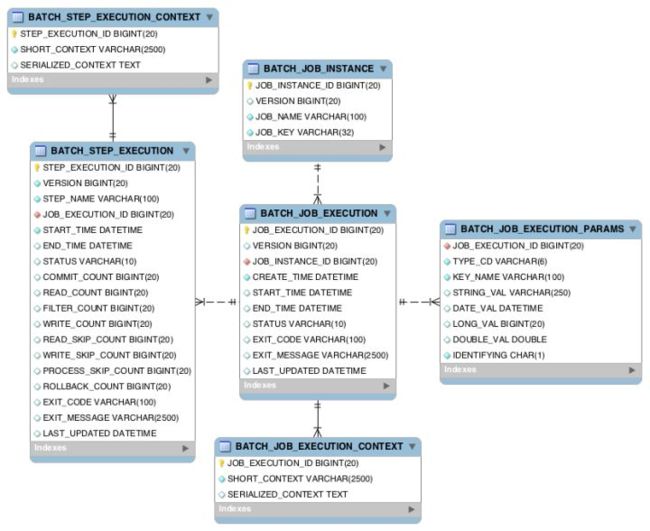
-
BATCH_JOB_INSTANCE:Job实例表,存放Job的实例 -
BATCH_JOB_EXECUTION_PARAMS:Job参数表,用于存放每个Job执行时候的参数信息. -
BATCH_JOB_EXECUTION:Job执行器表,用于存放当前作业的执行信息:创建时间、开始时间、结束时间、执行状态等。 -
BATCH_JOB_EXECUTION_CONTEXT:Job执行上下文表。 -
BATCH_STEP_EXECUTION:Job step执行器表,用于存放每个Step执行器的信息:开始执行时间、执行完成时间、执行状态、读写次数、跳过次数等信息。 -
BATCH_STEP_EXECUTION_CONTEXT:Job step执行上下文表。

JobLauncher执行job,先根据执行参数,通过repository获取有没有最近的lastExecution,如果有的话就把ExecutionContextset到新的job中去并创建新job。然后执行step,在step中根据BATCH_JOB_EXECUTION_CONTEXT和BATCH_JOB_EXECUTION_PARAMS(要不要跳过、重试、是不是重启、上次执行数量等)进行数据处理。然后更新job的信息到数据库中,返回job的最终状态。
2 Spring Batch提供的一些高可用性机制
基于以上六张表,可以对任务的状态各种指标进行跟踪监控,也可以进行一系列的容错操作:skip、retry、restart
2.1 跳过
给Step定义skip-limit属性,告诉spring batch如果出问题可以跳过,允许最大跳过次数。也可以定义跳过异常skip(Exception.class)。
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
. chunk(1)
.reader(testReader)
.processor(testProcessor)
.writer(testWriter)
.faultTolerant().skipLimit(1).skip(Exception.class)
.build();
}
这样可以使系统更健壮,比如你想从Excel中读取数据,可以定义skip,跳过第一行表头数据。
2.2 重试
给Step定义retry-limit属性,告诉spring batch出问题可以继续重试处理这一行数据。且定义重试次数。通过retry(Exception.class)来告诉spring batch哪些异常需要重试。
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
. chunk(1)
.reader(testReader)
.processor(testProcessor)
.writer(testWriter)
.faultTolerant().retryLimit(1).retry(Exception.class)
.build();
}
重试机制非常适用于远程调用失败的情况,可以允许重试多次后失败。
2.3 重启
给Step定义restart-limit属性,告诉spring batch当前step可重启次数。在任务出问题后,可以用相同的参数再次启动任务。而Spring batch默认不会从失败的地方重新执行,除非你用的reader是AbstractItemCountingItemStreamItemReader,它会在ExecutionContext中以Json字符串的形式记录currentCount({"string":"restart.read.count","int":8}),下次重启的时候,会获取会currentCount,从失败的地方重新执行该任务。
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.> chunk(1)
.reader(productReader)
.processor(productProcessor)
.writer(productWriter)
.faultTolerant().startLimit(2).allowStartIfComplete(true)
.build();
}
//reader中的实现。
public T read() throws Exception, UnexpectedInputException, ParseException {
if (currentItemCount >= maxItemCount) {
return null;
}
currentItemCount++;
T item = doRead();
if(item instanceof ItemCountAware) {
((ItemCountAware) item).setItemCount(currentItemCount);
}
return item;
}
3 数据分片
可以通过实现Partitioner接口来对需要处理的数据进行分片处理。然后在配置job的时候设置分片job,在job启动的时候,会根据你分配的线程数,自动开启多线程执行job。
示例如下:
public class IdPartitioner implements Partitioner {
private static final String PARTITION_KEY = "partition";
private Integer total = 100;
private Integer minId = 1;
@Override
public Map partition(int gridSize) {
Map result = Maps.newHashMap();
for(int a = 0; a < gridSize; a++) {
int targetSize = (total / gridSize) + 1;
ExecutionContext context = new ExecutionContext();
context.putInt("minId", minId);
context.putInt("size", targetSize);
result.put(PARTITION_KEY + a, context);
minId += targetSize;
}
return result;
}
}
这是一个按照ID范围分片的一个配置中心。主要维护了两个参数:minId和size。
job的config配置如下:
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
. chunk(1)
.reader(testReader)
.processor(testProcessor)
.writer(testWriter)
.build();
}
@Bean
public Step partitionerStep(){
return stepBuilderFactory.get("partitionerStep")
.partitioner(step1())
.partitioner("step1", new IdPartitioner())
.gridSize(3)
.taskExecutor(new SimpleAsyncTaskExecutor())
.build();
}
@Bean
public Job testJob(){
return jobBuilderFactory.get("testJob")
.incrementer(new RunIdIncrementer())
.flow(partitionerStep())
.end()
.build();
}
定义partitionerStep配置3个线程并行异步执行任务。
@Value("#{stepExecutionContext['minId']}")
private Integer minId;
@Value("#{stepExecutionContext['size']}")
private Integer size;
在reader中通过ExecutionContext获取分片参数,来确定自己需要执行的数据范围。
注:数据分片上面只是展示了单机的多线程job执行方式,如果要实现分布式job,可以通过
MessageChannelPartitionHandler来配置消息中间件(MQ),Master会把分区上下文写入到消息中间件中,Slave监听消息队列获取分区上下文并执行Job。原理同单机分片。
4 远程step
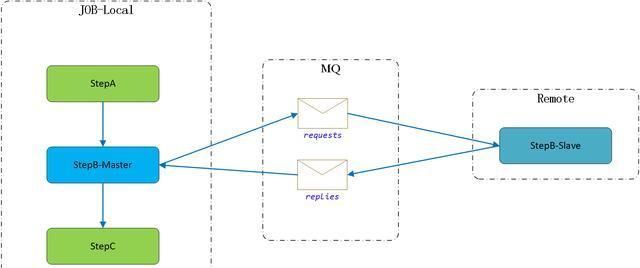
springbatch官方提供ChunkMessageChannelItemWriter支持将数据写到远程的消息队列中,然后远程step只需要从消息队列中获取数据,并入库即可。然后把处理的结果发送给消息队列,master获取远程step执行结果记录到数据库中。