集群
1.Redis 集群的优势
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
特点
主从复制
实现了高可用
数据分片存储
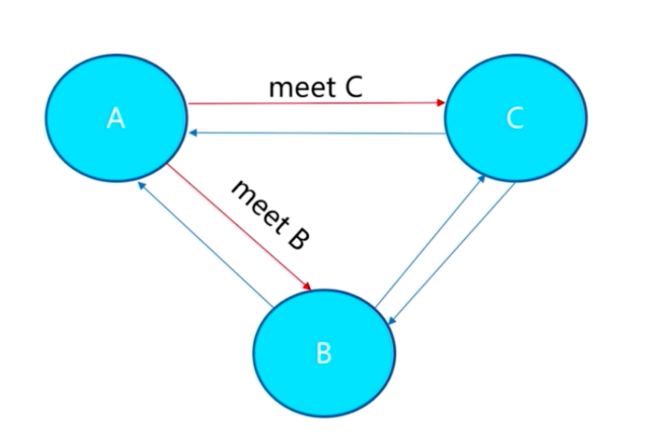
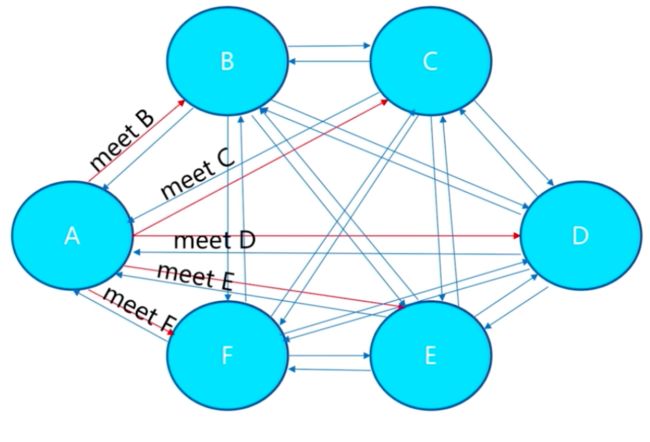
集群节点的 meet 过程
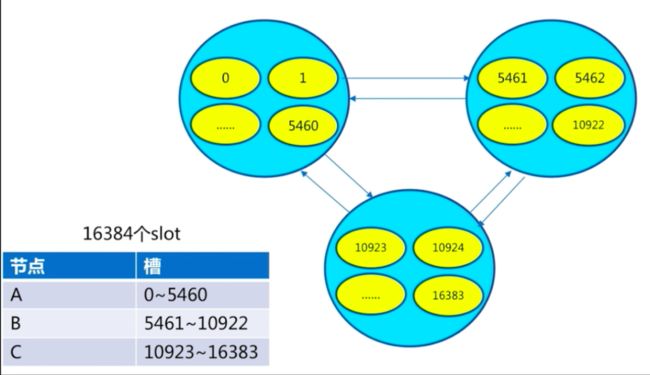
指派槽
客户端和槽

3. Redis 集群的安装
原生命令安装
步骤
配置开启集群节点
配置
meet指派槽
配置主从
实例操作
准备两台虚拟机:
一台启动三个 Redis 实例作为 主节点
另一台启动三个 Redis 实例作为 从节点
架构图

一、在一台服务器上手动部署 redis 集群
在一台服务器上启动六个 Redis 实例,三台作为主节点,三台作为从节点
实验步骤
- 先编辑一个集群的配置文件
编译配置文件 /etc/redis/7001.conf, 添加如下内容:
bind 0.0.0.0
port 7001
daemonize yes
# 允许任何地址不使用密码访问我
protected-mode yes
dir "/redis/data/"
logfile "cluster-7001.log"
dbfilename "cluster-dump-7001.log"
cluster-enabled yes
cluster-config-file cluster-redis-7001.conf
# 不需要集群的全部节点完好才提供服务
cluster-require-full-coverage no
-
再创建其他集群的配置文件
 image
image
sed 's/7001/7002/g' 7001.conf > 7002.conf
sed 's/7001/7003/g' 7001.conf > 7003.conf
sed 's/7001/7004/g' 7001.conf > 7011.conf
sed 's/7001/7005/g' 7001.conf > 7012.conf
sed 's/7001/7006/g' 7001.conf > 7013.conf
3.启动 redis 进程
mkdir -p /redis/data
redis-server /etc/redis/7001.conf
redis-server /etc/redis/7002.conf
redis-server /etc/redis/7003.conf
redis-server /etc/redis/7011.conf
redis-server /etc/redis/7012.conf
redis-server /etc/redis/7013.conf
4.检查进程
ps aux| grep redis-server

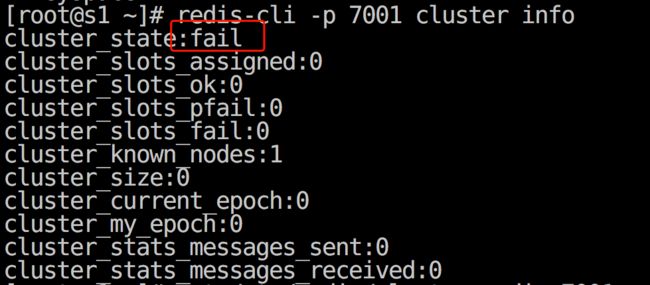
假设你现在去连接到任意一个节点上执行操作会返回集群目前是没有启动的信息。
原因是目前集群各节点之间没有进行 meet 操作,都是各自孤立的状态。

可以使用如下命令查看集群的相关信息
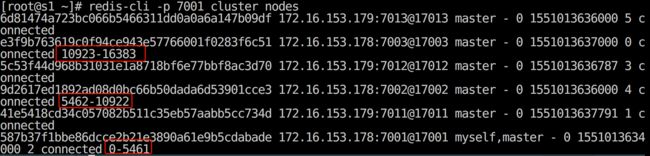
还可以查看某一个集群节点信息,第一列是集群节点 ID

- 集群节点之间的
meet
我们下面使用主节点127.0.0.1:7001去依次的meet其他 5 个节点。
redis-cli -p 7001 cluster meet 127.0.0.1 7002
redis-cli -p 7001 cluster meet 127.0.0.1 7003
redis-cli -p 7001 cluster meet 127.0.0.1 7004
redis-cli -p 7001 cluster meet 127.0.0.1 7005
redis-cli -p 7001 cluster meet 127.0.0.1 7006
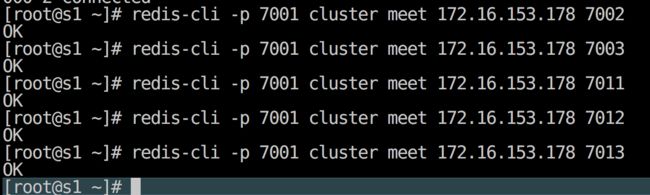
查看集群信息和节点 信息


- 给集群节点分配
数据槽
集群的槽号是 从0开始,到16383结束,共16384个。
槽的分配是拿 16384 除以集群中主节点的个数,得到每个主节点应该被分配给槽的数量。
所以现在的计划是:

命令
redis-cli -h 被添加的主机 IP -p 端口 cluster addslots 槽号
假如给
7001分配 0 号槽。命令应该是:redis-cli -h 172.16.153.178 -p 7001 cluster addslots 0每次只能分配一个 槽号,所以我们可以写个脚本,当然这种方式是不会在生产环境中使用的,这里只是为了理解集群的架构关系。
脚本
#!/bin/sh
target_host_ip=$1
target_host_port=$2
star=$3
end=$4
for slot in $(seq ${star} ${end})
do
echo "正在给 ${target_host_ip} ${target_host_port} 添加${slot}"
redis-cli -h ${target_host_ip} -p ${target_host_port} cluster addslots ${slot}
done
使用脚本
sh mutil-addslots.sh 172.16.153.178 7002 5462 10922
sh mutil-addslots.sh 172.16.153.178 7003 10923 16383
多线程版
target_host_ip=$1
target_host_port=$2
star=$3
end=$4
num=$5
mkfifo t # 创建命名管道文件
exec 7<>t # 给命名管道起个文件描述符
rm -rf t # 删除这个命名管道文件,但是管道依然存在,可以使用文件描述符 7 进行使用。
for i in $(seq 1 ${num}) # 向这个管道中输入相应数据的空行
do
echo >&7 # 每一行就是一次并发
done
for slot in $(seq ${star} ${end})
do
read -u7 # 这个不能变
{
echo " 主机 ${target_host_ip} 端口 ${target_host_port} 数据槽 ${slot}"
redis-cli -h ${target_host_ip} -p ${target_host_port} \
cluster addslots ${slot}
echo >&7
}&
done
wait # 这个不能变, 就是等待上面的所有后台进程结束
exec 7>&- # 这个不能变,
echo "任务执行完毕"
最后查看集群信息
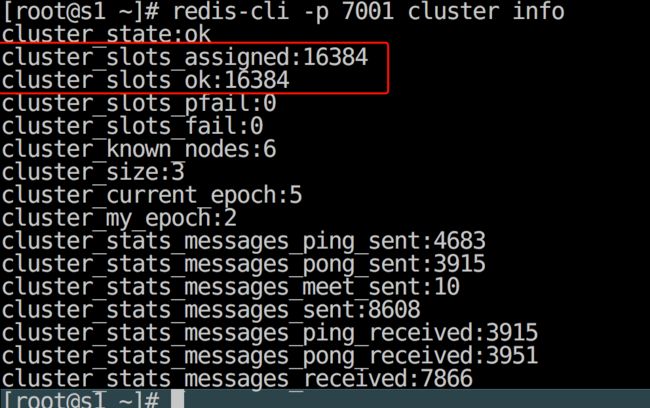
可以发现此时集群的状态是
OK的。
查看节点信息
- 给集群节点配置主从关系
命令语法
redis-cli -p 从节点端口 cluster replicate 主节点的 ID
实操
切换到从节点所在的主机,这样有便于操作
先获取到集群各个节点的 ID

再按照计划好的进行复制关系的设置
[root@s2 ~]# redis-cli -p 7011 cluster replicate 587b37f1bbe86dcce2b21e3890a61e9b5cdabade
OK
[root@s2 ~]# redis-cli -p 7012 cluster replicate 9d2617ed1892ad08d0bc66b50dada6d53901cce3
OK
[root@s2 ~]# redis-cli -p 7013 cluster replicate e3f9b763619c0f94ce943e57766001f0283f6c51
OK
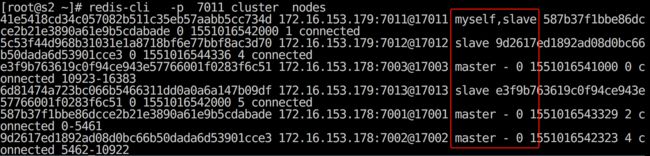
查看集群节点信息,验证主从关系
redis-cli -p 7011 cluster nodes
完全配置好后,可以观察集群的数据槽的分配情况
redis-cli -p 7011 cluster slots
最后用客户端登录集群的方式登录到集群中的任意一个节点,设置键值对进行测试。

二、使用官方工具 redis-trib.rb 进行部署
官方工具依赖于 Ruby
1. 下载、编译、安装 Ruby
点我到下载页面
wget https://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.1.tar.gz
安装依赖包
yum install zlib-devel readline openssl-devel gcc gcc-c++
点我查看具体安装方法
tar xf ruby-2.6.1.tar.gz
cd ruby-2.6.1
./configure
make && make install
2. 安装 rubygem redis
一个 ruby 语言实现的访问 Redis 集群的客户端
点我到官网下载地址
cd ..
wget https://rubygems.org/rubygems/rubygems-3.0.2.tgz
tar -xf rubygems-3.0.2.tgz
cd rubygems-3.0.2/
ruby setup.rb
gem install redis
3. 安装 redis-trib.rb
redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
cp ~/redis-4.0.10/src/redis-trib.rb /usr/local/bin/
chmod +x redis-trib.rb
没有源码安装的可以从以下网址获取
Redis 源码 src 中的 redis-trib.rb 文件内容
create:创建集群
check:检查集群
info:查看集群信息
fix:修复集群
reshard:在线迁移slot
rebalance:平衡集群节点slot数量
add-node:添加新节点
del-node:删除节点
set-timeout:设置节点的超时时间
call:在集群所有节点上执行命令
import:将外部redis数据导入集群
配置集群
假如你完全安装这个文档做的实验的换,此时配置集群之前,需要把之前的集群进程都停掉。
先在从节点上执行,再到主节点上执行
ps -ef | grep redis-server | grep -v 'grep' | awk '{print $2}' |xargs kill
接着分别在两台主机上,把之前集群产生的数据清除
rm -rf /redis/data/*
再重新启动这些节点的服务进程
redis-server 7001.conf
redis-server 7002.conf
redis-server 7003.conf
redis-server 7011.conf
redis-server 7012.conf
redis-server 7013.conf
之后使用如下命令创建集群
redis-trib.rb create --replicas 1 主节点1的IP:端口 主节点2的IP:端口 主节点3的IP:端口 从节点1的IP:端口 从节点2的IP:端口 从节点3的IP:端口
选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006



创建流程如下:
1、首先为每个节点创建ClusterNode对象,包括连接每个节点。检查每个节点是否为独立且db为空的节点。执行load_info方法导入节点信息。
2、检查传入的master节点数量是否大于等于3个。只有大于3个节点才能组成集群。
3、计算每个master需要分配的slot数量,以及给master分配slave。分配的算法大致如下:
先把节点按照host分类,这样保证master节点能分配到更多的主机中。
不停遍历遍历host列表,从每个host列表中弹出一个节点,放入interleaved数组。直到所有的节点都弹出为止。
master节点列表就是interleaved前面的master数量的节点列表。保存在masters数组。
计算每个master节点负责的slot数量,保存在slots_per_node对象,用slot总数除以master数量取整即可。
遍历masters数组,每个master分配slots_per_node个slot,最后一个master,分配到16384个slot为止。
接下来为master分配slave,分配算法会尽量保证master和slave节点不在同一台主机上。对于分配完指定slave数量的节点,还有多余的节点,也会为这些节点寻找master。分配算法会遍历两次masters数组。
第一次遍历masters数组,在余下的节点列表找到replicas数量个slave。每个slave为第一个和master节点host不一样的节点,如果没有不一样的节点,则直接取出余下列表的第一个节点。
第二次遍历是在对于节点数除以replicas不为整数,则会多余一部分节点。遍历的方式跟第一次一样,只是第一次会一次性给master分配replicas数量个slave,而第二次遍历只分配一个,直到余下的节点被全部分配出去。
4、打印出分配信息,并提示用户输入“yes”确认是否按照打印出来的分配方式创建集群。
5、输入“yes”后,会执行flush_nodes_config操作,该操作执行前面的分配结果,给master分配slot,让slave复制master,对于还没有握手(cluster meet)的节点,slave复制操作无法完成,不过没关系,flush_nodes_config操作出现异常会很快返回,后续握手后会再次执行flush_nodes_config。
6、给每个节点分配epoch,遍历节点,每个节点分配的epoch比之前节点大1。
7、节点间开始相互握手,握手的方式为节点列表的其他节点跟第一个节点握手。
8、然后每隔1秒检查一次各个节点是否已经消息同步完成,使用ClusterNode的get_config_signature方法,检查的算法为获取每个节点cluster nodes信息,排序每个节点,组装成node_id1:slots|node_id2:slot2|...的字符串。如果每个节点获得字符串都相同,即认为握手成功。
9、此后会再执行一次flush_nodes_config,这次主要是为了完成slave复制操作。
10、最后再执行check_cluster,全面检查一次集群状态。包括和前面握手时检查一样的方式再检查一遍。确认没有迁移的节点。确认所有的slot都被分配出去了。
11、至此完成了整个创建流程,返回[OK] All 16384 slots covered.。
4. 深入集群
集群的伸缩
添加节点(扩容)
-
准备节点
 image
image
启动两个新的 redis 实例, 分别监听不同端口 比如 7008 和 7009
我这里是在一台主机上启动 redis 实例

cp 7001.conf 7008.conf
sed -i 's/7001/7008/g' 7008.conf
cp 7001.conf 7014.conf
sed -i 's/7001/7009/g' 7014.conf
redis-server 7008.conf
redis-server 7014.conf
2.加入集群中
添加一个新的节点为主节点
redis-trib.rb add-node new_host:new_port existing_host:existing_port
// new_host:new_port 为新添加的节点信息
// existing_host:existing_port 集群中任意节点的信息
添加一个新节点为从节点
redis-trib.rb add-node --slave --master-id 主节点的 ID new_host:new_port existing_host:existing_port
主节点 ID 可以使用如下命令查看,此命令还同时输出了各个节点的角色
redis-trib.rb check host:port
// host:port 为集群中任意节点的信息
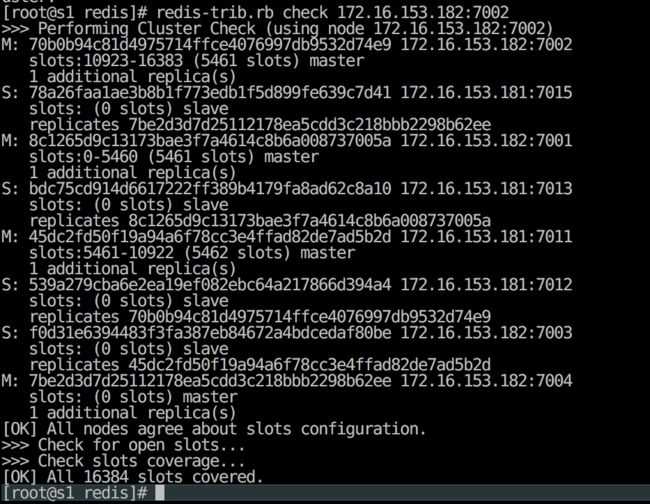
例如:
加入一个主节点到集群中
redis-trib.rb add-node 127.0.0.1:7008 127.0.0.1:7002
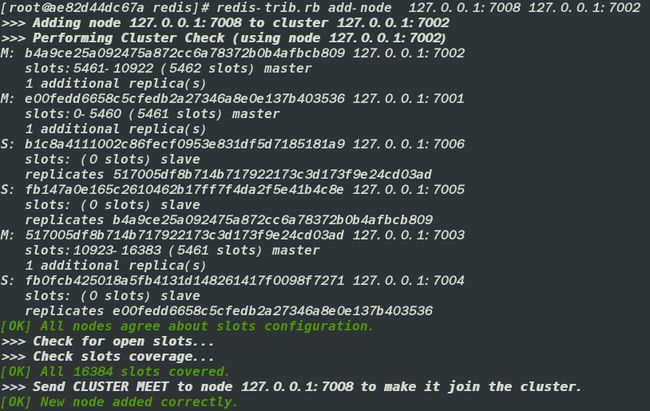
- 获取刚才新加入的主节点信息
redis-trib.rb check 127.0.0.1:7002
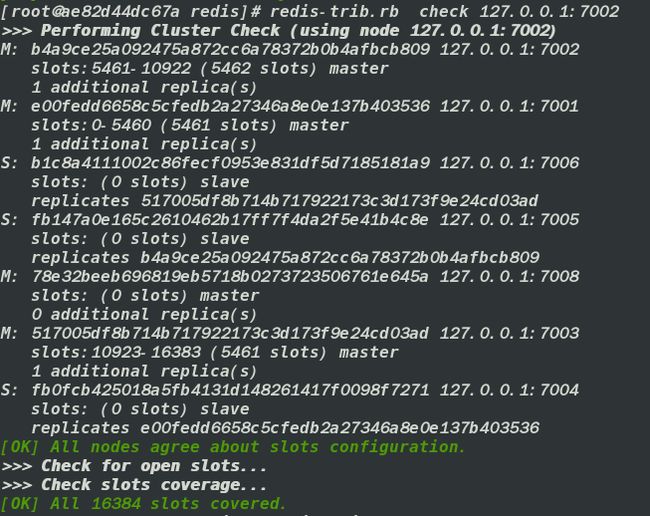
检查前会先执行load_cluster_info_from_node方法,把所有节点数据load进来。load的方式为通过自己的cluster nodes发现其他节点,然后连接每个节点,并加入nodes数组。接着生成节点间的复制关系。
load完数据后,开始检查数据,检查的方式也是调用创建时候使用的check_cluster。
- 添加从节点到集群中,并指定他的主节点
redis-trib.rb add-node --slave --master-id 78e32beeb696819eb5718b0273723506761e645a 127.0.0.1:7009 127.0.0.1:7001
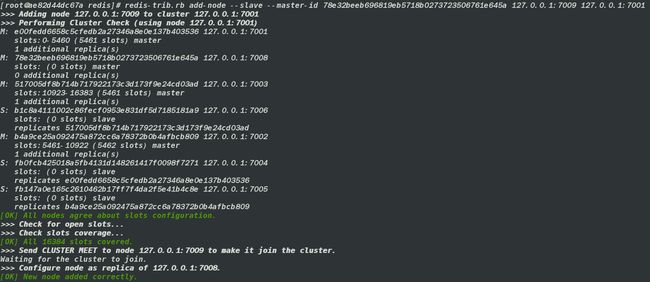
add-node命令可以将新节点加入集群,节点可以为master,也可以为某个master节点的slave。
add-node new_host:new_port existing_host:existing_port
--slave
--master-id
add-node有两个可选参数:
--slave:设置该参数,则新节点以slave的角色加入集群
--master-id:这个参数需要设置了--slave才能生效,--master-id用来指定新节点的master节点。如果不设置该参数,则会随机为节点选择master节点。
add-node流程如下:
1、通过load_cluster_info_from_node方法转载集群信息,check_cluster方法检查集群是否健康。
2、如果设置了--slave,则需要为该节点寻找master节点。设置了--master-id,则以该节点作为新节点的master,如果没有设置--master-id,则调用get_master_with_least_replicas方法,寻找slave数量最少的master节点。如果slave数量一致,则选取load_cluster_info_from_node顺序发现的第一个节点。load_cluster_info_from_node顺序的第一个节点是add-node设置的existing_host:existing_port节点,后面的顺序根据在该节点执行cluster nodes返回的结果返回的节点顺序。
3、连接新的节点并与集群第一个节点握手。
4、如果没设置–slave就直接返回ok,设置了–slave,则需要等待确认新节点加入集群,然后执行cluster replicate命令复制master节点。
5、至此,完成了全部的增加节点的流程。
- 向新加入的主节点中分配槽
redis-trib.rb reshard 127.0.0.1:7001

reshard host:port
--from
--to
--slots
--yes
--timeout
--pipeline
host:port:这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口。
--from :需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入。
--to :slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入。
--slots :需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--yes:设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard。
--timeout :设置migrate命令的超时时间。
--pipeline :定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
迁移的流程如下:
1、通过load_cluster_info_from_node方法装载集群信息。
2、执行check_cluster方法检查集群是否健康。只有健康的集群才能进行迁移。
3、获取需要迁移的slot数量,用户没传递--slots参数,则提示用户手动输入。
4、获取迁移的目的节点,用户没传递--to参数,则提示用户手动输入。此处会检查目的节点必须为master节点。
5、获取迁移的源节点,用户没传递--from参数,则提示用户手动输入。此处会检查源节点必须为master节点。--from all的话,源节点就是除了目的节点外的全部master节点。这里为了保证集群slot分配的平均,建议传递--from all。
6、执行compute_reshard_table方法,计算需要迁移的slot数量如何分配到源节点列表,采用的算法是按照节点负责slot数量由多到少排序,计算每个节点需要迁移的slot的方法为:迁移slot数量 * (该源节点负责的slot数量 / 源节点列表负责的slot总数)。这样算出的数量可能不为整数,这里代码用了下面的方式处理:
n = (numslots/source_tot_slots*s.slots.length)
if i == 0
n = n.ceil
else
n = n.floor
这样的处理方式会带来最终分配的slot与请求迁移的slot数量不一致,这个BUG已经在github上提给作者,https://github.com/antirez/redis/issues/2990。
7、打印出reshard计划,如果用户没传--yes,就提示用户确认计划。
8、根据reshard计划,一个个slot的迁移到新节点上,迁移使用move_slot方法,该方法被很多命令使用,具体可以参见下面的迁移流程。move_slot方法传递dots为true和pipeline数量。
9、至此,就完成了全部的迁移任务。
补充
move_slot方法可以在线将一个slot的全部数据从源节点迁移到目的节点,fix、reshard、rebalance都需要调用该方法迁移slot。
move_slot接受下面几个参数,
1、pipeline:设置一次从slot上获取多少个key。
2、quiet:迁移会打印相关信息,设置quiet参数,可以不用打印这些信息。
3、cold:设置cold,会忽略执行importing和migrating。
4、dots:设置dots,则会在迁移过程打印迁移key数量的进度。
5、update:设置update,则会更新内存信息,方便以后的操作。
move_slot流程如下:
1、如果没有设置cold,则对源节点执行cluster importing命令,对目的节点执行migrating命令。fix的时候有可能importing和migrating已经执行过来,所以此种场景会设置cold。
2、通过cluster getkeysinslot命令,一次性获取远节点迁移slot的pipeline个key的数量.
3、对这些key执行migrate命令,将数据从源节点迁移到目的节点。
4、如果migrate出现异常,在fix模式下,BUSYKEY的异常,会使用migrate的replace模式再执行一次,BUSYKEY表示目的节点已经有该key了,replace模式可以强制替换目的节点的key。不是fix模式就直接返回错误了。
5、循环执行cluster getkeysinslot命令,直到返回的key数量为0,就退出循环。
6、如果没有设置cold,对每个节点执行cluster setslot命令,把slot赋给目的节点。
7、如果设置update,则修改源节点和目的节点的slot信息。
8、至此完成了迁移slot的流程。
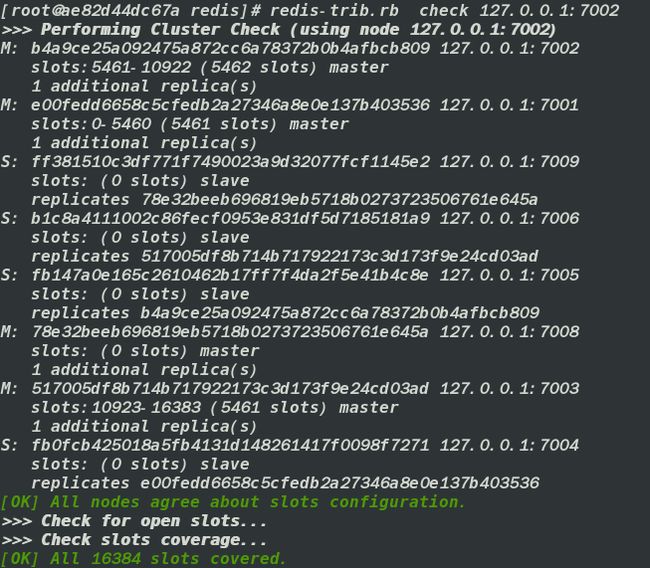
- 完成后观察各主节点的数据槽的分配情况
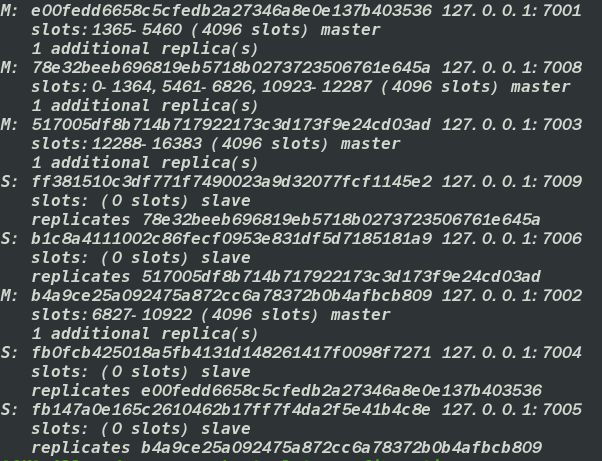
减少节点(缩容)

缩容时的迁移槽
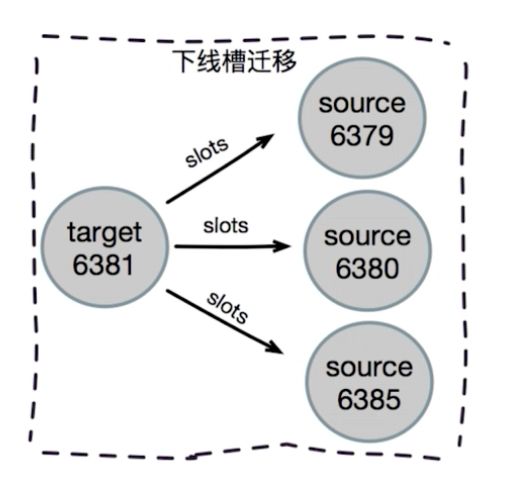
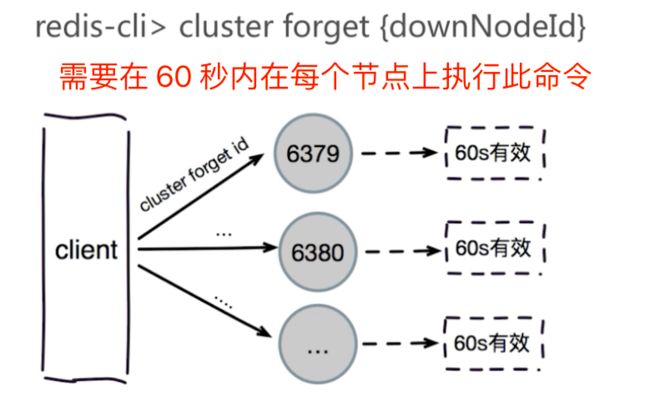
忘记节点操作
实验
命令:
./redis-trib.rb reshard --from 下线节点 ID --to 集群中的任意主节点 ID --slots 迁移到槽数 目前集群中任意节点 IP:端口
redis-trib.rb reshard --from 78e32beeb696819eb5718b0273723506761e645a --to e00fedd6658c5cfedb2a27346a8e0e137b403536 --slots 4096 127.0.0.1:7001
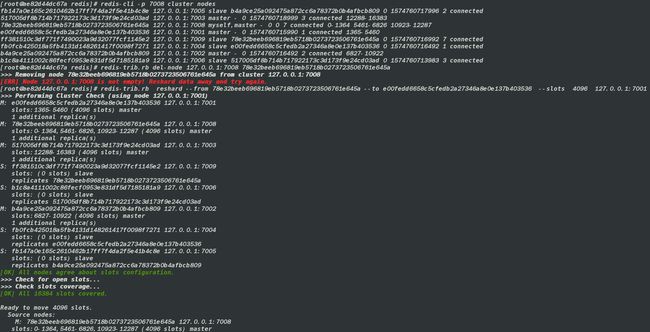

注意:
需要把下线节点的槽数平均迁移到剩余的所有节点,所以需要分批分次执行上面的命令。
并且,每次都集群中的主节点应该不同。
删除节点
当我们使用 redis-trib.rb 工具时,只需要在目前集群中的任意一个节点中执行如下命令即可。
redis-trib.rb del-node 集群中的任意host:port 删除的节点的id
注意:
你应该始终先删除从节点,再删除主节点


del-node流程如下:
1、通过load_cluster_info_from_node方法转载集群信息。
2、根据传入的node id获取节点,如果节点没找到,则直接提示错误并退出。
3、如果节点分配的slot不为空,则直接提示错误并退出。
4、遍历集群内的其他节点,执行cluster forget命令,从每个节点中去除该节点。如果删除的节点是master,而且它有slave的话,这些slave会去复制其他master,调用的方法是get_master_with_least_replicas,与add-node没设置--master-id寻找master的方法一样。
5、然后关闭该节点
删除节点的小问题
在cluster不小心删除某个节点后再加入节点是个很麻烦的事(删除之前先把cluster分配的hashslot给重新分配一下(很重要))
通过 redis-trib.rb del-node 你的节点地址 bd5a40a6ddccbd46a0f4a2208eb25d2453c2a8db(你的node ID(可以通过 redis-trib.rb check 查看))删除你的节点。
删除完后要是想重新添加回去时发现用 redis-trib.rb add-node 你的节点地址 需要挂载的集群的节点 添加时会报错,
[ERR] Node 192.168.XX.XX:XXXX is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
出现这个的原因是这个节点之前已经加入过这个集群了,再次加入就会爆出这样的错误,你可以区配置节点的xxxx.conf文件里找到你保存的cluster-config-fil节点信息,找到然后删除掉,然后删除掉该节点的数据保存RDB文件(要是开启的AOF)也需一并删除掉
然后运行 redis-trib.rb add-node 命令,看是否可以加入集群。成功的话就不用往下看了
要是还是不行就得去连接到你的Redis redis-cli -h 192.168.XXX.XXX -p xxxx (你节点的地址个端口号)去flushdb一下,清空数据库,再次add-node应该就可以了。添加节点后记得给他分配hashslot(记得)
补充知识点
rebalance平衡集群节点slot数量
rebalance命令可以根据用户传入的参数平衡集群节点的slot数量,rebalance功能非常强大,可以传入的参数很多,以下是rebalance的参数列表和命令示例。
rebalance host:port
--weight
--auto-weights
--threshold
--use-empty-masters
--timeout
--simulate
--pipeline
$ruby redis-trib.rb rebalance --threshold 1 --weight b31e3a2e=5 --weight 60b8e3a1=5 --use-empty-masters --simulate 10.180.157.199:6379
host:port:这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口。
--weight :节点的权重,格式为node_id=weight,如果需要为多个节点分配权重的话,需要添加多个--weight 参数,即--weight b31e3a2e=5 --weight 60b8e3a1=5,node_id可为节点名称的前缀,只要保证前缀位数能唯一区分该节点即可。没有传递–weight的节点的权重默认为1。
--auto-weights:这个参数在rebalance流程中并未用到。
--threshold :只有节点需要迁移的slot阈值超过threshold,才会执行rebalance操作。具体计算方法可以参考下面的rebalance命令流程的第四步。
--use-empty-masters:rebalance是否考虑没有节点的master,默认没有分配slot节点的master是不参与rebalance的,设置--use-empty-masters可以让没有分配slot的节点参与rebalance。
--timeout :设置migrate命令的超时时间。
--simulate:设置该参数,可以模拟rebalance操作,提示用户会迁移哪些slots,而不会真正执行迁移操作。
--pipeline :与reshar的pipeline参数一样,定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
rebalance命令流程如下:
1、load_cluster_info_from_node方法先加载集群信息。
2、计算每个master的权重,根据参数--weight,为每个设置的节点分配权重,没有设置的节点,则权重默认为1。
3、根据每个master的权重,以及总的权重,计算自己期望被分配多少个slot。计算的方式为:总slot数量 * (自己的权重 / 总权重)。
4、计算每个master期望分配的slot是否超过设置的阈值,即--threshold设置的阈值或者默认的阈值。计算的方式为:先计算期望移动节点的阈值,算法为:(100-(100.0*expected/n.slots.length)).abs,如果计算出的阈值没有超出设置阈值,则不需要为该节点移动slot。只要有一个master的移动节点超过阈值,就会触发rebalance操作。
5、如果触发了rebalance操作。那么就开始执行rebalance操作,先将每个节点当前分配的slots数量减去期望分配的slot数量获得balance值。将每个节点的balance从小到大进行排序获得sn数组。
6、用dst_idx和src_idx游标分别从sn数组的头部和尾部开始遍历。目的是为了把尾部节点的slot分配给头部节点。
sn数组保存的balance列表排序后,负数在前面,正数在后面。负数表示需要有slot迁入,所以使用dst_idx游标,正数表示需要有slot迁出,所以使用src_idx游标。理论上sn数组各节点的balance值加起来应该为0,不过由于在计算期望分配的slot的时候只是使用直接取整的方式,所以可能出现balance值之和不为0的情况,balance值之和不为0即为节点不平衡的slot数量,由于slot总数有16384个,不平衡数量相对于总数,基数很小,所以对rebalance流程影响不大。
7、获取sn[dst_idx]和sn[src_idx]的balance值较小的那个值,该值即为需要从sn[src_idx]节点迁移到sn[dst_idx]节点的slot数量。
8、接着通过compute_reshard_table方法计算源节点的slot如何分配到源节点列表。这个方法在reshard流程中也有调用,具体步骤可以参考reshard流程的第六步。
9、如果是simulate模式,则只是打印出迁移列表。
10、如果没有设置simulate,则执行move_slot操作,迁移slot,传入的参数为:quiet=>true,:dots=>false,:update=>true。
11、迁移完成后更新sn[dst_idx]和sn[src_idx]的balance值。如果balance值为0后,游标向前进1。
12、直到dst_idx到达src_idx游标,完成整个rebalance操作。