
内容来源:2017年6月11日,饿了么数据专家翟玉勇在“饿了么&七牛云联合论坛 大数据最新场景化应用实践”进行《cassandra在饿了么的应用》演讲分享。IT 大咖说(ID:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:1759 | 4分钟阅读
获取嘉宾演讲视频回放及PPT,请点击:http://t.cn/RF2KHyL

摘要
1、饿了么大数据为什么选择cassandra
2、 Cassandra的基本原理
3、饿了么cassandra实践
4、 Cassandra和大数据离线平台的结合
Cassandra历史
Google的三大论文其中有一个叫BigTable,Amazon有一个kv存储叫Dynamo。Facebook根据Google和Amazon的这两个自己创造出了Cassandra。2008年,Facebook放弃了Cassandra,把它交给了Apache。
Cassandra概述
Cassandra最初源自Facebook,集合了Google BigTable面向列的特性和Amazon Dynamo分布式哈希(DHT)的P2P特性于一身,具有很高的性能、可扩展性、容错、部署简单等特点。
Cassandra架构关键字
1、Gossip 点对点通信协议,用于集群之间节点交换位置和状态信息。
2、Partitioner 决定如何在集群中的节点间分发数据,也就是哪个节点放止数据的第一个replica。
3、Replica Strategy 决定在哪些节点放置数据的其他replica。
4、Snitch 定义了复制策略用来放置replicas和路由请求所使用的拓扑信息。
Gossip-节点的通信
Cassandra使用点对点通信协议Gossip在集群中的节点间交换位置和状态信息。Gossip进程每秒运行一次,与最多3个其他节点交换信息,这样所有的节点可很快的了解集群中其他节点信息。
1、种子节点。它的作用就是让其它节点来认识到这个集群在哪里,如何与集群连上关系。
2、Cassandra故障探测。Cassandra协议就是每个进程每秒最多会和三个其它节点做交互,判断它是否存活。
3、Cassandra故障修复。当一个节点挂了,但不代表它从这个集群中移走了,而只是暂时offline。当它再拉起来的时候,Gossip系统也能探测到它活了,并加入到集群中去。
Partitioner
Partitioner定义了数据如何在集群中的节点分布,哪个节点应该存放数据的第一份拷贝。基本上,Partitioner就是一个计算分区键token的哈希函数。
Partitioner中分为三大类。Partition Key 决定数据在Cassandra哪个节点上,Clustering Key 用于在各个分区内的排序,Primary Key 主键决定数据行的唯一性。


Replica Strategy
Cassandra在多个节点中存放replicas以保证可靠性和容错性。Replica Strategy决定放置replicas的节点,replicas的数目由复制因子确定,比如通常设置3表示每行数据有三份拷贝,每份数据存储在不同的节点。
当前可用的两种复制策略:
1、SimpleStrategy 仅用于但数据中心
CREATEKEYSPACE dw WITH replication = {'class':'SimpleStrategy', ‘replication_factor': 3}
2、NetworkTopologyStrategy 用于多IDC场景,可指定每个IDC有多少replicas
CREATEKEYSPACE dw WITH replication = {'class':'NetworkTopologyStrategy', 'DC-SH' : 2,'DC-BG' : 2}
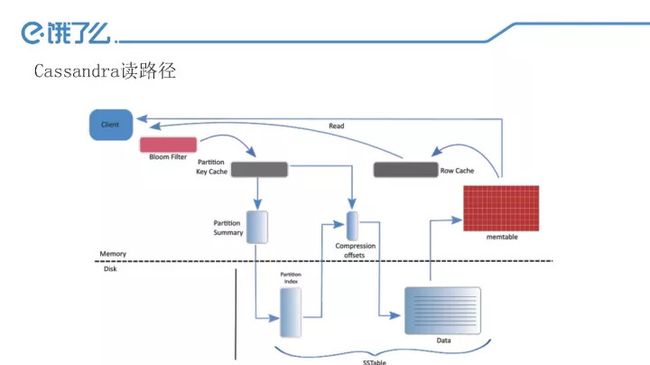
Cassandra主要的数据结构
Memtable:它的本质是java里的跳表。
SSTable:最终存放的数据落地在磁盘的结构。
BloomFilter:高效地用最少的内存来判断数据是否存在。

CQL语言
CQL类似于SQL,支持DDL操作create table,drop table等,也支持DML操作INSERT、UPDATE、DELETE等等,通过select进行数据查询。
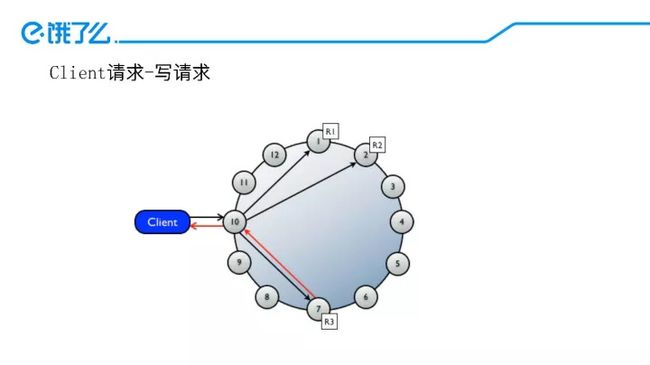


Cassandra一致性保障
在Cassandra中,有三重策略来保障Cassandra达到最终的一致性。
HintedHandoff:如果写了三个副本,只要有两个响应就可以。但是假如有一个节点挂了,Cassandra可以把本来要写到这个节点的数据写到另一个节点上。等挂了的节点拉起来之后,再把这个数据写回去,以保证三份数据同时写成功了。
ReadRepair:当一个读的请求发起之后,可以触发后台一个线程检查这三个数据的副本数据是否一致,如果不一致再进行修复。
Anti-EntropyNode Repair:主动把自己节点的key和其它节点的key进行比较,不一致的进行修复。
为什么选择Cassandra
运维成本:部署简单,只需要运维一个组件,监控成本低。
开发成本:类似sql的cql语言,对开发友好,低成本上手;DataStax公司提供的强大的java client;可调节的数据一致性;异步接口。
适用场景:Cassandra自带多idc策略、我们的业务需求。
Cassandra在饿了么的实践
生产应用(用户画像、历时订单、dt.api)、Client选择、运维和监控以及性能调优。
生产应用-用户画像
我们的用户画像用了5 个节点,超过2.6亿的饿了么用户数据,100+的用户属性,每天有5000万+数据更新,Scheme变更频繁(加字段),99%的读延时能控制在3-5ms之内。
生产应用-历史订单
我们采用了Sata盘集群,它对我们的响应时间并不是要求很高,平均响应时间小于80ms。这个集群大概有15个节点。
生产应用-dt.api
Dt.api是一个饿了么大数据平台自助化数据接口平台。用户在这个平台上只要写出一个SQL,它就会自动生成一个HTTP或SOA接口。当前这里有50+ 基于Cassandra的CQL API生成。
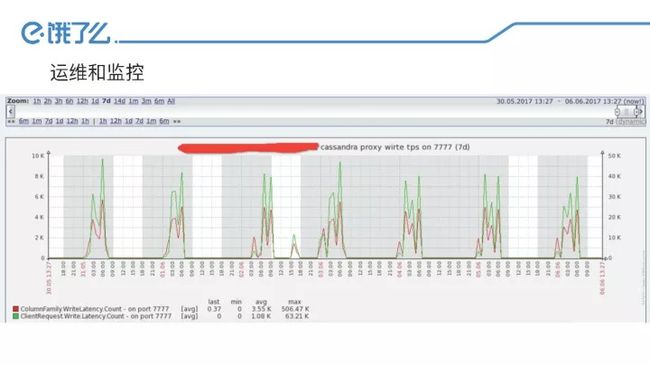
运维和监控
ansible自动部署:Cassandra的端口必须绑定到内网IP,用ansible进行自动部署特别方便。
Zabbix监控:饿了么大数据平台的监控主要是Zabbix。
性能调优-集群调优化
集群参数设置
1、memtable_allocation_type
heap_buffers:on heap nio buffer
offheap_buffers:off heap(direct) nio buffers
offheap_objects:native memory
2、concurrent_write和concurrent_read
3、Sstable compression
4、Concurrent compactor
5、memtable_flush_writers
6、Netty io线程数目
JVM调优化
1、堆的大小选择
2、取消偏向锁
Scheme设计优化
1、Primary key设计,避免热点
2、关闭读修复
3、Compaction strategy策略选择
4、Ttl设置
5、Row cache启用
大数据离线平台和Cassandra的整合

两大数据推送Cassandra工具
HiveIntegrate Cassandra Native Protocol:
1.Hive外部表映射到Cassandra表
2.InsertInto HiveTable Select 简单快捷
3.跨机房推送限流/限速
4.异步写
HiveIntegrate Cassandra Bulkload:

1.hive生成Cassandra底层的SSTable文件直接load到Cassandra。
2.适用于数据快速初始化。
3.需要控制生成的SSTable大小避免Compact耗时多久。

我今天的分享就到这里,谢谢大家!