“时势造英雄”,是亘古不变的真理。在当前的时代背景下,在线文档可以称得上是这样的“英雄”。
自 2020 年新冠疫情爆发以来,远程办公彻底颠覆了传统的企业管理模式,在线文档作为远程办公软件的重要组成部分也同样迎来了高速发展。
如今,即便市场中已经有了腾讯文档、石墨文档、飞书、语雀和灵犀文档等在线办公产品,但在线文档本身仍面临功能、技术、数据安全、服务、生态等多方面的考验,如数据处理效率、多人协作、二次扩展、系统集成、框架兼容性问题等。
从技术角度来看,在线、数据处理和多人协作是开发在线文档系统最关键的技术指标。不过,在线和数据处理均已有较成熟的技术方案,实现难度不大。因此,多人协作才是影响在线文档系统易用性的核心要素。
什么是多人协作?
多人协作,即多人同时对同一份文档进行编辑,用户无需刷新即可看到其他人所做的修改。Google Docs、腾讯文档、石墨文档、Quip 等都具备多人协作功能。
那么,多人协作是如何实现的呢?
任何信息如要做到多人实时编辑与展现,需要实现以下三步:
- 操作化
- 可传输
- 可还原
这三步,类似于编解码过程。首先将信息转换为一组操作集合,然后将操作通过网络传输给其他终端,最后在本地终端将操作还原为信息。
这些步骤看起来简单,但每一步都需要考虑很多。比如操作化过程中,在对信息进行分割与组合时,如何确保信息的所有变化都可以分解为操作的集合、如何令操作覆盖信息的所有变化,以及如何决定分割的颗粒度。
可传输需要考虑以下几点:
- 传输内容
a. 原始文本
i. 清晰
ii. 冗余
b. 压缩技术
i. 逻辑压缩
ii. 协议压缩
iii. 手动压缩 - 网络协议
a. Socket
i. TCP
ii. UDP
b. HTTP
c. WebSocket - QoS(Quality of Service,服务质量)
a. 快速失败
b. 自动回滚
c. 自动重连
d. 自动恢复
可还原主要涉及:
- 绝对操作的还原
a. 控制体积
b. 合理的提示 - 相对操作的还原
a. 严格的顺序性
b. 从源头保障顺序性
c. 顺序性的补救 - 本地操作的还原
a. 过滤收到的操作集合
b. 从源头细化操作颗粒
c. 本地保存本地执行 - 无入侵的还原
a. 定义入侵
b. 排除入侵
c. 千人千面
在了解了多人协作的基本原理之后,我们来研究一下它的技术难点。
多人协作有哪些技术难点?
多人协作,本质是分布式系统中的 Multiple Leader Replication,即任何一个用户端都可被视为 Data Leader,这些 Leader 之间同步数据必然会遇到乱序和冲突问题。这就是多人协作的主要难点。
对于 Multiple Leader Replication 的冲突问题,有如下解决方法:
- 避免产生冲突,即不让多个用户同时编辑同一处地方。该解决方法简单粗暴,使用时需具体查看产品形态是否适合该方案。
- 把冲突暴露给用户,让用户自己解决。目前大多数专业的版本控制软件采用了该方法,但它不适用于拥有大量非专业用户的产品,如在线文档。
- 给写入操作打上全局 index,可以是时间戳或序列号,该 index 必须是全局的且递增。在任何冲突的地方,都选择 index 较高的那个写入。该方法的优势在于冲突的解决是完全自动化的,不需要用户参与。缺点就是如果遇到同步间隔很长的情况,会丢失很多用户的输入。
在实际开发在线文档系统的过程中,Operational Transformation(OT)算法技术是解决多人协作冲突问题较为常用的方法。这项技术诞生于 1989 年,其原理是将文本内容统一为以下 3 种类型的操作方式,目的是为用户提供最终一致性实现:
- retain(n):保持 n 个字符
- insert(str):插入字符 str
- delete(str):删除字符 str
在完成上述操作后,OT 算法将正在并发的操作合并转换,以形成新的操作流,并应用在历史版本上,实现无锁化同步编辑。

OT 算法技术中的操作转换过程(图源: https://en.wikipedia.org/wiki... )
OT 算法背后的思想其实非常简单,就是在特定的条件下进行相应的操作转换,因此,OT 主要用于文本,通常很复杂且不可扩展。对于富文本编辑等更高级的结构,OT 用复杂性换来了对用户预期的实现,不会给系统性能造成过多的负面影响。因此,如今大多数实时协同编辑逻辑都是基于 OT 算法来实现的。
正因如此,OT 算法成为了解决当前协同冲突处理最主要的方案之一。然而,即便它已经诞生了 30 余年,控制算法相关的理论早已百花齐放,却仍无法很好地处理分布式实现问题,且开发一个支持多人实时协同编辑的系统也远比想象中的更加复杂。
实现多人协作的突破口在哪里?
由此可见,实现一款复杂的多人实时协同编辑系统仅仅依靠算法逻辑是不够的,还需要根据不同的业务场景(如项目看板、纯文本编辑、undo/redo 等),投入大量的研发成本和时间,并在不断摸索中,寻找到产品性能和易用性之间的平衡点。
那么,是否存在一条更为简单快捷的解决方法呢?
通过对市面上多款在线协同办公产品的示例代码进行分析,我们发现这些产品除了运用到前文提到的 OT 算法之外,基本都会借助第三方表格组件。通过嵌入组件,在线文档系统很好地支持了多人协作的最终一致性,给用户提供了更加易用且多样化的体验效果,在减少研发成本的同时,实现了更高密度的计算复杂度,大幅提高了多人协作效率。
用于多人协作的表格组件需要具备哪些功能?
首先,是对于表格的功能支持。
由于表格的数值敏感性远高于其他数据类型,用作多人协作文档时可以实现更为细腻的操作颗粒度和计算复杂度。因此,所选用的组件必须具备强大的表格功能支持,不仅要在数据录入、数据填报等方面展现出强大的能力,还要具备各类统计、计算汇总、透视分析,以及图形化手段。
其次,需要具备开放的 API 接口,满足更多定制化选项。
这类组件需要提供丰富的事件和应用程序接口,用于控制单元格状态、表单保护、数据传输等逻辑,对于多人协作而言,还需限制用户对同一处内容进行编辑,以及插入时间戳(序列化)等功能。
出于好奇,笔者下载试用了网上多款表格组件,发现能满足上述需求的屈指可数,而 SpreadJS 无疑是最为亮眼的一款。这款组件主打可嵌入系统的“在线 Excel”,纯前端的体系架构可以很容易的嵌入系统开发,而无需考虑与原生系统的兼容性。值得一提的是,SpreadJS 采用了稀疏数组 (Sparse Array) 作为存储模型,相较于传统的链式存储或数组存储,稀疏数组只会对非空数据进行存储,而不需要对空数据开辟额外的内存空间。
除了节省内存空间外,对于表格这类布局松散的数据类型,稀疏数组也更易于构建基于行索引的数据字典,以便随时替换或恢复整个存储结构中的任何一个级别的节点,借助这一特性,SpreadJS 在多人协同中实现了高效的数据回滚和数据恢复 (Redo/Undo)。
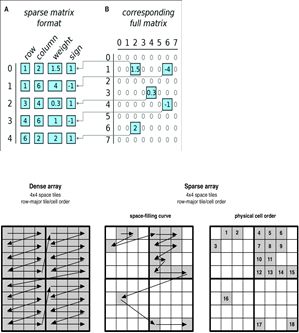
SpreadJS 的稀疏矩阵存储模型 (Sparse Array)
结语
疫情加速了企业数字化转型。未来企业协同办公将朝着产品易用性提升、可集成与二次扩展能力、与原系统/业务的高度契合、满足最终用户的使用习惯等层面发展。
如何打破技术壁垒,开发出既能满足不同场景下的用户需求,又具备市场竞争力和差异化的在线文档产品,是 SaaS 企业和系统供应商们首要考虑的问题。
“好风凭借力,送我上青云。”在如今竞争激烈的在线文档领域,除了耗费大量精力自主研发,学会借力打力满足不同的业务场景和客户需求,或许也是一个不错的选择。
如果你想了解更多前端表格技术,欢迎参加本周六举行的 SegmentFault D-Day 大前端技术沙龙,葡萄城高级产品技术顾问、技术布道师姚尧将与大家面对面交流和分享前端电子表格技术的那些事儿。

点击这里,了解更多详情!