Presto作为一个计算引擎,除了支持一些常见的数字、字符串类型的数据,还支持一些别的系统里面比较少见的自定义的 IpAddress, Geometry 等等高级类型,今天来分析一下这些好玩的数据类型。
整数类型
tinyint, smallint, integer, bigint 是几种整数类型,但是跟通常的数据库不一样的是,Presto里面的数据都是 signed 类型,下面是这些数据类型的一个基本信息:
| 类型 | 类型Size(Byte) | 最大值 | 最小值 |
|---|---|---|---|
| tinyint | 1 | -128 | 127 |
| smallint | 2 | -32768 | 32767 |
| integer | 4 | -2147483648 | -2147483647 |
| bigint | 8 | -9223372036854775808 | 9223372036854775807 |
Boolean
Boolean在底层是用 Byte 来表示的, 1代表true, 0代表false。
浮点数
在一般的编程语言里面浮点数会有两种类型: float 和 double , 在Presto里面对应的是 real 和 double, real 其实就是 float, 只是用了一个更专业化的名字。
real 在Presto里面是用一个int来表示的:
@Override
public Object getObjectValue(ConnectorSession session, Block block, int position)
{
if (block.isNull(position)) {
return null;
}
return intBitsToFloat(block.getInt(position, 0)); // 看这里: block.getInt()
}
需要获取实际的值的时候才会用 Float.intBitsToFloat 来进行转换,为什么可以用一个int来表示一个float? 因为它们在内存表示的时候都是用的4个字节来表示的,占用的存储空间是一样的。
那为什么不直接用 float 自己来表示呢? 看下代码我们会发现Presto的 Block 类里面只有针对整数的方法, 没有浮点数:
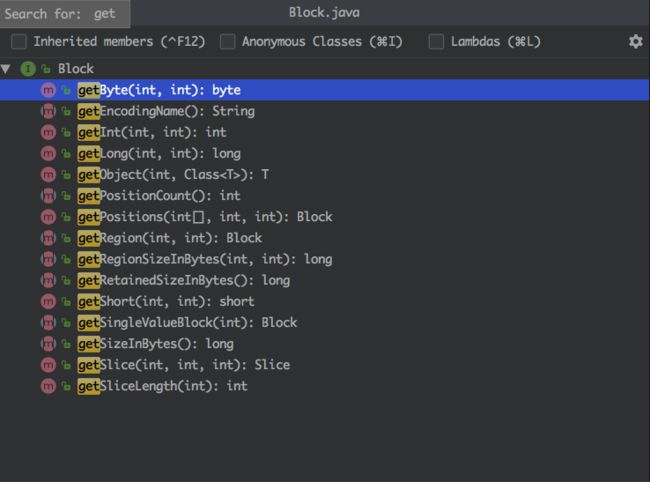
浮点数的不精确性
这里稍微展开一下,我们知道浮点数跟定点数不一样的是,它们无法精确无损的表达所有的数。以float为例,根据 IEEE-754 它在内存里面的表示方法是:

我们代码里面写的十进制的数字在内存里面实际是用如上的二进制表示的, 它一共分为三段:
- 第一位是符号位,用来表示这个数字的正负。
- 第二到九位,用来表示指数(exponent)。
- 剩下的23位,用来表示有效数字(Significant Figures)。
把上面的二进制表示换算成十进制的公式如下:
由于各种原因,10进制的整数和小数用二进制的float都可能无法准确表示,首先来看看整数,整数在理论上都是可以无损的转换成二进制的,但是由于Float一共只有32位,其中只有23位用来表示有效数字(Significant Figures), 因此即使一个很小的数用Float都可能无法无损表示,比如: 20014999 , 它的完整二进制表示应该是:
0 10010111 1001100010110011110010111 (33位)
但是由于float一共只有32位,最后几位被截断了,实际的二进制表示是:
0 10010111 00110001011001111001100 (31位)
那自然就会有精度丢失了,这就解释了虽然 2001499 不是一个很大的数,而且是一个整数,但是用float无法精确表示。
类似的,10进制的小数在理论上就不一定 能用二进制完全表示,比如 0.9 用二进制表示是:
1100 1100 1100 1100 ... (1100一直重复)
由于有效位数是无穷大的(因为在无限循环),不管你精度是多少都无法无损的表示0.9这个数。
Double类型跟Float类型有类似的特点和类似的问题。它使用52位来表示有效数字 (float是23位) ,因此它的精度更高;它有11位(float是8位)来表示指数(exponent),因此它能表示的数字的范围更大。
既然浮点数有这么明显的精度问题,为什么我们还要用? 原因在于相对于定点数来说浮点数以相同的存储空间可以表示更大范围的数字, 比如同样使用4个字节来表示,int类型能表示的最大的数字是 (2 ^ 31 - 1) , 而Float能表示的最大的数字则是: (2 − 2 ^ −23) × (2 ^ 127) 这可大的太多了,在一些非金融领域使用float, double完全没问题,但是一旦涉及到金融领域,必须要用定点数了。
定点数 Decimal
Decimal跟普通浮点数不一样的是,它在声明的时候有两个关键参数: precision 和 scale:
decimal(3, 1)
这里的 3 是precision, 而 1 是scale,所谓的 precision, 表示这个decimal的数
字里面一共有多少个digits, 而scale表示的是小数点后面可以有多少个digits, 比如我
们上面例子里面这个类型小数点前面最多2个数字,小数点后面最多1个数字, 也就是说最大值为: 99.9
decimal还有一些其它的声明形式如下:
decimal // == decimal(10, 0)
decimal(20) // == decimal(20, 0)
Decimal类型在Presto里面是用 BigInteger + (precision, scale) 信息来一起表示的:
// LongDecimalType.java
@Override
public Object getObjectValue(ConnectorSession session, Block block, int position)
{
if (block.isNull(position)) {
return null;
}
Slice slice = block.getSlice(position, 0, getFixedSize());
return new SqlDecimal(decodeUnscaledValue(slice), getPrecision(), getScale());
}
// SqlDecimal.java
public final class SqlDecimal
{
private final BigInteger unscaledValue;
private final int precision;
private final int scale;
Decimal在Presto里面又分为两种类型ShortDecimalType 和 LongDecimalType, Short的版本最大的Precision是 18, 而Long的版本最大的Precision是 38 。分两种类型的主要目的是为了性能,Short版本的性能更好,而且我们通常也确实使用Short版本的就够了。这两种版本是内部实现细节,用户不需要感知这个。
Java里面的Decimal -- BigDecimal
定点数由于完全准确的存储了数值,没有什么十进制与二进制之间的转换, 因此可以完全精准的存储数据,我们来看看Java的Decimal实现: BigDecimal是怎么保存Decimal的数据的:

我们可以看到,BigDecimal 为了优化性能和内存占用分了两种情况对数据进行存储:
- 不管是哪种情况,都通过
precision和scale两个字段来保存精度信息 - 如果数据不大(比Long.MAX_VALUE)小,那么它会直接把数字保存在intCompact里面 (intCompact其实是一个long类型的字段)。
- 如果数据确实很大,超过了Long类型的范围, 它会使用BigInteger类型的
intVal来保 存scale过后的值。- 而BigInteger里面则是通过一个int字段的
signum和 一个int数组:mag来表达。
- 而BigInteger里面则是通过一个int字段的
其实我们上面的例子里面举的这个 bigDecimal 值并不是特别大,用 double 表示 8个字节就够了,而BigDecimal来表示的时候光是一个mag的int数组就有三个int, 占用了12个byte。因此Decimal类型其实是通过空间的消耗来换取的精度的准确。
字符串类型
Presto里面支持4种字符串类型: varchar, char, varbinary, json 。
varchar 是一种可变长的字符串类型, 你可以指定一个可选的最大长度, 比如 varchar 表示这个字段的长度没有上限(unbounded), 而 varchar(10) 则表示这个字符串最大可以容纳10个字符,但是也可以只容纳5个字符,因此一个类型 varchar(5) 的值跟一个varchar(10) 的值是可能相等的。
char 是一种定长的字符串类型,跟 char 类似长度也是可选的, 你如果不写长度,那么默认长度就是1: char == char(1) 。而如果你指定了长度,而最终你数据的长度又没有那么长,那么会在尾部自动填充空格, 比如我们定义了 char(10) 类型的字段,我们填充一个 hello 进去,那么最终存储的值其实是 hello_____ (因为显示问题,这里用下划线代替空格), 因此两个不同长度类型的 char 的值是绝对不可能相等的。
varbianry 表示的一种可变长的二进制字符串(binary string), 所谓的 bianry string也是一种string, 跟普通的string的区别在于普通的string是character string, 也就是说字符串里面的元素不一样: 一个是 byte, 一个是 char。 Presto里面的varbinary目前不接受最大长度的参数,也就是说所有的 varbinary 都是unbounded。
json 类型保存的JSON类型的数据,可能是简单类型: string, boolean, 数字, 也可能是复杂类型比如: JSONObject, JSONArray等等。
时间类型
时间类型主要有7种: date, time, time with time zone, timestamp,
timestamp with time zone, interval year to month, interval day to second。
date 表示的是日期(不带时分秒部分), Presto 里面是用从 1970-01-01 到现在的天数来表示的, 从它的实现 SqlDate 就可以看出来了:
public final class SqlDate
{
private final int days;
// TODO accept long
public SqlDate(int days)
{
this.days = days;
}
...
}
time 表示的是时间(不带日期部分), Presto内部保存的是从UTC的
1970-01-01T00:00:00 到指定时间的毫秒数,由于时间跟时区是有关的,因此计算的时候一定会把当前session的时间传入加入计算的。
timestamp 这是 date 和 time 的结合,既有日期,也有时间,而且也是从UTC的1970-01-01T00:00:00开始算的,这个 timestamp 字段值的timezone取的是客户端的TimeZone.
timestamp with time zone 顾名思义, 这个类型的数据的值里面是自带了时区的, 比如: TIMESTAMP '2001-08-22 03:04:05.321 America/Los_Angeles'。
剩下的两种数据类型是 interval 类型的,表示时间的间隔。这两种类型貌似是从
Oracle 里面借鉴过来的,其中 interval day to second, 表示的是天、时、分、秒级别的时间间隔, Presto内部保存的是时间间隔用毫秒来表示的长度;而 interval year tomonth 表示的这是年、月级别的时间间隔,Presto内部保存的月份的数量。
结构化的数据类型
Presto支持三种结构化的数据类型: ARRAY, MAP, ROW。
ARRAY 很好理解,就是一个数组,数组里面的元素的类型必须一致:
mysql> select ARRAY[1, 2, 3];
+----------------+
| ARRAY[1, 2, 3] |
+----------------+
| [1, 2, 3] |
+----------------+
1 row in set (0.11 sec)
MAP 表示是一个映射类型,跟JSON不一样的是,所有的key的类型必须一致,所有value的类型也必须一致。在字面量里面,Presto是通过让用户指定两个有序ARRAY: 一个key的ARRAY,一个value的ARRAY来表达的:
mysql> select MAP(ARRAY['foo', 'bar', 'hello'], ARRAY[1, 2, 3]);
+---------------------------------------------------+
| MAP(ARRAY['foo', 'bar', 'hello'], ARRAY[1, 2, 3]) |
+---------------------------------------------------+
| {bar=2, foo=1, hello=3} |
+---------------------------------------------------+
1 row in set (0.11 sec)
在内存里面的表示,MAP 的内容这是被保存成一个一个的key-value对:
// MapType.java
for (int i = 0; i < singleMapBlock.getPositionCount(); i += 2) {
map.put(
keyType.getObjectValue(session, singleMapBlock, i),
valueType.getObjectValue(session, singleMapBlock, i + 1)
);
}
ROW 表示的是一行记录,这行记录的数据可以是各种不同的类型,比如:
mysql> select ROW(1, 2.0);
+-------------+
| ROW(1, 2.0) |
+-------------+
| [1, 2.0] |
+-------------+
1 row in set (0.32 sec)
IpAddress
IpAddress是一个蛮有意思的类型,它可以表示IPV4和IPV6的IP地址, 你可以通过下面的语句来试试这种类型:
CREATE TABLE foo (
a VARCHAR,
b BIGINT,
c IPADDRESS
)
IPADDRESS之间可以进行比较, 支持一些操作包括 =, >, '<' 等等, 同时 IPADDRESS和 VARCHAR两种类型之间可以进行CAST。比如:
CAST (ipaddress AS VARCHAR)
因为IpAdress内部存储都是以IPV6的形式来存的(IPV4也会被转成IPV6), 而IPV6是128位的,因此从存储空间占用上来看,IpAddress类似于BINARY(16)。
Geometry
Geometry类型是表示几何学上的一些信息,它表达的一一组相关的类型以及一些辅助函数的几何,比如点(Point)、线(LineStrin)、多边形(Polygon)等,用Oracle文档上的一张图来看特别直观:
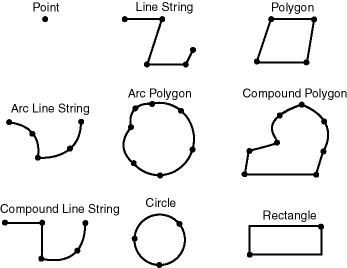
Geometry是一类很有意思的数据,Presto里面提供了大量相关的函数,比如 ST_Crosses 来判断两个几何图形是否有交集, 再比如 ST_Equals 来表示两个图形表示的是否是同一个图形等等。
BingTile
BingTile 也是一个地理位置相关的类型, 它表示的是微软Bing地图服务上地图的一个指定区域。首先Bing把整个地图映射到一个平面上面:
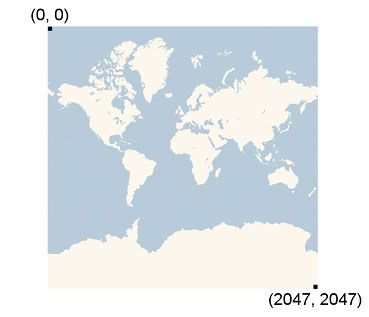
这样地球上的任何一个点都可以用一个二维的坐标 (X,Y) 来定位了。我们平时看地图的时候经常对地图进行缩放,不同程度的缩放对应的地图的详细程度是不一样的,这样地图就会有一个缩放因子的参数(zoomLevel)。相同的坐标在不通的缩放因子上对应的地理位置是不一样的。
但是通常我们获取一个坐标没太大意义,更多的时候我们是要获取指定的一块区域,为了高效的获取一个指定区域的地图,Bing把整个地球的地图分成了很多小份,每一份叫做一个 Tile, 每个 Tile 的大小是 256 x 256(pixel)。

这样每个Tile也有了坐标,我们指定特定的的缩放程度以及对应的坐标,我们就可以获得指定区域的地图了, 我们看看 Presto 的代码也可以印证这一点:
public final class BingTile
{
public static final int MAX_ZOOM_LEVEL = 23;
private final int x;
private final int y;
private final int zoomLevel;
...
}
HyperLogLog 和 P4HyperLogLog
HyperLogLog 是一种计算 count-distinct 的近似算法,我们知道要对数据集数据进行 count-distinct 的计算,需要的内存量跟要计算的数据量是成正比的,HyperLogLog算法可以对 10 ^ 9 以上的数据量进行高效的 count-distinct 计算,所需要的内存仅为 1.5KB, 而准确性为 98% 左右。P4HyerLogLog 表示的也是同一个东西,只是使用的算法稍有差异。
总结
今天我们分析了Presto里面的所有标准数据类型,除了常见的简单类型,还有一些高级的自定义类型,Presto里面添加自定义类型很简单,后面有机会专门分析一下。
参考文档
- Significant Digits(有效数字)
- Single Precision
- Double Precision
- IEEE-754
- Presto IpAddress Type
- Presto Geospatial Functions
- Geometry Types
- Presto里面的数据类型
- MySQL Varbinary
- Oracle Day-to-second
- Oracle Year-to-month
- Bing Tile System