语音信号编码的主要内容
- 1)语音信号编码的基本概念
- 2)PCM通信系统的构成
- 3)抽样
- 4)量化
- 5)编码与解码
1、语音信号编码的基本概念
语音信号的编码指的是模拟语音信号的数字化,即信源编码。

- 波形编码:根据语音信号波形的特点将其转换为数字信号。常见的有PCM、DPCM、ADPCM等,其速率通常是在16kbit/s~64kbit/s的范围。
- 参量编码:根据语音信号产生的数学模型,通过提取语音信号的一些特征参量,对其进行编码(将特征参数变换为数字代码进行传输)。LPC等声编码器属于参量编码。
- 混合编码:介于波形编码和参量编码之间的一种编码,同时使用两种或两种以上的编码方法进行编码。子带编码属于混合编码。
2、PCM通信系统的构成
PCM,是对模拟信号的瞬时抽样值量化、编码,以将模拟信号转化为数字信号。即PCM是模/数变换的一种方法,模/数变换的方法有很多,由此构成的数组通信系统称为PCM通信系统。

PCM编码的特性:
- 抽样频率为8kHz;
- 量化具有非均匀A率(A=87.6)13折线压扩特性;
- 每个样值编8为码。
则一路语音的速率为64kbit/s。其占用带宽大约为模拟单边带系统的16倍。
3、抽样
抽样是每隔一定的时间间隔T抽取模拟信号的一个瞬时幅度值(样值)。即 模拟信号在时间上离散化得到PAM信号。
3.1、低通型信号的抽样定理
设模拟信号的频率范围为 f0~ fM , B=fM - f0 ,当 f0 < B ,为低通型信号(语音信号等),当 f0 ≥ B,为带通型信号。则有,抽样信号频谱的频率成分为:
- 原始频带: f0~ fM
- 上、下边带: n fs ,其中n=1,2,....
- 抽样频率:fs = ,其中T为抽样周期
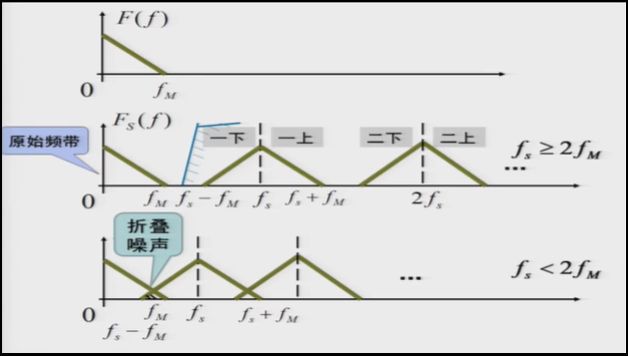
接收端低通的作用是恢复或重建原模拟信号。为在接收端准确的恢复原模拟信号,避免产生折叠噪声,应满足抽样定理 fs ≥ 2 fM ,否则PAM信号产生折叠噪声,收端就无法用低通滤波器准确地恢复原模拟话音信号。但为了留有一定的防卫带,需满足 fs > 2 fM 。
则对于话音信号,其频谱范围为 300~3400 Hz, fM = 3400 Hz,因需满足 fs ≥ 2 fM = 6800Hz,且为了留有一定的防卫带,需取 fs = 8000Hz,即 T= = 125μs,这也是 CCITT 中规定的。( 国际电信咨询机构简称CCITT,International Telephone and Telegraph Consultative Committee , 后改为ITU-T的中文名称是国际电信联盟电信标准分局(ITU-T for ITU Telecommunication Standardization Sector), 它是国际电信联盟管理下的专门制定电信标准的分支机构。)
4、量化
量化,即将PAM信号(样值)在幅度上离散化。分为均匀量化和非均匀量化。
4.1 均匀量化
均匀量化,即在量化区内(即从-U ~ +U, U为过载电压,话音信号的幅度主要分布在这个区间)均匀等分N(量化级数)个小间隔(Δ = )。
若在量化区内,则取各个量化间隔的中间值;过载区内则取量化区内最大的量化值(值绝对值),即 |uq| = U - 。则有
1)量化值的数目等于量化级数N,量化后对N个量化值要用二进制编码,编码的码位数为l,N=2l。
2)量化误差=量化值-样值=uq(t) - u(t)
量化区内,emax(t) = ;
过载区内,emax(t) > ;
量化误差会引起量化噪声,此噪声会叠加在原来的信号上,对原信号产生干扰。通常使用量化信噪比来衡量量化误差,量化噪声比越大,噪声对信号的影响也相对越小。
(S/Nq)db = 10lg (dB)
其中,S为话音信号的平均功率, 为量化噪声功率。
经过上述可知均匀量化的缺点为,在N(或l) 大小适当时,均匀量化小信号的量化信噪比太小,不满足要求,而大信号的量化信噪比较大,远远满足要求。而数字通信系统中,一般要求量化信噪比要大于等于26db。则对于均匀量化,大小信号在量化区内的最大量化都是 ,量化误差等效为量化噪声功率,而小信号的信号功率小故信噪比大,大信号的信号功率大故信噪比大。为了解决这个问题,若依旧采用均匀量化,对于小信号则需要提高信噪比,因话音信号功率不变则需要降低量化噪声功率,即量化误差emax(t) 要降低,Δ = 要降低,则N需要增大,又N=2l,则最终必然会引起 l 增大,这又会引起其他的问题,比如编码复杂度增大,信道利用率下降(虽然l增大,传信率会增大,但是数码率的数值近似的等于数字信号所占用的带宽,而数码率增大即需要占用的带宽增大,信道利用率自然就下降了)。
4.2 非均匀量化
非均匀量化的宗旨在不增大量化级数 N 的前提下, 利用降低大信号的量化信噪比来提高小信号的量化信噪比。 为了达到这一目的,对于小信号(信号幅度小)需要降低量化间隔,则量化误差降低等效的噪声功率降低,进而提高量化信噪比;对于大信号(信号幅度大),量化增大量化间隔,则量化误差降低等效的噪声功率提高,进而降低量化信噪比
常用的非均匀量化方法有,模拟压扩法和直接非均匀编解码法(根据非均匀量化的划分,根据样值落在哪个间隔范围内直接对样值进行编码,相当于编码过程中就进行了量化。)
在数字通信系统中,理论上需要抽样、量化
变化,而在实际实现中通常是根据量化间隔的划分,直接对样值进行编码,在编码过程中相当于实现了量化。
5、编码与解码
5.1、编码的基本概念及分类
编码,是把模拟信号的样值变换成对应的二进制码组。常用的二进制码组有3种:
- 一般二进制码
- 循环二进制码
- 折叠二进制码(样值的绝对值相同,其幅度码也相同)
编码主要分为:
- 线性编码与解码,具有均匀量化特性的编码与解码,即根据均匀量化间隔的划分直接对样值编码,收端解码。
- 非线性编码与解码,具有非均匀量化特性的编码与解码,即根据非均匀量化间隔的划分直接对样值编码,收端解码。
PCM 通信系统一般采用非线性编码与解码,通常是根据A律13折线非均匀量化间隔的划分直接对样值编码,收端再解码。


5.2、量化级数 N
对于A律13折线编码器,分为正、负 极性,每个极性有8个量化段,每个量化段内16等分,即有N = 2x8x16 = 256, 则有
l = log2N = log2 256 = 8
对应的码字安排为

编码时先编极性码后编段落码(非线性编码)再编段内码(线性编码)。


A律13折线编码过程:

编码过程的关键为判定值的确定。判定值是各量化段或量化级的分界点电平(IRi 或 URi),数目 nR = -1 = 127 (l=8)。
5.3、判定值
对于段落码,根据A律13折线的单极性量化表所示,以量化段为单位逐次对分,对分点电平依次为a2~a4的判定值。对整个量化段进行对分,对分点为128Δ,段4和段5的中间即为a2的判定值IR2,则当a2=0,说明样值<128Δ,在前4段;对前4段对分,对分点为32Δ,即IR3在段2和段3中间,此时a3=1,说明样值>32Δ, 则说明在后2段;对后2两段进行对分,对分点为64Δ,即IR4在段3和段4中间,当a4=0,说明样值<64Δ, 则说明样值在第3段。可以看出a4的判定值有4个,具体使用哪个需要通过a2、a3来决定。

同理,对于段内码判定值的确定,是以谋量化段内量化级为单位逐次对分,对分点点平依次为 a5~a8 的判定值,其中a8的判定点用哪个需要根据a5、a6、a7的值来定。
5.4、A律13折线编码的编解码点平
(1) 编码电平与编码误差
编码电平,即编码器输出的码字所对应的电平(IC 或者 UC )。以IC 为例:
编码误差为:
(2) 解码电平与解码误差
解码电平,是解码器的输出电平(IC 或者 UC )。
解码误差:
5.5、逐次渐进型编码器
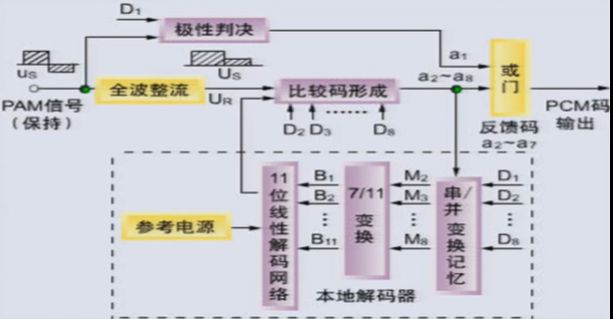
5.6、A律13折线解码器
