作者:麦乐
来源:恒生LIGHT云社区
一 数据访问
认识作用域链
function add(num1, num2) {
var sum =num1 + num2
return sum
}当add函数创建的时候,它的作用域链中填入了一个单独的可变对象,包含了所有全局作用域可以访问到的变量。
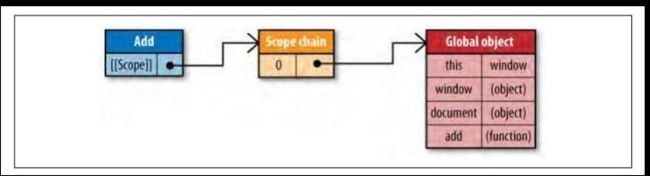
当add函数执行的时候,会创建一个叫做运行期上下文的内部对象。此对象被推入作用域链的顶端。
标识符解析的性能
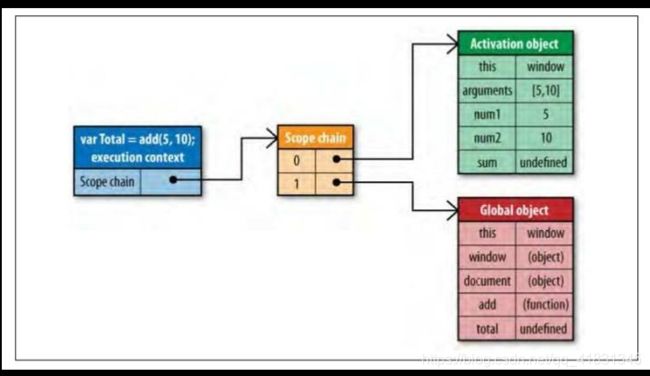
当要访问某个变量时,会从 作用域链的顶端(0)开始查询,如果找到了,就拿来用,如果没有找到,0就会继续沿着作用域链寻找(1)。实时上,查找的过程都会消耗性能的,一个标识符的位置越深,它的读写速度就会越慢。因此,函数中读写局部变量总是最快的,读写全局变量总是最慢的。各个浏览器的测试如下图:
function initUi() {
var bd = document.body,
links = document.getElementByName('a'),
i = 0,
len = links.length;
while(i < len) {
// do something
i++;
}
document.getElementById('btn').onclick = function() {
// do something
}
} 这个函数访问了三次document,而document是一个全局变量,每次访问都必须遍历整个作用域链,直到找到这个变量。可以通过下面得方式减少性能得消耗:
function initUi() {
var doc = document
bd = doc.body,
links = doc.getElementByName('a'),
i = 0,
len = links.length;
while(i < len) {
// do something
i++;
}
doc.getElementById('btn').onclick = function() {
// do something
}
} 改变作用域链
with和try catch 可以改变一个运行期上下文的作用域链。
用with重写下initUi函数:
function initUi() {
with(document) {
var bd = body,
links = getElementByName('a'),
i = 0,
len = links.length;
while(i < len) {
// do something
i++;
}
getElementById('btn').onclick = function() {
// do something
}
}
} 用with也可以避免重复访问一个全局变量的问题,这样看上去更高效,实际上产生了一个性能问题。当运行到with语句时,运行期上下文的作用域链被改变了:
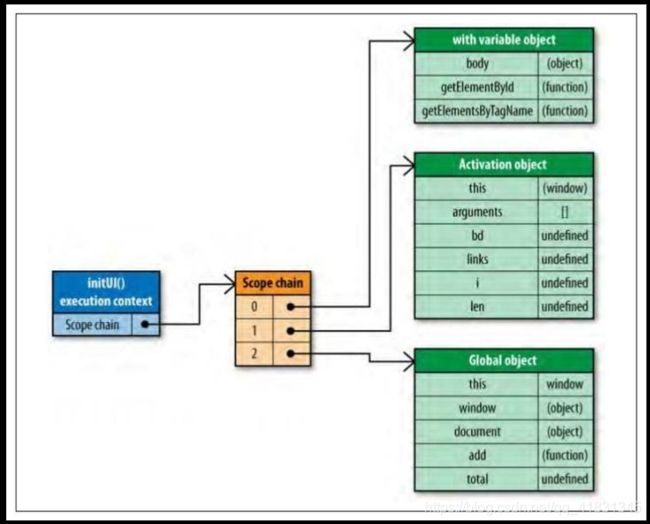
这就意味着所有的局部变量现在都处在第二个作用域链对象中,访问的代价更高了。
try-catch也是一样,当try发生错误,直接跳转到catch执行,然后把异常对象推到作用域链的头部,这个时候try中的所有局部变量都会在第二位。一旦catch执行完毕,作用域链就会回到以前的状态。如果要使用try-catch,尽量不要在catch中去访问局部变量。用下面的方式去处理异常:
try {
// do
} catch (error) {
handleError(error)
}动态作用域
with try-catch eval都被认为是动态作用域。经过优化的JavaScript引擎,尝试通过分析代码来确定哪些变量可以在特定时候被访问。这些引擎试图避开传统作用域链的查找,取代以标识符索引的方式进行快速查找。当涉及到动态作用域时,这种优化方式就失效了。脚本引擎必须切换回较慢的基于哈希表的标识符识别方式,这更像是传统的作用域链查找。
function execute(str) {
eval(str)
console.log(window)
}
execute('var window = {}')闭包,作用域和内存
function assignEvents() {
var id = "12"
document.getElementById('btn').onclick = function() {
saveDocument(id)
}
}上面的函数创建了一个闭包,作用域链和普通函数有些区别:
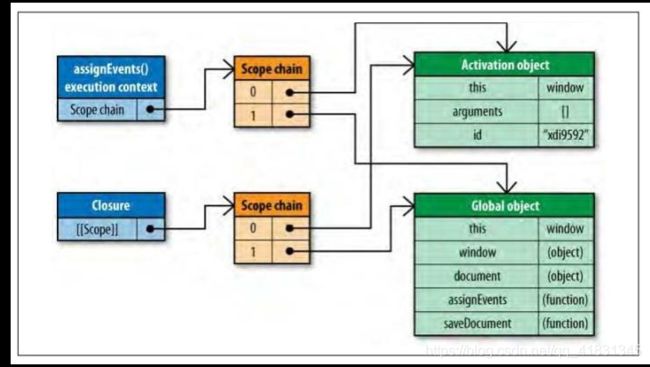
通常来说,函数的执行上下文对象会随着运行期上下文一起销毁,由于闭包的[[scope]]属性引用了执行期上下文对象,所以不会销毁。这就意味着闭包需要更多的内存开销。
当闭包被执行时,一个运行期上下文被创建,它的作用域链与属性[[Scope]]中引用的两个相同的作用域链对象同时被初始化,然后一个活动对象为闭包自身所创建。
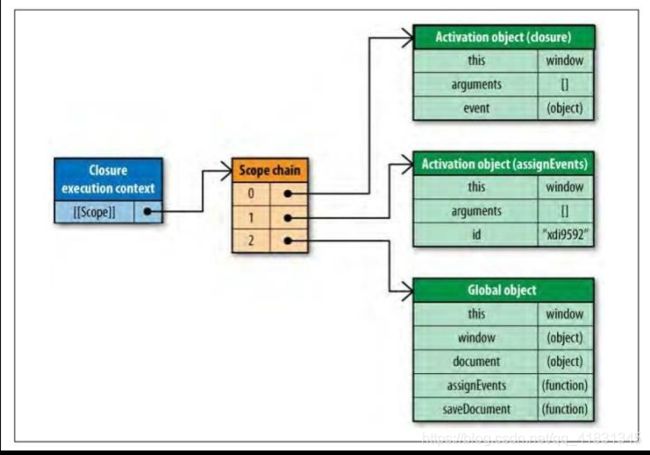
闭包中使用的两个标识符,id和saveDocument,处于作用域链的1和2层级,如果要大量访问跨作用域链的标识符,就会造成很高的性能开销。
使用闭包的时候,也是可以使用把全局变量变为局部变量的方式来减轻影响。
总结
函数中对同一外部变量访问频繁时,尽量把它变为局部变量。
尽量不要使用with, eval。
使用try-catch时,尽量避免对外部变量的访问(包括局部的和全局的)。
谨慎使用闭包,注意标识符的访问深度问题。
二 DOM编程
dom的访问和修改
对dom的访问和修改总是昂贵的,在使用的过程一定要注意。比如下面代码:
function innerHTMLLoop() {
for(var i = 0; i < 15000; i++) {
document.getElementById('here').innerHTML += 'a'
}
}用chrome浏览器来测试下:
console.time()
innerHTMLLoop()
console.timeEnd()
// default: 820.547119140625 ms这段代码的问题在于,每次循环迭代,该元素都被访问两次:一次读取innerHTML属性值,另一次重写它。可优化为:
function innerHTMLLoop() {
var count = ''
for(var i = 0; i < 15000; i++) {
count += 'a'
}
document.getElementById('here').innerHTML += count;
}console.time()
innerHTMLLoop()
console.timeEnd()
// default: 1.85595703125 ms执行时间由800ms左右提升到了2ms左右。
昂贵的元素集合
这段代码看上去只是简单地把页面中div元素数量翻倍。它遍历现有的div元素,每次创建一个新的 div 并添加到 body 中。但事实上这是一个死循环,因为循环的退出条件allDivs.length在每次迭代时都会增加,它反映出的是底层文档的当前状态。
var allDivs = document.getElementsByTagName('div')
for(var i = 0; i < allDivs.length; i ++) {
document.body.appendChild(document.createElement('div'))
}在循环的条件控制语句中读取数组的length属性是不推荐的做法。读取一个集合的length比读取普通数组的length要慢很多,因为每次都要重新查询。使用集合时要记得把集合转化为数组,或者避免在循环体内频繁的取集合的length.
function toArray(coll) {
return Array.prototype.slice.call(coll)
}
var allDivs = document.getElementsByTagName('div')
var len = allDivs.length
for(var i = 0; i < len; i ++) {
document.body.appendChild(document.createElement('div'))
}查找DOM节点
使用children替代childNodes会更快,因为集合项更少。HTML源码中的空白实际上是文本节点,而且它并不包含在children集合中。

css选择器
尽量使用querySelectorAll
最新的浏览器也提供了一个名为querySelectorAll()的原生DOM方法。这种方式自然比使用JavaScript和DOM来遍历查找元素要快很多。
var elements=document.querySelectorAll('#menu a');返回值是一个类数组,但不是一个HTML集合。返回值类似一个静态列表,多次取length不会引起重复计算。
var allDivs = document.getElementsByTagName('div')
console.log(allDivs)
var qDivs = document.querySelectorAll('#here')
console.log(qDivs)![]()
如果需要处理大量组合查询,使用 querySelectorAll()的话会更有效率。比如,页面中有一些class为“warning”的div元素和另一些class为“notice”的元素,如果要同时得到它们的列表,建议使用querySelectorAll():
var errs=document.querySelectorAll('div.warning,div.notice');最小化重绘和重排
方法一,合并修改样式
下面代码会触发三次重排和重绘。

优化后只触发一次:
var el=document.getElementById('mydiv');
el.style.cssText='border-left: 1px; border-right: 2px; padding: 5px;';方法二,使DOM脱离文档流
1 隐藏元素,修改后,重新显示
把下面数据添加到ul中
var data = [
{
url: 'http://www.csdn.com',
text: '博客'
},
{
url: 'http://www.csdn.com',
text: '博客'
}
] 用下面的常规方式更新列表是相当损耗性能的,因为每次循环都会引起一次重排。
function appDataToEl(ul, data) {
var doc = document;
for(let i = 0; i < data.length; i++) {
var liE = doc.createElement('li')
var aE = doc.createElement('a')
aE.innerHTML = data[i].text;
aE.href = data[i].url
liE.appendChild(aE)
ul.appendChild(liE)
}
}
appDataToEl(document.getElementById('uls'), data)优化如下:
var ul = document.getElementById('uls')
ul.style.display = 'none'
appDataToEl(ul, data)
ul.style.display = 'block'2 利用文档片段
var ul = document.getElementById('uls')
var frame = document.createDocumentFragment()
appDataToEl(frame, data)
ul.appendChild(frame)3 需要修改的节点创建一个备份,然后对副本进行操作,一旦操作完成,就用新的节点替代旧的节点。
var old = document.getElementById('uls')
var clone = old.cloneNode(true)
appDataToEl(clone, data)
old.parentNode.replaceChild(clone, old)推荐尽可能地使用文档片断(第二个方案),因为它们所产生的DOM遍历和重排次数最少。
方法三 让动画脱离文档流
页面顶部的一个动画推移页面整个余下的部分时,会导致一次代价昂贵的大规模重排,让用户感到页面一顿一顿的。渲染树中需要重新计算的节点越多,情况就会越糟。
1.使用绝对位置定位页面上的动画元素,将其脱离文档流。
2.让元素动起来。当它扩大时,会临时覆盖部分页面。但这只是页面一个小区域的重绘过程,不会产生重排并重绘页面的大部分内容。
3.当动画结束时恢复定位,从而只会下移一次文档的其他元素。
方法四 事件委托
当页面中存在大量元素,而且每一个都要一次或多次绑定事件处理器(比如onclick)时,这种情况可能会影响性能。一个简单而优雅的处理 DOM 事件的技术是事件委托。它是基于这样一个事实:事件逐层冒泡并能被父级元素捕获。使用事件代理,只需给外层元素绑定一个处理器,就可以处理在其子元素上触发的所有事件。
三 算法
循环
for,do while,while,for in,四种循环速度只有for in 速度比较慢,因为它不仅查找对象本身,还还会查找对象的原型,避免使用for in来循环数组。
倒序循环提升性能
for(var i = arr.length; i--;) {
console.log(arr[i])
}
var i = arr.length
while(i--) {
console.log(arr[i])
}
var i = arr.length
do {
console.log(arr[--i])
} while(i)1.一次控制条件中的比较(i==true)
2.一次减法操作(i--)
3.一次数组查找(items[i])
4.一次函数调用(console.log(items[i]))
新的循环代码每次迭代中减少了两次操作,随着迭代次数增加,性能的提升会更趋明显。
优化 if else
if else 对比 switch
二者速度上差别不大,判断条件较多的话,switch易读性更好一些。
优化if-else的目标是:最小化到达正确分支前所需判断的条件数量。最简单的优化方法是确保最可能出现的条件放在首位。考虑如下代码:
var value = 4;
if(value <= 5) {
} else if (value > 5 & value < 10) {
} else {
}如果value小于等于5的概率比较大,就可以把小于5的条件放在最前面,否则,选择相对概率比较大的防止在最前面。
另一种减少条件判断次数的方法是把if-else组织成一系列嵌套的if-else语句。使用单个庞大的if-else通常会导致运行缓慢,因为每个条件都需要判断。例如:
var value = 9;
if(value === 1) {
} else if(value === 2) {
} else if(value === 3) {
} else if(value === 4) {
} else if(value === 5) {
} else if(value === 6) {
} else if(value === 7) {
} else if(value === 8) {
} else if(value === 9) {
} else {
}在这个if-else表达式中,条件语句最多要判断10次。假设value的值在0到10之间均匀分布,那么这会增加平均运行时间。为了最小化条件判断的次数,代码可重写为一系列嵌套的if-else语句,比如:
var value = 9;
if(value <= 5) {
if(value === 1) {
} else if(value === 2) {
} else if(value === 3) {
} else if(value === 4) {
} else {}
} else {
if(value === 6) {
} else if(value === 7) {
} else if(value === 8) {
} else if(value === 9) {
} else {
}
}避免使用if else 和switch
var value = 3
var resultArr = [1,2,3,4,5,6,7,8,9,10]
var result = resultArr[value]用对象或者数组代替if else既能增加移读性,也可以提高性能。
总结:
● for、while和do-while循环性能特性相似,所以没有一种循环类型明显快于或慢于其他类型。
● 避免使用for-in循环,除非你需要遍历一个属性数量未知的对象。
● 改善循环性能的最佳方式是减少每次迭代的运算量和减少循环迭代次数。
● 通常来说,switch总是比if-else快,但并不总是最佳解决方案。
● 在判断条件较多时,使用查找表比if-else和switch更快。
● 浏览器的调用栈大小限制了递归算法在JavaScript中的应用;栈溢出错误会导致其他代码中断运行。
● 如果你遇到栈溢出错误,可将方法改为迭代算法,或使用Memoization来避免重复计算。
运行的代码数量越大,使用这些策略所带来的性能提升也就越明显。
四 字符串和正则表达式
字符串链接

+="one"+"two";
此代码运行时,会经历四个步骤:
1.在内存中创建一个临时字符串
2.连接后的字符串“onetwo”被赋值给该临时字符串
3.临时字符串与str当前的值连接
4.结果赋值给str
书中介绍,上面这种合并字符串的方式相比于str = str +"one"+"two";会慢一些,本人在chrome浏览器中进行了测试发现:
function testStr() {
var str = ''
for(var i = 0; i < 200000; i++) {
str += "one" + 'two'
}
}
function testStr1() {
var str = ''
for(var i = 0; i < 200000; i++) {
str = str + "one" + 'two'
}
}
console.time()
testStr()
console.timeEnd()
// default: 14.6337890625 ms
console.time()
testStr1()
console.timeEnd()
// default: 26.135009765625 ms结果是相反的,估计是现代浏览器对拼接方法进行了优化。
在FireFox浏览器中,时间相差不大。
IE浏览器中,也是第一个比下面的稍微快一点。
对比第一种,用数组的方法拼接字符串,优化不是很明显,但在Ie浏览器中,数组方法比较消耗时间。
function arrToStr() {
var str = '', arr = []
for(var i = 0; i < 200000; i++) {
arr.push("one" + 'two')
}
str += arr.join('')
}str的contact方法稍微慢一些。
正则表达式优化
正则表达式优化的要点是理解它的工作原理,理解回溯。回溯会产生昂贵的计算消耗,一不小心会导致回溯失控。
回溯法概念
基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发 所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从 另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、 不断“回溯”寻找解的方法,就称作“回溯法”。
引起回溯的场景
- 贪婪量词
没有回溯的情况
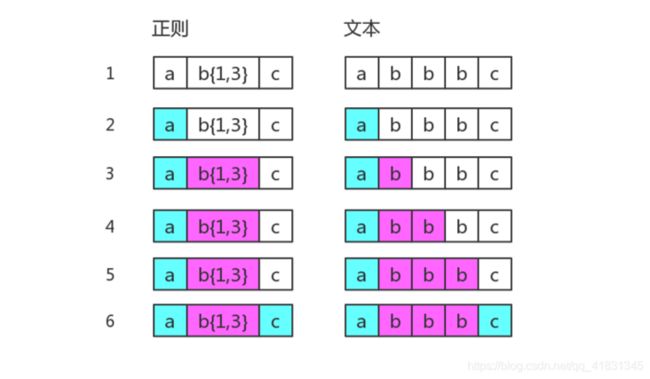
假设我们的正则是 /ab{1,3}c/,而当目标字符串是 "abbbc" 时,就没有所谓的“回溯”。其匹配过程是:
有回溯的情况
如果目标字符串是"abbc",中间就有回溯。
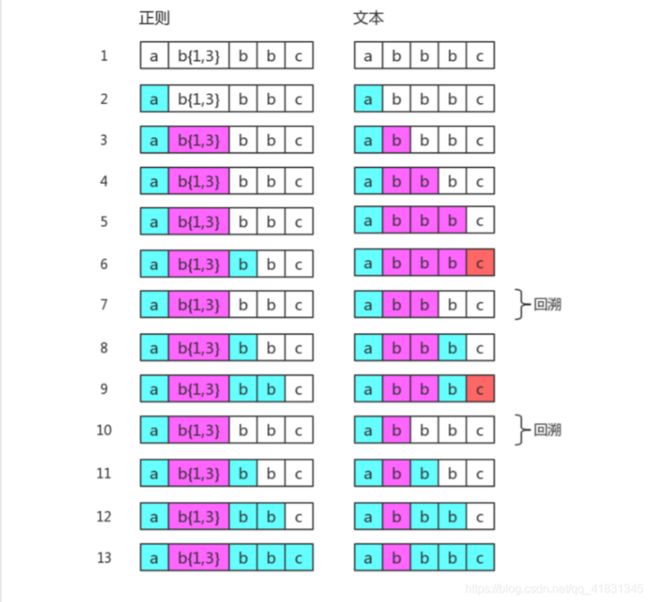
其中第 7 步和第 10 步是回溯。第 7 步与第 4 步一样,此时 b{1,3} 匹配了两个 "b",而第 10 步与 第 3 步一样,此时 b{1,3} 只匹配了一个 "b",这也是 b{1,3} 的最终匹配果。
惰性量词
var string = "12345";
var regex = /(\d{1,3}?)(\d{1,3})/;
console.log( string.match(regex) );
// => ["1234", "1", "234", index: 0, input: "12345"]目标字符串是 "12345",匹配过程是:
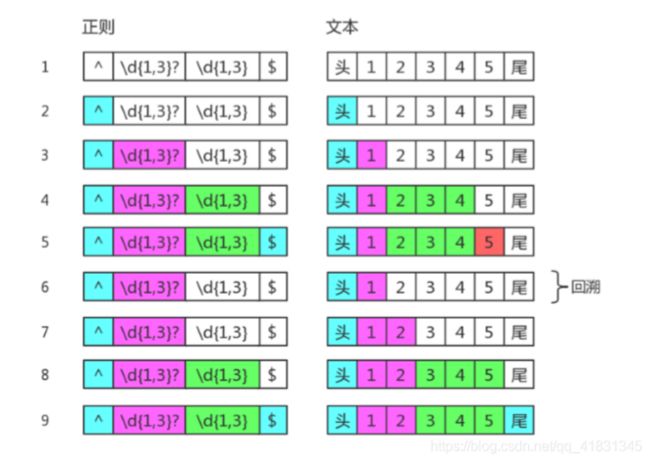
知道你不贪、很知足,但是为了整体匹配成,没办法,也只能给你多塞点了。因此最后 \d{1,3}? 匹配的字 符是 "12",是两个数字,而不是一个。
分支结构
分支结构也是惰性的,但是也会引起回溯
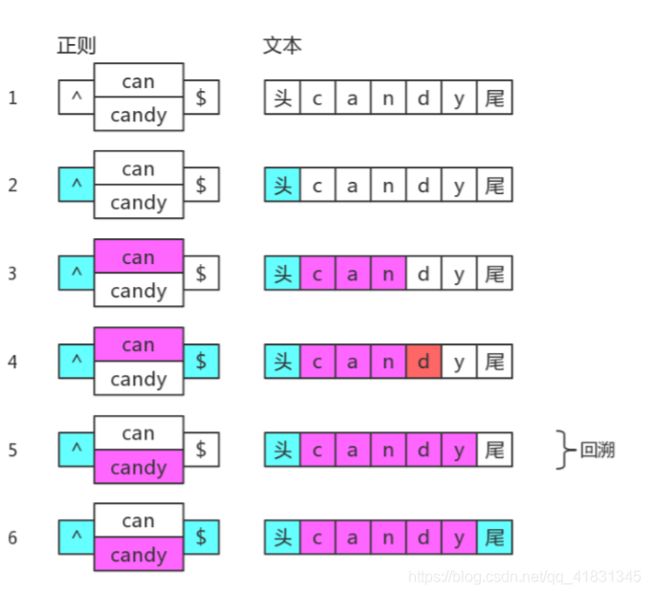
var reg1 = /^can|candy$/g
console.log('candy'.match(reg1)) // [ 'can' ]
var reg = /^(?:can|candy)$/g
console.log('candy'.match(reg)) // [ 'candy' ]上面第二个正则的匹配过程:
总结:
- 贪婪量词“试”的策略是:买衣服砍价。价钱太高了,便宜点,不行,再便宜点。
- 惰性量词“试”的策略是:卖东西加价。给少了,再多给点行不,还有点少啊,再给点。
- 分支结构“试”的策略是:货比三家。这家不行,换一家吧,还不行,再换。
对比贪婪量词和惰性量词的回溯:
惰性量词的匹配次数比贪婪量词的多,亲自在不同的浏览器试过后发现,即使匹配的内容很长,也很难看出二者谁的效率更高。
当正则表达式导致你的浏览器假死数秒、数分钟、甚至更长时间,问题很可能是因为回溯失控。
方案: 有待补充
五 响应速度
浏览器的响应速度是一个很重要的性能关注点,大多数浏览器让一个单一的线程执行javascript代码和用户界面的更新,也就是说如果javascript代码执行时间过长,将会导致用户界面得不到及时的更新,甚至新的任务不会被放入ui队列。
浏览器UI线程
浏览器UI线程做了两件事情,执行javascript和更新用户界面。UI线程的工作基于一个简单的队列系统,任务会被保存到队列中直到进程空闲。一旦空闲,队列中的下一个任务就被重新提取出来并运行。这些任务要么是运行JavaScript代码,要么是执行UI更新,包括重绘和重排(在第三章讨论过)。
Document
点击按钮时,会触发两个任务,一个button按钮样式的改变,一个是点击事件的执行,这两个任务会被放入UI Queue。依次执行,如果遇到新的任务,再放入UI Queue,在UI空闲再接着执行,以图形来表示:
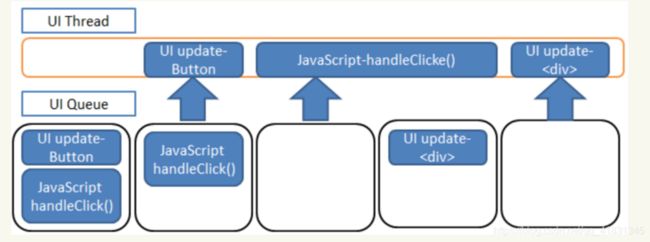
当所有UI线程任务都执行完毕,进程进入空闲状态,并等待更多任务加入队列。空闲状态是理想的,因为用户所有的交互都会立刻触发 UI 更新。如果用户试图在任务运行期间与页面交互,不仅没有即时的 UI 更新,甚至可能新的 UI 更新任务都不会被创建并加入队列。
浏览器很聪明,对JavaScript任务的运行时间做了限制,此类限制分两种:调用桟大小限制(在第4章讨论过)和长时间运行(long-running)脚本限制。
- Chrome没有单独的长运行脚本限制,替代做法是依赖其通用崩溃检测系统来处理此类问题。
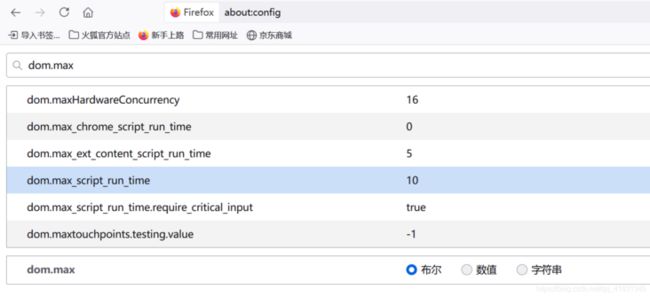
- Firefox 的默认限制为 10 秒;该限制记录在浏览器配置设置中(通过在地址栏输入about:config 访问),键名为 dom.max_script_run_time。支持修改
![]()
- Opera没有长运行脚本限制
- Safari 的默认限制为 5 秒;该限制无法更改,但是你可以通过 Develop 菜单选择Disable Runaway JavaScript Timer 来禁用定时器。
浏览器给出了限制时间,但是并不意味着你可以让代码执行这么久,事实证明,哪怕是1s种对脚本运行而言也太久了。单个JavaScript运行的时间不能超过100ms。
分割任务
当遇到长时间执行的JavaScript代码时,应该怎么做优化呢?由于JavaScript的执行阻碍了UI的渲染,我们主要让长时间执行代码在执行的过程中让出时间给UI渲染,是不是就可以解决问题了呢?
下面这段代码就是告诉浏览器等待2s以后向UI队列插入一个执行greeting函数的任务
function greeting() {
alert(2)
}
setTimeout(greeting, 2000)可以使用延时器来处理长数组:
const arr = [];
for(let i = 0; i < 10000; i ++) {
arr.push(i)
}
function handleArr(item) {
// ...
console.log(item)
}
function processArray(arr, process,callback) {
const _arr = arr.concat();
function test() {
process(_arr.shift())
if(_arr.length > 0) {
setTimeout(test, 25)
} else {
callback()
}
}
setTimeout(test, 25)
}
processArray(arr,handleArr, () => {
console.log('processArray')
})也可以使用这种方式来分割不同的任务:
function openDocument() {
// ...
}
function addText() {
// ...
}
function closeDocument() {
// ...
}
function saveDocument(id) {
const arr = [openDocument, addText, closeDocument]
function test() {
const process = arr.shift();
typeof process === 'function' && process.call(this, id)
if(arr.length) {
setTimeout(test, 25)
}
}
setTimeout(test, 25)
}封装为通用的函数:
function multistep(arr, args, callback) {
if(!Array.isArray(arr)) {
console.error('第一个参数为数组');
return
}
const _arr = arr.concat();
function excu() {
const process = _arr.shift();
typeof process === 'function' && process.call(null, args)
if(_arr.length) {
setTimeout(excu, 25)
} else {
typeof callback === 'function' && callback()
}
}
setTimeout(excu, 25)
}但是上面的方法还存在一些问题,每次只会执行数组的一个函数,而有些函数的执行时间或许不长,如果遇到这样的函数,可以允许执行数组的多个任务函数,这样就能更高效的去执行任务:
const arr = [openDocument, addText, closeDocument]
function multistep(arr, args, callback) {
if(!Array.isArray(arr)) {
console.error('第一个参数为数组');
return
}
const _arr = arr.concat();
let timer;
function excu() {
const preDate = new Date();
do {
const process = _arr.shift();
typeof process === 'function' && process.call(null, args);
console.log(3)
} while( _arr.length && new Date() - preDate < 50);
if(_arr.length) {
timer = setTimeout(excu, 25)
} else {
typeof callback === 'function' && callback()
}
}
timer = setTimeout(excu, 25)
}
multistep(arr, 8, () => {
console.log('h')
})在Firefox 3 中,如果 process()是个空函数,处理1 000项的数组需要38~43毫秒;原始的函数处理相同数组需要超过25 000毫秒。这就是定时任务的作用,能避免把任务分解成过于零碎的片断。代码中使用了的定时器序列,防止创建太多的定时器影响性能。
Worker
考虑这样一个例子:解析一个很大的 JSON 字符串(JSON 解析将会在第7章讨论)。假设数据量足够大,至少需要 500 毫秒才能完成解析。很明显时间太长了,超出了客户端允许JavaScript运行的时间,因为它会干扰用户体验。而此任务难以分解成若干个使用定时器的小任务,因此 Worker 成为最理想的解决方案。下面的代码描绘了它在网页中的使用:
worker.html
Document
live-srver
core.js
self.onmessage = function(event) {
jsonObj(event.data)
self.postMessage(event.data)
}
function jsonObj(obj) {
// ...
}浏览器一般不容许在本地使用Worker,可以使用live-server快速启动一个本地服务器来测试。也可以在vscode中安装一个live server 插件。
Worker运行环境由以下部分组成:
● 一个 navigator 对象,只包括四个属性:appName、appVersion、user Agent 和 platform
● 一个 location 对象(与 window.location 相同,不过所有属性都是只读的)
● 一个 self 对象,指向全局 worker 对象
● 一个 importScripts()方法,用来加载 Worker 所用到的外部 JavaScript 文件
● 所有的 ECMAScript 对象,诸如:Object、Array、Date等
● XMLHttpRequest构造器
● setTimeout()和setInterval()方法
● 一个close()方法,它能立刻停止Worker运
Worker 通过 importScripts()方法加载外部 JavaScript 文件
importScripts('file1.js', 'file2.js')
self.onmessage = function(event) {
jsonObj(event.data)
self.postMessage(event.data)
}
function jsonObj(obj) {
// ...
}使用场景:
解析一个大字符串只是许多受益于Web Workers的任务之一。其他可能受益的任务如下:
● 编码/解码大字符串
const num1 = 3;
const num2 = 4;
var res0 = eval("num1 + num2");
console.log(res0) // 7
var res = new Function('arg1', 'arg2', "return arg1 + arg2");
console.log(res(num1, num2)) // 7
var res1;
setTimeout("res1 = num1 + num2", 100) // setInterval
console.log(res1) // 7
},100)
● 大数组排序
任何超过 100 毫秒的处理过程,都应当考虑 Worker 方案是不是比基于定时器的方案更为合适。当然,前提是浏览器支持 Web Workers。
六 编程实践
避免双重求值
JavaScript 像其他很多脚本语言一样,允许你在程序中提取一个包含代码的字符串,然后动态执行它。有四种标准方法可以实现:eval()、Function()构造函数、setTimeout()和setInterval()。其中每个方法都允许你传入一个 JavaScript 代码字符串并执行它。来看几个例子:
使用Object/Array直接量
从技术上看,第二种方式没有什么问题,但是从运行速度上看,第一种要快些,数组也是如此。
// 较快
var myObject = {
name: "maile",
count: 2,
age: 15,
parent: 2
}
// 较慢
var otherObject = new Object()
otherObject.name = "maile";
otherObject.count = '1';
otherObject.age = '15';
otherObject.parent = '2';延迟加载
乍一看这些函数似乎已经过充分优化。隐藏的性能问题在于每次函数调用时都做了重复工作,因为每次的检查过程都相同:看看指定方法是否存在。如果你假定 target唯一的值就是 DOM 对象,而且用户不可能在页面加载完后奇迹般地改变浏览器,那么这次检查就是重复的。
function addHandle(target, type, fun) {
if(target.addEventListener) {
target.addEventListener(type, fun)
} else {
target.attachEvent("on" + type, fun)
}
}可以优化为:
function addHandle(target, type, fun) {
if(target.addEventListener) {
addHandle = function(target, type, fun){
target.addEventListener(type, fun)
}
} else {
addHandle = function(target, type, fun) {
target.attachEvent("on" + type, fun)
}
}
addHandle(target, type, fun)
}
function removeHandle(target, type, fun) {
if(target.removeEventListener) {
removeHandle = function(target, type, fun){
target.removeEventListener(type, fun)
}
} else {
removeHandle = function(target, type, fun){
target.detachEvent(type, fun)
}
}
removeHandle(target, type, fun)
}位操作
Bitwise AND按位与 &
两个操作数的对应位都是1时,则在该位返回1。
const num1 = 25
const num2 = 4;
console.log(num1.toString(2)) // 11001 二级制
console.log(num2.toString(2)) // 100 二进制
const res1 = num1 | num2
console.log(res1.toString(2)) // 11101 二进制
console.log(res1) // 29Bitwise OR 按位或 |
两个操作数的对应位只要一个为1时,则在该位返回1。
const num1 = 25
const num2 = 4;
console.log(num1.toString(2)) // 11001 二级制
console.log(num2.toString(2)) // 100 二进制
const res1 = num1 | num2
console.log(res1.toString(2)) // 11101 二进制
console.log(res1) // 29Bitwise XOR 按位异或 ^
两个操作数的对应位只有一个为1,则在该位返回1,如果两个都为1舍弃该位
const num1 = 56
const num2 = 34;
console.log(num1.toString(2)) // 111000 二级制
console.log(num2.toString(2)) // 100010 二进制
const res1 = num1 ^ num2
console.log(res1.toString(2)) // 11010 二进制
console.log(res1) // 26const num1 = 43
const num2 = 45;
console.log(num1.toString(2)) // 101011 二级制
console.log(num2.toString(2)) // 101101 二进制
const res1 = num1 ^ num2
console.log(res1.toString(2)) // 110 二进制
console.log(res1) // 6const num1 = 43
const num2 = 45;
console.log(num1.toString(2)) // 101011 二级制
console.log(num2.toString(2)) // 101101 二进制
const res1 = num1 ^ num2
console.log(res1.toString(2)) // 110 二进制
console.log(res1) // 6Bitwise NOT 按位取反 ~
遇 0 则返回1,反之亦然。
const num1 = 43
console.log(num1.toString(2)) // 101011 二级制
const res1 = ~num1
console.log(res1.toString(2)) // -101100 二进制
console.log(res1) // -44偶数的最低位是 0,奇数的最低位是 1。 可以用来区分奇数个偶数。
const arr = [3,67,5,2,4,7,53,1,34,5]
const evenArr=[];
const oddArr = []
arr.forEach((item) => {
item & 1 ? oddArr.push(item) : evenArr.push(item)
})
console.log(oddArr, evenArr)第二种使用位运算的技术称作“位掩码”
在开发过程中,有些时候我们要定义很多种状态标,举一个经典的权限操作的例子,假设这里有四种权限状态如下:
public class Permission {
// 是否允许查询
private boolean allowSelect;
// 是否允许新增
private boolean allowInsert;
// 是否允许删除
private boolean allowDelete;
// 是否允许更新
private boolean allowUpdate;
}我们的目的是判断当前用户是否拥有某种权限,如果单个判断好说,也就四种。但如果混合这来呢,就是2的4次方,共有16种,这就繁琐了。那如果有更多权限呢?组合起来复杂度也就成倍往上升了。
换二进制来表示,二进制结果中每一位的0或1都代表当前所在位的权限关闭和开启,四种权限有16种组合方式 ,这16种组合方式就都是通过位运算得来的,其中参与位运算的每个因子你都可以叫做掩码(MASK)
const ALLOW_SELECT = 1 << 0, // 1 0001 是否允许查询,二进制第1位,0表示否,1表示是
ALLOW_INSERT = 1 << 1, // 2 0010 是否允许新增,二进制第2位,0表示否,1表示是
ALLOW_UPDATE = 1 << 2, // 4 0100 是否允许修改,二进制第3位,0表示否,1表示是
ALLOW_DELETE = 1 << 3, // 8 1000 是否允许修改,二进制第3位,0表示否,1表示是
ALLOW_UPDATE_DELETE_MASK = 12, // 1100 允许修改和删除
AllOW_ALL_MASK = 15 // 允许所有
class Premission {
constructor() {
this.flag = null;
}
setPremission(premission) {
this.flag = premission
}
// 启用某些权限
enable(premission) {
this.flag = this.flag | premission
}
// 删除某些权限
disable(premission) {
this.flag = this.flag & (~premission)
}
// 是否有某些权限
isAllow(premission) {
return (this.flag & premission) == premission
}
// 是否仅仅拥有某些权限
isOnlyAllow(premission) {
return this.flag == premission
}
// 是否禁用某些权限
isNotAllow(premission) {
return (this.flag & premission) == 0
}
}
new Premission()像这样的位掩码运算速度非常快,原因正如前面提到的,计算操作发生在系统底层。如果有许多选项保存在一起并频繁检查,位掩码有助于提高整体性能。
使用这些方法比使用同样功能的 JavaScript 代码更快。当你需要运行复杂数学运算时,应先查看 Math 对象。