熬夜写完,尚有不足,但仍在努力学习与总结中,而您的点赞与关注,是对我最大的鼓励!
在一些本地化项目开发当中,存在这样一种需求,即开发完成的项目,在第一次部署启动时,需能自行构建系统需要的数据库及其对应的数据库表。
若要解决这类需求,其实现在已有不少开源框架都能实现自动生成数据库表,如mybatis plus、spring JPA等,但您是否有想过,若要自行构建一套更为复杂的表结构时,这种开源框架是否也能满足呢,若满足不了话,又该如何才能实现呢?
我在前面写过一篇 Activiti工作流学习笔记(三)——自动生成28张数据库表的底层原理分析 ,里面分析过工作流Activiti自动构建28数据库表的底层原理。在我看来,学习开源框架的底层原理,其中一个原因是,须从中学到能为我所用的东西。故而,在分析理解完工作流自动构建28数据库表的底层原理之后,我决定也写一个基于Springboot框架的自行创建数据库与表的demo。我参考了工作流Activiti6.0版本的底层建表实现的逻辑,基于Springboot框架,实现项目在第一次启动时可自动构建各种复杂如多表关联等形式的数据库与表的。
整体实现思路并不复杂,大概是这样:先设计一套完整创建多表关联的数据库sql脚本,放到resource里,在springboot启动过程中,自动执行sql脚本。
首先,先一次性设计一套可行的多表关联数据库脚本,这里我主要参考使用Activiti自带的表做实现案例,因为它内部设计了众多表关联,就不额外设计了。
sql脚本的语句就是平常的create建表语句,类似如下:
create table ACT_PROCDEF_INFO ( ID_ varchar(64) not null, PROC_DEF_ID_ varchar(64) not null, REV_ integer, INFO_JSON_ID_ varchar(64), primary key (ID_) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE utf8_bin;
增加外部主键、索引——
create index ACT_IDX_INFO_PROCDEF on ACT_PROCDEF_INFO(PROC_DEF_ID_); alter table ACT_PROCDEF_INFO add constraint ACT_FK_INFO_JSON_BA foreign key (INFO_JSON_ID_) references ACT_GE_BYTEARRAY (ID_); alter table ACT_PROCDEF_INFO add constraint ACT_FK_INFO_PROCDEF foreign key (PROC_DEF_ID_) references ACT_RE_PROCDEF (ID_); alter table ACT_PROCDEF_INFO add constraint ACT_UNIQ_INFO_PROCDEF unique (PROC_DEF_ID_);
整体就是设计一套符合符合需求场景的sql语句,保存在.sql的脚本文件里,最后统一存放在resource目录下,类似如下:
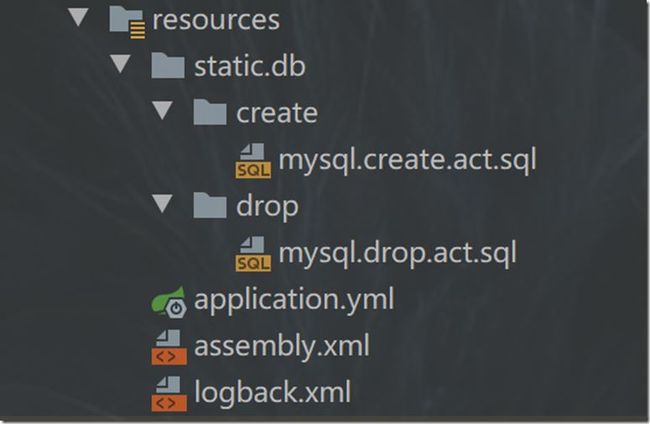
接下来,就是实现CommandLineRunner的接口,重写其run()的bean回调方法,在run方法里开发能自动建库与建表逻辑的功能。
目前,我已将开发的demo上传到了我的github,感兴趣的童鞋,可自行下载,目前能直接下下来在本地环境运行,可根据自己的实际需求针对性参考使用。
首先,在解决这类需求时,第一个先要解决的地方是,Springboot启动后如何实现只执行一次建表方法。
这里需要用到一个CommandLineRunner接口,这是Springboot自带的,实现该接口的类,其重写的run方法,会在Springboot启动完成后自动执行,该接口源码如下:
@FunctionalInterface
public interface CommandLineRunner {
/**
*用于运行bean的回调
*/
void run(String... args) throws Exception;
}
扩展一下,在Springboot中,可以定义多个实现CommandLineRunner接口类,并且可以对这些实现类中进行排序,只需要增加@Order,其重写的run方法就可以按照顺序执行,代码案例验证:
@Component
@Order(value=1)
public class WatchStartCommandSqlRunnerImpl implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("第一个Command执行");
}
@Component
@Order(value = 2)
public class WatchStartCommandSqlRunnerImpl2 implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("第二个Command执行");
}
}
控制台打印的信息如下:
第一个Command执行
第二个Command执行
根据以上的验证,因此,我们可以通过实现CommandLineRunner的接口,重写其run()的bean回调方法,用于在Springboot启动后实现只执行一次建表方法。实现项目启动建表的功能,可能还需实现判断是否已经有相应数据库,若无,则应先新建一个数据库,同时,得考虑还没有对应数据库的情况,因此,我们通过jdbc第一次连接MySQL时,应连接一个原有自带存在的库。每个MySql安装成功后,都会有一个mysql库,在第一次建立jdbc连接时,可以先连接它。

代码如下:
Class.forName("com.mysql.jdbc.Driver");
String url="jdbc:mysql://127.0.0.1:3306/mysql?useUnicode=true&characterEncoding=UTF-8&ueSSL=false&serverTimezone=GMT%2B8";
Connection conn= DriverManager.getConnection(url,"root","root");
建立与MySql软件连接后,先创建一个Statement对象,该对象是jdbc中可用于执行静态 SQL 语句并返回它所生成结果的对象,这里可以使用它来执行查找库与创建库的作用。
//创建Statement对象
Statement statment=conn.createStatement();
/**
使用statment的查询方法executeQuery("show databases like \"fte\"")
检查MySql是否有fte这个数据库
**/
ResultSet resultSet=statment.executeQuery("show databases like \"fte\"");
//若resultSet.next()为true,证明已存在;
//若false,证明还没有该库,则执行statment.executeUpdate("create database fte")创建库
if(resultSet.next()){
log.info("数据库已经存在");
}else {
log.info("数据库未存在,先创建fte数据库");
if(statment.executeUpdate("create database fte")==1){
log.info("新建数据库成功");
}
}
在数据库fte自动创建完成后,就可以在该fte库里去做建表的操作了。
我将建表的相关方法都封装到SqlSessionFactory类里,相关建表方法同样需要用到jdbc的Connection连接到数据库,因此,需要把已连接的Connection引用变量当做参数传给SqlSessionFactory的初始构造函数:
public void createTable(Connection conn,Statement stat) throws SQLException {
try {
String url="jdbc:mysql://127.0.0.1:3306/fte?useUnicode=true&characterEncoding=UTF-8&ueSSL=false&serverTimezone=GMT%2B8";
conn=DriverManager.getConnection(url,"root","root");
SqlSessionFactory sqlSessionFactory=new SqlSessionFactory(conn);
sqlSessionFactory.schemaOperationsBuild("create");
} catch (SQLException e) {
e.printStackTrace();
}finally {
stat.close();
conn.close();
}
}
初始化new SqlSessionFactory(conn)后,就可以在该对象里使用已进行连接操作的Connection对象了。
public class SqlSessionFactory{
private Connection connection ;
public SqlSessionFactory(Connection connection) {
this.connection = connection;
}
......
}
这里传参可以有两种情况,即“create”代表创建表结构的功能,“drop”代表删除表结构的功能:
sqlSessionFactory.schemaOperationsBuild("create");
进入到这个方法里,会先做一个判断——
public void schemaOperationsBuild(String type) {
switch (type){
case "drop":
this.dbSchemaDrop();break;
case "create":
this.dbSchemaCreate();break;
}
}
若是this.dbSchemaCreate(),执行建表操作:
/**
* 新增数据库表
*/
public void dbSchemaCreate() {
if (!this.isTablePresent()) {
log.info("开始执行create操作");
this.executeResource("create", "act");
log.info("执行create完成");
}
}
this.executeResource("create", "act")代表创建表名为act的数据库表——
public void executeResource(String operation, String component) {
this.executeSchemaResource(operation, component, this.getDbResource(operation, operation, component), false);
}
其中 this.getDbResource(operation, operation, component)是获取sql脚本的路径,进入到方法里,可见——
public String getDbResource(String directory, String operation, String component) {
return "static/db/" + directory + "/mysql." + operation + "." + component + ".sql";
}
接下来,读取路径下的sql脚本,生成输入流字节流:
public void executeSchemaResource(String operation, String component, String resourceName, boolean isOptional) {
InputStream inputStream = null;
try {
//读取sql脚本数据
inputStream = IoUtil.getResourceAsStream(resourceName);
if (inputStream == null) {
if (!isOptional) {
log.error("resource '" + resourceName + "' is not available");
return;
}
} else {
this.executeSchemaResource(operation, component, resourceName, inputStream);
}
} finally {
IoUtil.closeSilently(inputStream);
}
}
最后,整个执行sql脚本的核心实现在this.executeSchemaResource(operation, component, resourceName, inputStream)方法里——
/**
* 执行sql脚本
* @param operation
* @param component
* @param resourceName
* @param inputStream
*/
private void executeSchemaResource(String operation, String component, String resourceName, InputStream inputStream) {
//sql语句拼接字符串
String sqlStatement = null;
Object exceptionSqlStatement = null;
try {
/**
* 1.jdbc连接mysql数据库
*/
Connection connection = this.connection;
Exception exception = null;
/**
* 2、分行读取"static/db/create/mysql.create.act.sql"里的sql脚本数据
*/
byte[] bytes = IoUtil.readInputStream(inputStream, resourceName);
/**
* 3.将sql文件里数据分行转换成字符串,换行的地方,用转义符“\n”来代替
*/
String ddlStatements = new String(bytes);
/**
* 4.以字符流形式读取字符串数据
*/
BufferedReader reader = new BufferedReader(new StringReader(ddlStatements));
/**
* 5.根据字符串中的转义符“\n”分行读取
*/
String line = IoUtil.readNextTrimmedLine(reader);
/**
* 6.循环读取的每一行
*/
for(boolean inOraclePlsqlBlock = false; line != null; line = IoUtil.readNextTrimmedLine(reader)) {
/**
* 7.若下一行line还有数据,证明还没有全部读取,仍可执行读取
*/
if (line.length() > 0) {
/**
8.在没有拼接够一个完整建表语句时,!line.endsWith(";")会为true,
即一直循环进行拼接,当遇到";"就跳出该if语句
**/
if ((!line.endsWith(";") || inOraclePlsqlBlock) && (!line.startsWith("/") || !inOraclePlsqlBlock)) {
sqlStatement = this.addSqlStatementPiece(sqlStatement, line);
} else {
/**
9.循环拼接中若遇到符号";",就意味着,已经拼接形成一个完整的sql建表语句,例如
create table ACT_GE_PROPERTY (
NAME_ varchar(64),
VALUE_ varchar(300),
REV_ integer,
primary key (NAME_)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE utf8_bin
这样,就可以先通过代码来将该建表语句执行到数据库中,实现如下:
**/
if (inOraclePlsqlBlock) {
inOraclePlsqlBlock = false;
} else {
sqlStatement = this.addSqlStatementPiece(sqlStatement, line.substring(0, line.length() - 1));
}
/**
* 10.将建表语句字符串包装成Statement对象
*/
Statement jdbcStatement = connection.createStatement();
try {
/**
* 11.最后,执行建表语句到数据库中
*/
log.info("SQL: {}", sqlStatement);
jdbcStatement.execute(sqlStatement);
jdbcStatement.close();
} catch (Exception var27) {
log.error("problem during schema {}, statement {}", new Object[]{operation, sqlStatement, var27});
} finally {
/**
* 12.到这一步,意味着上一条sql建表语句已经执行结束,
* 若没有出现错误话,这时已经证明第一个数据库表结构已经创建完成,
* 可以开始拼接下一条建表语句,
*/
sqlStatement = null;
}
}
}
}
if (exception != null) {
throw exception;
}
} catch (Exception var29) {
log.error("couldn't " + operation + " db schema: " + exceptionSqlStatement, var29);
}
}
这部分代码主要功能是,先用字节流形式读取sql脚本里的数据,转换成字符串,其中有换行的地方用转义符“/n”来代替。接着把字符串转换成字符流BufferedReader形式读取,按照“/n”符合来划分每一行的读取,循环将读取的每行字符串进行拼接,当循环到某一行遇到“;”时,就意味着已经拼接成一个完整的create建表语句,类似这样形式——
create table ACT_PROCDEF_INFO ( ID_ varchar(64) not null, PROC_DEF_ID_ varchar(64) not null, REV_ integer, INFO_JSON_ID_ varchar(64), primary key (ID_) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE utf8_bin;
这时,就可以先将拼接好的create建表字符串,通过 jdbcStatement.execute(sqlStatement)语句来执行入库了。当执行成功时,该ACT_PROCDEF_INFO表就意味着已经创建成功,接着以BufferedReader字符流形式继续读取下一行,进行下一个数据库表结构的构建。
整个过程大概就是这个逻辑,可以在此基础上,针对更为复杂的建表结构sql语句进行设计,在项目启动时,自行执行相应的sql语句,来进行建表。
该demo代码已经上传git,可直接下载运行:https://github.com/z924931408/Springboot-AutoCreateMySqlTable.git
到此这篇关于解决Springboot项目启动后自动创建多表关联的数据库与表的方案的文章就介绍到这了,更多相关Springboot创建多表关联的数据库与表内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!