为什么要了解编译技术:
- 编译技术是计算机科学的一个非常重要的基础技术
- 编程用的一些框架或组件都用到了编译技术,比如注解支持和字节码动态生成等
- 帮助理解项目构建流程CMake 和 Gradle等配置构建工具配置
- 其他等等....,绝对不是只能用于炫耀的屠龙技
本次分享的内容简介:
- 主要是编译器前端部分
- 理论部分涉及到词法分析,语法分析,语义分析
- c4简版编译器(4个函数实现的c编译器,大约500行)源码分析,帮助理解编译原理
现代编译器结构
现代编译器通常分为前端和后端,前端将高级语言转化为中间的统一代码,然后由后端将中间代码编译为机器代码,处理硬件架构相关的优化,讲到现代编译器我们主要以LLVM平台作为学习重点,LLVM是Apple官方支持的编译器,LLVM是一个模块化的编译器平台,可以支持不同的编译前端,Apple官方的编译器前端是Clang,前端生成各种中间代码,后端自动进行各类优化分析,让用LLVM开发的编译器,都能用上最先进的后端优化技术。
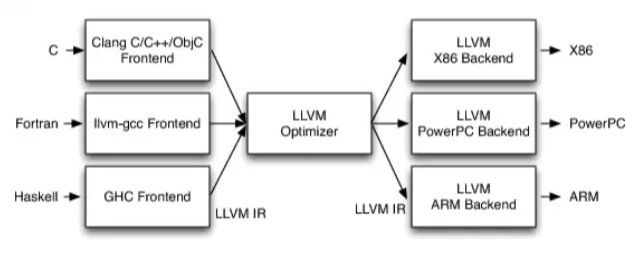
LLVM发展历史:https://blog.csdn.net/zhouzhaoxiong1227/article/details/52166942
编译涉及到的主要流程如下:
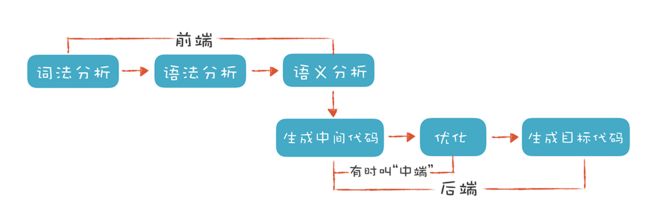
词法分析
- 词法分析:相当于识别每个词代表什么。进行的工作就是识别单词。在程序语言中,一般单词的类型包括:关键字,操作符,变量标识符,数值常量,字符串常量和运算符。
词法分析器以源码字符串为输入,输出为标记流(token stream),即一连串的标记,每个标记通常包括: (token, token value) 即标记本身和标记的值。
例如:
2 + 3 * (4 - 5)
=>
(Number, 2) Add (Number, 3) Multiply Left-Bracket (Number, 4) Subtract (Number, 5) Right-Bracket
由于词法分析的工作很常见,但又枯燥且容易出错,所以人们已经开发出了许多工具来生成词法分析器,如 lex, flex。这些工具允许我们通过正则表达式来识别标记。
这里注意的是,我们并不会一次性地将所有源码全部转换成标记流,原因:
- 字符串转换成标记流有时是有状态的,即与代码的上下文是有关系的。
- 保存所有的标记流没有意义且浪费空间。
所以实际的处理方法是提供一个函数(即前几篇中提到的 next()),每次调用该函数则返回下一个标记。
词法分析实践---c4
c4的词法分析实现采用的是手工编码实现方式,没有采用正则表达,因为支持的语法比较简单手写也不复杂。
char *p, *lp, // 指向source area的指针,读入的代码会以文本信息的形式读入在该区域 current position in source code
int64 *e, *le, // 指向text area的指针,解析代码后生成相应的伪汇编代码写入该区域 current position in emitted code
*id, // 指向当前正在设置或解析的语义关键字结构 currently parsed identifier
*sym, // 指向symble area的指针,能够解析的关键字、库函数以及函数的参数和局部变量会存储在该区域 symbol table (simple list of identifiers)
tk, // 当前正在解析的代码的游标 current token
ival, // 当前解析的数字的值 current token value
ty, // 语义关键字结构的类型 current expression type
loc, // 局部变量偏移量标识 local variable offset
line, // 当前解析的代码行数 current line number
src, // 解析的代码和生成的伪汇编代码的标识 print source and assembly flag
debug; // 输出汇编代码执行结果标识 print executed instructions
// 获取Token,即词法分析
void next()
{
char *pp;
// 只要未到文件末尾
while (tk = *p) {
++p;
if (tk == '\n') {
// 换行符处理
if (src) {
printf("line %d: %.*s", line, p - lp, lp);
lp = p;
while (le < e) {
printf("%8.4s", &"LEA ,IMM ,JMP ,JSR ,BZ ,BNZ ,ENT ,ADJ ,LEV ,LI ,LC ,SI ,SC ,PSH ,"
"OR ,XOR ,AND ,EQ ,NE ,LT ,GT ,LE ,GE ,SHL ,SHR ,ADD ,SUB ,MUL ,DIV ,MOD ,"
"OPEN,READ,CLOS,PRTF,MALC,FREE,MSET,MCMP,EXIT,"[*++le * 5]);
if (*le <= ADJ) printf(" %d\n", *++le); else printf("\n");
}
}
++line;
}
else if (tk == '#') {
// #符处理,此处直接忽略
while (*p != 0 && *p != '\n') ++p;
}
else if ((tk >= 'a' && tk <= 'z') || (tk >= 'A' && tk <= 'Z') || tk == '_') {
// 字符处理,变量或函数名等
pp = p - 1;
// 第二个字符符合变量字符范围
while ((*p >= 'a' && *p <= 'z') || (*p >= 'A' && *p <= 'Z') || (*p >= '0' && *p <= '9') || *p == '_')
tk = tk * 147 + *p++;
tk = (tk << 6) + (p - pp);
id = sym;
// 得到变量或函数名的Token,p-pp范围内的字符
while (id[Tk]) { // 查询符号表中是否已经有该变量定义,有直接返回
if (tk == id[Hash] && !memcmp((char *)id[Name], pp, p - pp)) { tk = id[Tk]; return; }
id = id + Idsz;
}
// 符号表中没有该定义,就添加到符号表中
id[Name] = (int64)pp;
id[Hash] = tk;
tk = id[Tk] = Id;
return;
}
else if (tk >= '0' && tk <= '9') {
// 数字处理
if (ival = tk - '0') { while (*p >= '0' && *p <= '9') ival = ival * 10 + *p++ - '0'; }
else if (*p == 'x' || *p == 'X') {
// 十六进制数字转化为十进制
while ((tk = *++p) && ((tk >= '0' && tk <= '9') || (tk >= 'a' && tk <= 'f') || (tk >= 'A' && tk <= 'F')))
ival = ival * 16 + (tk & 15) + (tk >= 'A' ? 9 : 0);
}
else {
// 八进制转为十进制
while (*p >= '0' && *p <= '7') ival = ival * 8 + *p++ - '0';
}
tk = Num;
return;
}
else if (tk == '/') {
// ‘/’字符处理
if (*p == '/') {
// 下一个字符也是‘/’,是注释代码,直接忽略
++p;
while (*p != 0 && *p != '\n') ++p;
}
else {
// 除法
tk = Div;
return;
}
}
else if (tk == '\'' || tk == '"') {
// 字符串处理
pp = data;
while (*p != 0 && *p != tk) {
if ((ival = *p++) == '\\') {
if ((ival = *p++) == 'n') ival = '\n';
}
if (tk == '"') *data++ = ival;
}
++p;
if (tk == '"') ival = (int64)pp; else tk = Num;
return;
}
else if (tk == '=') { if (*p == '=') { ++p; tk = Eq; } else tk = Assign; return; }
else if (tk == '+') { if (*p == '+') { ++p; tk = Inc; } else tk = Add; return; }
else if (tk == '-') { if (*p == '-') { ++p; tk = Dec; } else tk = Sub; return; }
else if (tk == '!') { if (*p == '=') { ++p; tk = Ne; } return; }
else if (tk == '<') { if (*p == '=') { ++p; tk = Le; } else if (*p == '<') { ++p; tk = Shl; } else tk = Lt; return; }
else if (tk == '>') { if (*p == '=') { ++p; tk = Ge; } else if (*p == '>') { ++p; tk = Shr; } else tk = Gt; return; }
else if (tk == '|') { if (*p == '|') { ++p; tk = Lor; } else tk = Or; return; }
else if (tk == '&') { if (*p == '&') { ++p; tk = Lan; } else tk = And; return; }
else if (tk == '^') { tk = Xor; return; }
else if (tk == '%') { tk = Mod; return; }
else if (tk == '*') { tk = Mul; return; }
else if (tk == '[') { tk = Brak; return; }
else if (tk == '?') { tk = Cond; return; }
else if (tk == '~' || tk == ';' || tk == '{' || tk == '}' || tk == '(' || tk == ')' || tk == ']' || tk == ',' || tk == ':') return;
}
}
语法分析
语法分析:识别语句的结构,通常以树的形式表示。
如果把词法分析看作为字母组合成单词的过程,那么语法分析就是一个把单词组合成句子的过程。正如在词法分析中使用正则表达式来描述词法的规则一样,我们在语法分析中使用上下文无关文法来描述语言的语法规则。我们可以把某一种语言看成无数个符合语法规则的句子的集合,根据给定的上下文无关文法我们可以判断某一个 Token 串是否符合某个语法规则;如果符合,那么我们可以把此文法和对应输入的 Token 串组合起来生成一个句子。整个流程如下图所示:
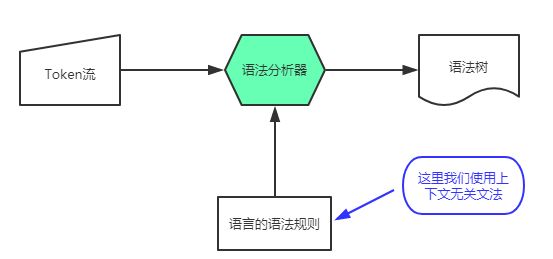
上下文无关文法
上下文无关文法(context-free grammar, CFG),是一种用来对某种语言进行形式化的、精确的描述的工具,我们就可以很方便的定义一种语言的语法了。CFG 是一个四元组(N, T, P, S),下面我们看一下 CFG 的组成:
- N 是非终结符的集合;
- T 是终结符的集合;
- P 是一条产生式规则;
- S 是开始符号;
四则运算的语法分析器例子
四则运算的规则可以表示如下:
-> +
| -
|
-> *
| /
|
-> ( )
| Num
用尖括号 <> 括起来的就称作 非终结符 ,因为它们可以用->右侧的式子代替。| 表示选择,如 可以是 + 、 - 或 中的一种。而没有出现在->左边的就称作 终结符 ,一般终结符对应于词法分析器输出的标记。
抽象语法树
抽象语法树是程序中语句表示的一种数据格式。
以上面的 CFG 为例,我们要从它推导出句子 1+2-3*4,则推导方式如下:
S => A+S => B+S => 1+S => 1+A-S => 1+B-S =>1+2-S =>1+2-A=>1+2-BA=>1+2-3A=>1+2-3B=>1+2-34,这个推导过程可以用下面的(语法)分析树来表示:
无法复制加载中的内容
语义分析
对语法分析生成的两个语法树进行分析,检查结构正确的句子是否语义合法,对于语言来说主要会做以下几点:
- 申明检查
- 类型检查
- 范围解决方案
- 数组绑定检查
符号表
虽然编译器很不厚道的给链接器留了一项任务,但是编译器为了链接器工作的轻松一点还是做了一点事情,这就是符号表,符号表是为编译器存储变量名、函数名、对象、类、接口等各种实体的出现情况而创建和维护的一种重要的数据结构,符号表是实现变量作用域的关键——常见做法是用hashtable来实现 (变量名 -> 变量信息) 的映射关系,并且通过嵌套的符号表来实现作用域。举个符号表样例:

看个例子,一个用Java实现的C的简化版C-flat语言的编译器cbc里的作用域实现:
https://github.com/aamine/cbc/blob/master/net/loveruby/cflat/entity/LocalScope.java
- 它用Map
- 它用parent链来构成嵌套的作用域。变量名的搜索总是从当前作用域开始,找不到再到上一层作用域搜索,直到到达顶层作用域为止。
再看个简单的例子,巨紧凑的迷你C编译器c4里也有符号表:
https://github.com/rswier/c4
其中的int *sym就是符号表。不过c4不支持嵌套作用域,变量只支持函数级别(local)和全局级别(global)的作用域,所以处理起来相当简单:
- 局部变量的处理:见 if (d[Class] == Loc)
- 全局变量的处理:见 else if (d[Class] == Glo)
- 还有一些特殊处理的命名空间,例如函数见 else if (d[Class] == Fun)
我们再详细说一下c4的符号表数据结构,它的结构是一个一维数组,符号的数据结构是含8个字段的对象,把连续的8个数据空间用于存一个符号记录。
int *sym // 符号表指针
/** 符号表是一个长数组,每个数组的元素为符号描述,元素长度为Idsz
每个符号元素包括的信息为:
Tk 符号类型,id类型,用来区分是否为关键字的
Hash 符号哈希
Name 符号名字
Class 变量类型,Num = 128(常数)Fun(函数)Sys(系统调用) Glo(全局变量) Loc(本地变量) Id
Type 变量数值类型,char,int,ptr,还是*char,*int,*ptr,还是**char,**int,**ptr
Val 变量的值,对应不同的数据类型有不同的值
*/
enum { Tk, Hash, Name, Class, Type, Val, HClass, HType, HVal, Idsz };
// 比如下面查询符号表中是否已有指定名字的符号,如果没有就添加一条记录到符号表中
id = sym;
while (id[Tk]) { // 遍历符号表
if (tk == id[Hash] && !memcmp((char *)id[Name], pp, p - pp)) {
// 查询符号表中是否已经有该变量定义,有直接返回
tk = id[Tk]; return;
}
// 遍历下一个符号,Idsz是符号的对象的size=8
id = id + Idsz;
}
// 符号表中没有该定义,就添加到符号表中
id[Name] = (int64)pp;
id[Hash] = tk;
tk = id[Tk] = Id;
有了符号表,上面提到的语义分析中的关键检查如下:
申明检查:申明类型,如果从符号表中查询未定义,报申明异常
类型检查:使用到的类型如果符号表中未查询到,报类型异常
范围解决方案:符号表通过嵌套实现作用域,变量作用域不对,报异常
数组绑定检查:查找符号表中的数组定义,并根据符号信息取对应数据
总的来说,有了符号表和抽象语法树,就可以做语法检查和中间代码生成。
语法语义分析实践---c4
c4是一个简版的编译器实现,它的语法分析、语义分析以及生成中间代码都是在两个函数中实现,且没有生成抽象语法树,直接语法分析+语义分析,并直接生成了中间代码,我们看看它的实现源码来帮助理解语法分析和语义分析,中间代码生成涉及到汇编相关知识不在本文范围。
// 代码解析
void stmt()
{
int64 *a, *b;
printf("statement() token=%c \n", tk);
if (tk == If) {
// if语句处理
next();
if (tk == '(') next(); else { printf("%d: open paren expected\n", line); exit(-1); }
expr(Assign);
if (tk == ')') next(); else { printf("%d: close paren expected\n", line); exit(-1); }
*++e = BZ; b = ++e;
stmt();
if (tk == Else) {
*b = (int64)(e + 3); *++e = JMP; b = ++e;
next();
stmt();
}
*b = (int64)(e + 1);
}
else if (tk == While) {
// while语句处理
next();
a = e + 1;
if (tk == '(') next(); else { printf("%d: open paren expected\n", line); exit(-1); }
expr(Assign);
if (tk == ')') next(); else { printf("%d: close paren expected\n", line); exit(-1); }
*++e = BZ; b = ++e;
stmt();
*++e = JMP; *++e = (int64)a;
*b = (int64)(e + 1);
}
else if (tk == Return) {
// return处理
next();
if (tk != ';') expr(Assign);
*++e = LEV;
if (tk == ';') next(); else { printf("%d: semicolon expected\n", line); exit(-1); }
}
else if (tk == '{') {
// 函数体
next();
while (tk != '}') stmt();
next();
}
else if (tk == ';') {
next();
}
else {
// 表达式处理,关键!!!
expr(Assign);
if (tk == ';') next(); else { printf("%d: semicolon expected\n", line); exit(-1); }
}
}
// 操作符语义解析(如:sizof,&,|,++,--,=,==等等) 生成伪汇编代码,写到text area中
void expr(int64 lev)
{
int64 t, *d;
if (!tk) { printf("%d: unexpected eof in expression\n", line); exit(-1); }
else if (tk == Num) {
// 数字处理,生成对应的中间代码
*++e = IMM; *++e = ival; next(); ty = INT;
}
else if (tk == '"') {
// 字符串处理
*++e = IMM; *++e = ival; next();
while (tk == '"') next();
// append the end of string character '\0', all the data are default
// to 0, so just move data one position forward.
data = (char *)((int64)data + sizeof(int64) & -sizeof(int64)); ty = PTR;
}
else if (tk == Sizeof) {
next(); if (tk == '(') next(); else { printf("%d: open paren expected in sizeof\n", line); exit(-1); }
ty = INT; if (tk == Int) next(); else if (tk == Char) { next(); ty = CHAR; }
while (tk == Mul) { next(); ty = ty + PTR; }
if (tk == ')') next(); else { printf("%d: close paren expected in sizeof\n", line); exit(-1); }
*++e = IMM; *++e = (ty == CHAR) ? sizeof(char) : sizeof(int64);
ty = INT;
}
else if (tk == Id) {
d = id; next();
if (tk == '(') {
// 处理函数调用
next();
t = 0;
while (tk != ')') { expr(Assign); *++e = PSH; ++t; if (tk == ',') next(); }
next();
if (d[Class] == Sys) *++e = d[Val];
else if (d[Class] == Fun) { *++e = JSR; *++e = d[Val]; }
else { printf("%d: bad function call\n", line); exit(-1); }
if (t) { *++e = ADJ; *++e = t; }
ty = d[Type];
}
else if (d[Class] == Num) {
// 处理数字
*++e = IMM; *++e = d[Val]; ty = INT;
}
else {
// 变量处理
if (d[Class] == Loc) { *++e = LEA; *++e = loc - d[Val]; }
else if (d[Class] == Glo) { *++e = IMM; *++e = d[Val]; }
else { printf("%d: undefined variable\n", line); exit(-1); }
*++e = ((ty = d[Type]) == CHAR) ? LC : LI;
}
}
else if (tk == '(') {
// 类型强转
next();
if (tk == Int || tk == Char) {
t = (tk == Int) ? INT : CHAR; next();
while (tk == Mul) { next(); t = t + PTR; }
if (tk == ')') next(); else { printf("%d: bad cast\n", line); exit(-1); }
expr(Inc);
ty = t;
}
else {
expr(Assign);
if (tk == ')') next(); else { printf("%d: close paren expected\n", line); exit(-1); }
}
}
else if (tk == Mul) {
// 指针取值
next(); expr(Inc);
if (ty > INT) ty = ty - PTR; else { printf("%d: bad dereference\n", line); exit(-1); }
*++e = (ty == CHAR) ? LC : LI;
}
else if (tk == And) {
// 取址操作
next(); expr(Inc);
if (*e == LC || *e == LI) --e; else { printf("%d: bad address-of\n", line); exit(-1); }
ty = ty + PTR;
}
else if (tk == '!') {
//逻辑取反
next(); expr(Inc); *++e = PSH; *++e = IMM; *++e = 0; *++e = EQ; ty = INT;
}
else if (tk == '~') {
// 按位取反
next(); expr(Inc); *++e = PSH; *++e = IMM; *++e = -1; *++e = XOR; ty = INT;
}
else if (tk == Add) {
// 正号
next(); expr(Inc); ty = INT; }
else if (tk == Sub) {
// 负号
next(); *++e = IMM;
if (tk == Num) { *++e = -ival; next(); } else { *++e = -1; *++e = PSH; expr(Inc); *++e = MUL; }
ty = INT;
}
else if (tk == Inc || tk == Dec) {
// 自增自减
t = tk; next(); expr(Inc);
if (*e == LC) { *e = PSH; *++e = LC; }
else if (*e == LI) { *e = PSH; *++e = LI; }
else { printf("%d: bad lvalue in pre-increment\n", line); exit(-1); }
*++e = PSH;
*++e = IMM; *++e = (ty > PTR) ? sizeof(int64) : sizeof(char);
*++e = (t == Inc) ? ADD : SUB;
*++e = (ty == CHAR) ? SC : SI;
}
else { printf("%d: bad expression\n", line); exit(-1); }
while (tk >= lev) { // "precedence climbing" or "Top Down Operator Precedence" method
t = ty;
if (tk == Assign) {
// 赋值操作
next();
if (*e == LC || *e == LI) *e = PSH; else { printf("%d: bad lvalue in assignment\n", line); exit(-1); }
expr(Assign); *++e = ((ty = t) == CHAR) ? SC : SI;
}
else if (tk == Cond) {
// 三目运算符 ? :
next();
*++e = BZ; d = ++e;
expr(Assign);
if (tk == ':') next(); else { printf("%d: conditional missing colon\n", line); exit(-1); }
*d = (int64)(e + 3); *++e = JMP; d = ++e;
expr(Cond);
*d = (int64)(e + 1);
}
// 逻辑运算符
else if (tk == Lor) { next(); *++e = BNZ; d = ++e; expr(Lan); *d = (int64)(e + 1); ty = INT; }
else if (tk == Lan) { next(); *++e = BZ; d = ++e; expr(Or); *d = (int64)(e + 1); ty = INT; }
else if (tk == Or) { next(); *++e = PSH; expr(Xor); *++e = OR; ty = INT; }
else if (tk == Xor) { next(); *++e = PSH; expr(And); *++e = XOR; ty = INT; }
else if (tk == And) { next(); *++e = PSH; expr(Eq); *++e = AND; ty = INT; }
else if (tk == Eq) { next(); *++e = PSH; expr(Lt); *++e = EQ; ty = INT; }
else if (tk == Ne) { next(); *++e = PSH; expr(Lt); *++e = NE; ty = INT; }
else if (tk == Lt) { next(); *++e = PSH; expr(Shl); *++e = LT; ty = INT; }
else if (tk == Gt) { next(); *++e = PSH; expr(Shl); *++e = GT; ty = INT; }
else if (tk == Le) { next(); *++e = PSH; expr(Shl); *++e = LE; ty = INT; }
else if (tk == Ge) { next(); *++e = PSH; expr(Shl); *++e = GE; ty = INT; }
else if (tk == Shl) { next(); *++e = PSH; expr(Add); *++e = SHL; ty = INT; }
else if (tk == Shr) { next(); *++e = PSH; expr(Add); *++e = SHR; ty = INT; }
// 数学运算符
else if (tk == Add) {
// +
next(); *++e = PSH; expr(Mul);
if ((ty = t) > PTR) { *++e = PSH; *++e = IMM; *++e = sizeof(int64); *++e = MUL; }
*++e = ADD;
}
else if (tk == Sub) {
// -
next(); *++e = PSH; expr(Mul);
if (t > PTR && t == ty) { *++e = SUB; *++e = PSH; *++e = IMM; *++e = sizeof(int64); *++e = DIV; ty = INT; }
else if ((ty = t) > PTR) { *++e = PSH; *++e = IMM; *++e = sizeof(int64); *++e = MUL; *++e = SUB; }
else *++e = SUB;
}
else if (tk == Mul) {
// *
next(); *++e = PSH; expr(Inc); *++e = MUL; ty = INT;
}
else if (tk == Div) {
// /
next(); *++e = PSH; expr(Inc); *++e = DIV; ty = INT;
}
else if (tk == Mod) { next(); *++e = PSH; expr(Inc); *++e = MOD; ty = INT; }
else if (tk == Inc || tk == Dec) {
// 自增自减
if (*e == LC) { *e = PSH; *++e = LC; }
else if (*e == LI) { *e = PSH; *++e = LI; }
else { printf("%d: bad lvalue in post-increment\n", line); exit(-1); }
*++e = PSH; *++e = IMM; *++e = (ty > PTR) ? sizeof(int64) : sizeof(char);
*++e = (tk == Inc) ? ADD : SUB;
*++e = (ty == CHAR) ? SC : SI;
*++e = PSH; *++e = IMM; *++e = (ty > PTR) ? sizeof(int64) : sizeof(char);
*++e = (tk == Inc) ? SUB : ADD;
next();
}
else if (tk == Brak) {
// 数组取值操作
next(); *++e = PSH; expr(Assign);
if (tk == ']') next(); else { printf("%d: close bracket expected\n", line); exit(-1); }
if (t > PTR) { *++e = PSH; *++e = IMM; *++e = sizeof(int64); *++e = MUL; }
else if (t < PTR) { printf("%d: pointer type expected\n", line); exit(-1); }
*++e = ADD;
*++e = ((ty = t - PTR) == CHAR) ? LC : LI;
}
else { printf("%d: compiler error tk=%d\n", line, tk); exit(-1); }
}
}
c4总结
c4仓库:https://github.com/rswier/c4
c4的代码简洁,但较难懂,好多变量都是缩写。
功能齐全,满足编译器开发的,词法分析,语法分析,目标代码生成的三个基本步骤。
并实现了自举,可以自己编译自己。
// 编译c4
gcc -o c4 c4.c
// 用c4编译hello.c文件
./c4 hello.c
// 用c4编译hello.c文件, 输出源码参数
./c4 -s hello.c