1. Hadoop的安装
下载Hadoop安装包,通过scp(或其他指令方式)发送到虚拟机上,并进行解压安装。修改环境变量
vi /etc/profile
export JAVA_HOME="/opt/jdk1.8.0_211"
export HADOOP_HOME="/opt/hadoop-2.8.4" # hadoop安装目录
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
使用hadoop命令检查是否安装成,如下则说明安装成功

2. 伪集群配置
Hadoop正常工作必须启动两个基础的服务-hadoop和yarn。伪集群模式即在单机上启动这些服务。包括主动启动nn,dn,sn、rm、nm等
2.1 NameNode配置
修改etc目录下的core-site.xml文件,在configuration标签中添加
fs.defaultFS
hdfs://主机名1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.X.X/data/tmp
其中9000时hadoop中namenode的通信端口,此前版本时8200;
对于文件目录,不指定时存放在用户的/tmp目录,系统会自动清理,影响使用
2.2 HDFS配置
修改同目录下的hdfs-site.xml,添加如下配置
dfs.replication
3
dfs.namenode.secondary.http-address
主机名1:50090
dfs.permissions
false
对于replication数据副本的数量,在伪集群模式下,因为datanode只有一个,所以复制数量填1即可;
关闭权限-一些非root用户在权限控制下无法提交文件到hdfs,便于学习,直接关闭
2.3 Map-Reduce配置
修改配置目录下mapred-site.xml文件(默认是template可自行创建)
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
主机名1:10020
mapreduce.jobhistory.webapp.address
主机名1:19888
该配置文件指定mr的获取任务的方式通过yarn调度
2.4 配置env脚本
Hadoop的脚本hadoop-env.sh、yarn-env.sh、mapred-env.sh中,都有使用到JAVA_HOME环境变量,但是很容易出现找不到的情况,因此要手动在其中添加配置
export JAVA_HOME=/opt/jdk1.8.11_201 # jdk安装目录
3. 启动测试
3.1 执行格式化
初次启动hdfs前,需要对nameNode进行格式化
hdfs namenode -format
为什么要格式化?
NameNode用来管理HDFS的命名空间元数据,同时加入了操作日志,初始启动时,需要添加执行格式化初始化这些操作
格式化执行了哪些操作?
格式化时会清空tmp目录下dfs目录中的所有文件,并重新创建新的目录信息
3.2 启动集群
# 启动NameNode主节点
sbin/start-dfs.sh
# 启动yarn
sbin/start-yarn.sh
完全启动后看到一下5个进程

hdfs web控制台:http://host:50070

yarn web控制台:http://host:8088
3.3 文件系统测试
使用指令
hadoop fs -ls / # 查看hdfs系统根目录
hadoop fs -mkdir /root # 创建root目录
hadoop fs -put test.txt /root # 上传文件
可以实现上传并查看文件,也可以通过web控制台查看
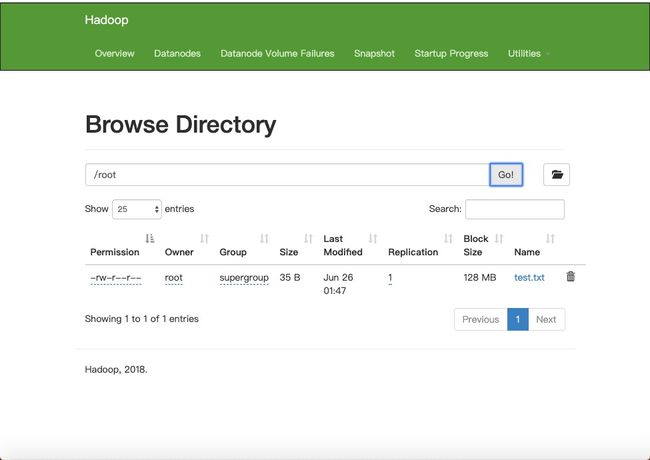
可以看到,hdfs中一个块的大小默认128M(理论最佳值,可配置),但文件实际大小只有35B。
“块”相当于一个袋子,容量最大128M,一个袋子只放一个文件。把文件放进去,不充满也不会重复使用。新的文件放在新的袋子里。
进入hdfs的文件目录,也可以看到块文件和meta文件
/opt/hadoop-2.8.4/data/tmp/dfs/data/current/BP-1797775247-192.168.56.101-1561479286518/current/finalized/subdir0/subdir0
4. 对于HDFS的目录说明
在core-site.xml中配置的hadoop.tmp.dir路径/dfs即为hdfs的根路径,其结构分为data、name、nameSecondary
/opt/hadoop-2.8.4/data/tmp/dfs
-
data目录是datanode创建,存放数据块和meta验证文件(验证数据完整性)
 block数据块
block数据块 -
name目录是namenode创建,保存操作记录(edits),系统原属记录(fsimage)等
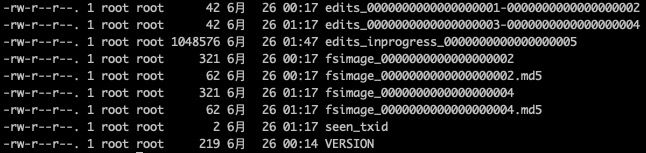 namenode元数据
namenode元数据 nameSecondary目录是secondarynamenode创建