一、扩展FlinkSQL实现流与维表的join
二、为什么要扩展FlinkSQL?
1、实时计算需要完全SQL化
SQL是数据处理中使用最广泛的语言。它允许用户简明扼要地声明他们的业务逻辑。大数据批计算使用SQL很常见,但是支持SQL的实时计算并不多。其实,用SQL开发实时任务可以极大降低数据开发的门槛,在袋鼠云数栈-实时计算模块,我们决定实现完全SQL化。
数据计算采用SQL的优势
☑ 声明式。用户只需要表达我想要什么,至于怎么计算那是系统的事情,用户不用关心。
☑ 自动调优。查询优化器可以为用户的 SQL 生成最有的执行计划。用户不需要了解它,就能自动享受优化器带来的性能提升。
☑ 易于理解。很多不同行业不同领域的人都懂 SQL,SQL 的学习门槛很低,用 SQL 作为跨团队的开发语言可以很大地提高效率。
☑ 稳定。SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。所以当我们升级引擎的版本时,甚至替换成另一个引擎,都可以做到兼容地、平滑地升级。
参考链接:https://blog.csdn.net/weixin_...
2、实时计算还需要流与维表的JOIN
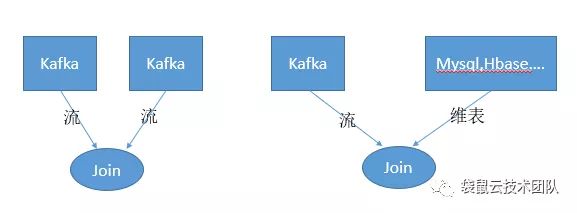
在实时计算的世界里不只是流与流的JOIN,还需要流与维表的JOIN。在去年,袋鼠云数栈V3.0版本研发期间,当时最新版本——flink1.6中FlinkSQL,已经将SQL的优势应用到Flink引擎中,但还未支持流与维表的JOIN。
FlinkSQL于2017年7月开始面向阿里巴巴集团开放流计算服务的,虽然是一个非常年轻的产品,但是到双11期间已经支撑了数千个作业,在双11期间,Blink 作业的处理峰值达到了5+亿每秒,而其中仅 Flink SQL 作业的处理总峰值就达到了3亿/秒。
参考链接:https://yq.aliyun.com/article...
里先解释下什么是维表;维表是动态表,表里所存储的数据有可能不变,也有可能定时更新,但是更新频率不是很频繁。在业务开发中一般的维表数据存储在关系型数据库如mysql,oracle等,也可能存储在hbase,redis等nosql数据库。
三、FlinkSQL实现流与维表的join分步走
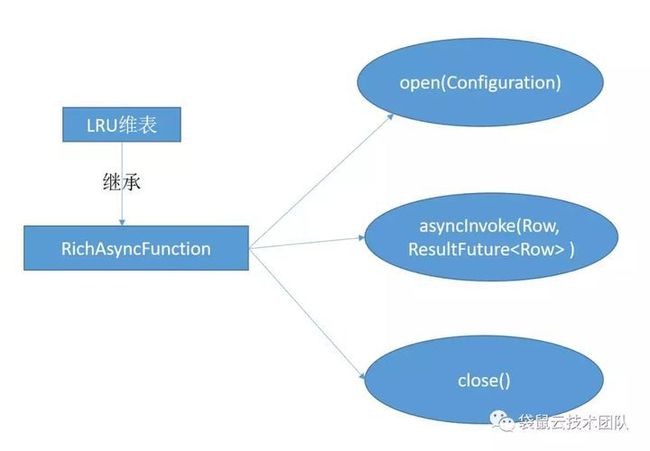
1、用Flink api实现维表的功能
要实现维表功能就要用到 Flink Aysnc I/O 这个功能,是由阿里巴巴贡献给Apache Flink的。
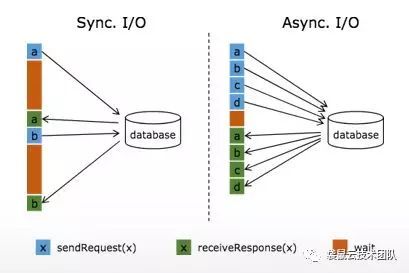
Async I/O 是由阿里巴巴贡献给社区的,于1.2版本引入,主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
具体介绍可以看这篇文章:http://wuchong.me/blog/2017/0...
对应到Flink 的api就是RichAsyncFunction 这个抽象类,继层这个抽象类实现里面的open(初始化),asyncInvoke(数据异步调用),close(停止的一些操作)方法,最主要的是实现asyncInvoke 里面的方法。
流与维表的join会碰到两个问题:
1)第一个是性能问题。
因为流速要是很快,每一条数据都需要到维表做下join,但是维表的数据是存在第三方存储系统,如果实时访问第三方存储系统,不仅join的性能会差,每次都要走网络io;还会给第三方存储系统带来很大的压力,有可能会把第三方存储系统搞挂掉。
所以解决的方法就是维表里的数据要缓存,可以全量缓存,这个主要是维表数据不大的情况,还有一个是LRU缓存,维表数据量比较大的情况。
2)第二个问题是流延迟过来的数据这么跟之前的维表数据做关联。
这个就涉及到维表数据需要存储快照数据,所以这样的场景用HBase 做维表是比较适合的,因为HBase 是天生支持数据多版本的。

2、解析流与维表join的SQL语法转化成底层的FlinkAPI
因为FlinkSQL已经做了大部分SQL场景,我们不可能在去解析SQL的所有语法,在把他转化成底层FlinkAPI。
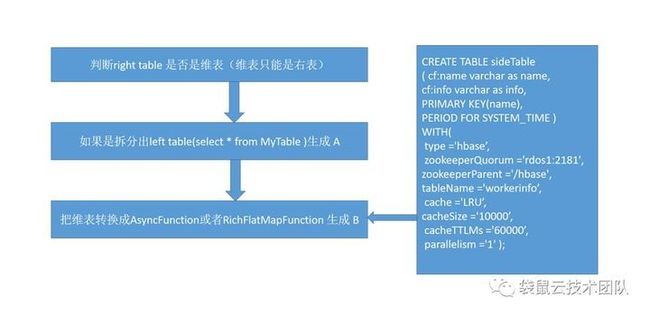
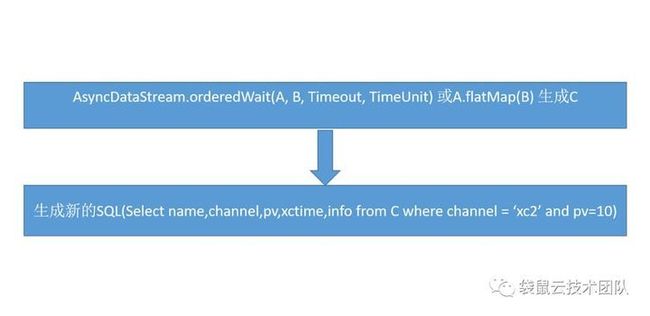
所以我们做的就是解析SQL语法,来找到join表里有没有维表,如果有维表,那我们会把这个join的维表的语句单独拆来,用Flink的TableAPI和StreamAPi 生成新DataStream,在把这个DataStream与其他的表在做join这样就能用SQL来实现流与维表的join语法了。
SQL解析的工具就是用Apache calcite,Flink也是用这个框架做SQL解析的。所以所有语法都是可以解析的。
1)DEMO SQL
insert
into
MyResult
select
d.channel,
d.info
from
( select a.*,b.info
from
MyTable a
join sideTable b
on a.channel=b.name
where a.channel = 'xc2’
and a.pv=10 ) as d
2)Calcite解析Insert into语句,拆分出子语句
select a.*,b.info from MyTable a join sideTable b on a.channel=b.name
where a.channel = 'xc2' and a.pv=10
select d.channel, d.info from d
insert into MyResult
3) Calcite继续解析select语句
old: select a.*,b.info from MyTable a join sideTable b on a.channel=b.name
where a.channel = 'xc2' and a.pv=10
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/fl...
gitee开源项目:https://gitee.com/dtstack_dev...