一、安装环境准备
操作系统:centos7
三台主机
hdc-data4:192.168.163.54
hdc-data5:192.168.163.55
hdc-data6:192.168.163.56
【安装环境准备每台集群机器一样的操作,或者使用scp远程拷贝】
0、创建新的虚拟机【可选】
根据安装向导创建一台虚拟机主机(其他主机使用克隆)。然后配置静态ip和主机名。重启网络服务。
step1: 配置IP
vi /etc/sysconfig/network-scripts/ofcfg-ens33
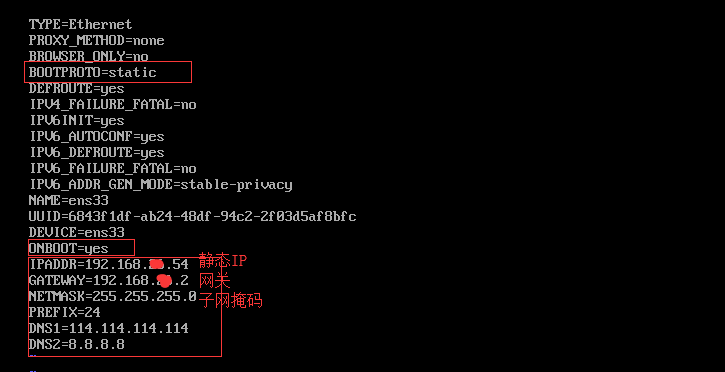 image.png
image.png
step2: 修改主机名
vi /etc/hostname
step3: 使用 init 6命令重启主机,使用ip addr查看ip
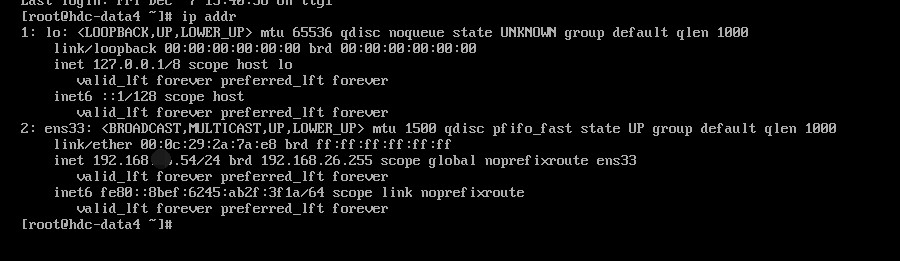 image.png
image.png
step4: 克隆主机
当前主机关机,选择虚拟机 ->管理->克隆。克隆完成修改IP和主机名重启即可。
第三步时选择【创建完整克隆(F)】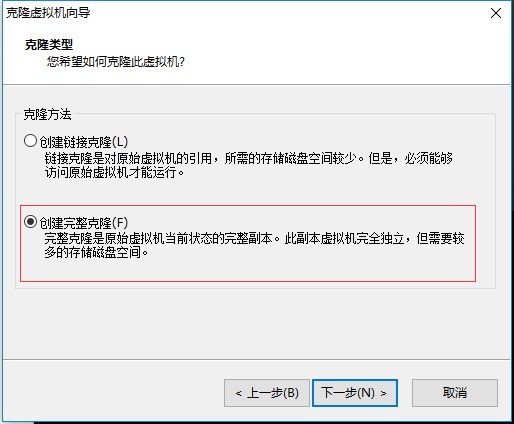 image.png
image.png
1、主机名IP映射配置
vi /etc/hosts
#添加如下地址映射
192.168.163.54 hdc-data4
192.168.163.55 hdc-data5
192.168.163.56 hdc-data6
2、SSH免密登录配置
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hdc-data4
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hdc-data5
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hdc-data6
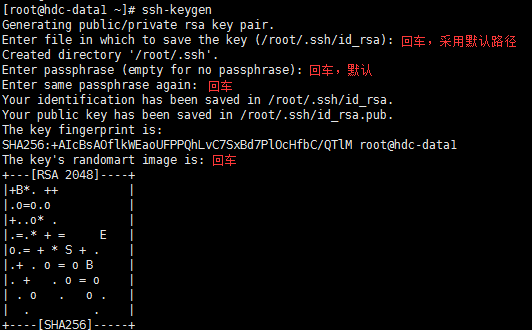 image.png
image.png
3、关闭及禁止防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
4、关闭SELinux
SELinux(Security-Enhanced Linux) 是美国国家安全局(NSA)对于强制访问控制的实现,是 Linux历史上最杰出的新安全子系统。NSA是在Linux社区的帮助下开发了一种访问控制体系,在这种访问控制体系的限制下,进程只能访问那些在他的任务中所需要文件。
vi /etc/sysconfig/selinux
#修改以下内容
SELINUX=disabled
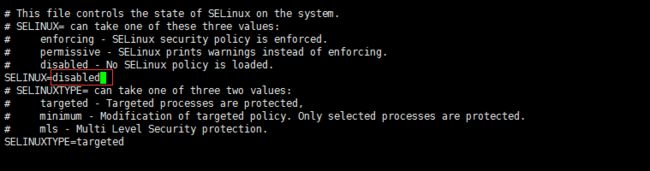 image.png
image.png
5、开启NTP服务
yum install -y ntp
systemctl enable ntpd
systemctl start ntpd
6、安装JDK
下载地址:https://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
mkdir -p /opt/java
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /opt/java/
vi /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
远程分发到其他服务器
scp -r /opt/java/jdk1.8.0_181/ root@hdc-data5:/opt/java/
scp -r /opt/java/jdk1.8.0_181/ root@hdc-data6:/opt/java/
scp /etc/profile root@hdc-data5:/etc/
scp /etc/profile root@hdc-data6:/etc/
source /etc/profile
二、安装zookeeper
mkdir -p /opt/apps
tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/
mkdir -p /data/zookeeper/data
mkdir -p /data/zookeeper/log
#每台机器myid不能相同,1,2,3...以此类推
echo 1 > /data/zookeeper/data/myid
vi /opt/zookeeper-3.4.6/conf/zoo.cfg
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/log
clientPort=2181
server.1=hdc-data4:2888:3888
server.2=hdc-data5:2888:3888
server.3=hdc-data6:2888:3888
ln -s /opt/zookeeper-3.4.6/ /opt/apps/zookeeper
vi /etc/profile
/etc/profile
export ZOOKEEPER_HOME=/opt/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
三、安装hadoop
1、下载解压hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt
ln -s /opt/hadoop-2.7.2/ /opt/apps/hadoop
vi /etc/profile
/etc/profile
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2、修改hadoop配置文件
需要修改/opt/hadoop-2.7.2/etc/hadoop/下hadoop-env.sh、core-site.xml、hdfs-site.xm、yarn-site.xml、mapred-site.xml、slaves
cd /opt/hadoop-2.7.2/etc/hadoop/
mv mapred-site.xml.template mapred-site.xml
hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_181 --第25行
core-site.xml
fs.defaultFS
hdfs://mycluster
ha.zookeeper.quorum
hdc-data4:2181,hdc-data5:2181,hdc-data6:2181
hadoop.tmp.dir
/data/hadoop
hdfs-site.xml
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hdc-data4:8020
dfs.namenode.rpc-address.mycluster.nn2
hdc-data5:8020
dfs.namenode.http-address.mycluster.nn1
hdc-data4:50070
dfs.namenode.http-address.mycluster.nn2
hdc-data5:50070
dfs.namenode.shared.edits.dir
qjournal://hdc-data4:8485;hdc-data5:8485;hdc-data6:8485/mycluster
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/data/hadoop/journalnode
yarn-site.xml
yarn.resourcemanager.hostname
hdc-data4
yarn.nodemanager.aux-services
mapreduce_shuffle
mapred-site.xml
mapreduce.framework.name
yarn
slaves
hdc-data4
hdc-data5
hdc-data6
3、同步到集群其他主机
拷贝/etc/profile文件和zookeeper、hadoop目录(保持集群hadoop配置文件一致)
scp /etc/profile root@hdc-data5:/etc/
scp /etc/profile root@hdc-data6:/etc/
scp -r /opt/zookeeper-3.4.6 root@hdc-data5:/opt/
scp -r /opt/zookeeper-3.4.6 root@hdc-data6:/opt/
scp -r /opt/hadoop-2.7.2 root@hdc-data5:/opt/
scp -r /opt/hadoop-2.7.2 root@hdc-data6:/opt/
并在被同步的主机建立软连接
ln -s /opt/zookeeper-3.4.6/ /opt/apps/zookeeper
ln -s /opt/hadoop-2.7.2/ /opt/apps/hadoop
注:若被同步主机未执行 echo [1,2,3...] > /data/zookeeper/data/myid分配zookeeper id,则需要分配唯一的id。
每台集群服务器执行 source /etc/profile使得环境变量生效
4、启动及初始化(严格按照下面步骤执行)
- 1> 在三个节点上执行如下命令启动zookeeper,并分别查看节点状态,正常情况下一个leader和两个follower。
zkServer.sh start
zkServer.sh status
- 2> hdc-data4(master)节点上启动journalnode集群 。用jps检验集群节点多了JournalNode进程。
hadoop-daemons.sh start journalnode
- 3>hdc-data4(master)上格式化HDFS
hdfs namenode -format
- 4>保持主从master历史日志一致
scp -r /data/hadoop/dfs/name root@hdc-data5:/data/hadoop/dfs/
- 5>hdc-data4(master)上格式化ZK
hdfs zkfc -formatZK
- 6>hdc-data4(master)上启动HDFS和YARN
start-all.sh
-
7>jsp查看启动进程是否正常,并通过50070和8088端口在WEBUI查看。
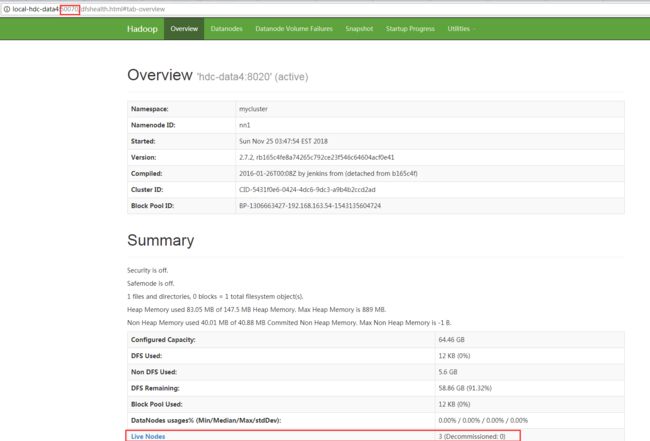 image.png
image.png