作者
作者田奇,腾讯高级工程师,专注大规模在离线混部,分布式资源管理调度,熟悉Kubernetes,关注云原生大数据、AI。
导语
什么是在离线混部
随着微服务、大数据、人工智能的不断发展,为了满足业务需求,企业的 IT 环境通常运行两大类服务,一类是在线服务,一类是离线作业。
在线服务:往往长时间运行,服务流量存在周期特性,整体资源使用率不高,但是对服务 SLA 却有着极高的要求,如网页搜索服务、电商交易服务等。
离线作业:往往是资源密集型服务,但其可以容忍较高的时延、失败任务重启,如大数据分析服务、机器学习训练服务等。
这两种类型的服务负载在分时复用、资源互补上存在极大的优化空间,使得它成为混部的首选场景,所谓在离线混部,指的就是将离线作业和在线服务部署到同一个节点,以此来提高资源利用率,减少企业对与日俱增的离线计算资源的成本开支。
在离线混部价值
资源利用率提升
据 Gartner 统计,全球数据中心平均使用率不足15%,每年会有巨大的资源浪费。
造成资源效率低下的原因,主要是以下几点:
- 业务流量周期性,对于在线服务,为了保证其流量高峰期的业务 SLA,往往按照最高峰值评估资源。比如外卖业务,峰值期(吃饭时间)可能需要8 核 CPU,但是在低峰期(夜晚),可能就不消耗资源,导致大部分时间段资源利用率都很低,造成浪费。
- 集群资源碎片,所谓资源碎片,指的是服务器还有一定的静态资源没有被分配,但是由于此时各个维度的资源(如 CPU 和 ram )不均衡,导致没有办法再继续分配资源。由于当前主流的资源调度框架,都会采用静态资源分配算法来分配资源,最终都会造成资源碎片,从而无法有效利用资源。
- 在离线机房隔离,资源池划分粒度太粗,有些企业会将在线机房(主要部署在线服务如 Web)、离线机房(主要运行离线集群如 Hadoop)完全隔离开,在这么粗的粒度划分下,在线机房有大量资源闲置,也无法被离线服务利用,反之亦然,离线机房空闲的时候,在线业务也无法充分利用,无法实现不同 IDC 之间资源池的互通。
通过在离线混部,可以充分利用节点的空闲资源,从而提高资源利用率。
成本优化
在离线混部当前在各大中型互联网公司等都有落地,通过混部提升资源利用率,可以获得可观的成本节省,获得规模效应下的巨大经济价值。
下面可以做一个简单的计算分析,我们提升20%的资源利用率,可以大致节省的预算:
假设我们当前所有的机器有10w 核 CPU,平均每台机器的资源使用率是20%, 那么 0.2 10w = 2w 核,在业务规模不变的情况下,假设资源平均使用率提高到40%,我们只需要5w 核就可以满足业务需求,假设 CPU 的平均价格是 300元/核/年,就可以节省 5w 300= 1500w 元/年。
对于有成本控制诉求的企业,在离线混部是降本增效的首选,比如谷歌已经将所有业务混合部署在 Borg(Kubernetes 的前身)系统中,其资源利用率可以达到60%,每年可以节省上亿美金。
挑战
调度保障
资源复用
传统模式的 Kubernetes 按照业务申请的 request 资源量进行静态调度,如果在线和离线业务都按照 request 进行调度,离线业务先调度,占满了节点的 request 资源,那么在线业务就无法调度了,同理,如果在线业务先调度并占满了节点 request 资源,离线业务就没法调度了,传统模式的调度器将没有办法进行在线业务的资源复用。
传统的资源复用方式,往往会采取分时复用,就是在固定的时间点跑离线业务,比如凌晨以后,就开始调度运行离线业务,在白天开始调度在线业务。这种模式下的资源复用,往往时间粒度过粗,虽然可以在一小段时间内复用在线资源,但是有比较严格的时间限制。
另一种是资源预留,将一个机器的资源整体划分为在线资源、离线资源以及在离线共享资源,该方式采用了静态划分的方法,将整机资源进行了划分,无法进行弹性复用,而是只能将在线业务和离线业务的资源进行提前预留。虽然通过部署离线业务能够一定程度的提高资源利用率,但是复用不够充分,并且需要资源规格大的机器才能将资源进行静态划分。
因此,要想高效的、自动化的进行细粒度的资源分时复用,就必须拥有及时准确的资源预测手段、快速响应资源变化的能力,以及一套可以在资源水位变化的时候进行的服务保障措施。
调度增强
由于在线业务和离线业务在工作模式上的差异,社区往往采用不同的调度器进行调度。
混部场景下,在线调度器和离线调度器同时部署在集群中,当资源比较紧张的时候,调度器会发生资源冲突,只能重试,此时调度器的吞吐量和调度性能会受到较大影响,最终影响调度的 SLA。
同时,大规模批量调度场景下,原生的 Kubernetes 是无法支持的,它只支持在线业务的调度。
资源保障
在线业务和离线业务本来属于不同的工作类型,将这两种负载部署在同一个节点上,会出现资源干扰,所谓资源干扰,就是当资源紧张或者流量突发的时候,在线业务在资源使用上会受到离线业务的干扰。在离线混部最重要的目标,就是在提高单机资源利用率的同时,保障在线和离线业务的服务 SLA。
- 针对在线业务,需要保证其在业务在流量高峰时期与没有混部之前一样,不能产生较大的干扰,需要将其干扰率降低到5%以内。
- 针对离线业务,不能因为优先级不如在线业务,就一直处于饥饿或者频繁驱逐状态,影响离线业务总的运行时间和 SLA。
资源隔离
容器的本质是一个受限制的进程,进程之间通过 namespace 做隔离,Cgroup 做资源限制,在云原生时代,所有的业务负载都是通过容器来控制隔离和资源限制。在离线混部场景下,虽然可以通过 Cgroup 来限制在线和离线业务的资源使用,但是当前的原生 Cgroup 在资源超售和在离线场景下,CPU、内存、网络和磁盘 IO 都存在不同的挑战。
在 CPU 方面,给创建的 Pod 指定 Limit,就可以通过 Cgroup quota 限制容器的最大资源使用量,采用 CPU share 权重来划分不同应用的 CPU 权重,但是这种手段在资源不紧张的时候还可以,一旦在线服务有流量突发,此时离线业务是很难立即退出运行的核心的,从而引发在线业务的 SLO 抖动。
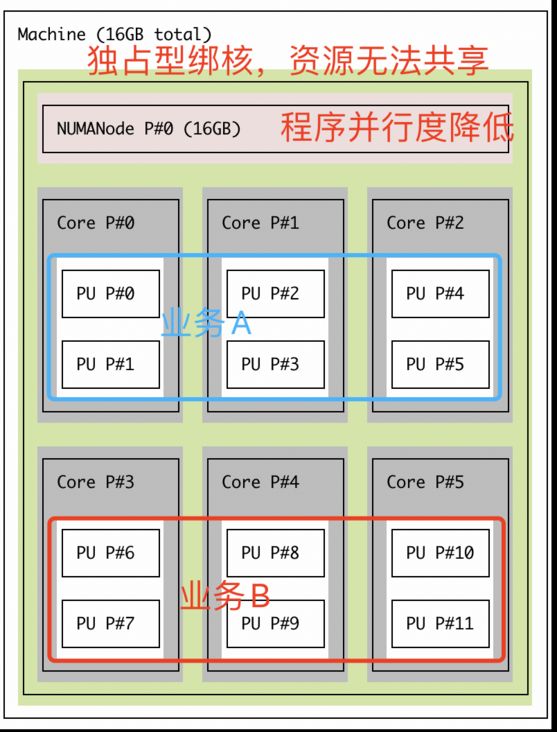
为了保证在线服务稳定性,普遍做法是进行 CPU 绑核,将在线服务绑定在某个逻辑核心上,避免其他业务占用。
但是此时会出现两个问题,一方面是 CPU 核心独占,资源利用不充足的问题,因为一旦一个核心被独占, CPU 就无法充分利用了,而混部的目的就是为了压榨 CPU 的资源,让其能够充分运行;
另一方面,绑核以后,对于有并行计算要求的服务,不管是在线还是离线,都会受到并行度的影响,比如原来虽然限制最多4个核心,但是由于不绑核,服务其实可以并行的使用所有的 CPU ,并行度可以大大提高,但是一旦将服务绑定在4个 CPU 上,那么其并行度就最大是4了。
以上场景中的矛盾相信很多落地在离线混部的厂家都遇到过。
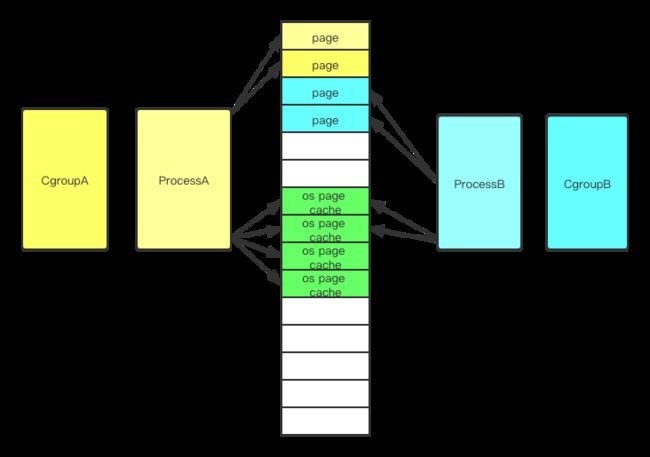
在内存方面,离线业务往往会读取大量文件数据,导致操作系统会做 page cache,而原生操作系统对page cache的管理是全局的,不是容器维度的,容器在 cgroup 的资源限制机制下,往往存在 page cache 无法及时释放的问题,导致其他容器在内存的分配上出现抖动,甚至存在 page cache 一直被另一个 cgroup 占用,无法清理 cgroup 的问题,在离线混部中,如果是离线业务也使用了 page cache,那么此时离线业务的资源可能无法进行调整和压制成功的,就在于 page cache 没有释放。
资源干扰
超线程技术其实是现代 CPU 架构中非常常见的一种硬件虚拟化手段。
简单来说,现代 CPU 基本都是 Numa 架构的,每个 Numa 节点上会有 Socket,Socket 中存在物理核 Core,物理核上还可以开启超线程技术,让操作系统看到多个 CPU 逻辑,我们平常用 top 命令看到的 CPU ,就是指的逻辑 CPU ,当没有开启超线程的时候,该逻辑 CPU 就是物理核心,但是如果开启超线程,该逻辑 CPU 可能就是物理核心上虚拟出来的一个逻辑 CPU 。
比如,如果进行在离线混部,在线业务和离线业务被调度到了同一个物理核心的不同逻辑核上运行,此时就会产生干扰。

TKE 方案
TKE 针对腾讯内部自研业务上云的场景,设计和实现了混部相关方案。
调度保障
我们采取混部节点自动上报扩展的离线资源,离线服务通过离线 Cgroup 大框隔离的方式来保证资源的弹性复用和回收。
在调度增强方面,多调度器共享状态调度的模式,第一是解决在线资源的复用调度问题,第二是解决调度冲突、调度性能、可扩展性和可靠性。
资源复用
上文讲到,传统模式的 Kubernetes 按照业务申请的 request 资源量进行静态调度,如果在线和离线业务都按照 request 进行调度,离线业务先调度,占满了节点的 request 资源,那么在线业务就无法调度了。同理,如果在线业务先调度,离线业务就没法调度了,传统模式的调度器将没有办法进行在线业务的资源复用。
首先,在资源复用的方式上,TKE 将空闲的在线资源进行精准预测,并通过扩展资源的方式,暴露给离线调度器,从而让离线调度器可以看到有多少离线资源是可以复用的,然后进行调度。
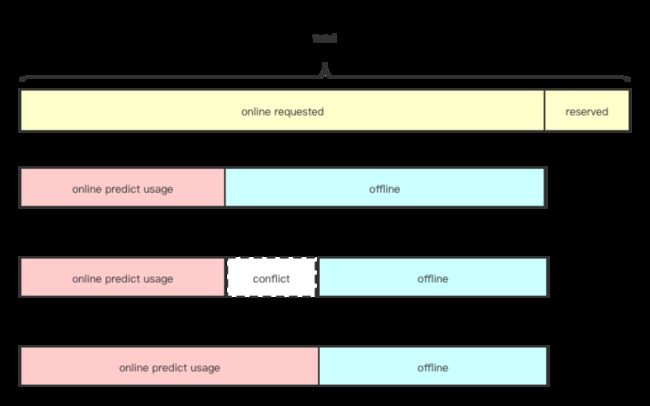
- 针对 request 资源可以修改的离线负载,为了让业务不感知修改资源逻辑,采用 webhook 动态修改其 resource 中的 CPU 等原生资源表达,转变为 extend 资源表达,转换为 besteffort 类型的 Pod,供离线调度器调度计算使用。
- 针对 best-effort 类型的离线负载,我们根据混部节点上报的扩展离线资源,弹性的复用在线资源,该扩展资源随着节点的负载水位实时变更,上文中资源冲突复用已经讲述具体的方案。
- 针对 request 资源不可修改的离线负载(如 driver pod),此时会按照真实的 request 进行调度,那么就有可能和在线调度器发生冲突,因为在混部集群中,整个集群的 request 资源都往往已经被在线业务装箱满了。
其次,资源复用以后,需要能够有一层限制,限制离线负载不能过度使用宿主机的资源;在底层资源限制上,针对在线和离线业务,分别限制其在不同的 Cgroup 层级上:
- 针对在线业务,还是正常的设置其资源需求,按照其 request 资源进行调度,最终按照 Kubernetes 原生的 Cgroup QoS 管理方式设置其资源限制;
- 针对离线业务中的 worker 等资源密集负载,将所有的离线 Pod 限制在一个 Cgroup 父层级构造的资源池内,也就是离线大框,该方案的优点在于既能够让离线业务充分使用到在线空闲资源,但是在在线资源回收的时候,又可以限制住所有的离线任务,从而保证在线服务的稳定性。
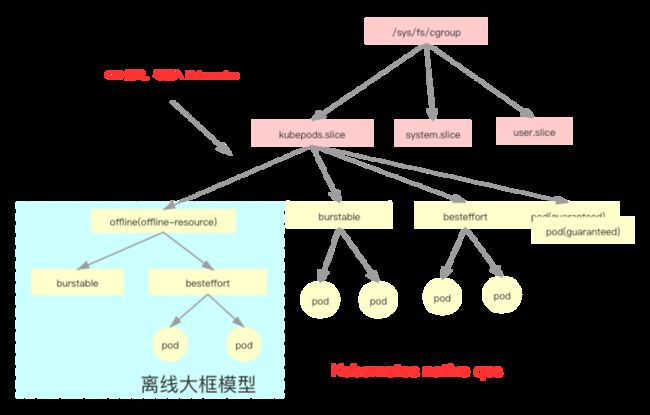
为什么不直接将离线任务当做 Kubernetes 原生的 best effort 处理呢?
原因在于 Kubernetes 机制下的 best effort 类型负载,在 Cgroup 这一层是不设置资源限制的,一旦 Pod 有异常使用资源的情况,将会引发在线资源被抢占和内存挤爆的风险,所以必须要用一个有限制的上层的 Cgroup 来进行限制。
由于 Kubernetes 原生的 Cgroup 管理器,并不支持自定义 Cgroup 层级和更新资源,因此业界往往会入侵 kubelet 代码,修改 kubelet 的 Cgroup 管理器,但是 TKE 全栈式混部对 Kubernetes 是零侵入的,通过采用 CRI 劫持的方式,做到对 Kubernetes Quality of Service 中底层 Cgroup 的修改但是却不用修改 Kubernetes代码,这对于客户来讲是一大亮点。
你不需要做任何处理就可以享受到极致的资源提升效果,同时 Kubernetes 的特性和社区完全兼容,我们可以做到单个节点粒度的混部框架自动上下线,帮助你再需要的时候进行混部操作。
在资源的预测和负载处理上,TKE 采用指数衰减滑动窗口算法,达到快速感应资源上升,慢速感应资源下降的目的,做到自动化,细粒度的分时复用目标;之所以需要快速感应到资源上升,是因为在线服务负载如果有上升,一般都是比较短暂的,此时需要快速感知,从而快速做出资源回收和离线退位。
而在负载下降的过程中,一般不能立即就去减小在线服务的资源,而是要保证其运行一段时间,确认是负载真实的进入平稳状态,离线才能开始复用在线资源。
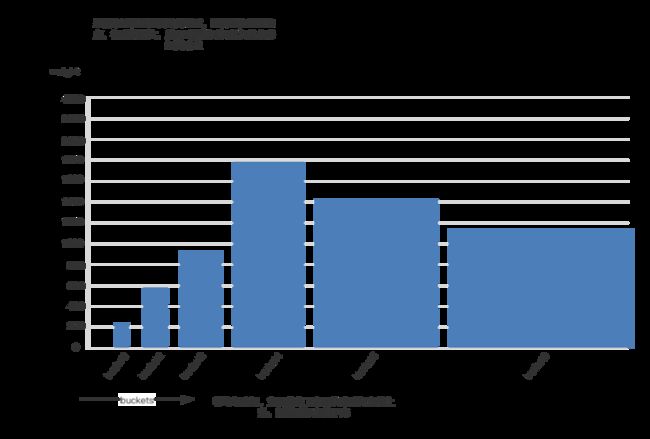
首先是对原始数据分桶,分桶后可以消除需要存储的历史数据点,减少数据存储量,如果采用直接存储历史点的做法,那么 10w 容器的集群,历史的点就会成倍线性增加,而采用分桶统计法,则可以将该值变成常量,分桶以后得到一个柱状图,利用该柱状图进行滑动窗口算法,获取资源预测的平均值和分位值;然后通过时间衰减函数,将最近的点的权重提升,这样可以消除该柱状图统计出来的历史比较久远的数据的作用,进行当前资源的短期预测。

另外,分桶的过程中采取的是非均匀分桶,目的是为了实现能够快速的感知到资源上升,慢速的感应资源下降;我们可以这么简单的理解,假设所有的点的权重都是一样的为1(这些权重其实是柱状图的高),那么我们采用 P90 作为预测值,其实就是求柱状图的面积,如果当前大部分点都是低负载的点,P90 是比较低的值,然后突然有一些点负载突增,他们都会落到范围较大的桶内,也就是宽度变大,后面的桶面积能够立马成为主导面积,那么 P90必定立即会往大桶内移动;
而反过来,当负载从高负载往低负载突降的时候,低负载的点在前面的小桶内,此时小桶的宽度不够,面积无法成为主导面积,P90 就不会那么快的降低,只有当大部分的点都变低的时候,他们在小桶的高度增加,此时小桶才能成为主导面积,P90 预测值才能下降。

调度增强
在离线混部场景下,由于每个调度器单独工作,ClusterState 的数据之间没有进行同步,那么就会发生多个调度器同时选中一个节点,但是资源写入冲突的问题。
当前的分布式资源调度方案主要是以下几种类型:
| 方案(Approach) | 资源视图(Resource choice) | 干扰冲突(Interference) | 分配粒度(Alloc. granularity) | 集群范围策略 |
|---|---|---|---|---|
| 全局调度器(Kubernetes/Borg) | 全局视图 | 无(串行) | 全局搜索,单个调度单元分配 | 严格优先级 |
| 静态分区(比如label分区) | 固定子集 | 无(分区) | 分区隔离策略,单个调度单元分配 | 不同的调度器相互独立 |
| 两层调度(Mesos/Yarn) | 动态子集 | 悲观并发 | 全局搜索,成堆分配,死锁或者长期等待 | 严格的公平调度 |
| 共享状态(Omega) | 全局视图 | 乐观并发 | 每个调度器可以自己决定如何分配 | 每个调度器自己的策略 |
如果让一个调度器来完成在线和离线业务的调度,往往会导致调度器的逻辑复杂,功能堆积,不便于维护和迭代。特别是在集群规模比较大的时候,调度器在性能、可靠性、迭代速度、灵活性等方面都会受到影响。
如果直接部署两个调度器在集群中,由于多个调度器在同一个 Kubernetes 集群,他们使用同一份集群状态来完成调度,但是这里对状态的更新,多个调度器之间是没有同步的,这会导致调度出现冲突,也就是说两个调度器会同时选中同一个节点,但是其实当前节点只够放下其中一个调度器要调度的 Pod,无法同时放置。
共享状态调度,无论从资源视图共享性,并发性,资源分配的灵活性以及对多调度器的灵活支持,都表现比较出色。因此 TKE 采用共享状态乐观并发的调度方式,该方案对于协调器的性能和可靠性有较高要求,但是它可以做到真实的资源共享,资源视图的全局一致性,同时还能支持客户部署多个不同的调度器来针对不同场景进行调度。

TKE 设计和实现了 调度协调器,Kubernetes 调度器只需要在 reserve 阶段,开发扩展插件,进行 reserve 的提交,即可完成共享状态并发。
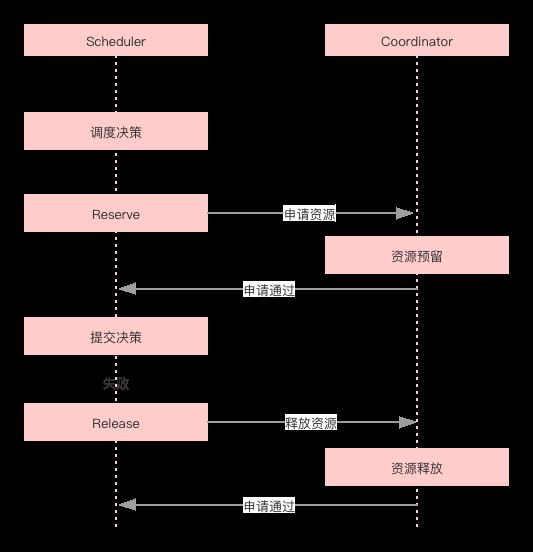
协调器采用 gRPC 调用,通过消息驱动模式来提升其性能和吞吐量,且协调器目前是非常轻量级设计。
- Coordinator 接收到的请求与事件放入后端多维队列中
- 每个 Node 队列优先处理状态更新事件以及高优先级的资源请求
- 不同 Node 的队列并发处理
- 每个请求只执行最基本的资源冲突检查,非常轻量

资源保障
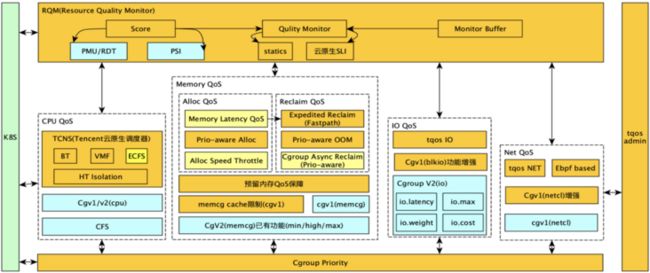
TKE 在离线混部,在单机资源保障上,结合 TencentOS 内核,提供了全维度的资源保证;在 Kubernetes 和内核侧提供了强有力的资源隔离和保障机制。
多优先级策略
在优先级上,TKE 采用精细化的 CPUSet 编排技术,根据不同类型的服务优先级,比如高优在线业务,将其进行 cpuset 绑核,针对中优在线业务,采用 Cgroup quota 和 cpushare 进行 CPU 资源共享,针对离线业务,则采用离线大框将所有离线业务划分在一个离线 Cgroup 资源池下,但是可以去使用所有的 CPU 核,也可以支持离线业务单独绑定在和高优在线业务完全互斥的 CPU 子集下。

针对需要绑核的场景,采用超线程避让绑核分配算法,算法采用贪心策略,优先选取整个 Core 绑定,而不是直接按照逻辑 CPU 进行无差别分配,调度算法可以感知 CPU 拓扑逻辑。

针对内存绑定的场景,采取 Numa 感知的调度策略进行Pod调度。
资源隔离
除了基于传统 Cgroup 限制与隔离,比如采用 CPU quota、CPU share 进行资源的限制和隔离,采用 cpuset 进行绑核等,TKE 也在内核层次上进行了充分的定制和优化,以适应云原生场景。
在 CPU 方面,为了在微观层次应对突发流量以及超线程干扰,TencentOS 云原生内核支持选取 BT 调度类进行离线任务调度,从而能够实现在内核级快速减少离线任务干扰,同时能防止离线任务出现饥饿状态。

BT 调度可以防止多个离线任务出现饿死的现象,当在线服务资源消耗突增,此时为了保证在线服务,往往会压低离线服务的优先级,离线业务其时间片会越来越少,排在队首的离线任务,由于一直跑不完,导致其他离线业务全部饿死,腾讯的内核 BT 调度,可以防止多个离线业务之间饿死,交替的执行离线业务。
在内存方面,TencentOS 内核拥有 Cgroup 级别的 cache 清理功能,及时释放某个容器的 cache, 比如离线业务完成以后,就可以将其 pod 触发的 page cache 进行及时清理。
在网络和磁盘 IO 方面,云原生内核都进行了自研控制,接口都是标准 cgroup 接口,TKE 混部充分利用相关 qos 进行容器的 qos 保证。
干扰检查
业务的 SLO 干扰检查,一方面是系统层次的指标的干扰检查,另一方面是应用层次的指标的干扰检查。
在系统层次,TKE 采集各种系统资源指标,比如感知指令集频率 CPI,感知系统调用等手段,获取系统指标干扰。
在应用层次,TKE 允许在线业务设置自己的 SLO 干扰阈值,TKE 混部系统能够回调和检查业务的 SLO,一旦检查到业务真实的 SLO 不符合预期,就会采取一系列措施进行干扰源消除,其中包括状态机控制的信号处理模式,通过压缩离线资源、禁止离线调度、驱逐等层层递进的手段,保证业务的 SLO, 以及整个节点的稳定性。
对于离线业务的 SLO,TKE 允许动态优先级调整以及弹性公有云的方式,避免离线业务长时间等待或者频繁驱逐,保证离线业务能够在规定时间内跑完。

总结与展望
本文针对在离线混部中最关键的资源保障和调度保障,阐述了 TKE 的在离线混部方案,针对资源保障,通过应用优先级划分、内核增强、干扰检查、超线程避让等关键手段,保证应用间资源隔离;针对调度保障,采用快感知慢回退预测算法、离线大框、共享状态调度等手段,进行资源弹性复用,解决调度冲突。
未来的混部发展,第一是无差别混部,混部的场景将不再局限于在离线,而是更多复杂类型的负载混部,将会出现更多不同优先等级的负载,进行多优先级资源池的池化处理,资源池间抢占和池间回收技术,充分探索系统层次的资源干扰,如 CPI 干扰检查,eBPF 观测技术;第二是混部+弹性的极致结合,混合云中 IDC 和公有云极致的资源共享,多云多集群的资源分时复用调度,以此来达到云的本质目标--降本增效。
参考
腾讯TencentOS 十年云原生的迭代演进之路:
https://mp.weixin.qq.com/s/Cb...
英特尔® 超线程技术:https://www.intel.com/content...
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
