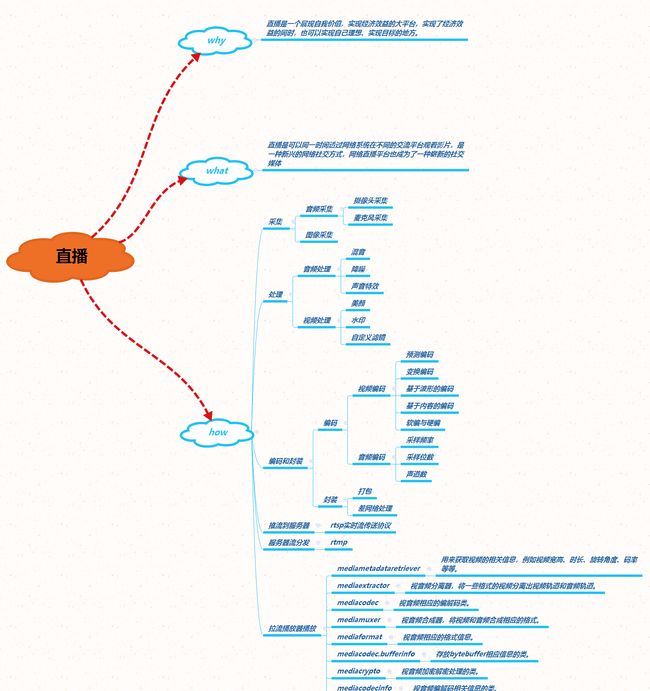
视频直播的流程可以分为如下几步: 采集 —>处理—>编码和封装—>推流到服务器—>服务器流分发—>播放器流播放

1.采集
采集是整个视频推流过程中的第一个环节,它从系统的采集设备中获取原始视频数据,将其输出到下一个环节。视频的采集涉及两方面数据的采集:音频采集和图像采集,它们分别对应两种完全不同的输入源和数据格式。
视频采集技术要点:
检测摄像头是否可以使用;
/**
* 测试当前摄像头能否被使用
*
* @return
*/
public static boolean isCameraCanUse() {
boolean canUse = true;
Camera mCamera = null;
try {
mCamera = Camera.open(0);
mCamera.setDisplayOrientation(90);
} catch (Exception e) {
canUse = false;
}
if (canUse) {
mCamera.release();
mCamera = null;
}
//Timber.v("isCameraCanuse="+canUse);
return canUse;
}
//调用相机权限判定
if (CameraCanUseUtils.isCameraCanUse()) {
Log.i(TAG, "相机");
} else {
ToastUtils.showTextToast(mContext, "没相机权限,请到应用程序权限管理开启权限");
//跳转至app设置
getAppDetailSettingIntent();
return;
}
//设置相机
/**
* 相机权限设置
* 跳转至设置页面
*/
private void getAppDetailSettingIntent() {
Intent localIntent = new Intent();
if (Build.VERSION.SDK_INT >= 9) {
localIntent.setAction("android.settings.APPLICATION_DETAILS_SETTINGS");
localIntent.setData(Uri.fromParts("package", mContext.getPackageName(), null));
} else if (Build.VERSION.SDK_INT <= 8) {
localIntent.setAction(Intent.ACTION_VIEW);
localIntent.setClassName("com.android.settings", "com.android.settings.InstalledAppDetails");
localIntent.putExtra("com.android.settings.ApplicationPkgName", mContext.getPackageName());
}
startActivity(localIntent);
}
音频采集技术要点:
检测麦克风是否可以使用;
/**
* 作用:用户是否同意录音权限
*
* @return true 同意 false 拒绝
*/
public boolean isVoicePermission() {
try {
AudioRecord record = new AudioRecord(MediaRecorder.AudioSource.MIC, 22050, AudioFormat.CHANNEL_CONFIGURATION_MONO,
AudioFormat.ENCODING_PCM_16BIT, AudioRecord.getMinBufferSize (22050, AudioFormat.CHANNEL_CONFIGURATION_MONO,
AudioFormat.ENCODING_PCM_16BIT));
record.startRecording();
int recordingState = record.getRecordingState();
if(recordingState == AudioRecord.RECORDSTATE_STOPPED){
return false;
}
record.release();
return true;
} catch (Exception e) {
return false;
}
}
音频采集 音频数据既能与图像结合组合成视频数据,也能以纯音频的方式采集播放,后者在很多成熟的应用场景如在线电台和语音电台等起着非常重要的作用。
android平台上的音频采集一般就三种:
1.利用android内置的应用程序
2.使用MediaRecorder进行音频捕获
3.使用AudioRecord进行音频捕获。
此3种方式的灵活性逐渐增大,相应的所需要做的工作也逐渐增多。
(1)、Android 内置的应用程序。
Intent intent=new Intent(MediaStore.Audio.Media.RECORD_SOUND_ACTION);
startActivityForResult(intent,0); //通过startActivityForResult获取音频录制的结果的路径
这种方式灵活度最差,一般就是做着演示下,开发中基本不用这种方案。
(2)、使用MediaRecorder进行音频的捕获。
MediaRecorder是用于录制音频和视频的一个类。
MediaPlayer是用于播放视频的一个类。
这种方案相较于调用系统内置的用用程序,灵活度要高很多,便于开发者在UI界面上布局,而且系统封装的很好,便于使用,唯一的缺点是使用它录下来的音频是经过编码的,没有办法的得到原始的音频。同时MediaRecorder即可用于音频的捕获也可以用于视频的捕获相当的强大。实际开发中没有特殊需求的话,用的是比较多的!
使用步骤:
创建MediaRecorder对象,调用如下方法(Ps:调用顺序顺序对结果的影响是非常的大。)
MediaRecorder recorder=new MediaRecorder();//创建MediaRecoder对象
1.recorder.setAudioSource(MediaRecorder.AudioSource.MIC); //调用setAudioSource方法 (调用的第一个方法) //设置声音来源,一般传入 MediaRecorder. AudioSource.MIC参数指定录制来自麦克风的声音。
MediaRecorder.AudioSource.CAMCORDER和MediaRecorder.AudioSource.VOICE_RECOGNITION当设备具有。>=2个麦克风的时候就可以使用它们。
MediaRecorder.AudioSource.VOICE_CALL从电话中录音
2.recorder.setOutputFormat(MediaRecorder.OutputFormat.THREE_GPP);//setOutputFormat方法(调用的第二个方法)//设置所录制的音视频文件的格式。
MediaRecorder.OutputFormat.THREE_GPP 输出文件将是一个扩展名为(.3gp)的文件。它可能包含音频和视频。
MediaRecorder.OutputFormat.MPEG_4 输出一个MPEG_4文件,它可能包含音频和视频。
3.recorder.setAudioEncoder(MediaRecorder.AudioEncoder.AAC); //setAudioEncoder方法 (这是调用的第三个方法)设置编解码器AAC(AAC低复杂度(AAC-LC)音频编解码器)
4.recorder.setOutputFile(url); //setOutputFile方法 url是目标文件路径(这是调用的第四个方法)
//设置录制的音频文件的保存位置。
(3)、使用AudioRecord 进行音频捕获。
这种方法是3种之中最为灵活的,能让开发者最大限度的处理采集的音频,同时它捕获到的音频是原始音频PCM格式的!像做变声处理的需要就必须要用它收集音频。在实际开发中,它也是最常用来采集音频的手段
//指定音频源 这个和MediaRecorder是相同的
int audioSource=MediaRecorder.AudioSource.MIC;
//指定采样率 (MediaRecoder 的采样率通常是8000Hz CD的通常是44100Hz 不同的Android手机硬件将能够以不同的采样率进行采样。其中11025是一个常见的采样率)
int sampleRateInHz=11025 ;
//指定捕获音频的通道数目。在AudioFormat类中指定用于此的常量
int channelConfig=AudioFormat.CHANNEL_CONFIGURATION_MONO;
//指定音频量化位数 ,在AudioFormaat类中指定了以下各种可能的常量。通常我们选择ENCODING_PCM_16BIT和ENCODING_PCM_8BIT PCM代表的是脉冲编码调制,它实际上是原始音频样本。
//因此可以设置每个样本的分辨率为16位或者8位,16位将占用更多的空间和处理能力,表示的音频也更加接近真实。
int audioFormat=AudioFormat.ENCODING_PCM_16BIT;
指定缓冲区大小。调用AudioRecord类的getMinBufferSize方法可以获得。
//创建AudioRecord。AudioRecord类实际上不会保存捕获的音频,因此需要手动创建文件并保存下载。
AudioRecord record=new AudioRecord(audioSource,sampleRateInHz,channelConfig,audioFormat,bufferSizeInBytes);
音频的采集过程主要通过设备将环境中的模拟信号采集成 PCM 编码的原始数据,然后编码压缩成 MP3 等格式的数据分发出去。
常见的音频压缩格式有:MP3,AAC,HE-AAC,Opus,FLAC,Vorbis (Ogg),Speex 和 AMR等。
1、AudioRecord
优点:语音的实时处理,可以用代码实现各种音频的封装,比如降噪,合成等
缺点:输出是PCM语音数据,如果保存成音频文件,是不能够被播放器播放的,所以必须先写代码实现数据编码以及压缩。
AudioRecord可以采用speex进行压缩,是通过jni调用,压缩,目前so的大小在13k左右,压缩程度 也有所不同
2、MediaRecorder
优点:已经集成了录音、编码、压缩等,支持少量的录音音频格式,
直接调用相关接口即可,代码量小。
缺点:无法实时处理音频
如果不用对音频流进行处理或者直接想使用音频的话可以采用MediaRecorder来实现。实现容易且可以直接录制成amr格式。
amr为音频文件格式,是一种保存手机录音的格式,能够打开amr文件的软件有很多,比如:常用的暴风影音、迅雷看看等音、视频播放软件均可打开amr文件,由于AMR文件的容量很小——每秒钟的AMR音频大小可控制在1K左右,因此即便是长达1分钟的音频文件,也能符合中国移动现行的彩信不超过50K的技术规范,所以AMR也是实现在彩信中加载人声的惟一格式。
如果要对音频流进行处理比如降噪等,可以采用AudioRecord录制,然后对buff里面的流进行操作
音频采集和编码主要面临的挑战在于:延时敏感、卡顿敏感、噪声消除(Denoise)、回声消除(AEC)、静音检测(VAD)和各种混音算法等。
麦克风降噪
现在的手机不仅仅只有一个麦克风,而是有2个甚至是3个,而这多出来的几个就是手机降噪的关键。
一般来说手机都有两个麦克风,顶部和底部都各有一个。这两个麦看起来都非常小,但是两者的作用有着明显的区别,其中底部的麦是用来提供清晰通话,而顶部的麦是用来消除噪音。
由于顶部和底部在通话时距离音源的距离不同,所以两个麦拾取的音量大小也是有不同的,利用这个差别,我们就可以过滤掉噪声保留人声了。在打电话时,两个麦克风所拾取的背景噪声音量是基本相同的,而记录的人声会有6dB左右的音量差。顶端麦收集噪声后,通过解码生成补偿信号后就可以用来消除噪音了。
回声消除
回声(或称回音)是指障碍物对声音的反射。声波在遇到障碍物时,一部分声波会穿过障碍物,而另一部分声波会反射回来形成回声。
回声消除就是在麦克风录制外音的时候去除掉手机自身播放出来的声音,这样就将对方的声音从采集的声音中过滤出去,从而就避免了回声的产生。
图像采集
图像采集 将图像采集的图片结果组合成一组连续播放的动画,即构成视频中可肉眼观看的内容。图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据,然后经过编码压缩成 H.264 等格式的数据分发出去。
常见的视频封装格式有:MP4、3GP、AVI、MKV、WMV、MPG、VOB、FLV、SWF、MOV、RMVB 和 WebM 等。
图像由于其直观感受最强并且体积也比较大,构成了一个视频内容的主要部分。图像采集和编码面临的主要挑战在于:设备兼容性差、延时敏感、卡顿敏感以及各种对图像的处理操作如美颜和水印等。
视频采集的采集源主要有 摄像头采集、屏幕录制和从视频文件推流。
2.处理
视频或者音频完成采集之后得到原始数据,为了增强一些现场效果或者加上一些额外的效果,我们一般会在将其编码压缩前进行处理,比如打上时间戳或者公司 Logo 的水印,祛斑美颜和声音混淆等处理。在主播和观众连麦场景中,主播需要和某个或者多个观众进行对话,并将对话结果实时分享给其他所有观众,连麦的处理也有部分工作在推流端完成。

如上图所示,处理环节中分为音频和视频处理,音频处理中具体包含混音、降噪和声音特效等处理,视频处理中包含美颜、水印、以及各种自定义滤镜等处理。
3.编码和封装
(1)编码
视频编码
1、预测编码、
众所周知,一幅图像由许多个所谓像素的点组成,大量的统计表明,同一幅图像中像素之间具有较强的相关性,两个像素之间的距离越短,则其相关性越强,通俗地讲,即两个像素的值越接近。于是,人们可利用这种像素间的相关性进行压缩编码,这种压缩方式称为帧内预测编码。不仅如此,邻近帧之间的相关性一般比帧内像素间的相关性更强,压缩比也更大。由此可见,利用像素之间(帧内)的相关性和帧间的相关性,即找到相应的参考像素或参考帧作为预测值,可以实现视频压缩编码。
2、变换编码
大量统计表明,视频信号中包含着能量上占大部分的直流和低频成分,即图像的平坦部分,也有少量的高频成分,即图像的细节。因此,可以用另一种方法进行视频编码,将图像经过某种数学变换后,得到变换域中的图像
3、基于波形的编码
基于波形的编码采用了把预测编码和变换编码组合起来的基于块的混合编码方法。为了减少编码的复杂性,使视频编码操作易于执行,采用混合编码方法时,首先把一幅图像分成固定大小的块,例如块 8×8(即每块 8 行,每行 8 个像素)、块 16×16(每块 16 行,每行 16 个像素)等等,然后对块进行压缩编码处理。
自 1989 年 ITU-T 发布第一个数字视频编码标准——H.261 以来,已陆续发布了 H.263 等视频编码标准及 H.320、H.323 等多媒体终端标准。ISO 下属的运动图像专家组(MPEG)定义了 MPEG-1、MPEG-2、MPEG-4 等娱乐和数字电视压缩编码国际标准。
2003 年 3 月份,ITU-T 颁布了 H.264 视频编码标准。它不仅使视频压缩比较以往标准有明显提高,而且具有良好的网络亲和性,特别是对 IP 互联网、无线移动网等易误码、易阻塞、QoS 不易保证的网络视频传输性能有明显的改善。 所有这些视频编码都采用了基于块的混合编码法,都属于基于波形的编码。
4、基于内容的编码
还有一种基于内容的编码技术,这时先把视频帧分成对应于不同物体的区域,然后对其编码。具体说来,即对不同物体的形状、运动和纹理进行编码。在最简单情况下,利用二维轮廓描述物体的形状,利用运动矢量描述其运动状态,而纹理则用颜色的波形进行描述。
当视频序列中的物体种类已知时,可采用基于知识或基于模型的编码。例如,对人的脸部,已开发了一些预定义的线框对脸的特征进行编码,这时编码效率很高,只需少数比特就能描述其特征。对于人脸的表情(如生气、高兴等),可能的行为可用语义编码,由于物体可能的行为数目非常小,可获得非常高的编码效率。
MPEG-4 采用的编码方法就既基于块的混合编码,又有基于内容的编码方法。
5、软编与硬编
在Android平台上实现视频的编码有两种实现方式,一种是软编,一种是硬编。
软编的话,往往是依托于cpu,利用cpu的计算能力去进行编码。软编即采用CPU对相机采集的
原始数据进行编码后再和音频一起合并成一个MP4等格式的文件。
优点
技术相对成熟,网上开源的编码以及合成库很多,实现相对较快,同时兼容性比较好。
缺点
CPU占用率高,性能差的手机无法达到较大目标参数,同时引用了大量的第三方库,导致包很大。
软编的具体实现方案如下图所示,流程相对清晰简单:
camera采集YUV数据 ==> 滤镜 ==> x264编码器机型编码 ==> MP4打包合成
YUV 表示三个分量, Y 表示 亮度(Luminance),即灰度值,UV表示色度(Chrominance),描述图像色彩和饱和度,指定颜色。YUV格式有YUV444、 YUV422 和 YUV420 三种,差别在于:
YUV444: 每个Y分量对应一组UV分量
YUV422:每两个Y分量共用一组UV分量
YUV420:每四个Y分量共用一组UV分量
硬编则是采用Android自身提供的MediaCodec,使用MediaCodec需要传入相应的数据,这些数据可以是yuv的图像信息,也可以是一个Surface,一般推荐使用Surface,这样的话效率更高。Surface直接使用本地视频数据缓存,而没有映射或复制它们到ByteBuffers;因此,这种方式会更加高效。在使用Surface的时候,通常不能直接访问原始视频数据,但是可以使用ImageReader类来访问不可靠的解码后(或原始)的视频帧。这可能仍然比使用ByteBuffers更加高效,因为一些本地缓存可以被映射到 direct ByteBuffers。当使用ByteBuffer模式,可以利用Image类和getInput/OutputImage(int)方法来访问到原始视频数据帧。
音频编码
Android中利用AudioRecord可以录制声音,录制出来的声音是PCM声音。想要将声音用计算机语言表述,则必须将声音进行数字化。将声音数字化,最常见的方式是透过脉冲编码调制PCM(Pulse Code Modulation) 。声音经过麦克风,转换成一连串电压变化的信号。要将这样的信号转为 PCM 格式的方法,是使用三个参数来表示声音,它们是:声道数、采样位数和采样频率。
1、采样频率
即取样频率,指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。在16位声卡中有22KHz、44KHz等几级,其中,22KHz相当于普通FM广播的音质,44KHz已相当于CD音质了,目前的常用采样频率都不超过48KHz。
2、采样位数
即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
在计算机中采样位数一般有8位和16位之分,但有一点请大家注意,8位不是说把纵坐标分成8份,而是分成2的8次方即256份; 同理16位是把纵坐标分成2的16次方65536份。
3、声道数
很好理解,有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声的pcm可以使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果。
我们就可以得到pcm文件所占容量的公式:
存储量=(采样频率 ✖️ 采样位数 ✖️ 声道 ✖️ 时间)➗ 8 (单位:字节数)
如果音频全部用PCM的格式进行传输,则占用带宽比较大,因此在传输之前需要对音频进行编码。
现在已经有一些广泛使用的声音格式,如:wav、MIDI、MP3、WMA、AAC、Ogg等等。相比于pcm格式而言,这些格式对声音数据进行了压缩处理,可以降低传输带宽。
对音频进行编码也可以分为软编和硬编两种。软编则下载相应的编码库,写好相应的jni,然后传入数据进行编码。硬编则是使用Android自身提供的MediaCodec。
如果把整个流媒体比喻成一个物流系统,那么编解码就是其中配货和装货的过程,这个过程非常重要,它的速度和压缩比对物流系统的意义非常大,影响物流系统的整体速度和成本。
同样,对流媒体传输来说,编码也非常重要,它的编码性能、编码速度和编码压缩比会直接影响整个流媒体传输的用户体验和传输成本。
视频编码的意义 原始视频数据存储空间大,一个 1080P 的 7 s 视频需要 817 MB 原始视频数据传输占用带宽大,10 Mbps 的带宽传输上述 7 s 视频需要 11 分钟 而经过 H.264 编码压缩之后,视频大小只有 708 k ,10 Mbps 的带宽仅仅需要 500 ms ,可以满足实时传输的需求,所以从视频采集传感器采集来的原始视频势必要经过视频编码。
基本原理 为什么巨大的原始视频可以编码成很小的视频呢?
这其中的技术是什么呢?
核心思想就是去除冗余信息:
1)空间冗余:图像相邻像素之间有较强的相关性
2)时间冗余:视频序列的相邻图像之间内容相似
3)编码冗余:不同像素值出现的概率不同
4)视觉冗余:人的视觉系统对某些细节不敏感
5)知识冗余:规律性的结构可由先验知识和背景知识得到
编码器的选择 视频编码器经历了数十年的发展,已经从开始的只支持帧内编码演进到现如今的 H.265 和 VP9 为代表的新一代编码器,下面是一些常见的视频编码器: 1)H.264/AVC 2)HEVC/H.265 3)VP8 4)VP9 5)FFmpeg 注:音频编码器有Mp3, AAC等。