基本原理
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Hive构建在基于静态批处理的Hadoop之上,由于Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不适合那些需要低延迟的应用,它最适合应用在基于大量不可变数据的批处理作业,例如,网络日志分析。
- Hive的特点是:可伸缩(在Hadoop集群上动态的添加设备)、可扩展、容错、输出格式的松散耦合。
- Hive将元数据存储在关系型数据库(RDBMS)中,比如MySQL、Derby中。
- Hive有三种模式连接到数据,其方式是:单用户模式,多用户模式和远程服务模式。(也就是内嵌模式、本地模式、远程模式)。
系统环境
Linux Ubuntu 20.04
OpenJDK-11.0.11
hadoop-3.2.2
mysql-8.0.25
mysql-connector-java-8.0.25.jar
前提条件
在Hadoop和mysql安装完成的基础上,搭建hive。
安装步骤
1.在Linux本地创建/data/hive1文件夹用来存放安装包。
mkdir -p /data/hive1切换到/data/hive1的目录下,使用wget命令下载apache-hive-2.3.8-bin.tar.gz和mysql-connector-java-8.0.25.jar。
cd /data/hive1
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.8/apache-hive-2.3.8-bin.tar.gz
wget https://dev.mysql.com/downloads/file/?id=5046462.将/data/hive1目录下的apache-hive-2.3.8-bin.tar.gz,解压缩到/apps目录下。
tar -xzvf /data/hive1/apache-hive-2.3.8-bin.tar.gz -C /apps/再切换到/apps目录下,将/apps/hive-1.1.0-cdh5.4.5,重命名为hive。
cd /apps
mv /apps/apache-hive-2.3.8-bin.tar.gz/ /apps/hive 3.使用vim打开用户环境变量。
sudo vim ~/.bashrc将Hive的bin目录,添加到用户环境变量PATH中,然后保存退出。
#hive config
export HIVE_HOME=/apps/hive
export PATH=$HIVE_HOME/bin:$PATH执行source命令,使Hive环境变量生效。
source ~/.bashrc 4.由于Hive需要将元数据,存储到Mysql中。所以需要拷贝/data/hive1目录下的mysql-connector-java-8.0.25.jar到hive的lib目录下。
cp /data/hive1/mysql-connector-java-8.0.25.jar/apps/hive/lib/ 5.下面配置Hive,切换到/apps/hive/conf目录下,并创建Hive的配置文件hive-site.xml。
cd /apps/hive/conf
touch hive-site.xml 使用vim打开hive-site.xml文件。
vim hive-site.xml并将下列配置项,添加到hive-site.xml文件中。
#javax.jdo.option.ConnectionDriverName:连接数据库的驱动包。
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
#javax.jdo.option.ConnectionUserName:数据库用户名。
javax.jdo.option.ConnectionUserName
root
#javax.jdo.option.ConnectionPassword:连接数据库的密码。
javax.jdo.option.ConnectionPassword
123456
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
127.0.0.1
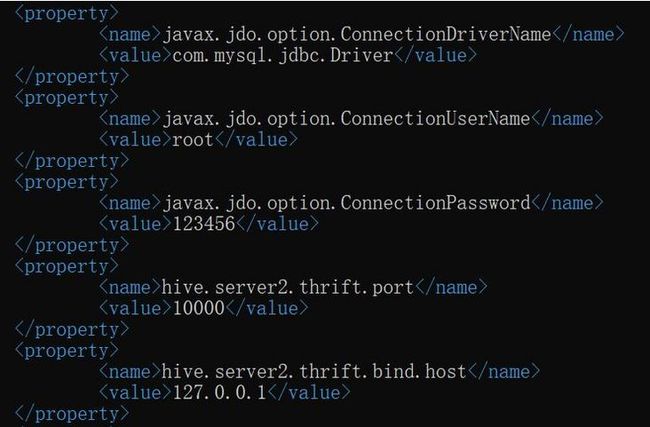
由于Hive的元数据会存储在Mysql数据库中,所以需要在Hive的配置文件中,指定mysql的相关信息。
javax.jdo.option.ConnectionURL:数据库链接字符串。
javax.jdo.option.ConnectionDriverName:连接数据库的驱动包。
javax.jdo.option.ConnectionUserName:数据库用户名。
javax.jdo.option.ConnectionPassword:连接数据库的密码。
此处的数据库的用户名及密码,需要设置为自身系统的数据库用户名及密码。
6.另外,还需要告诉Hive,Hadoop的环境配置。所以我们需要修改hive-env.sh文件。
首先我们将hive-env.sh.template重命名为hive-env.sh。
mv /apps/hive/conf/hive-env.sh.template /apps/hive/conf/hive-env.sh 使用vim打开hive-env.sh文件。
vim hive-env.sh追加Hadoop的路径,以及Hive配置文件的路径到文件中。
# Set HADOOP_HOME to point to a specific hadoop install directory
# HADOOP_HOME=${bin}/../../hadoop
HADOOP_HOME=/apps/hadoop
# Hive Configuration Directory can be controlled by:
# export HIVE_CONF_DIR=
export HIVE_CONF_DIR=/apps/hive/conf 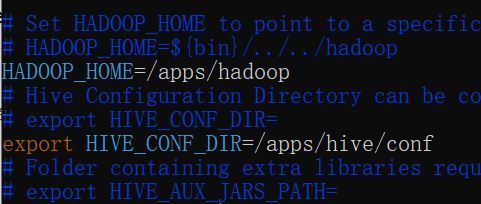
7.下一步是配置Mysql,用于存储Hive的元数据。
首先,需要保证Mysql已经启动。执行以下命令,查看Mysql的运行状态。
sudo service mysql status 
通过输出,可以看出Mysql已经启动。如果未启动需要执行启动命令。
sudo service mysql start如果未安装Mysql则需要执行安装命令。若我们的环境已安装Mysql,则无需执行此步。
sudo apt-get install mysql-server 8.开启Mysql数据库。
mysql -u root -p查看数据库。
show databases;下面,输入exit退出Mysql。
exit 9.执行测试。由于Hive对数据的处理,依赖MapReduce计算模型,所以需要保证Hadoop相关进程已经启动。
输入jps,查看进程状态。若Hadoop相关进程未启动,则需启动Hadoop。
/apps/hadoop/sbin/start-all.sh 启动Hadoop后,在终端命令行界面,直接输入hive便可启动Hive命令行模式。
hive 输入HQL语句查询数据库,测试Hive是否可以正常使用。
show databases; 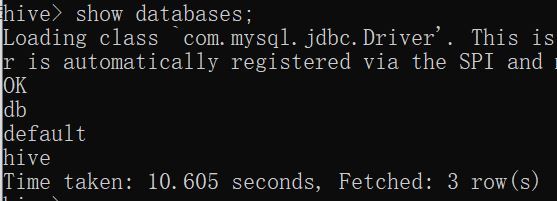
踩坑
报错:hive启动时报错
Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因:hadoop和hive的lib下有一个guava开头的jar包不匹配。
查看guava开头的jar分别在hadoop和hive上的所在路径
Hadoop:
cd /apps/hadoop/share/hadoop/common/lib/Hive:
cd /apps/hive/lib/解决:查看所在路径下的guava开头的jar,选择版本高的那个去覆盖另一个。
mv /apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /apps/hive/lib/删除掉版本低的
rm -f guava-19.0.jar完成!