背景
机器学习工作负载与传统的工作负载相比,一个比较显著的特点是对 GPU 的需求旺盛。在之前的文章中介绍过(https://mp.weixin.qq.com/s/Na... 和 https://mp.weixin.qq.com/s/X4...),目前 GPU 的显存已经不足以跟上模型参数规模的发展。随着 Transformer 等新的模型结构的出现,这一问题越来越显著。算法工程师们训练模型所需要的资源越来越多,分布式训练也随之成为了工业界进行模型训练的标准方式。
弹性训练能够在训练过程中动态地调整参与训练的实例数量,极大程度提高集群资源的利用率。同时,配合云上的竞价实例等资源类型,能够以更低的成本进行模型调优,进一步降本增效。在 PyTorch 最新发布的 1.9.0 版本中,其原本分布式训练的方式torch.distributed.launch 即将被废弃,转而推荐用户使用弹性的分布式训练接口 torch.distributed.run。
借此机会,我们对这一新特性进行简单地介绍,并且与 Horovod Elastic 进行简单地对比和分析。最后总结一下使用弹性训练时,需要注意的问题。
PyTorch 1.9.0 之前的设计
PyTorch 是目前最流行的深度学习框架之一,它最让人称道的是易用性。无论是单机训练还是分布式训练,PyTorch 都提供了简洁的 API。
PyTorch 1.9.0 版本之前,分布式训练的方式通常是通过如下的方式进行。
python -m torch.distributed.launch
--nnodes=NODE_SIZE
--nproc_per_node=TRAINERS_PER_NODE
--node_rank=NODE_RANK
--master_port=HOST_PORT
--master_addr=HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)其中 nnodes 是参与训练的节点个数,nproc_per_node 是每个节点上运行的进程数量。node_rank 是当前节点的标识符,master_addr 和 master_port 是 master 监听的地址和端口。torch.distributed.launch 会设置一些环境变量,其中包括 WORLD_SIZE 和 MASTER_PORT、MASTER_ADDR 等。
随后在当前机器上会创建对应进程进行训练,当前机器会有 TRAINERS_PER_NODE 个进程,这些进程组成了一个 local worker group。一共有 NODE_SIZE 个机器参与训练,一共有 NODE_SIZE * TRAINERS_PER_NODE 个进程。如果想要发起一个分布式训练任务,需要在所有的机器上执行相应的命令。
PyTorch 1.9.0 中的新设计
在 PyTorch 1.9 中,torch.distributed.launch 即将被废弃,取而代之的是基于 pytorch/elastic 的 torch.distributed.run。这一新的方式与之前相比有一些使用上的改动,如下所示。
python -m torch.distributed.run
--nnodes=MIN_SIZE:MAX_SIZE
--nproc_per_node=TRAINERS_PER_NODE
--rdzv_id=JOB_ID
--rdzv_backend=c10d
--rdzv_endpoint=HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)它提供了一些新的能力:首先是更好的容错,当 worker 失败后会自动重启继续训练;其次是 RANK 和 WORLD_SIZE 这些字段不再需要手动设置。最后也是最重要的,支持弹性训练,动态地增加或减少参与训练的 worker 数量。在上面的例子中,nnodes 的设置不再是一个固定的值,而是一个区间。训练任务可以容忍在这一区间范围内的 worker 数量变化。
如果要支持弹性能力,训练代码也需要进行一些修改。
def main():
args = parse_args(sys.argv[1:])
state = load_checkpoint(args.checkpoint_path)
initialize(state)
# torch.distributed.run ensure that this will work
# by exporting all the env vars needed to initialize the process group
torch.distributed.init_process_group(backend=args.backend)
for i in range(state.epoch, state.total_num_epochs)
for batch in iter(state.dataset)
train(batch, state.model)
state.epoch += 1
save_checkpoint(state)其中比较明显的变化是,用户需要手动地处理 checkpoint。这是因为当 worker 出现失效时,所有的 worker 都会重启,所以需要 checkpoint 机制来保证重启后训练能够继续下去。这一新的分布式训练方式引入不少新的概念,包括 agent、rendezvous 等。接下来我们自用户能接触到的 torch.distributed.run 开始,介绍这些新的设计。
def run(args):
if args.standalone:
args.rdzv_backend = "c10d"
args.rdzv_endpoint = "localhost:29400"
args.rdzv_id = str(uuid.uuid4())
log.info(
f"\n**************************************\n"
f"Rendezvous info:\n"
f"--rdzv_backend={args.rdzv_backend} "
f"--rdzv_endpoint={args.rdzv_endpoint} "
f"--rdzv_id={args.rdzv_id}\n"
f"**************************************\n"
)
config, cmd, cmd_args = config_from_args(args)
elastic_launch(
config=config,
entrypoint=cmd,
)(*cmd_args)其中主要区分了两个模式,Standalone 模式和分布式模式。Standalone 模式是分布式模式的一种特例,它主要针对单机多 Worker 的方式提供了一些便利的设置,不再需要设置一些多余的参数如 rdzv_backend 和 rdzv_endpoint 等。
两者最后都会通过 elastic_launch 发起真正的训练进程。elastic_launch 会通过 elastic agent 来管理 worker 的生命周期,它的返回是每个 worker 的输出。
class elastic_launch:
...
def __call__(self, *args):
return launch_agent(self._config, self._entrypoint, list(args))
def launch_agent(
config: LaunchConfig,
entrypoint: Union[Callable, str, None],
args: List[Any],
) -> Dict[int, Any]:
...
agent = LocalElasticAgent(
spec=spec, start_method=config.start_method, log_dir=config.log_dir
)
...
result = agent.run()
...
return result.return_valuesElastic Agent 的设计:如何管理多个 worker 进程
elastic agent 是一个独立的进程,负责管理其下的 workers。它起到了类似进程管理系统 supervisor 的作用,会在启动的时候确保每个 worker 的设置正确。由于有关 WORLD_SIZE 和 RANK 的信息不再需要用户提供,elastic agent 会负责处理。
除此之外,worker 的失效也是由 elastic agent 负责捕获处理。可以说 elastic agent 是弹性训练中最核心的抽象概念。
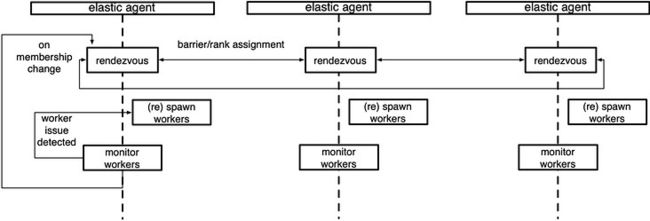
上图展示的是elastic agent 的工作原理。
不同的 elastic agent 之间通过 rendezvous 进行 worker 之间的相互发现和对成员变动的同步。与此同时,通过对 worker 进程的监控,来捕获训练过程中的失效。其中核心的逻辑都包装在 LocalElasticAgent.run() 这一函数调用中。
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
...
result = self._invoke_run(role)
return result
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
...
self._initialize_workers(self._worker_group)
while True:
...
run_result = self._monitor_workers(self._worker_group)
state = run_result.state
...
if state == WorkerState.SUCCEEDED:
...
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
if self._remaining_restarts > 0:
...
self._restart_workers(self._worker_group)
else:
...
return run_result
elif state == WorkerState.HEALTHY:
...
if num_nodes_waiting > 0:
...
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")可以看到,核心的逻辑在 _invoke_run 中。其中 _initialize_workers 执行了大部分初始化的工作,其中包括为每个 worker 分配 RANK 等。在默认的实现中 elastic agent 和 workers 进程在同一机器上,因此 self._monitor_workers(self._worker_group) 通过 multiprocessing 对 workers 的运行状态进行了监控。并且根据不同的状态,进行不同的处理。
elastic agent 的可扩展性非常好,在 1.9.0 版本中,一共有三个 Agent,分别是 ElasticAgent、SimpleElasticAgent 和 LocalElasticAgent。
其中 ElasticAgent 是一个 Abstract Class,SimpleElasticAgent 对其中的某些函数进行了实现,而 LocalElasticAgent 则实现了管理单机上所有 worker 进程的 elastic agent。
SimpleElasticAgent 这一个抽象主要是为了方便扩展新的 agent 实现,比如如果你想通过一个 agent 管理多机上所有的 worker,而不只是本机上的 worker,则可以通过扩展 SimpleElasticAgent 来实现。
rendezvous 的设计:如何在不同的节点间确定 RANK
接下来,我们再看另外一个核心的抽象 rendezvous。为了实现弹性训练,worker 之间要能够动态地进行 membership 的变更。rendezvous 就是实现这一特性的用于同步的组件。
rendezvous 最核心的方法是:
@abstractmethod
def next_rendezvous(
self,
) -> Tuple[Store, int, int]:
"""Main entry-point into the rendezvous barrier.
Blocks until the rendezvous is complete and the current process is
included in the formed worker group, or a timeout occurs, or the
rendezvous was marked closed.
Returns:
A tuple of :py:class:`torch.distributed.Store`, ``rank``, and
``world size``.
Raises:
RendezvousClosedError:
The rendezvous is closed.
RendezvousConnectionError:
The connection to the rendezvous backend has failed.
RendezvousStateError:
The rendezvous state is corrupt.
RendezvousTimeoutError:
The rendezvous did not complete on time.
"""如注释所示,这一函数调用会被阻塞,直到 worker 的数量达到了要求。在 worker 被初始化,或者重启的时候,这一函数都会被调用。当函数返回时,不同的 worker 会以返回中的 rank 作为唯一的标示。rendezvous 一共有四个实现,分别是 etcd、etcd-v2、c10d 和 static。
class EtcdRendezvousHandler(RendezvousHandler):
def next_rendezvous(self):
rdzv_version, rank, world_size = self._rdzv_impl.rendezvous_barrier()
log.info("Creating EtcdStore as the c10d::Store implementation")
store = self._rdzv_impl.setup_kv_store(rdzv_version)
return store, rank, world_size其中 etcd 相关的是之前推荐使用的实现,在 c10d 出现后就不再推荐了。etcd 的实现中,不同 worker 之间的状态通过 etcd 的 KV 接口存储。
确定参与训练的实例和对应的 RANK 的过程如下图所示。
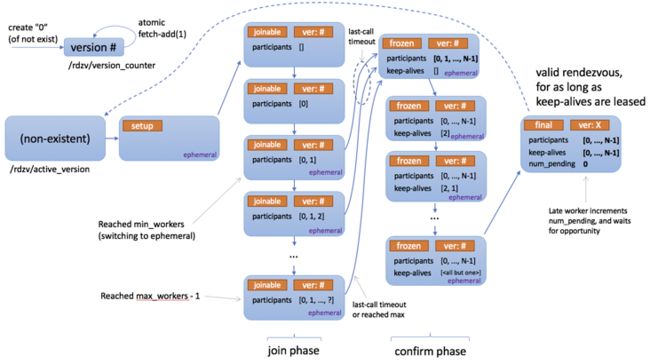
首先会在 /rdzv/active_version 下尝试写一个值 status: setup。在整个过程中,/rdzv/active_version 会作为存储 rendezvous 过程中间状态的 KV store,以及 rendezvous 过程中的排他锁来使用。
如果写失败了,说明目前已经有对应的 rendezvous 过程正在进行中。
在成功后,会更新 /rdzv/version_counter 为原值加一。然后会创建一个目录 /rdzv/v_${version_counter}。这些操作做完后,会将 /rdzv/active_version 的状态写为 joinable,这时就进入了 join 阶段。
在 join 阶段,不同的 agent 在锁的保护下,会依次更新 /rdzv/active_version 下的 paticipants,分配到递增的 rank,这里的 rank 并不是每个 worker 进程分配到的 global rank,而是 agent 自己的 rank。worker 进程的 rank 会根据 agent rank 经过一定的计算得到。这也是一个非常容易混淆的设计,窃以为有优化的空间。
def init_phase(self):
try:
active_version = self.try_create_rendezvous()
state = json.loads(active_version.value)
log.info("New rendezvous state created: " + str(state))
except etcd.EtcdAlreadyExist:
# 已经有了一个新的 rendezvous 过程
active_version, state = self.get_rdzv_state()
# Note: it is possible for above query to fail (etcd.EtcdKeyNotFound),
# but this is ok for us - just means we'll restart from beginning.
log.info("Observed existing rendezvous state: " + str(state))
if state["status"] == "closed":
raise RendezvousClosedError()
if state["status"] == "joinable":
return self.join_phase(state["version"])
if state["status"] == "final":
self.handle_existing_rendezvous(state["version"])
raise EtcdRendezvousRetryImmediately()
self.try_wait_for_state_change(etcd_index=active_version.etcd_index + 1)
raise EtcdRendezvousRetryableFailure()在参与训练的节点达到 nnodes 的命令行参数中传入的最小值时,会等待一定时间,在等待时间结束或者参与训练的节点达到了 nnodes 设定的最大值时,会进入 frozen 阶段。
在 fronzen 阶段中,每个参与训练的节点都需要通过在 /rdzv/v_${version_counter}/rank_${agent_rank} 下写值的方式进行确认。在所有节点都确认完毕后,会进入最后的 final 阶段。
在最后的 final 阶段中,后续进入的 agent 都会 pending,已经达成 rendezvous 的节点上的 agent 会为其管理的 worker 进程分配 RANK。RANK 0 的实例会作为 master 的角色存在。随后就会直接创建对应的 worker 进程。在默认的 LocalElasticAgent 中,会利用 python.multiprocessing 在本地创建多个进程。
@prof
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
spec = worker_group.spec
store = worker_group.store
...
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
...
}
...
args[local_rank] = tuple(worker_args)
...
self._pcontext = start_processes(
name=spec.role,
entrypoint=spec.entrypoint,
args=args,
envs=envs,
log_dir=attempt_log_dir,
start_method=self._start_method,
redirects=spec.redirects,
tee=spec.tee,
)
return self._pcontext.pids()c10d 新的设计
前文介绍了基于 etcd 的 rendezvous 实现,它可以保证多个实例之间对于参与训练的节点共识的强一致,但是这也为 PyTorch 运行训练任务引入了额外的依赖。因此 PyTorch 也提供了一个内置的实现 c10d。相比于基于 etcd 的实现,c10d 基于 TCP 来进行同步。
def create_backend(params: RendezvousParameters) -> Tuple[C10dRendezvousBackend, Store]:
...
if store_type == "file":
store = _create_file_store(params)
elif store_type == "tcp":
store = _create_tcp_store(params)
...
backend = C10dRendezvousBackend(store, params.run_id)
def _create_tcp_store(params: RendezvousParameters) -> TCPStore:
host, port = parse_rendezvous_endpoint(params.endpoint, default_port=29400)
...
for is_server in [is_host, False]:
...
store = TCPStore(
host, port, is_master=is_server, timeout=timedelta(seconds=read_timeout)
)
...
break
return storec10d 是一个 client-server 的架构,其中的一个 agent 上会运行 c10d 的 TCPServer,它监听给定的端口,提供了 compareAndSet、add 等原语。它也可以被理解为一个简化的,提供 KV 接口的内存数据库,类似于 Redis。有关 rendezvous 的同步,都是由各个 agent 通过一个中心化的 agent 上的 c10d TCPServer 完成的。可以预见这样的实现在可用性上相比于 etcd 是有一定差距的,但是胜在易用性。用户如果使用 c10d,那么不再需要运维一个 etcd 集群。
PyTorch Elastic on Kubernetes
为了能够享受到弹性训练带来的便利,PyTorch 同时提供了在 Kubernetes 上的支持。相比于 1.9.0 之前的版本,新版本的分布式训练添加了一些新的参数。因此 PyTorch 社区在 Kubeflow PyTorch operator 的基础上,对 CRD 进行了一些修改。一个典型的弹性训练示例如下所示:
apiVersion: elastic.pytorch.org/v1alpha1
kind: ElasticJob
metadata:
name: imagenet
namespace: elastic-job
spec:
# Use "etcd-service:2379" if you already apply etcd.yaml
rdzvEndpoint: ":"
minReplicas: 1
maxReplicas: 2
replicaSpecs:
Worker:
replicas: 2
restartPolicy: ExitCode
template:
apiVersion: v1
kind: Pod
spec:
containers:
- name: elasticjob-worker
image: torchelastic/examples:0.2.0
imagePullPolicy: Always
args:
- "--nproc_per_node=1"
- "/workspace/examples/imagenet/main.py"
- "--arch=resnet18"
- "--epochs=20"
- "--batch-size=32"
# number of data loader workers (NOT trainers)
# zero means load the data on the same process as the trainer
# this is set so that the container does not OOM since
# pytorch data loaders use shm
- "--workers=0"
- "/workspace/data/tiny-imagenet-200"
resources:
limits:
nvidia.com/gpu: 1 由于在最开始,基于 c10d 的 rendezvous 还没有被支持,所以 CRD 中需要定义 rdzvEndpoint,指向一个已经部署好的 etcd 集群。同时,用户需要指定 minReplicas 和 maxReplicas。其他就与 Kubeflow PyTorchJob 并无二致。
PyTorch Elastic 与 Horovod Elastic
目前,两者的设计从原理上来说并无二致。相比于 Horovod Elastic,PyTorch Elastic 提供了更灵活的扩展性,它提供了 agent、rendezvous 等接口,用户可以根据需要进行扩展。但是从另外一个角度讲,Horovod 的易用性做的更好。
PyTorch 并没有提供保存状态的内置支持,为了能够在 worker 进程失败,重建训练任务的时候,需要用户自己实现保存会加载 checkpoint 的逻辑;而 Horovod 则提供了内置的实现。
Horovod 和 PyTorch 在同步机制上也具有比较大的差异。Horovod Elastic 需要用户提供一个脚本 discovery_hosts.sh,帮助其在运行时获得正在参与训练的节点。
$ horovodrun -np 8 --host-discovery-script discover_hosts.sh python train.py
...
$ ./discover_hosts.sh
host-1:29500
host-2:29500
host-3:29500这相当于将节点发现的逻辑交给用户来实现。反观 PyTorch,它利用 etcd、自身实现的 c10d 等组件解决节点间的相互发现问题,显得更为精巧。
总结
在文章最后,我们总结一下目前实现弹性训练需要注意的问题。
首先,也是最重要的,弹性训练需要一种机制来解决节点/训练进程间相互发现的问题。训练过程中节点会动态地加入或者退出,如何让其他的节点感知到这一变化,是这一机制主要面对的问题。目前的设计中,Horovod 将这一问题交给用户来解决,Horovod 定期执行用户定义的逻辑来发现目前的节点。PyTorch 通过第三方的分布式一致性中间件 etcd 等来实现高可用的节点发现。除此之外,也有一些探索性的工作,利用基于 Gossip 的协议来进行同步,在兼顾高可用的同时也没有引入过多的组件。
其次,要实现弹性训练还需要捕获训练失效。Horovod 和 PyTorch 都通过一个后台进程(Horovod 中是 Driver,PyTorch 中是每个节点的 Local Elastic Agent)来实现这一逻辑。当进程 crash,或在梯度通信中遇到问题时,后台进程会捕获到失效并且重新进行节点发现,然后重启训练。
最后,训练时的数据切分的逻辑和学习率/ batch size 的设置也要对应进行修改。由于参与训练的进程会动态的增减,因此可能需要根据新的训练进程的规模来重新设置学习率和数据分配的逻辑,避免影响模型收敛。
在本文中,我们首先介绍了 PyTorch 1.9.0 版本中弹性训练的设计与实现。然后分析总结了实现弹性训练的方式和不同框架之间的设计差异。从我们的角度来看,弹性训练能够很好地贴合云原生的趋势,以极致的弹性来降低成本提高资源利用率,是未来的趋势。因此目前我们也在积极参与 TensorFlow、PyTorch 和 Kubeflow 等社区的弹性训练的社区贡献工作,后续会发布更多的相关文章,感谢关注。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
