1. 前言
本篇文章记录了一次接口慢查问题排查过程,该问题产生的现象迷惑性较高。同时由于问题偶发性高,排查难度也比较大。排查过程从 druid 数据源“导致”的一个慢查现象作为切入点,逐步分析,排除诸多可能性后仍无解。之后重新审视故障现象,换个角度分析,找到了问题根因。最后对问题原因进行了验证确认,结果符合预期。到此,排查过程算是结束了,本文对问题进行记录归档。
2. 问题描述
前段时间收到业务同事反馈,说他们应用的某台机器连续两天多个接口出现了两次慢查情况(偶发性较高)。但持续时间比较短,但很快又恢复了。Pinpoint 调用链信息如下:
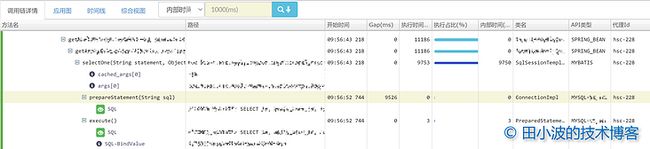
图1:长 RT 接口调用链信息
上图是业务同学反馈过来的信息,可以看出从 MyBatis 的 SqlSessionTemplate#selectList 方法到 MySQL 的 ConnectionImpl#prepareStatement 方法之间出现了 2111 毫秒的间隔,正是这个间隔导致了接口 RT 升高。接下来针对这个现象进行分析。
3. 排查过程
3.1 直奔主题
从全链路追踪系统给出的链路信息来看,问题的原因似乎很明显,就是 selectList 和 prepareStatement 之间存在着长耗时的操作。理论上只要查出哪里出现了长耗时操作,以及为什么发生,问题就解决了。于是先不管三七二十一,直接分析 MyBatis 的源码吧。
public class SimpleExecutor extends BaseExecutor {
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog()); // 预编译
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog); // 获取数据库连接
stmt = handler.prepare(connection, transaction.getTimeout()); // 执行预编译
handler.parameterize(stmt);
return stmt;
}
} MyBatis 的 SqlSessionTemplate#selectList 方法的调用链比较长,这里就不一一分析,感兴趣可以看一下我三年前的文章 MyBatis 源码分析 - SQL 的执行过程。SqlSessionTemplate#selectList 最终会执行到 SimpleExecutor#doQuery,该方法在执行后续逻辑前,会先调用 SimpleExecutor#prepareStatement 进行预编译。prepareStatement 方法涉及到两个外部操作,一个是获取数据库连接,另一个是执行调用 MySQL 驱动相关方法执行预编译。
从图1的监控上看,预编译速度很快,可以确定预编译没有问题。现在,把注意力移到 getConnection 方法上,这个方法最终会向底层的 druid 数据源申请数据库连接。druid 采用的是生产者消费者模型来维护连接池,更详细的介绍参考我的另一篇文章。如果连接池中没有可用连接,这个时候业务线程就会等待 druid 生产者创建连接。如果生产者创建连接速度比较慢,或者活跃连接数达到了最大值,此时业务线程就必须等待了。好在业务应用接了 druid 监控,我们可以通过监控了解连接池的情况。
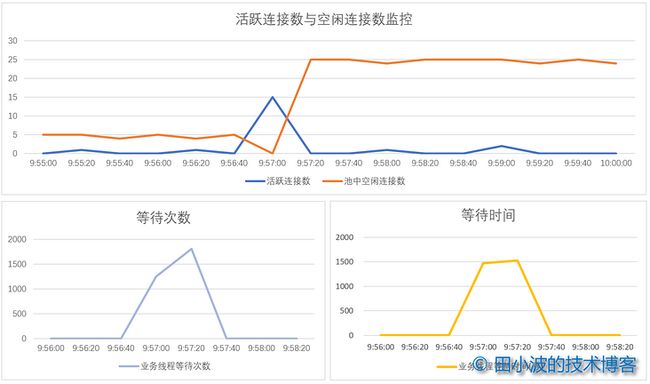
图2:druid 监控图
上图是用 excel 绘制的,数据经过编辑,与当时情况存在一定的偏差,但不影响后续的分析。从监控上来看,连接池中的空闲连接全部被借出去了,但仍然不够,于是生产者不停的创建连接。这里引发了我们的思考,为什么活跃连接数会突然上升这么多?可能是出现了慢查。与此同时,业务线程的等待次数和等待时间大幅上涨,这说明 druid 连接生产者的“产能”似乎不足,以至于部分业务线程出现了等待。什么情况下生产者创建连接会出现问题呢?我们当时考虑到的情况如下:
- 网络出现了延迟或者丢包,造成重传
- 阿里云 RDS 实例负载很高,无法及时响应客户端的连接建立请求
先说第二种情况,RDS 负载的问题很好确认,阿里云上有 RDS 的监控。我们确认了两次问题发生时的监控曲线,发现实例负载并不高,没有明显波动,所以情况二可以排除。那情况一呢,网络会不会出现问题呢?这个猜想不好排除。原因如下:
活跃连接数正常情况下会很低,暴涨一般都不是正常现象。假如一个 Java 线程从发出 SQL 请求到收到数据耗时 5ms,那么一条连接可以达到 200 的 QPS。而这个单机 QPS 还不足 200,不应该用掉这么多连接,除非出现了慢查。但是我们用阿里云的 SQL 洞察服务里也没发现慢 SQL,因此可以排除掉慢查的可能性。不是慢查,似乎只能甩锅给网络了,一定是当时的网络(接锅好手)出了问题。
如果真是网络出问题了,那么 druid 生产者“产能”不足的问题似乎也能得到合理的解释。但是经过我们的分析,发现了一些矛盾点,如下:
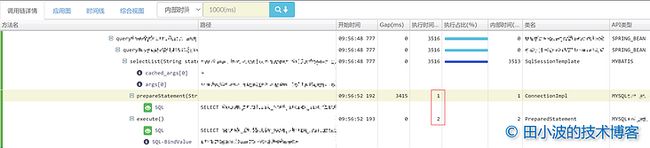
图3:某个长 RT 请求的链路追踪数据
从链路数据上来看,SQL 的预编译和执行时间都是很快的,没有出现明显的等待时间。如果说上面的情况是偶然,但是我们翻看了很多链路数据,都发现 SQL 的预编译和执行速度都很快,不存在明显的延迟。因此,把锅甩给网络是不合适的。
排查到这里,思路断了。首先没有发现慢查,其次数据库资源也是充足的,最后网络似乎也没问题。都没有问题,那问题出在哪里呢?
3.2 扩大信息面
3.2.1 基本信息
首先查看了问题机器的 QPS,发现没有突发流量。虽有一定波动,但总体仍然平稳。
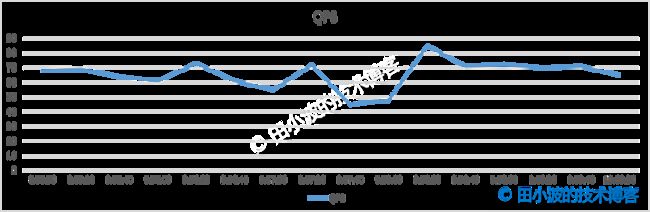
图4:QPS 折线图
接着看了应用的 CPU 使用率,发现了一点问题,使用率突然上升了很多。
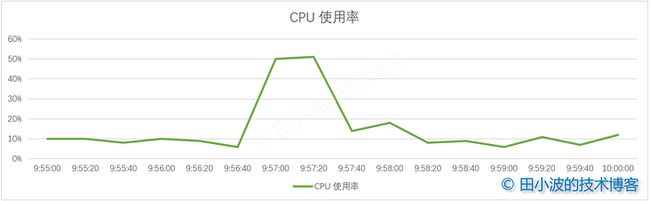
图5:CPU 使用率折线图
询问了业务同学,这个点没有定时任务,QPS 与以往相似,没有什么异常。目前不知道 CPU 为什么会突然上升这么多,这个信息暂时无法提供有效的帮助,先放着。最后再看一下网络 I/O 监控。
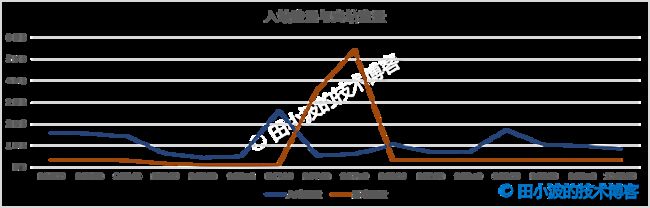
图6:网络流量监控图
入站流量与出站流量在问题发生时间段内都出现了上升,其中出站流量上升幅度很大,说明当时应该有大量的数据发出去。但具体是哪些接口的行为,目前还不知道。
3.2.2 业务日志信息
接着分析了一下业务日志,我们发现了一些 WARN 级别信息:
# 业务线程打出的 WARN 日志,表示等待连接超时,重试一次
2021-07-20 09:56:42.422 [DubboServerHandler-thread-239] WARN com.alibaba.druid.pool.DruidDataSource [DruidDataSource.java:1400] - get connection timeout retry : 1
2021-07-20 09:56:42.427 [DubboServerHandler-thread-242] WARN com.alibaba.druid.pool.DruidDataSource [DruidDataSource.java:1400] - get connection timeout retry : 1
2021-07-20 09:56:42.431 [DubboServerHandler-thread-240] WARN com.alibaba.druid.pool.DruidDataSource [DruidDataSource.java:1400] - get connection timeout retry : 1
# Dubbo TimeoutFilter 答疑超时日志
2021-07-20 09:56:42.432 [DubboServerHandler-thread-254] WARN org.apache.dubbo.rpc.filter.TimeoutFilter [TimeoutFilter.java:60] - [DUBBO] invoke time out. method: xxx arguments: [yyy] , url is dubbo://172.***.***.***:20880/****
2021-07-20 09:56:42.489 [DubboServerHandler-thread-288] WARN org.apache.dubbo.rpc.filter.TimeoutFilter [TimeoutFilter.java:60] - [DUBBO] invoke time out. method: **** arguments: [***, ***] , url is dubbo://172.***.***.***:20880/****这两种日志说实话没什么用,因为这些日志是结果,本就应该发生的。除了 WARN 信息,业务日志里找不到任何异常信息。需要说明的是,我们并没有设置业务线程获取连接重试次数,默认重试次数是0。但这里却进行了一次重试,而我们预期是业务线程在指定时间内获取连接失败后,应抛出一个 GetConnectionTimeoutException 异常。这个应该是 druid 的代码有问题,我给他们提了一个 issue (#4381),但是没人回复。这个问题修复也很简单,算是一个 good first issue,有兴趣的朋友可以提个 Pull Request 修复一下。
业务日志没有太多可用信息,我们继续寻找其他的线索,这次我们从 JVM 监控里发现了端倪。
3.2.3 GC 信息
问题发生的那一小段时间内,JVM 发生了多次的 YGC 和 FGC,而且部分 GC 的耗时很长。
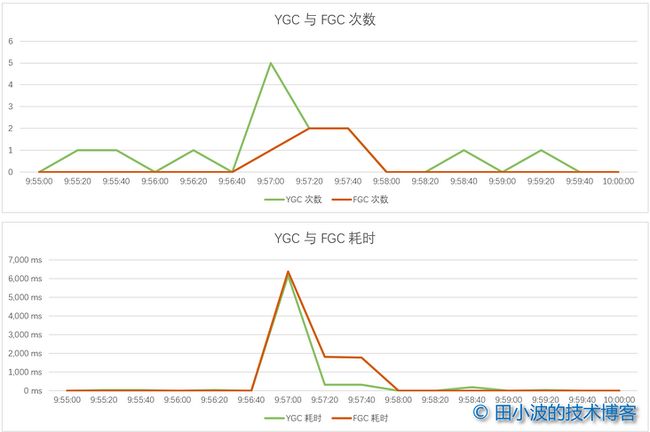
图7:GC 次数与耗时监控
那么现在问题来了,GC 是原因还是结果?由于 GC 发生的时间与接口慢查出现的时间都在 9.56:30 之后,时间上大家是重叠的,谁影响了谁,还是互相影响,这都是不清楚的。GC 的引入似乎让排查变得更为复杂了。
到这里信息收集的差不多了,但是问题原因还是没有推断出来,十分郁闷。
3.3 重新审视
3.3.1 综合分析
如果我们仍然从 druid 这个方向排查,很难查出原因。时间宝贵,现在要综合收集的信息重新思考一下了。既然发生了 GC,那么应用的内存消耗一定是上升了。再综合网络 I/O 的情况,短时间内出现了比较大的波动,好像也能说明这个情况。但当时网络流量并不是特别大,似乎还不足以引发 GC。支撑力不足,先放一边。另外,应用的 QPS 没有多大变动,但是 CPU 负载却突然上升了很多。加之几次 GC 的耗时很长,搞不好它们俩之间有关联,即长时间的 GC 导致了 CPU 负载上升。目前,有两个排查方向,一个是从网络 I/O 方向排查,另一个是从 GC 方向排查。就现象而言,GC 的问题似乎更大,因此后续选择从 GC 方向排查。
3.3.2 换个思路
JVM 进行 GC,说明内存使用率一定是上去了。内存上升是一个累积过程,如果我们把排查时间从发生长耗时 GC 的时刻 9:57:00 向前推一分钟,没准会发现点什么。于是我到全链路追踪平台上按耗时倒序,拉取了问题应用在 9:56:00 这一分钟内的长 RT 接口列表,发现耗时靠前的十几个都是 queryAll 这个方法。如下:
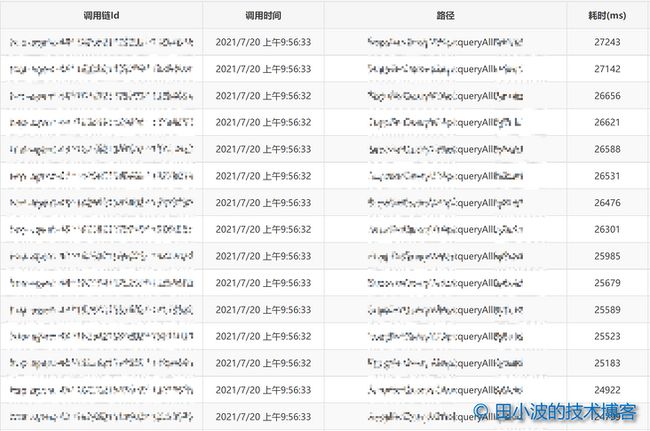
图8:queryAll 方法耗时倒序列表
我们看一下耗时最长请求的调用链信息:
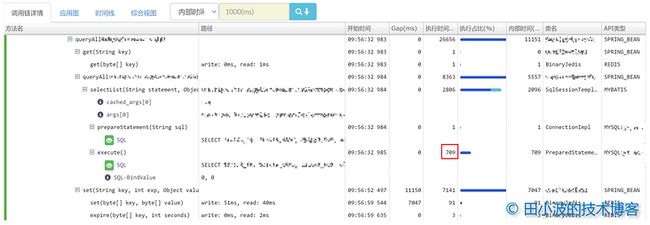
图9:耗时最长请求的链路信息
首先我们可以看到 MySQL 驱动的 execute 执行时间特别长,原因后面分析。其次 redis 缓存的读取耗时非常短,没有问题。但 redis 客户端写入数据耗时非常长,这就很不正常了。
于是立即向应用开发要了代码权限,分析了一下代码。伪代码如下:
public XxxService {
// 备注:该方法缓存实际上使用了 Spring @Cacheable 注解,而非显示操作缓存
public List queryAll(int xxxId) {
// 1、检查缓存,命中则立即返回
List xxxDTOs = customRedisClient.get(xxxId);
if (xxxDTOs != null) return list;
// 2、缓存未命中,查询数据库
List xxxDOs = XxxDao.queryAll(xxxId);
xxxDTOS = convert(xxxDOs)
// 3、写入缓存
customRedisClient.set(xxxId, xxxDTOs, 300s);
return list;
}
}代码做的事情非常简单,那为什么会耗时这么多呢?原因是这样的,如果缓存失效了,queryAll 这个方法一次性会从数据库里取出上万条数据,且表结构包含了一些复杂的字段,比如业务规则,通讯地址等,所以单行记录相对较大。加之数据取出后,又进行了两次模型转换(DO → DTO → TO),转换的模型数量比原始模型数量要多一半,约 1.5 万个,TO 数量与 DTO 一致。模型转换完毕后,紧接着是写缓存,写缓存又涉及序列化。queryAll 方法调用一次会在新生代生成约五份比较大的数据,第一份是数据集 ResultSet,第二份是 DO 列表,第三份是 DTO 列表,第四份 TO 列表,最后一份是 DTO 列表的序列化内容。加之两秒内出现了二十多次调用,加剧了内存消耗,这应该能解释为什么 GC 次数会突然上升这么多。下面还有几个问题,我用 FAQ 的方式解答:
Q:那 GC 耗时长如何解释呢?
A:我猜测可能是垃圾回收器整理和复制大批量内存数据导致的。
-------------------------------------------------✂-------------------------------------------------
Q:还有 execute 方法和 set 方法之间为什么会间隔这么长时间内?
A:目前的猜测是模型类的转换以及序列化本身需要一定的时间,其次这期间应该有多个序列化过程同时在就行,不过这也解释不了时间为什么这么长。不过如果我们把 GC 考虑进来,就会得到相对合理的解释。从 9:56:33 ~ 5:56:52 之间出现了多次 GC,而且有些 GC 的时间很长(长时间的 stop the world),造成的现象就是两个方法之间的间隔很长。实际上我们可以看一下 9:56:31 第一个 queryAll 请求的调用链信息,会发现间隔并不是那么的长:
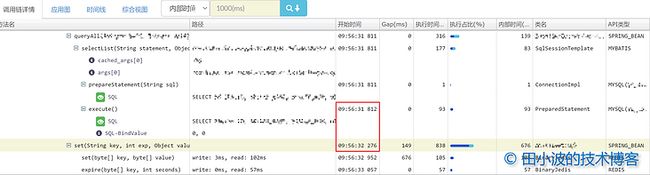
图10:queryAll 正常情况下的耗时情况
因此,我们可以认为后续调用链 execute 和 set 方法之间的超长间隔是因为 CPU 使用率,GC 等因素共同造成的。
-------------------------------------------------✂-------------------------------------------------
Q:第一个 set 和第二个 set 间隔为什么也会这么长?
A:第一个 set 是我们自定义的逻辑,到第二个 set 之间似乎没有什么特别的东西,当时没有查出问题。不过好在复现的时候,发现了端倪,后面章节给予解释。
-------------------------------------------------✂-------------------------------------------------
最后,我们把目光移到初始的问题上,即业务同事反馈部分接口 RT 上升的问题。下面仍用 FAQ 的方式解答。
Q:为什么多个接口的 RT 都出现了上升?调用链参考下图:
图11:某个长 RT 接口的链路信息
A:部分业务线程在等待 druid 创建数据库连接,由于 GC 的发生,造成了 STW。GC 对等待逻辑会造成影响。比如一个线程调用 awaitNanos 等待3秒钟,结果这期间发生了5秒的 GC(STW),那么当 GC 结束时,线程立即就超时了。在 druid 数据源中, maxWait 参数控制着业务线程的等待时间,代码如下:
public class DruidDataSource extends DruidAbstractDataSource {
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
// ...
final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait);
if (maxWait > 0) {
// 尝试在设定时间内从连接池中获取连接
holder = pollLast(nanos);
} else {
holder = takeLast();
}
// ...
}
}3.4 初步结论
经过前面的排查,很多现象都得到了合理的解释,是时候给个结论了:
本次 xxx 应用多个接口在两天连续出现了两次 RT 大幅上升情况,排查下来,初步认为是 queryAll 方法缓存失效,短时间内几十个请求大批量查询数据、模型转换以及序列化等操作,消耗量大量的内存,触发了多次长时间的 GC。造成部分业务线程等待超时,进而造成 Dubbo 线程池被打满。
接下来,我们要按照这个结论进行复现,以证明我们的结论是正确的。
4. 问题复现
问题复现还是要尽量模拟当时的情况,否则可能会造成比较大的误差。为了较为准确的模拟当时的接口调用情况,我写了一个可以控制 QPS 和请求总数的验证逻辑。
public class XxxController {
@Resource
private XxxApi xxxApi;
public Object invokeQueryAll(Integer qps, Integer total) {
RateLimiter rl = RateLimiter.create(qps.doubleValue());
ExecutorService es = Executors.newFixedThreadPool(50);
for (Integer i = 0; i < total; i++) {
es.submit(() -> {
rl.acquire();
xxxApi.queryAll(0);
});
}
return "OK";
}
}复现的效果符合预期,CPU 使用率,网络 I/O 都上去了(由于监控属于公司内部系统,就不截图了)。同时 GC 也发生了,而且耗时也很长。GC 日志如下:
2021-07-29T19:09:07.655+0800: 631609.822: [GC (Allocation Failure) 2021-07-29T19:09:07.656+0800: 631609.823: [ParNew: 2797465K->314560K(2831168K), 2.0130187 secs] 3285781K->1362568K(4928320K), 2.0145223 secs] [Times: user=3.62 sys=0.07, real=2.02 secs]
2021-07-29T19:09:11.550+0800: 631613.717: [GC (Allocation Failure) 2021-07-29T19:09:11.551+0800: 631613.718: [ParNew: 2831168K->314560K(2831168K), 1.7428491 secs] 3879176K->1961168K(4928320K), 1.7443725 secs] [Times: user=3.21 sys=0.04, real=1.74 secs]
2021-07-29T19:09:13.300+0800: 631615.467: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1646608K(2097152K)] 1965708K(4928320K), 0.0647481 secs] [Times: user=0.19 sys=0.00, real=0.06 secs]
2021-07-29T19:09:13.366+0800: 631615.533: [CMS-concurrent-mark-start]
2021-07-29T19:09:15.934+0800: 631618.100: [GC (Allocation Failure) 2021-07-29T19:09:15.934+0800: 631618.101: [ParNew: 2831168K->2831168K(2831168K), 0.0000388 secs]2021-07-29T19:09:15.934+0800: 631618.101: [CMS2021-07-29T19:09:17.305+0800: 631619.471: [CMS-concurrent-mark: 3.668/3.938 secs] [Times: user=6.49 sys=0.01, real=3.94 secs]
(concurrent mode failure): 1646608K->1722401K(2097152K), 6.7005795 secs] 4477776K->1722401K(4928320K), [Metaspace: 224031K->224031K(1269760K)], 6.7028302 secs] [Times: user=6.71 sys=0.00, real=6.70 secs]
2021-07-29T19:09:24.732+0800: 631626.899: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1722401K(2097152K)] 3131004K(4928320K), 0.3961644 secs] [Times: user=0.69 sys=0.00, real=0.40 secs]
2021-07-29T19:09:25.129+0800: 631627.296: [CMS-concurrent-mark-start]
2021-07-29T19:09:29.012+0800: 631631.179: [GC (Allocation Failure) 2021-07-29T19:09:29.013+0800: 631631.180: [ParNew: 2516608K->2516608K(2831168K), 0.0000292 secs]2021-07-29T19:09:29.013+0800: 631631.180: [CMS2021-07-29T19:09:30.733+0800: 631632.900: [CMS-concurrent-mark: 5.487/5.603 secs] [Times: user=9.29 sys=0.00, real=5.60 secs]
(concurrent mode failure): 1722401K->1519344K(2097152K), 6.6845837 secs] 4239009K->1519344K(4928320K), [Metaspace: 223389K->223389K(1269760K)], 6.6863578 secs] [Times: user=6.70 sys=0.00, real=6.69 secs]接着,我们再看一下那段时间内的接口耗时情况:
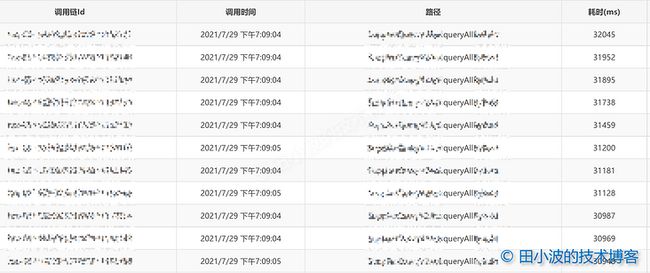
图12:问题复现时的 queryAll 耗时倒序列表
所有接口的消耗时间都很长,也是符合预期的。最后再看一个长 RT 接口的链路信息:
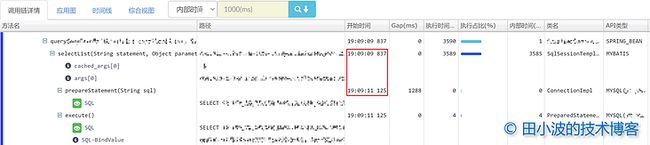
图13:某个长 RT 接口的链路信息
会发现和图片1,也就是业务同学反馈的问题是一致的,说明复现效果符合预期。
验证到这里,可以证明我们的结论是正确的了。找到了问题的根源,这个问题可以归档了。
5. 进一步探索
5.1 耗时测算
出于性能考虑,Pinpoint 给出的链路信息力度比较粗,以致于我们无法详细得知 queryAll 方法的耗时构成是怎样的。为了搞清楚这里面的细节,我对 queryAll 方法耗时情况进行比较详细的测算。在应用负载比较低的情况下触发一个请求,并使用 Arthas 的 trace 命令测算链路耗时。得到的监控如下:

图14:正常情况下 queryAll 方法链路信息
这里我对三个方法调用进行了编号,方法 ① 和 ② 之间存在 252 毫秒的间隔,方法 ② 和 ③ 之间存在 294 毫秒的间隔。Arthas 打印出的链路耗时情况如下:
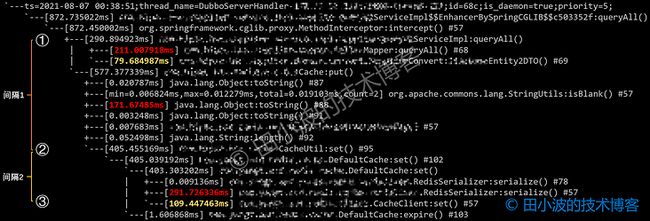
图15:queryAll 方法耗时测量
这里的编号与上图一一对应,其中耗时比较多的调用我已经用颜色标注出来了。首先我们分析间隔1的构成,方法 ① 到 ② 之间有两个耗时的操作,一个是批量的模型转换,也就是把 DO 转成 DTO,消耗了约 79.6 毫秒。第二个耗时操作是 Object 的 toString 方法,约 171.6。两者加起来为 251.2,与全链路追踪系统给出的数据是一致的。这里大家肯定很好奇为什么 toString 方法会消耗掉这么多时间,答案如下:
public void put(Object key, Object value) {
// 省略判空逻辑
// 把 key 和 value 先转成字符串,再进行判空
if (StringUtils.isBlank(key.toString()) || StringUtils.isBlank(value.toString())) {
return;
}
CacheClient.set(key, value);
}这是方法 ① 和 ② 路径中的一个方法,这段代码看起来人畜无害,问题发生在判空逻辑上(历史代码,不讨论其合理性)。当 value 是一个非常大集合或数组时,toString 会消耗掉很多时间。同时,toString 也会生成一个大字符串,无形中消耗了内存资源。这里看似不起眼的一句代码,实际上却是性能黑洞。这也提醒我们,在操作大批量数据时,要注意时空消耗。
最后,我们再来看一下方法 ② 和 ③ 之间的间隔问题,原因已经很明显了,就是 value 序列化过程消耗了大量的时间。另外,序列化好的字节数组也会暂时存在堆内存中,也是会消耗不少内存资源的。
到这里整个分析过程就结束了,通过上面的分析,我们可以看出,一次简单的查询竟然能引出了这么多问题。很多在以前看起来稀疏平常的逻辑,偶然间也会成为性能杀手。日常工作中,还是要经常关注一下应用的性能问题,为应用的稳定运行保驾护航。
5.2 内存消耗测算
由于问题发生时,JVM 只是进行了 FGC,内存并没有溢出,所以没有当时的内存 dump 数据。不过好在问题可以稳定复现,通过对 JVM 进行一些配置,我们可以让 JVM 发生 FGC 前自动对内存进行 dump。这里使用 jinfo 命令对正在运行的 JVM 进程设置参数:
jinfo -flag +HeapDumpBeforeFullGC $JVM_PID拿到内存数据后,接下来用 mat 工具分析一下。首先看一下内存泄露吧:
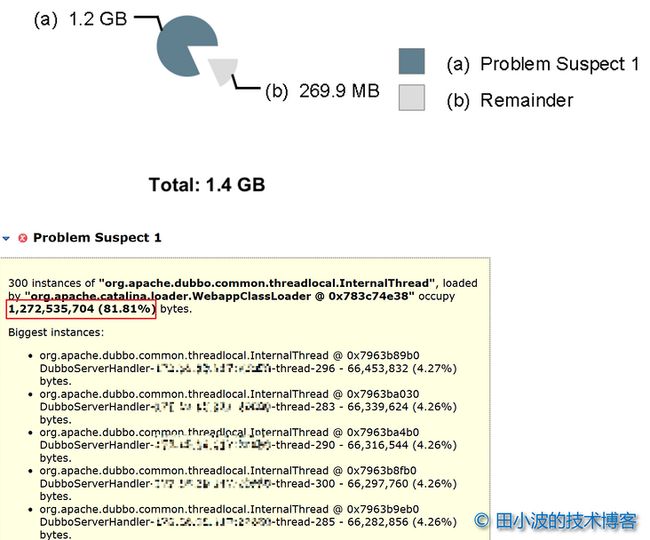
图16:应用内存泄露分析
从内存消耗比例上来看,确实存在一些问题,主要是与 dubbo 的线程有关。随便选一个线程,在支配树(dominator tree)视图中查看线程支配的对象信息:
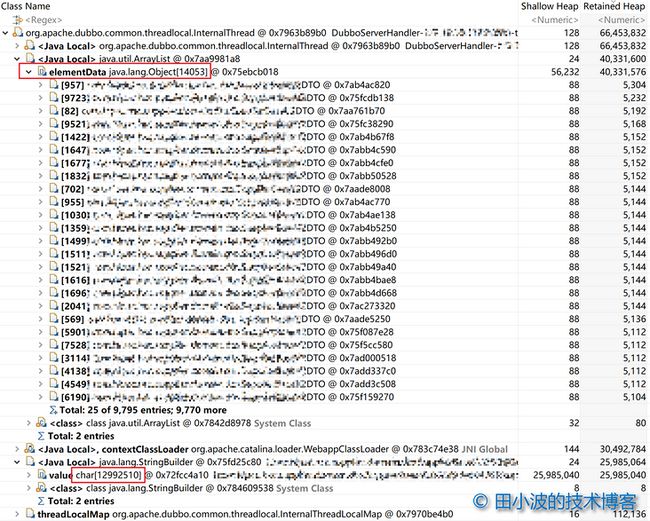
图17:dubbo 线程支配树情况
从上图可以看出,dubbo 线程 retained heap 约为 66 MB,主要由两个大的对象 ArrayList 和 StringBuilder 组成。ArrayList 里面存放的是 DTO,单个 DTO 的 retained heap 大小约为 5.1 KB。StringBuilder 主要是 toString 过程产生的,消耗了接近 26 MB 的内存。从 dump 的内存数据中没找到 DO 列表,应该是在 YGC 时被回收了。
好了,关于内存的分析就到这吧,大概知道内存消耗是怎样的就够了,更深入的分析就不搞了。
6. 总结
由于排查经验较少,这个问题断断续续也花了不少时间。这中间有找不到原因时的郁闷,也有发现一些猜想符合预期时的欣喜。不管怎么样,最后还是找到了问题的原因。在帮助别人的同时,自己也学到了不少东西。总的来说,付出是值得的。本文的最后,对问题排查过程进行简单的总结吧。
一开始,我直接从具体现象开始排查,期望找到引发现象的原因。进行了各种猜想,但是都没法得出合理的结论。接着扩大信息面,仍然无果。之后综合各种信息,思考之后,换个方向排查,找到了原因。最后进行验证,并对一些疑点进行解释,整个过程结束。
最后说说这次排查过程存在的问题吧。第一个问题是没有注意甄别别人反馈过来的信息,没有对信息进行快速确认,而是直接深入了。花了很多时间尝试了各种猜想,最终均无果。由于别人反馈过来的信息通常都是比较零碎片面的,甚至是不正确的。对于这些信息可以快速确认,幸运的话能直接找到原因。但如果发现此路不通,就不要钻牛角尖了,因为这个现象可能只是众多现象中的一个。在这个案例中,接口长 RT 看起来像是 druid 导致的,实际上却是因为 GC 造成 STW 导致的。继续沿着 druid 方向排查,最终一定是南辕北辙。其他的问题都是小问题,就不说了。另外,排查过程中要注意保存当时的一些日志数据,避免因数据过期而丢失,比如阿里云 RDS SQL 洞察是有时间限制的。
本篇文章到此结束,感谢阅读!
本文在知识共享许可协议 4.0 下发布,转载请注明出处
作者:田小波
原创文章优先发布到个人网站,欢迎访问: https://www.tianxiaobo.com