一、SuperEdge的定义
引用下SuperEdge开源官网的定义:
SuperEdge is an open source container management system for edge computing to manage compute resources and container applications in multiple edge regions. These resources and applications, in the current approach, are managed as one single Kubernetes cluster.
翻译过来的意思是:
SuperEdge 是开源的边缘容器解决方案,能够在单 Kubernetes 集群中管理跨地域的资源和容器应用。
我们通过关键词来简单解释下这句话:
- 开源
这个方案虽然是由腾讯云容器团队开源的边缘容器解决方案,但这是一个完全第三方中立的开源项目。官宣当日分别由 Intel、VMware、美团、寒武纪、首都在线、虎牙、腾讯共同官宣开源,并不由腾讯一家说了算,在边缘有想法的同学和企业也欢迎参与,共建边缘,共同推进边缘计算在实际场景的落地和发展。
- 边缘容器解决方案
这句话不用过多的解释,主要做容器的编排和调度管理。但是目前做容器的调度编排最火的方案是Kubernetes,为什么不拿 Kubernetes 直接做边缘容器的编排和调度管理呢?这个后面再解释。
- 单 Kubernetes 集群
还是用 Kubernetes 做容器编排调度,深入了解后,发现 SuperEdge 团队并没有删减 Kubernetes 任意一行代码,也就是说完全 Kubernetes 原生,具备 Kubernetes 对应版本的全部特性。
- 单 Kubernetes 集群中管理跨地域的资源和容器应用
重点词落在单和跨地域。为什么要在单 Kubernetes 集群中管理跨地域的资源和容器应用呢?场景、场景、还是场景决定的。
简单一个例子,有个连锁超市,10个营业网点,每个网点都有一个当日的特价广告推销程序。各个营业网点之间,以及营业网点和中心管控面之间,网络完全不通,完全独立,形成地域隔离。每个网点的广告程序完全一样,推送的内容也完全一样,目标是能够在单 Kubernetes 集群中,管理10个营业网点,像管理一个网点一样轻松。
二、可能存在的问题
看了SuperEdge官网的特性,我也没完全懂。什么是 Network tunneling? 为什么要 Built-in edge orchestration capability? 介绍的特性到底可以解决什么问题,我也存疑?
还是拿有个连锁超市,10个营业网点,中心和网点之间,网点和网点之间网络不通,但要部署运维同一个应用程序来设计下解决方案,看看这其中需要解决的问题,也许对SuperEdge的特性和设计初衷就能就更好的掌握了。
我们看下这个例子在实际的场景中,我们将要面对的问题:
1.10个营业网点一样的程序
虽然例子中只有10个营业网点,但实际中可能成百上千。我们也要考虑以后的扩展性,成百上千网点要让同一个程序全部都同步起来做一件事,难度自然不小。要是管理成百上千的营业网点,就像管理一个网点一样轻松容易,那确实轻松不少。
2.中心和网点之间,网点和网点之间网络不通
现实中真实存在这样的场景,毕竟专线耗时耗力成本高。真实的场景比较复杂,各个网点可能是一个小机房,也可能是一个小盒子,没有公网IP。有的网点几百个盒子,只有一个盒子可以访问外网,有的甚至所有的盒子都无法访问外网,部署的时候就相当的困难。
3.弱网、地域相隔甚远
边缘的场景不比中心,边缘的很多盒子,比如摄像头,各个区域都可能是走公网访问或者WIFI连接,时不时断网,短则几分钟,或者几个小时,长则几天都连不上网,都属于正常现象。更有甚者,断电重启一下……要在这种场景下保证边缘业务能够正常提供服务,尽可能提高服务的可用性,就是挑战了。
4.如何知道边缘节点的健康性?
边缘节点不健康了,就要把异常节点的服务调度到可用的节点上去,尽可能的保证服务的健康性。中心和边缘网络不通,各个网点的网络又不通的情况下,要怎么知道网点节点的健康性?
5.资源有限
嵌入式边缘节点往往资源有限,1G1C很常见,如何保证边缘资源有限的情况下,把边缘服务运行起来?
6.资源混部
中心云Kubernetes既想管理中心云应用,又想管理边缘应用,怎么搞呢?
...
不展开说了,这里面要考虑的细节问题还是比较多的,不能等在实际场景中碰到了才去解决,一定要在方案设计的时候,就尽可能的解决掉将要面对的问题。这样我们才能把有限的时间投入到具体的业务中,而不是和底层架构较劲。
三、思考自己的解决方案
如果我们遇到上面的问题,如何解决呢?
1.10个营业网点一样的程序
让一个程序以不变的环境,一份程序到处运行,比较好的解决方式是什么?容器,一个测试好的镜像,只要底层机型系统一致,运行起来问题不大。
2.用什么做容器的编排调度呢?
当然是 Kubernetes,可问题是开源社区的 Kubernetes 能直接拿来用吗?答案是:不能!为什么?因为Kubernetes官网网络模型中明确表明:
Kubernetes imposes the following fundamental requirements on any networking implementation (barring any intentional network segmentation policies):
- pods on a node can communicate with all pods on all nodes without NAT
- agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node也就说 Kubernetes 要求节点和 kube-apiserver 所在 master 节点网络互通,即节点的组件能访问 master 节点的组件,master 节点的组件也能访问节点的组件。我们的第二问题是中心和网点间网络不通,直接部署原生的Kubernetes 显然是行不通的,那么我们该如何解决边缘服务的管理呢?
3.弱网
弱网的话,即使我们中心和边缘建立了连接,但是中心和边缘也会时不时的断网,断网的情况下如何保证边缘容器正常服务呢?还有重启边缘节点,边缘容器能够正常服务的问题。
4.地域相隔甚远,边缘节点的部署怎么搞?
地域相隔甚远就得考虑部署的问题,我们不可能每部署一个网点都跑到用户那里去。出了什么问题,还得用户给开个后门,远程连接用户的节点去解决。
...
拿真实的场景思考下来,面临的问题还真是不少,希望这些问题可以引起大家的深思,边缘解决方案没有统一的标准,只能要能平滑的解决客户的问题,就是完美的方案。
下来我们一起看看 SuperEdge 的解决方案。
四、SuperEdge的功能
在介绍功能之前我们先把 SuperEdge 的架构图贴出来,一边看架构图,一边挖掘 SuperEdge 的实现:
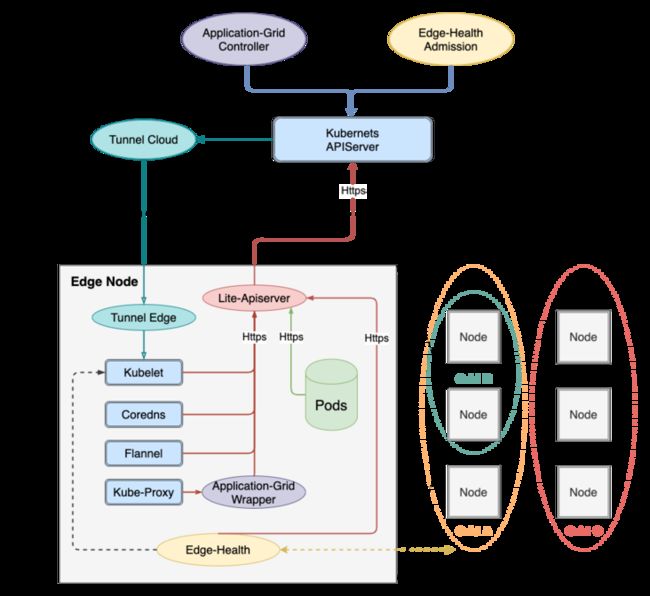
1.Network tunneling(tunnel隧道)
看了这个功能的介绍和 SuperEdge 的架构图,其实 Network tunneling 就是图中的 tunnel 隧道。在边缘节点部署一个 tunnel-edge, 在中心部署一个 tunnel-cloud。由 tunnel-edge 主动向 tunnel-cloud 发起请求建立长连接,这样即使边缘节点没有公网IP也能建立边端和云端的连接,让中心和边缘节点互通,本质就是 tunnel 隧道技术。
2.Edge autonomy(边缘自治)
这个主要是解决弱网和重启的。即使有了 Network tunneling,边缘节点和云端的网络不稳定是改变不了的事实,动不动断连还是存在的。边缘自治功能满足两个边缘场景:
一是中心和边缘之间断网,边缘节点的服务是不受影响的;
二是边缘节点重启,重启之后,边缘节点上的服务仍然能够恢复。
这个功能是怎么实现的?
看看 lite-apiserver 的介绍就明白了。这个组件把边缘节点请求中心的管理数据全部都缓存下来了,利用落盘数据在工作,维持了边缘服务,即使重启也能正常提供服务。不过有个问题,边缘自治的应用也会产生数据,产生的数据如何处理?会不会产生脏数据,影响边缘服务呢?这个问题留给大家思考。
3.Distributed node health monitoring(分布式健康检查)
不过我更疑惑了,为什么中心和边缘节点断网了,边缘节点的服务没有被驱逐呢?按照Kubernetes的逻辑,边缘节点NotReady,节点上的服务应该会被驱逐到其他Ready的节点上才对,为什么没有产生驱逐呢?难道SuperEdge关闭了边缘节点的驱逐。经我确认SuperEdge并没有关闭驱逐,而且在官网开源文档中强调只有在确认边缘节点异常的情况下才会产生Pod驱逐。
那么 SuperEdge 是如何确认边缘节点异常的呢?我后面在 edge-health 的组件介绍中找到了答案。
edge-health 运行在每个边缘节点上,探测某个区域内边缘节点的健康性。原理大概是这样的,在某个区域内,边缘节点之间是能互相访问的,然后运行在每个边缘节点的 edge-health 周期性的互相访问,确认彼此的健康性,也包括自己。按照大家的探测结果,统计出每个边缘节点的健康性,要是有XX%节点认为这个节点异常(XX%是healthcheckscoreline 参数配置的,默认100%) ,那么就把这个结果反馈给中心组件 edge-health admission。
edge-health admission 部署在中心,结合边缘节点的状态和 edge-health 的投票结果,决定是否驱逐边缘服务到其他边缘节点。通过运用 edge-health,设置好 healthcheckscoreline,只要是边缘节点不是真正的宕机,服务就不会驱逐。一来提高了边缘服务的可用性,二来很好的扩展了 Kubernetes 驱逐在边缘的运用。
可我仍有个疑问,要是有个边缘节点确实宕机了,服务也被驱逐到了其他边缘节点,但是后面这个边缘节点的健康性恢复了,边缘节点上的服务怎么处理?
4.Built-in edge orchestration capability
这个功能,个人认为是最具实用性的。也是就由架构图的application-grid controller和application-grid wrapper 两个组件联合提供的ServerGroup能力。
ServiceGroup有什么用呢?
拿那个连锁超市有10个营业网点的例子来说,大概提供了两个功能:
- 多个营业网点可以同时部署一套特价广告推销解决方案;
这个有什么稀奇的呢?注意是同时,就是说您有一个deployment,给中心集群提交了一次,就可以同时给10个营业网点,每个网点都部署一套这样的deployment解决方案。这样就能做到,管理10个营业网点的特价广告推销程序,像管理一个网点的特价广告推销程序一样轻松。并且新加入的网点,会自动部署特价广告推销解决方案,完全不用管版本、命名的问题了。
- 多个站点部署的服务有差别,即灰度能力
这个属于 ServiceGroup 的扩展功能,同一套服务在不同地域可能有字段的差异,或者镜像版本不一样,可以利用DeploymentGrid 的 templatePool 定义不同地域或者站点的模板,利用 Kubernestes Patch 功能,Patch 出基于基础版本不同运行版本。这样在某个服务上线前,进行一个地域的灰度,或者定义一套服务在各个站点运行的服务不同,利用 DeploymentGrid 的 templatePool 就可以简单的进行管理。
- 同一套解决方案不跨网点访问;
什么意思?即使各个网点网络互通,每个网点都部署了特价广告推销程序,A网点的程序也不会去访问B网点的特价广告推销服务,只会访问本网点的服务,实现了流量闭环。
这么做的好处个人认为有两个:
- 实现了网点访问流量闭环,本网点的服务只能访问本网点;
- 促进了边缘自治,要是一个网点连接不上中心,这个网点完全可以利用自己的服务实现自治,并不会访问其他网点。
这个功能确实在边缘的场景中很实用,可以把 application-grid controller和application-grid wrapper 两个组件独立的部署在 Kubernetes 集群中,解决多个网点多套解决方案的管理问题,大家也可以按 ServerGroup的文档 自己体验体验。
今天说到这里,基本把 SuperEdge 的基本功能分析的差不多了,后面有机会在深入剖析SuperEdge内部的原理!
5. 合作和开源
TKE Edge 边缘容器管理服务的边缘计算能力核心组件已经开源到 SuperEdge项目,欢迎共建边缘计算,参与 SuperEdge 开源项目的建设,让您开发的边缘能力惠及更多人。以下是SuperEdge开源项目的微信群,环境参与交流讨论。

SuperEdge版本:
TKE Edge相关文章:
- 【TKE 边缘容器系列】用 edgeadm 一键安装边缘 K8s 集群和原生 K8s 集群
- 【TKE 边缘容器系列】从0到N了解 SuperEdge,这些干货一定要看!【18篇干货合集】
- 【TKE 边缘容器系列】打破内网壁垒,从云端一次添加成百上千的边缘节点
- 【TKE 边缘容器系列】SuperEdge 云边隧道新特性:从云端SSH运维边缘节点
- 【TKE 边缘容器系列】一文读懂 SuperEdge 边缘容器架构与原理
- 【TKE 边缘容器系列】一文读懂 SuperEdge 分布式健康检查边端
- 【TKE 边缘容器系列】一文读懂 SuperEdge 拓扑算法
- 【TKE 边缘容器系列】一文读懂 SuperEdge 云边隧道
落地案例相关资料:
- 腾讯WeMake工业互联网平台的边缘容器化实践:打造更高效的工业互联网
- 完爆!用边缘容器,竟能秒级实现团队七八人一周的工作量
- 基于边缘容器技术的工业互联网平台建设
-
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
