这是我在上的第二篇文章,这篇文章在微信公众号里面分两次写完的,大家可以关注我的微信公众号(机器学习和数学),第一时间阅读我的文章哦~。
这篇文章主要是我如何抓取拉勾上面AI相关的职位数据,其实抓其他工作的数据原理也是一样的,只要会了这个,其他的都可以抓下来。一共用了不到100行代码,主要抓取的信息有“职位名称”,“月薪”,“公司名称”,“公司所属行业”,“工作基本要求(经验,学历)”,“岗位描述”等。涉及的工作有“自然语言处理”,“机器学习”,“深度学习”,“人工智能”,“数据挖掘”,“算法工程师”,“机器视觉”,“语音识别”,“图像处理”等几大类。
下面随便截个图给大家看下,我们想要的信息
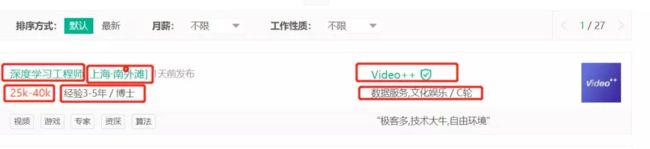

然后看下我们要的信息在哪里
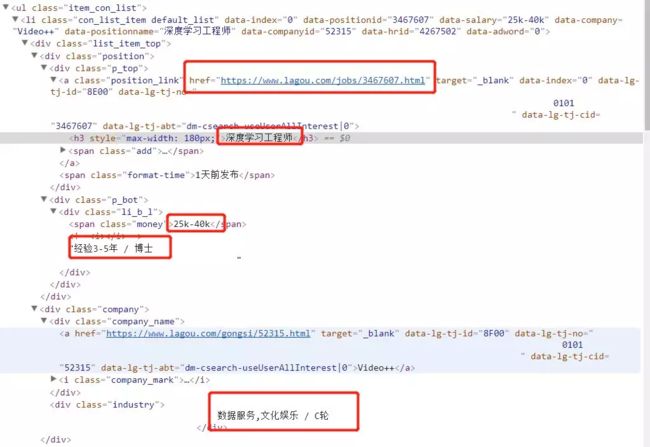
然后职位详细信息是的url就在那个href里面,所以关键是要取到那个href就OK了。
下面直接上代码
首先我们需要判断一个url是不是合法的url,就是isurl方法。
urlhelper方法是用来提取url的html内容,并在发生异常时,打一条warning的警告信息
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
import requests
from collections import OrderedDict
from tqdm import tqdm, trange
import urllib.request
from urllib import error
import logging
logging.basicConfig(level=logging.WARNING)
def isurl(url):
if requests.get(url).status_code == 200:
return True
else:
return False
def urlhelper(url):
try:
req = urllib.request.Request(url)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/45.0.2454.101 Safari/537.36")
req.add_header("Accept", "*/*")
req.add_header("Accept-Language", "zh-CN,zh;q=0.8")
data = urllib.request.urlopen(req)
html = data.read().decode('utf-8')
return html
except error.URLError as e:
logging.warning("{}".format(e))
下面就是爬虫的主程序了,里面需要注意的是异常的处理,很重要,不然万一爬了一半挂了,前面爬的又没保存就悲剧了。还有一个是想说BeautifulSoup这个类真的是十分方便,熟练使用能节省很多时间。
names = ['ziranyuyanchuli', 'jiqixuexi', 'shenduxuexi', 'rengongzhineng',
'shujuwajue', 'suanfagongchengshi', 'jiqishijue', 'yuyinshibie',
'tuxiangchuli']
fw = open("./datasets/lagou/job.txt", 'a+')
for name in tqdm(names):
savedata = []
page_number = 0
for page in range(1, 31):
rooturl = 'https://www.lagou.com/zhaopin/{}/{}/'.format(name, page)
if not isurl(rooturl):
continue
html = urlhelper(rooturl)
soup = BeautifulSoup(html, "lxml")
resp = soup.findAll('div', attrs={'class': 's_position_list'})
if len(resp) == 1:
resp = resp[0]
resp = resp.findAll('li', attrs={'class': 'con_list_item default_list'})
page_number += 1
if page_number % 5 == 0:
print(page_number)
# 保存到本地
df = pd.DataFrame(savedata)
df.to_csv("./datasets/lagou/{}_{}.csv".format(name, page_number), index=None)
savedata = []
for i in trange(len(resp)):
position_link = resp[i].findAll('a', attrs={'class': 'position_link'})
link = position_link[0]['href']
if isurl(link):
htmlnext = urlhelper(link)
soup = BeautifulSoup(htmlnext, "lxml")
try:
# 职位描述
job_bt = soup.findAll('dd',
attrs={'class': 'job_bt'})[0].text
except:
continue
try:
# 工作名称
jobname = position_link[0].find('h3').get_text()
except:
continue
try:
# 工作基本要求
p_bot = resp[i].findAll('div',
attrs={'class': 'p_bot'})[0].text
except:
continue
try:
# 月薪
money = resp[i].findAll('span',
attrs={'class': 'money'})[0].text
except:
continue
try:
# 行业
industry = resp[i].findAll('div',
attrs={'class': 'industry'})[0].text
except:
continue
try:
# 公司名字
company_name = resp[i].findAll(
'div', attrs={'class': 'company_name'})[0].text
except:
continue
rows = OrderedDict()
rows["jobname"] = jobname.replace(" ", "")
rows["money"] = money
rows["company_name"] = company_name.replace("\n", "")
rows["p_bot"] = p_bot.strip().replace(" ", ""). \
replace("\n", ",").replace("/", ",")
rows["industry"] = industry.strip(). \
replace("\t", "").replace("\n", "")
rows["job_bt"] = job_bt
savedata.append(rows)
最终修改的代码,主要是增加了异常处理,异常处理在爬虫中真的很重要,不然中间挂了,就很尴尬,还有就是数据保存的间隔,没爬5页就保存一次,防止爬虫中断,前功尽弃。
接下来,继续分析一下爬下来的数据
主要分析的是岗位职责和岗位要求,基本思路是先分词,然后统计词频,最后最词云展示出来。先看下效果

从这个图可以看出来,自然语言处理大多数需要掌握深度学习,需要用深度学习去解决问题,然后是工作经验,项目经验,以及对算法的理解。
首先分词,要正确分词,需要有一份高质量的词典,因为在岗位描述里面有好多专有名词,比如深度学习,命名实体识别,词性标注等等。我还是使用的jieba来做分词,结巴对这些词是分不出来的,所以先要建一个词典,我选了大概100个左右,然后加上公司的名字,一共400个左右。这个也可以分享给大家,非常欢迎大家补充,建立一份高质量的AI领域的专业词典,其实是非常有意义的事情,对这方面的文本分析非常有帮助。
对分词过程中标点符号的处理,有2种办法,一种是先去标点,然后分词,还有一种是先分词,然后去标点。常用的做法是先分词,然后把标点符号放在stopwords里面,这次我没有这么做,我是先按照可以划分句子、短语结构的标点符号,先把句子做切割,比如句号,一般以句号分割的两句话之间,肯定不会是一个词。最后对切割完毕的句子做分词,这样可以提高准确率,能防止分错不少词。分词的时候先把不能分割语义的标点符号先去掉,然后分词。
接下来,对上面切割好的词,统计词频,做一个词云,这里生成的词云可以做成那个样子,是因为我把本文开头的那个图片,作为背景图片,用wordcloud生成的词云就会是那个样子的。
好,直接看代码:
import os
import pandas as pd
import re
import jieba
import matplotlib.pyplot as plt
import wordcloud
from collections import OrderedDict
from tqdm import tqdm
from scipy.misc import imread
sw = []
jieba.load_userdict("./dictionary/ai.dict")
def linesplit_bysymbol(line):
# 先按句子切割,然后去标点,
line = line.replace("\n", "").replace("\r", '')
out = []
juzi = r"[\]\[\,\!\】\【\:\,\。\?\?\)\(\(\『\』\<\>\、\;\.\[\]\(\)\〔\〕\+\和\的\与\在]"
p = r"[\^\$\]\/\.\’\~\#\¥\#\&\*\%\”\“\]\[\&\×\@\]\"]"
salary_pattern = r'\d+\k\-\d+\k'
salarys = re.compile(salary_pattern).findall(line)
for salary in salarys:
out.append(salary)
linesplit = re.split(juzi, line)
for x in linesplit:
if str(x).isnumeric():
continue
if len(x) < 1:
continue
if x == '职位描述':
continue
if x == '岗位要求':
continue
if x == '岗位职责':
continue
if x == '工作职责':
continue
if x == '岗位说明':
continue
res = re.sub(p, "", x)
rescut = jieba.lcut(res)
for w in rescut:
if str(w).isdigit():
continue
out.append(w)
return " ".join(out)
def analysis(job='suanfagongchengshi'):
path = './datasets/lagou'
res = []
for file in tqdm(os.listdir(path)):
if "{}".format(job) in file:
file_name = os.path.join(path, file)
data = pd.read_csv(file_name, usecols=['job_bt', 'company_name']).values
for x in data:
rows = OrderedDict()
rows['company'] = x[0]
rows['bt'] = linesplit_bysymbol(x[1])
res.append(rows)
df = pd.DataFrame(res)
df.to_csv("./datasets/lagou/{}.csv".format(job), index=None)
下面是做词云的代码:
def plot_word_cloud(file_name, savename):
text = open(file_name, 'r', encoding='utf-8').read()
alice_coloring = imread("suanfa.jpg")
wc = wordcloud.WordCloud(background_color="white", width=918, height=978,
max_font_size=50,
mask=alice_coloring,
random_state=1,
max_words=80,
mode='RGBA',
font_path='msyh.ttf')
wc.generate(text)
image_colors = wordcloud.ImageColorGenerator(alice_coloring)
plt.axis("off")
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.figure(dpi=600)
plt.axis("off")
wc.to_file(savename)
最后,给大家提供一份我建的词典,欢迎大家补充哈~
链接:https://pan.baidu.com/s/1kWPshAR 密码:fvuy