摘要: 理解浏览器原理。
- 原文:浏览器解析 CSS 样式的过程
- 作者:前端小智
解析
一旦 CSS 被浏览器下载,CSS 解析器就会被打开来处理它遇到的任何 CSS。这可以是单个文档内的 CSS、
摘要: 理解浏览器原理。
一旦 CSS 被浏览器下载,CSS 解析器就会被打开来处理它遇到的任何 CSS。这可以是单个文档内的 CSS、
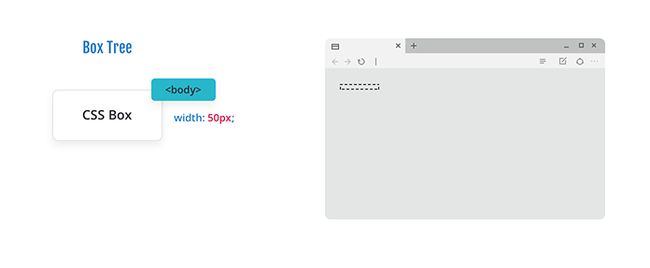
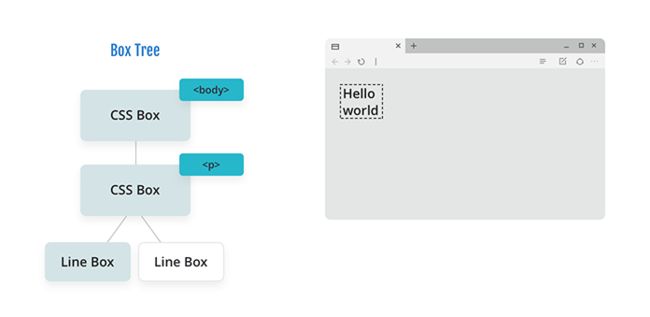
浏览器从 body 元素开始,生成它的主盒(principal box),它的宽度为50px,默认高度为auto。
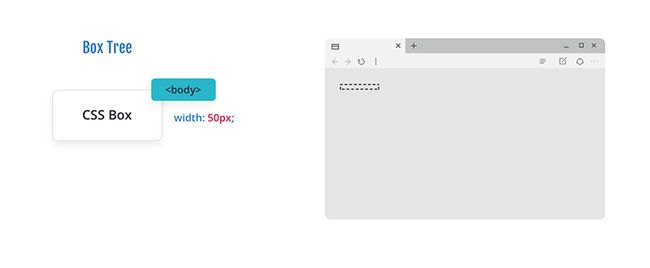
现在移动到 p 标签并生成其主盒(principal box),并且由于 p 标签默认有边距(margin),这将影响正文的高度,如下所示:
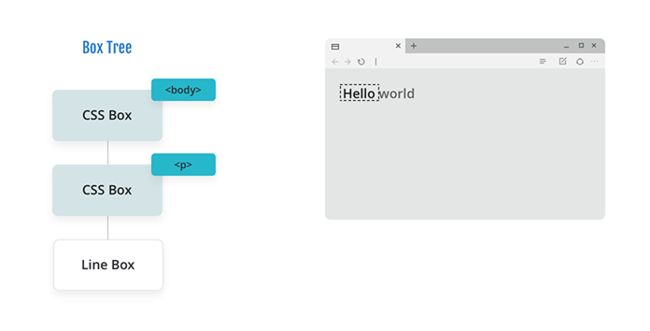
现在浏览器移动到 “Hello world” 文本,这是 DOM 中的文本节点。因此,我们在布局中生成一个 行内盒(line box) 。请注意,文本溢出了正文,我们将在下一步处理这个问题。
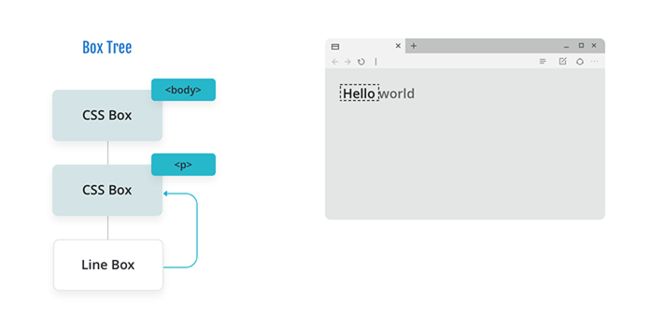
因为加上“world”长度后实际长度比较设置大并且我们没有设置 overflow 属性,所以引擎会向其父级报告它在布局文本时停止的位置。
由于父级已收到其子级无法完成所有内容布局的指令,因此它会克隆包含所有样式的 行内盒(line box),并传递该框的信息以完成布局。
布局完成后,浏览器会返回 box tree,解析尚未解决的所有基于 auto 或基于百分比的值。 在图中,可以看到正文和段落现在包含所有 “Hello world”,因为它的 height 设置为 auto。
代码部署后可能存在的 BUG 没法实时知道,事后为了解决这些 BUG,花了大量的时间进行 log 调试,这边顺便给大家推荐一个好用的 BUG 监控工具 Fundebug。
现在让布局变得更复杂一点。我们将使用一个普通布局,其中有一个按钮,内容为 “Share It”,并将其浮动到一段文本的左侧。浮动本身被认为是“shrink-to-fit” 上下文。之所以将其称为“shrink-to-fit”,是因为如果尺寸是自动的,则该框将围绕其内容进行收缩。
浮动盒子是与这种布局类型匹配的盒子的一种类型,但是还有许多其他的盒子,例如绝对定位盒子(包括 position: fixed)和基于自动调整大小的表格单元格,如下代码:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nullam
pellentesq
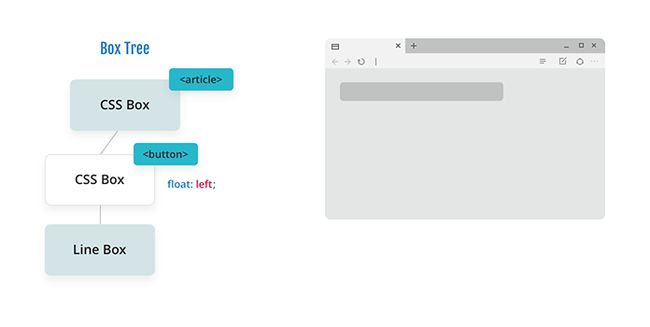
该过程开始时遵循与“Hello world”示例相同的模式,因此我将跳到我们开始处理浮动按钮的位置。
由于浮动创建了一个新的块格式化上下文(BFC),并且是一个 shrink-to-fit 上下文,因此浏览器执行一种称为内容度量的特定布局类型。
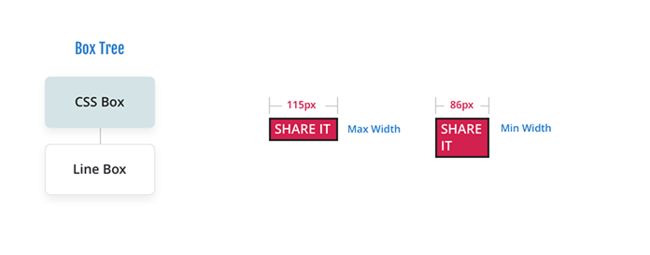
在这种模式下,它看起来与其他布局相同,但有一个重要的区别,即它是在无限空间中完成的。在此阶段,浏览器所做的就是以 BFC 的最大和最小宽度布局 BFC 树。
在本例中,它使用文本布局一个按钮,因此其最窄的大小(包括所有其他 CSS 框)将是最长单词的大小。在最宽的地方,它将是一行的所有文本,加上 CSS Box。注意:这里按钮的颜色不是文字的颜色。这只是为了说明问题。
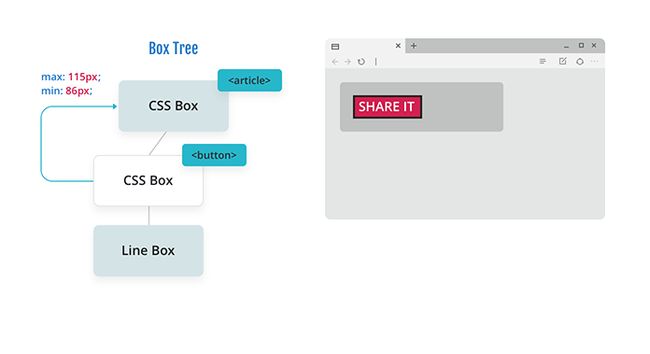
现在我们知道最小宽度是 86px,最大宽度是 115px,我们将此信息传递回父类的 box,让它决定宽度并适当地放置按钮。在这个场景中,有足够的空间来适应浮动的最大大小,这就是按钮的布局方式。
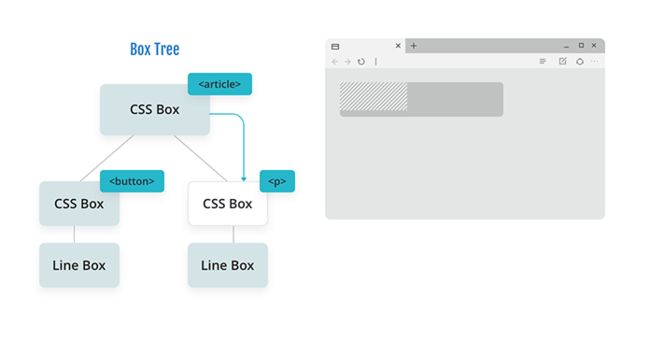
为了确保浏览器遵循标准,并且内容围绕浮动,浏览器更改了 article 的 BFC 的几何形状。这个几何图形被传递给段落,以便在段落布局期间使用。
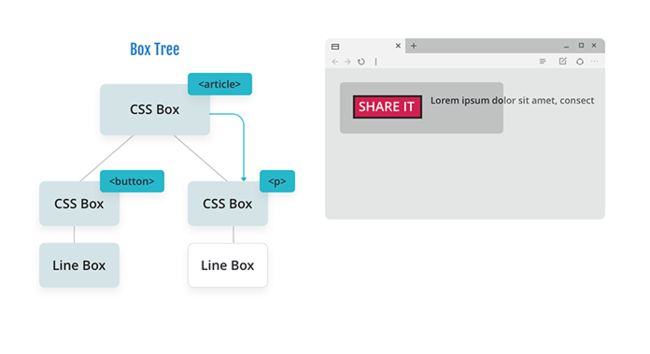
从这里开始,浏览器遵循与第一个示例相同的布局过程——但是它确保任何内联内容的内联和块的起始位置都位于浮动所占用的约束空间之外。
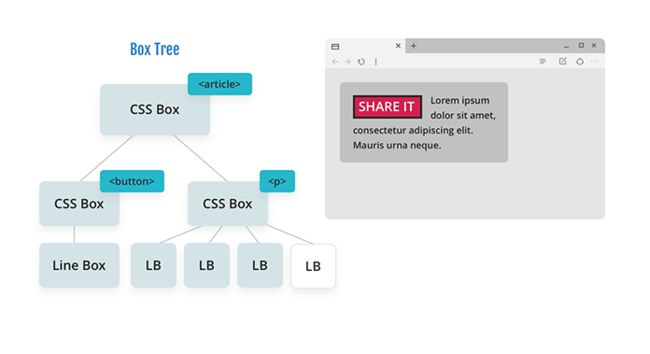
当浏览器继续沿着树向下移动并克隆节点时,它将越过约束空间的块位置。这允许最后一行文本(以及它之前的一行)以内联方向开始于 content box 的开头。然后浏览器返回到树中,根据需要解析 auto 和百分数。
关于布局如何工作的最后一个方面是碎片化。 如果你曾经打印过网页或使用过 CSS 多列,那么你已经利用了碎片。 碎片化是将内容分开以使其适合不同几何形状的逻辑。 让我们来看看同一个例子,利用 CSS 多列情况:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras nibh
orci, tincidunt eget enim et, pellentesque condimentum risus. Aenean
sollicitudin risus velit, quis tempor leo malesuada vel. Donec
consequat aliquet mauris. Vestibulum ante ipsum primis in faucibus

一旦浏览器到达 multicol 格式化上下文盒子,它就会看到它有一组设定的列。
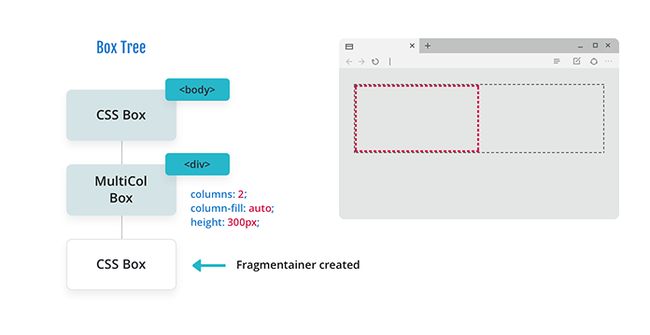
它遵循以前类似的克隆模型,并创建了一个具有正确维度的碎片处理程序,以满足作者对其列的要求。
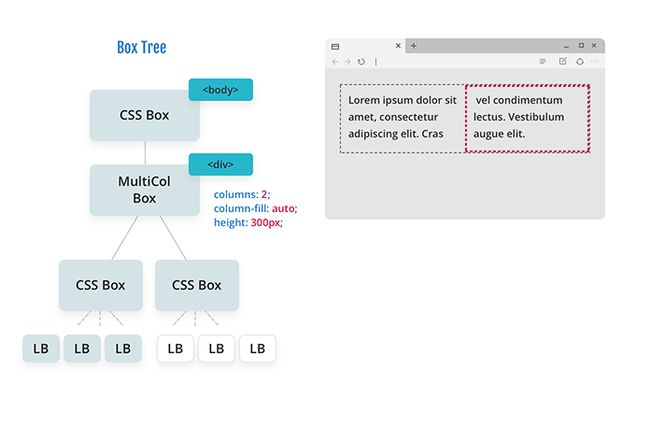
然后浏览器按照与之前相同的模式尽可能多地布局行,然后浏览器创建另一个碎片管理器,并继续完成布局。
来回顾一下我们现在的情况,我们取出所有的 CSS 内容,对其进行解析,将其级联到 DOM 树中,并完成布局。但是我们还没有对布图应用颜色、边框、阴影和类似的设计处理——处理这些过程被称为绘画。
绘画基本上是由 CSS 标准化的,简单地说,你可以按照以下顺序绘画:
更多绘画的顺序可查看 CSS 2.2 Appendix E。
因此,如果我们从前面的“SHARE IT”按钮开始,并遵循这个过程,它绘制过程大致如下:

完成后,它将转换为位图,最终每个布局元素(甚至文本)都成为引擎中的图像。
现在,我们大多数的网站都不是由单一的元素组成的。此外,我们经常希望某些元素出现在其他元素之上。为了实现这一点,我们可以利用 z-index 的特性将一个元素叠加到另一个元素上。
这可能感觉就像我们在设计软件中使用图层一样,但是唯一存在的图层是在浏览器的合成器中。看起来好像我们在使用 z-index 创建新层,但实际上并不是这样,那么到底是怎么样呢?
我们要做的是创建一个新的堆栈上下文。创建一个新的堆叠上下文可以有效地改变你绘制元素的顺序。让我们来看一个例子:
Item 1
Item 2
如果没有使用 z-index,上面的文档将按照文档顺序绘制,这将把 “Item 2” 置于 “Item 1” 之上。但由于 z-index 的影响,绘画顺序发生了变化。让我们逐步完成每个阶段,类似于我们之前完成布局的方式。
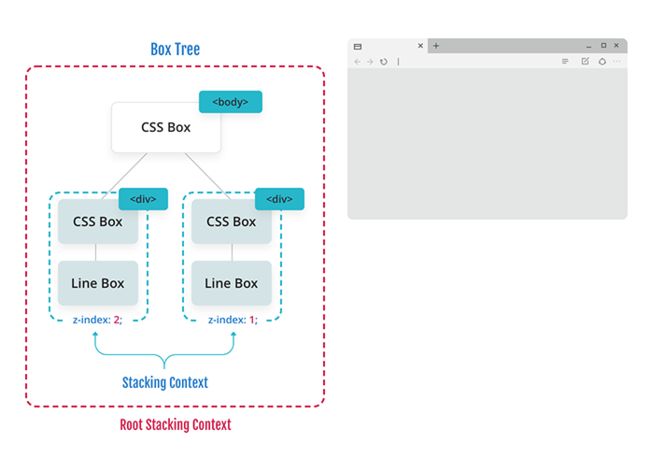
浏览器以根框开头,我们在后台画画。
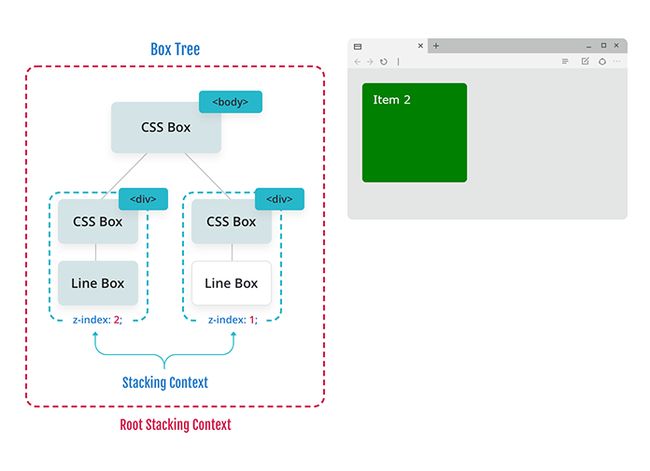
然后浏览器按照文档顺序遍历较低层次的堆栈上下文(在本例中是“Item 2”),并开始按照上面的规则绘制该元素。
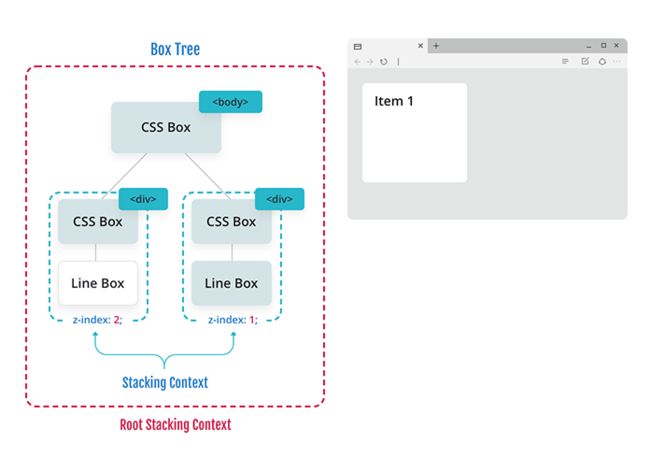
然后它遍历到下一个最高的堆栈上下文(在本例中是“Item 1”),并按照 CSS 2.2 中定义的顺序绘制它。
z-index 不影响颜色,只影响哪些元素对用户可见,因此也不影响哪些文本和颜色可见。
在这个阶段,我们至少有一个位图从绘画传递到合成。合成程序的工作是创建一个或多个层,并将位图呈现到屏幕上供最终用户查看。
此时一个合理的问题是,“为什么任何站点都需要不止一个位图或合成层?”,根据我们目前看到的例子,我们真的不会这么做。我们来看一个稍微复杂一点的例子。假设在一个假设的世界中,Office 团队想让 Clippy 重新上线,他们想通过 CS S 转换让 Clippy 跳动来吸引人们对他的注意。
动画 Clippy 的代码可以是这样的:
当浏览器读取 web 开发人员希望在无限循环中为 Clippy 添加动画时,它有两个选项:
在大多数情况下,浏览器将选择选项 2 并生成以下内容(我有意简化了 Word Online 为此示例生成的图层数量):

然后,它将重新组合剪辑位图在正确的位置,并处理脉动动画。这对于性能来说是一个很好的优势,因为在许多引擎中,合成程序是在它自己的线程上的,这样就可以解除主线程的阻塞。如果浏览器选择上面的选项 1,它将不得不阻塞每一帧以完成相同的结果,这将对最终用户的性能和响应能力产生负面影响。
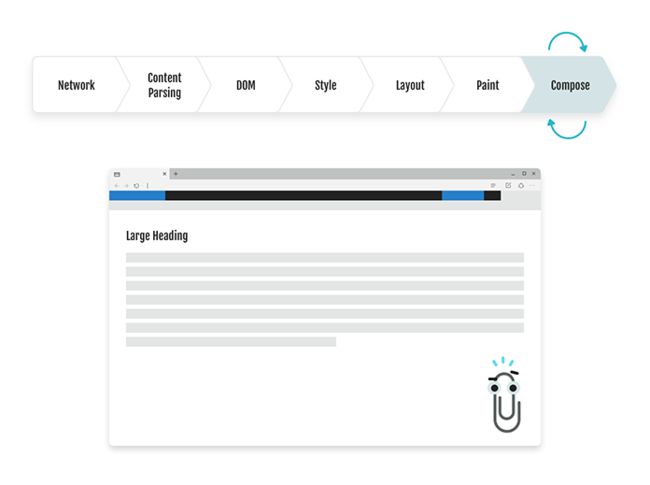
正如我们刚刚了解到的,我们使用了所有的样式和 DOM,并生成了一个呈现给最终用户的图像。那么浏览器如何创建交互性的假象呢?嗯,我相信你现在已经学过了,所以让我们看一个例子,用我们的 “SHARE IT” 按钮作为类比:
button {
float: left;
background: rgb(210, 32, 79);
padding: 3px 10px;
border: 2px solid black;
}
button:hover {
background: teal;
color: black;
}
我们在这里添加的是一个伪类,它告诉浏览器在用户悬停在按钮上时更改按钮的背景和文本颜色。这就引出了一个问题,浏览器如何处理这个问题?
浏览器不断跟踪各种输入,当这些输入正在移动时,它会经历称为命中测试的过程。 对于此示例,该过程如下所示:
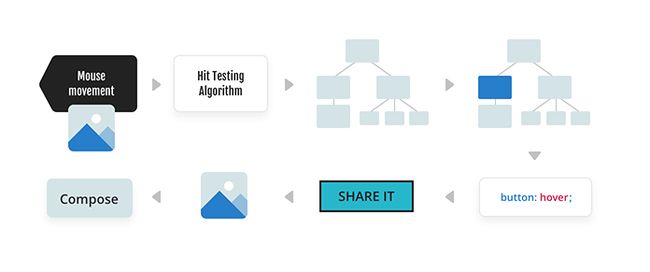
:hover 在声明块内部有一个仅使用绘制样式调整的伪类。希望这部分对你关于 css 解析过程多多少少有点帮助,共进步!
Fundebug专注于JavaScript、微信小程序、微信小游戏、支付宝小程序、React Native、Node.js和Java线上应用实时BUG监控。 自从2016年双十一正式上线,Fundebug累计处理了10亿+错误事件,付费客户有Google、360、金山软件、百姓网等众多品牌企业。欢迎大家免费试用!
