前言
大数据分析最核心的是数据,而数据的发送尤为重要。如何保证数据能够完整、准确、及时地上传到指定的服务端,是所有数据采集 SDK 需要面临的核心问题。神策数据 Web JS SDK 综合考虑数据发送的各项功能,设计并实现了一套适用于前端数据发送的方案。下面针对神策数据 Web JS SDK 数据发送方案进行详细的介绍,希望能够给大家提供一些参考。
数据发送架构解析
简介
Web JS SDK 致力于高效且稳定地采集页面数据,这就需要一个稳定简洁的架构。网页是基于浏览器运行的,浏览器本身并没有多少缓存功能。因此,Web JS SDK 的架构设计中数据默认是即时采集、即时发送的策略。
数据发送架构图
Web JS SDK 数据发送架构如图 2-1 所示: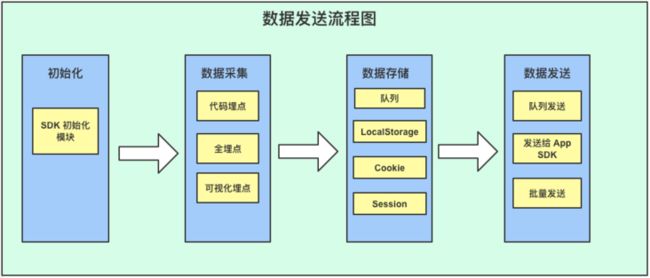
图 2-1 Web JS SDK 数据发送架构图
数据发送流程
Web JS SDK 数据从采集到发送的流程如图 2-2 所示: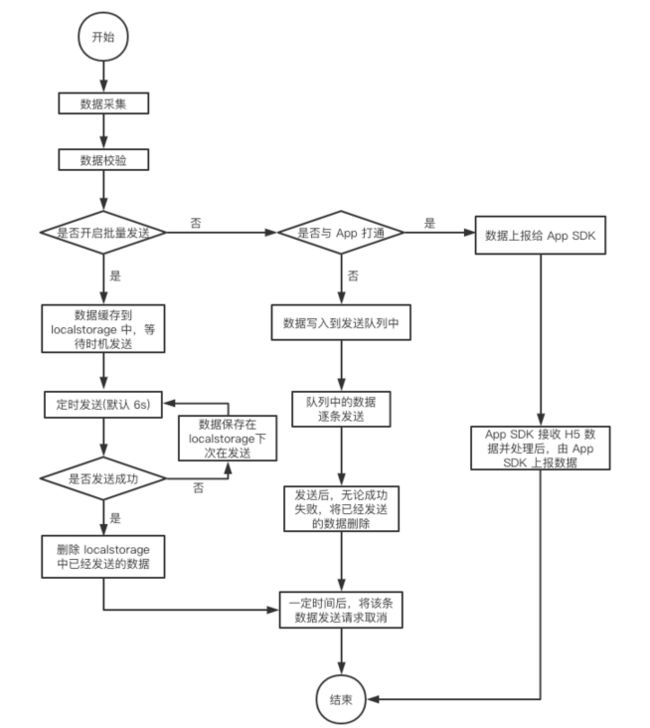
图 2-2 Web JS SDK 数据发送流程图
通过上图可以知道,数据发送流程主要包括下面几个步骤:
1.首先会针对上传的事件以及属性做格式校验;
2.批量发送配置下,将数据缓存到 localstorage,达到发送条件后通过网络发送。发送成功后将已发送的数据删除,发送失败后等待下次发送时机;
3.H5 页面在 App 中打开,可以通过配置项将 H5 采集的数据上报给 App 端的 SDK(Android SDK 或 iOS SDK),数据实时通过 WebView 中间层上报给 App 端,App 端控制数据上报;
4.实时发送配置下,数据会先保存到发送队列中,然后逐条发送,发送完成后(不论成功与否)将已发送的数据删除;
5.无论批量发送还是实时发送,请求时间超过设置的超时时间(实时发送默认为 3 秒,批量发送默认为 6 秒)后,都会取消该请求。
数据发送时间
Web JS SDK 监控到用户产生了行为,就会生成一条数据。为了最大限度地保证数据的准确性和安全性,会要求数据采集 SDK 尽快将数据同步到指定的服务端。因此,如何选择合适的时间是发送数据需要面临的核心问题。
时间戳是指格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒(北京时间 1970 年 01 月 01 日 08 时 00 分 00 秒)起至现在的总秒数。通俗的讲,时间戳能够表示在一个特定时间点已经存在的、完整的、可验证的数据。
物理时间指的就是时间戳;显示时间是指物理时间按照不同的时区,转化成符合各地区的显示时间。例如:我们生活中常见的「北京时间」和「纽约时间」。
客户端时间戳
客户端时间戳会存在被用户修改的风险,从而导致采集的 time 不符合实际情况。针对时间戳的问题,首先想到的应该是同步或者校准客户端时间。但是,同步或者校准不仅需要网络权限,还需要一个稳定的时间服务器。因此,这并不适用于 Web 端。针对这一问题,目前神策采用的是 “时间修正” 策略。
时间修正机制解释如下:发生事件时的时间(time)值为 t1,发送数据时的时间(_flush_time)的值为 t2(客户端时间,且 _flush_time 不入库),服务端接收到数据的时间($recive_time)为 t3(服务端时间)。如果 |t3 - t2| > 60s,则认为客户端的时间不准确,会对事件触发时间进行修正,修正后事件时间 t1‘ = t1 + (t3 - t2) 。
下面以图 3-1 为例介绍 “时间修正” 的过程: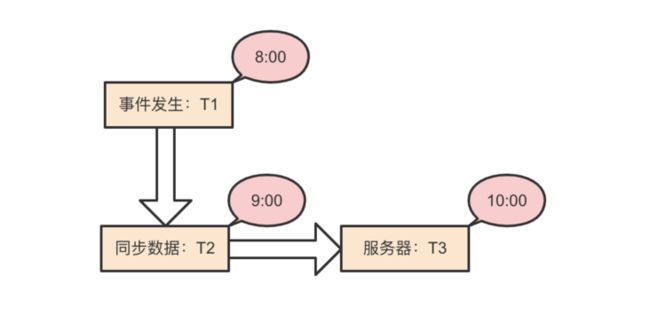
图 3-1 事件时间修正策略
用户在时间戳 T1(8:00)时触发了一个 $pageview(页面浏览事件),然后事件存入本地缓存。数据采集 SDK 在用户客户端时间 T2(9:00) 时开始同步事件数据,然后服务端通过 http(s) 的 Request Header Date 可以获取到数据采集 SDK 发起 Request 时用户客户端时间戳 T2 。如果 T2 与 当前服务端的时间戳 T3 的误差在可接受范围内(60s,因为网络请求需要一定的时间),则说明用户的客户端时间准确,不需要做修正处理。如果 T2 与 T3 的误差较大(大于 60s,这里为 1 小时),则可以确定客户端时间 T2 不准确,比服务端的时间戳晚了 1 小时。因此,服务端在接收到事件的时候会把 $pageview 的时间戳加上 1 小时,变成 9:00,这样就达到了 “时间修正” 的效果。
服务端时间戳
客户端时间戳存在被修改的风险,且需要服务端进行检查修正,那么直接使用服务端的时间戳是否更合适呢?确实可以直接使用服务端时间,不过也会存在一些问题。例如:浏览器端按顺序连续发送的多条数据,服务器接收到的顺序并不一定是事件发生的顺序。为了确保客户端数据发送顺序的准确性,会在下面章节中介绍神策 Web JS SDK 采用的队列发送方式。
数据发送的顺序
Web JS SDK 采集的是网页端的数据,通过网络请求发送到指定的服务端。但是,网络请求是有波动的,导致服务器接收到的顺序并不一定是事件发生的顺序。例如:点击按钮跳转页面,会先发送一个点击事件 A,在跳转到新页面时会发送一个页面浏览事件 B。事实上,经常会出现用户的行为序列中 A 和 B 事件顺序颠倒的问题。直观来看,用户行为会非常不合理:先触发了后一个页面的页面浏览事件,接下来的行为却是前一个页面的某个按钮的点击事件。
为了保证发送的顺序,SDK 在数据发送之前会构建数据发送队列,保证用户行为数据按照正确的顺序入库,形成正确的行为序列。这是如何做到的呢?
SDK 在发送数据队列中的数据时,默认会按照顺序发送:当前一条数据返回发送成功的状态后,依次发送下一条数据,这保证了大部分正常流程的数据发送正确。但是,万一前面的数据发送卡住了,一直没有状态返回怎么办?SDK 的解决方案是设置超时时间:
queue_timeout:队列发送超时时间,默认值 300 毫秒,如果数据发送时间超过 queue_timeout 还未返回结果,会强制发送下一条数据;
callback_timeout:回调函数超时时间,默认值 200 毫秒,如果数据发送时间超过 callback_timeout 还未返回结果,会强制执行回调函数;
datasend_timeout: 数据发送超时时间,默认值 3000 毫秒,如果数据发送时间超过 datasend_timeout 还未返回结果,会强制取消该请求。
队列发送以及超时时间的具体逻辑如图 4-1 所示: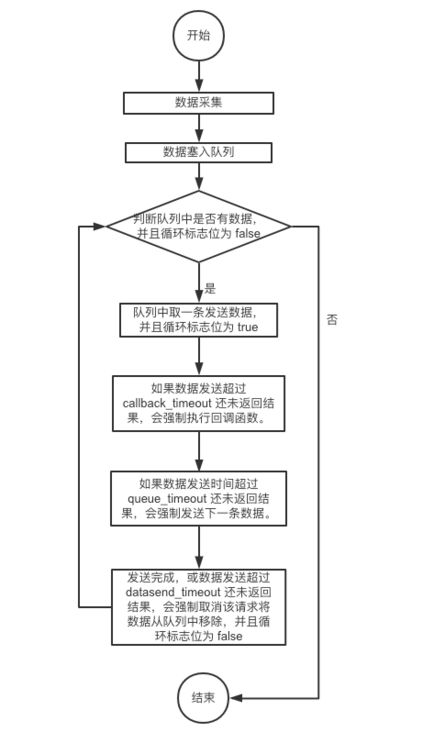
图 4-1 队列发送策略
下面是队列发送的具体实现代码:
_.autoExeQueue = function(){ var queue = { // 简单队列 items : [], enqueue: function(val){ this.items.push(val); this.start(); }, dequeue: function(){ return this.items.shift(); }, getCurrentItem: function(){ return this.items[0]; }, // 自动循环执行队列 isRun: false, start: function(){ if(this.items.length > 0 && !this.isRun){ this.isRun = true; this.getCurrentItem().start(); } }, close: function(){ this.dequeue(); this.isRun = false; this.start(); } }; return queue;};
数据发送方式
实时发送
大部分 Web JS SDK 数据采集使用的是即时采集、即时发送的策略,没有使用本地缓存。这样减少了复杂的缓存、读取和发送的控制流程。确保数据快速、灵活、准确地发往指定的服务端。
常见的数据发送方式有 img 发送、ajax 发送和 beacon 发送,下面对这几种发送方式进行简要的介绍:
img 发送:默认使用 img 发送数据。对于跨域的兼容比较好,发送的形式就是创建一个 img 元素,src 带上所有要发送的数据。执行过程无阻塞,不会影响用户体验。同时,相对于 XMLHttpRequest 对象,发送 GET 请求性能上更好。局限性是 GET 请求所携带的数据大小是有限的;
ajax 发送:常见的一种请求方式,为了不影响业务流程,默认是异步发送数据。跨域时默认不携带请求域名下的 cookie。采用的是 post 形式发送数据,数据较为安全,且发送数据的大小基本不受限制;
beacon 发送:当关闭页面发送数据的时候,经常受到页面容器 destroy 的影响,会导致数据来不及发送,进而产生丢失的问题。sendBeacon 是浏览器的新发送策略,可以避免页面容器 destroy 时数据发送丢失的问题。不过,目前该功能还未普及。
SDK 默认是选择立即发送的 img 方式。也可以通过配置项,修改为 'ajax' 或 'beacon' 方式发送数据。下面从多个角度来分析 img、ajax、sendBeacon 的优缺点,如表 5-1 所示: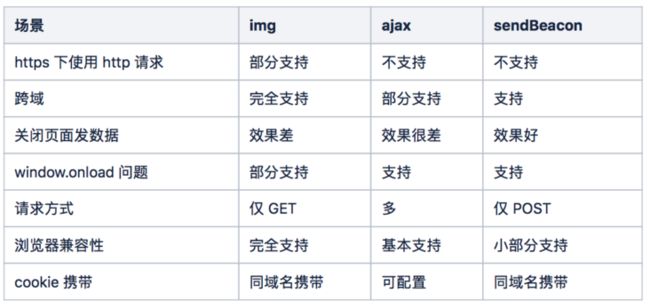
表 5-1 发送方式对比
批量发送
缓存方案
我们无法避免当网络情况不佳时,数据发送失败的问题。数据一旦发送失败,由于没有缓存的逻辑,就会造成数据丢失。一个常见的场景是:关闭页面时,有发送数据的需求。受当时网络环境和页面请求量的影响,发送数据时浏览器已经关闭,导致数据请求存在未发送出去的风险,从而导致丢失数据。基于以上原因 SDK 增加了缓存模式。
早期的浏览器只能通过 cookie 来存储数据,后来逐渐增加了 localStorage、sessionStorage 等存储方式,现代浏览器还包含 IndexedDB 。对比这几种方案的特点,如表 5-2 所示: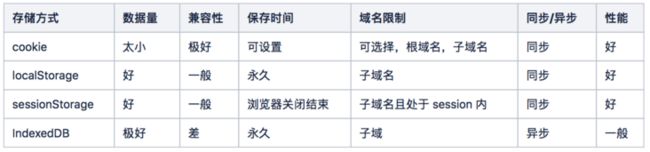
表 5-2 缓存方案对比
cookie:因为存储的数据量不能超过 4K,数据量较小,且 cookie 会被带在 http header 中;
sessionStorage:只可以存储 session 内的数据;
IndexedDB:NoSQL 数据库,本地可以存储 250M 以上的数据。数据量很大,但是性能一般,且操作相对麻烦;
localStorage:可以理解为是一个文件存储,大约存储 5M 的数据(不同浏览器实现不一致),数据量适中。
综合考虑后,针对用户行为这样的数据,localStorage 相对合适。同步的 API 可以确保数据的一致,同时性能好,频繁写入几乎感觉不到延时。
批量发送策略
批量发送方式下,当数据产生后会先将数据存储在 localStorage 中(存储的数据有条数限制,最大能存储 200 条),达到发送条件后才会把存储在 localStorage 中的数据合并发送出去。其中,发送条件包括:
时间间隔:每隔一定时间(默认 6 秒)发送一次数据;
遇到 $pageview(或使用 quick('autoTrack'); 方法)和 $SignUp 也会立即存储并且发送。
上述两个发送条件满足任意一个即可发送数据。批量发送默认使用跨域 ajax 的方式发送数据,且使用客户端系统时间标识数据。如果浏览器不支持跨域 ajax 发送数据,还是默认使用 img 且实时发送数据的方式。
如果数据发送不成功,会将发送的数据保存起来,满足发送条件后,与之后的数据一起尝试发送。这样可以减少网络请求、节省服务器资源,并且有效地降低一些数据发送过程中的丢失问题。
需要注意一下 localstorage 遵循浏览器同源策略,即子域名 localstorage 也不能共享,如表 5-3 所示: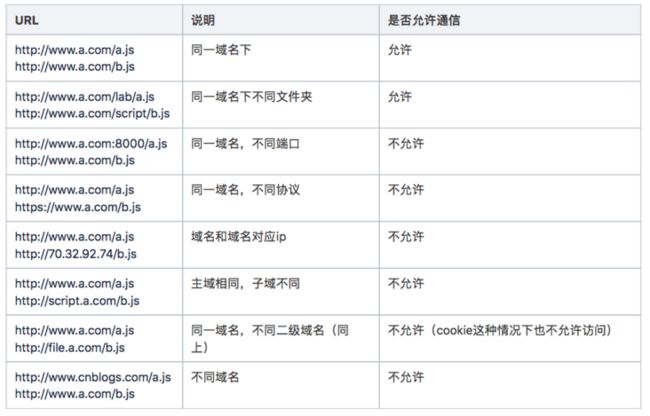
表 5-3 浏览器的同源策略
例如:某个用户最后一条数据是在域名 a.test.com 下,而之后几天浏览的页面都是其他域名(如 b.test.com),这个时候是无法发送 a.test.com 域名下未发送成功的数据的。
H5 和 App 打通
集成了神策 Web JS SDK 的 H5 页面,在嵌入到 App 后,H5 和 App 的数据想要统一,可以将 H5 内的事件通过 App SDK 进行发送,事件发送前会添加上 App 采集到的预置属性。该功能默认是关闭的,如果需要开启,需要在 App 和 H5 端同时进行配置。
这种情况下 Web JS SDK 调用 App 暴露在 window 上的变量,将数据发送给 App,由 App 端二次加工处理后存入本地缓存,在符合特定策略之后再进行数据同步。打通能将两端用户行为序列准确串联,补充 H5 数据设备相关的信息,降低 Web 端数据丢失率等。
关闭页面发数据
对于 web 数据采集来说,关闭或跳转页面时一直存在上报数据丢失的难题。因为浏览器通常会忽略在 unload 事件处理器中产生的请求,包括异步 ajax 和图片等请求。正常情况下,由于设备、浏览器和网络等因素影响,Web JS SDK 数据会存在一定的丢失率(不超过 5%)。在关闭页面的情况下丢失率会增加,尤其在移动网络环境下丢失更严重。相信很多读者都遇到过下面这几个问题:
统计某个链接的点击量,但是这个链接点击后直接跳转了;
统计页面时长问题,unload 的时候发送的统计丢失了;
统计登录成功数量,但是登录成功后页面跳转了。
针对这个问题,下面简单介绍神策 Web JS SDK 常用的几种方式:
服务端发送事件
一些关键的点击,需要十分准确的采集。例如:支付、登录成功等事件是在关闭页面时发送的,建议在服务端中增加埋点采集,前后端一起统计,提高数据准确性。
使用 setTimeout
延迟 500ms 跳转页面,给 SDK 发送数据提供时间。这样可以降低跳转页面发数据的丢失率,但会影响用户体验,并且延迟时间不好估算。代码如下所示:
// 点击链接function targetLinkIcon( url ){ //延迟跳转页面 setTimeout(function(){ window.location.href = url; },500); //神策自定义事件的方法 sensors.track('demo',{});}
callback 回调中跳转页面
跳转页面的时候,调用 SDK 的 track 方法触发自定义事件,可以在第三个参数(回调函数)中跳转页面。正常情况下数据请求返回后,就会执行 callback 方法,但是考虑到网络卡顿或者死机的情况,设置 callback_timeout(默认值 200ms)的超时来强制执行 callback。
callback_timeout 最好在 500ms 左右。设置的太长(例如 3s),页面可能跳转了还没有执行回调函数。设置的太短(例如 100ms),可能请求还没发成功,就执行 callback 了。如果 callback 里是页面跳转的操作,那上条数据可能会丢失。代码如下所示:
// 点击链接$('a').on('click',function(e,url){ e.preventDefault(); // 阻止默认跳转 sensors.track('a_click', {}, function(){ location.href = url; }); //把跳转操作加在callback里});
trackLink
如果有多个跳转链接需要监控,使用 setTimeout 或者 callback 比较繁琐。SDK 为了简化操作,对代码做了封装,提供了 trackLink 方法,在实际使用时只需要调用 trackLink 就可以了。代码如下所示:
sa.trackLink = function(link, event_name, event_prop){ addEvent(link,'click',function(e){ e.preventDefault(); // 阻止默认跳转 var hasCalled = false; setTimeout(redirectUrl, 1000); //如果没有回调成功,设置超时回调 function redirectUrl(){ if (!hasCalled) { hasCalled = true; location.href = link.href; //把 A 链接的点击跳转,改成 location 的方式跳转 } } sa.track(event_name, event_prop, redirectUrl); //把跳转操作加在callback里 });};
sa.trackLink(document.getElementById('index_detail'),'click_index_detail',{});
sendBeacon
Beacon API 在网页关闭的情况下也可以发送数据,但是兼容性不佳,它有如下特点:
在空闲的时候异步发送数据,并且是 POST 请求,不影响页面 JS、CSS Animation 等执行;
页面在 unload 状态下,也会发送数据,不影响页面的跳转,且不受同域限制;
能够被客户端优化发送,尤其在 Mobile 环境下,可以将 Beacon 请求合并到其他请求上一起处理。
sendBeacon 方法存在兼容性问题,除 IE 以外的大部分浏览器都已经支持,兼容情况如图 6-1 所示: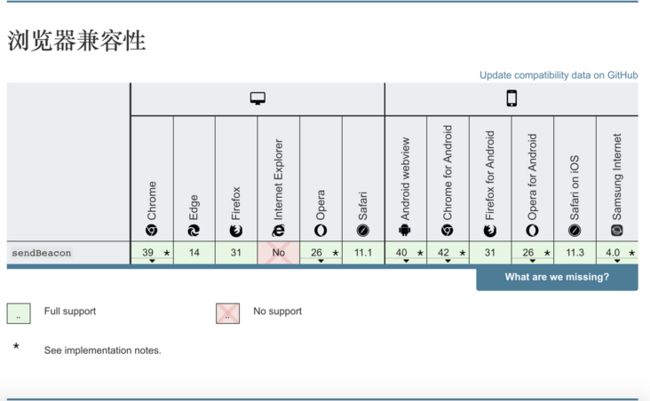
图 6-1 sendBeacon 浏览器兼容性(图片来源于 MDN)
SDK 自动处理好了 sendBeacon 的兼容性问题,在不支持 sendBeacon 情况下还是会默认使用 img 发送数据,代码如下所示:
if (sendType === 'beacon' && typeof navigator.sendBeacon !== "function") { sendType = 'image'; }
如果想了解更多 sendBeacon 相关的内容,可以参考下面链接:
W3标准描述:https://dvcs.w3.org/hg/webper... ;
MDN介绍:https://developer.mozilla.org... 。
批量发送缓存数据
批量发送默认使用跨域 ajax 的方式发送数据,并且使用客户端系统时间标识数据。如果数据发送不成功,会将发送的数据保存起来,满足发送条件后与后续数据一起尝试发送。如果 localStorage 里已经存了超过 200 条数据,会导致批量发送功能失效。localStorage 中只保存这 200 条数据,新产生的数据使用 img 且实时发送数据的方式。当进入同域名的新页面时,会自动检查缓存中是否有数据,如果有会继续发送缓存数据。
总结
本文对于 Web JS SDK 数据发送的实现原理进行了讲解,介绍了 SDK 处理数据发送的时间、顺序、方式以及降低关闭页面时发送数据丢失率的几种方式,如果大家有更好的想法欢迎一起讨论。关于数据采集、数据安全和数据处理等内容会在后续的文章中逐步向大家介绍。
文章来源:神策技术社区