- MarsCode算法题之补给站最优花费问题
xiao--xin
豆包MarsCode算法题算法java动态规划MarsCode
1.问题描述小U计划进行一场从地点A到地点B的徒步旅行,旅行总共需要M天。为了在旅途中确保安全,小U每天都需要消耗一份食物。在路程中,小U会经过一些补给站,这些补给站分布在不同的天数上,且每个补给站的食物价格各不相同。小U需要在这些补给站中购买食物,以确保每天都有足够的食物。现在她想知道,如何规划在不同补给站的购买策略,以使她能够花费最少的钱顺利完成这次旅行。M:总路程所需的天数。N:路上补给站的
- Go语言学习 day20
qq_50996930
Go语言基础golang学习算法
golang遍历map是有序还是无序,为什么?无序,因为go的map基于哈希表,可以实现快速插入和查找,不保证顺序。会根据key的哈希值来决定存放kv对的哈希桶的索引,对key的哈希值的计算没有固定顺序。定义一个局部变量,默认是分配到堆上还是栈上,什么情况是堆上?默认在栈上。分配到堆上的话,靠go的逃逸分析机制,编译器用逃逸分析,如果一个变量生存周期大于函数作用域,就是堆上,或者被外部引用(局部变
- C++ Lambda 表达式的本质及原理分析
流星雨爱编程
#C++进阶c++开发语言
目录1.引言2.Lambda的本质3.Lambda的捕获机制的本质4.捕获方式的实现与底层原理5.默认捕获的实现原理6.捕获this的机制7.捕获的限制与注意事项8.总结1.引言C++中的Lambda表达式是一种匿名函数,最早在C++11引入,用于简化函数对象的定义和使用。它以更简洁的语法提供了强大的功能,但其本质和捕获机制背后有许多值得深究的细节。本文将探讨Lambda的本质,以及捕获的底层实现
- MySQL中日期和时间戳的转换:字符到DATE和TIMESTAMP的相互转换
m0_51274464
面试学习路线阿里巴巴mysql数据库
在MySQL中,经常需要在DATE、TIMESTAMP和字符串之间进行相互转换。以下是一些常见的转换方法:1.字符串到日期/时间类型字符串转DATE:使用STR_TO_DATE()函数将字符串转换为DATE类型。你需要提供字符串的格式。SELECTSTR_TO_DATE('2024-08-24','%Y-%m-%d')ASmy_date;字符串转TIMESTAMP:同样使用STR_TO_DATE(
- uniapp中<map>地图怎么实现点位聚合?
GoppViper
前端uni-appuniapp前端前端框架地图聚合
推荐学习文档golang应用级os框架,欢迎stargolang应用级os框架使用案例,欢迎star案例:基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总想学习更多golang知识,这里有免费的golang学习笔记专栏想学习更多前端知识,这里有免费的前端专栏确定聚合条件定义聚合的距离阈值:根据你的需求确定一个合适的距离阈值,当两个标记点之
- Flask教程5:flask数据库SQLAlchemy
Cachel wood
Flask入门教程数据库flaskoraclepython阿里云开发语言LLM
文章目录SQLAlchemy为什么使用ORM初始化数据库配置表模型的定义与数据库映射数据的增、删、改、查操作数据的添加数据的查找数据的修改数据的删除init_app作用详解SQLAlchemySQLAlchemy是一个基于Python实现的ORM(ObjectRelationalMapping,对象关系映射)框架。该框架建立在DBAPI(数据库应用程序接口系统)之上,使用关系对象映射进行数据库操作
- 【Innodb阅读笔记】之 二进制文件
꧁瀟洒辵1恛꧂
笔记
一、什么是二进制文件二进制文件记录了对mySQL数据库执行修改的所有操作,不包括select和show这类操作,因为这类操作对数据库本身没有修改。但是,当执行修改操作,数据库没有发生变化,这类操作也会写入二进制文件中。通过配置参数log-bin开启二进制日志。如:#配置文件写入开启二进制指定文件名称为:mysql-bin#log-bin#不指定名称默认使用主机名log-bin=mysql-bin#
- PHP代码段,用于连接MySQL数据库并查询数据
黄聪的笔记本
数据库phpmysql
connect_error){die("连接失败:".$conn->connect_error);}//SQL查询语句$sql="SELECTid,firstname,lastnameFROMMyGuests";$result=$conn->query($sql);if($result->num_rows>0){//输出数据while($row=$result->fetch_assoc()){ec
- el-select 的默认选中 以及后端返回的数据进行默认选中
向明天乄
vue.jsjavascriptecmascript
前言本次内容为el-select的两种默认选中方式,一种自定义内容的默认选中,一种的后端返回数据的默认选中以及后端返回数据的默认选中,及注意事项。注意点!!!v-model拿到的值一定要是纯数值类型,只有数值类型才会自动加载对应的选中项,其他类型的则不生效一,自定义内容的默认选中statusType:[{label:'正常',value:1},{label:'禁用',value:0},],二,由后
- MySQL存储引擎
JustGopher
MySQL数据库mysql数据库
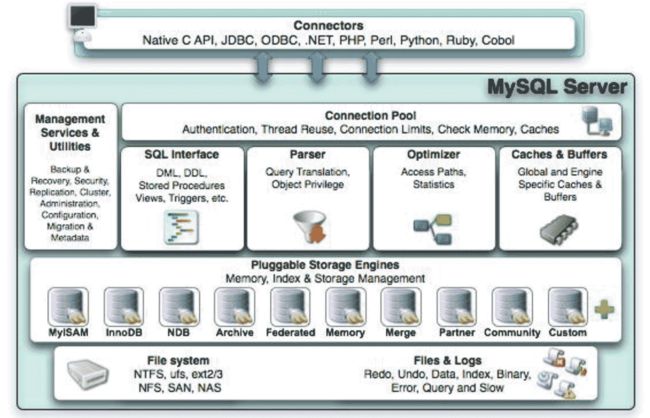
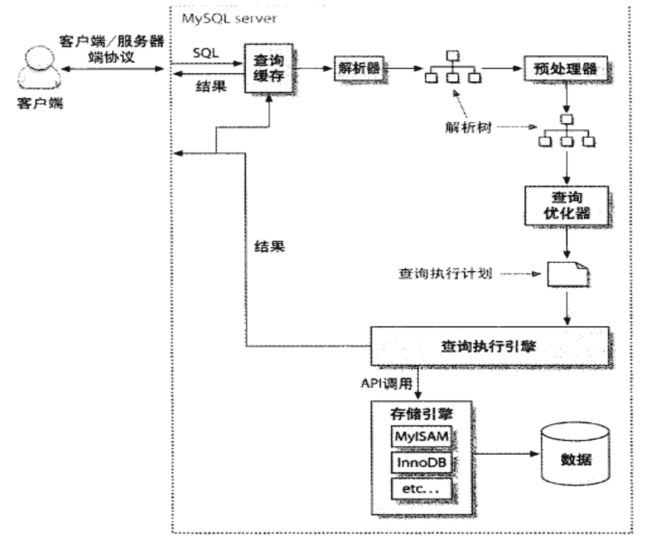
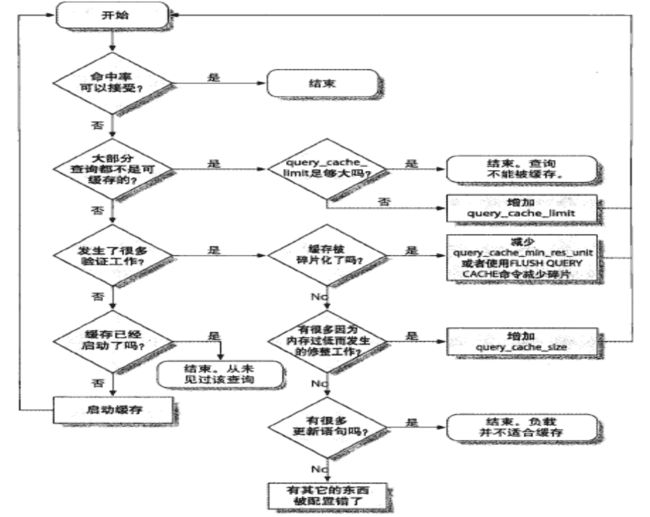
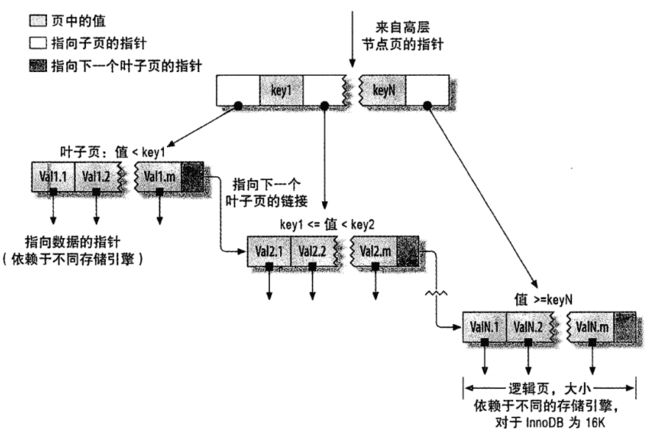
MySQL体系结构连接层最上层是一些客户端和连接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为每个安全接入的用户端验证它所具有的操作权限。服务层第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化、部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如:过程、函数等。引擎层存储引擎真正的负责了MySQL中数据的存储和提取,服务器
- mysql存储函数
小冯爱编程
mysql数据库sql
文章目录存储函数一、创建存储函数二、调用存储函数存储函数我们学过很多函数,使用这些函数可以对数据进行的各种处理操作,极大地提高用户对数据库的管理效率。MySQL支持自定义函数,定义好之后,调用方式与调用MySQL预定义的系统函数一样,比如AVG、COUNT、SUBSTR等。一、创建存储函数CREATEFUNCTION函数名(参数名参数类型,...)RETURNS返回值类型[characterist
- Linux内存管理:(一)物理页面分配流程 及 Linux6.5源码分析(中)
Albert XUU
内存管理linux运维服务器
《Linux6.5源码分析:内存管理系列文章》本系列文章将对内存管理相关知识进行梳理与源码分析,重点放在linux源码分析上,并结合eBPF程序对内核中内存管理机制进行数据实时拿取与分析。在进行正式介绍之前,有必要对文章引用进行提前说明。本系列文章参考了大量的博客、文章以及书籍:《深入理解Linux内核》《Linux操作系统原理与应用》《奔跑吧Linux内核》《深入理解Linux进程与内存》《基于
- 从新手到高手的蜕变:MySQL 视图进阶全攻略
꧁瀟洒辵1恛꧂
mysql数据库
一、视图是什么视图是一种虚拟表,它并非像普通表那样实际存储数据,而是基于SQL查询语句定义的。视图是从一个或多个基表(实际存在的物理表)或其他视图中导出的结果集。可以将其视为一个预定义的查询,当执行针对视图的操作时,MySQL会根据视图的定义从基表中动态检索数据。打个比方,你从一个或者好几个真实的表,还有别的视图里按照一定规则挑数据,这些挑出来的数据就构成了视图。每次你用这个视图查数据,MySQL
- 【MySQL】存储函数
JustGopher
MySQLmysqlandroidadb
存储函数根据调用方式的不同,可以把存储程序分为存储例程、触发器和事件这几种类型,存储例程又可以被细分为存储函数和存储过程存储程序├──存储例程│├──存储函数│└──存储过程├──触发器└──事件用户自定义变量定义变量set@a=1;查看变量的值select@a;把一个常量赋值给变量set@a='哈哈哈';把一个变量赋值给变量set@b=@a;还可以将某个查询的结果赋值给变量,前提是这个变量最多包
- Python之Spire.XLS进行Excel与CSV文件互转换
一晌小贪欢
Python自动化办公pythonexcelpython办公python自动化
目录专栏导读背景安装Excel转CSV文件(推荐速度会快一点)代码CSV转Excel文件(小文件推荐)代码结尾专栏导读欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手️博客主页:请点击——>一晌小贪欢的博客主页求关注该系列文章专栏:请点击——>Python办公自动化专栏求订阅文章作者技术和水平有限,如果文中出现错误,希望大家能指正❤️欢迎各位佬关注!❤️背景安装我们利用
- 华为云 oracle rac 稳定性,Oracle 11g RAC之HAIP相关问题总结
安幕
华为云oraclerac稳定性
1文档概要环境:RHEL6.4+GI11.2.0.4+Oracle11.2.0.4对有关HAIP相关问题的总结,包括禁用/启用HAIP,修改ASM资源的依赖关系,修改cluster_interconnects参数等。2禁用/启用HAIP2.1禁用/启用HAIP资源禁用HAIP资源:root用户执行@allnodes#/opt/app/11.2.0/grid/bin/crsctlmodifyreso
- mysql有rac吗_现在的国产数据库有类似于oracle Rac 的功能吗?
weixin_39623050
mysql有rac吗
有的,优炫软件今年就在软博会重磅推出了UXDBSuperRAC(超级实时应用集群),发布了优炫数据库UXDB新版本。长久以来,大型联机交易系统,特别是作为典型应用的银行核心业务系统对数据库要求极为严苛,要保证业务连续性,零RTO、RPO,强一致性ACID、业务不可分割性需求。因此,基于共享存储概念的RAC模式和完全支持ACID强一致性的数据库系统,依然是银行业核心数据库系统的首选,优炫数据库Sup
- C/C++ 已排序的链表中删除重复项算法详解及源码
猿来如此yyy
C/C++算法详解及源码算法c语言c++计算机视觉排序算法数据结构链表
已排序的链表中删除重复项的算法可以通过遍历链表的方式实现。具体步骤如下:初始化一个指针cur,指向链表的头节点。遍历链表,如果当前节点的值和下一个节点的值相同,则删除下一个节点,并将当前节点的next指针指向下一个节点的next指针,即将当前节点与下一个节点的重复项跳过。如果当前节点的值和下一个节点的值不同,则将指针cur指向下一个节点。优点:时间复杂度为O(n),其中n为链表的长度,算法只需要一
- 从0安装mysql server
追心嵌入式
mysql
安装MySQLServer首先,你需要在Ubuntu上安装MySQL服务器。运行以下命令来安装:sudoaptupdatesudoaptinstallmysql-server安装完成后,MySQL服务会自动启动。你可以通过以下命令检查MySQL服务是否正在运行:sudosystemctlstatusmysql如果MySQL正在运行,你会看到类似于以下的输出:yaml●mysql.service-M
- Vue组件开发-使用 html2canvas 和 jspdf 库实现PDF文件导出 设置页面大小及方向
LCG元
前端vue.jspdf前端
在Vue项目中实现导出PDF文件、调整文件页面大小和页面方向的功能,使用html2canvas将HTML内容转换为图片,再使用jspdf把图片添加到PDF文件中。以下是详细的实现步骤和代码示例:步骤1:安装依赖首先,在项目中安装html2canvas和jspdf:npminstallhtml2canvasjspdf步骤2:创建Vue组件以下是一个完整的Vue组件示例,包含导出PDF、调整页面大小和
- MyEclipse最新版-版本更新说明及下载 - MyEclipse官方中文网
weixin_34268310
开发工具
http://www.myeclipsecn.com/learningcenter/myeclipse-update/【重要更新】MyEclipse2015正式版发布【重要更新】MyEclipse2015Stable2.0发布【重要更新】MyEclipse2016CI0正式发布【重要更新】MyEclipse2016Stable1.0发布【重要更新】MyEclipse2017CI1正式发布【重要更新
- 深入理解 Python 之 with 语句
Phoenixtree_DongZhao
随笔pythonpython
浅谈Python的with语句深入理解Python王生辉,李骅宸发布:2011-12-02引言with语句是从Python2.5开始引入的一种与异常处理相关的功能(2.5版本中要通过fromfutureimportwith_statement导入后才可以使用),从2.6版本开始缺省可用(参考What’snewinPython2.6?中with语句相关部分介绍)。with语句适用于对资源进行访问的场
- Python框架区别是什么?比较常用的框架有哪些?
其实还好啦
python编程语言
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。众所周知,Python开发框架大大减少了开发者不必要的重复劳动,提高了项目开发效率的同时,还使得创建的程序更加稳定。目前比较主流的Python框架都有哪些呢?一般大家用的比较多的是Django、Flask、Scrapy、Diesel、Cubes、Pulsar和Tornado。那
- Vue.js 如何塑造现代网络体验
清风孤客
vue.js网络前端
Vue.js已迅速成为JavaScript框架中的热门之选,以其简洁的设计、灵活性和强大功能而闻名。全球的开发者被Vue.js所吸引,是因为它能极为轻松地构建动态且引人入胜的用户界面。但Vue.js究竟有何用途,又为何如此受欢迎呢?本文将探讨Vue.js及其在各个领域的关键应用。我们将展示开发者如何利用它构建从交互式网络应用、单页应用(SPA)到复杂电子商务网站等各种项目。我们还将讨论其核心特性、
- python爬虫之bs4解析和xpath解析
A.way30
python爬虫开发语言xpath
bs4解析原理:1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取如何实例化BeautifulSoup对象:frombs4importBeautifulSoupBeautifulSoup(参数一,参数二)参数一为文件描述符,参数二为解析器,一般为’lxml’一对象的实例化:1.将本地的h
- Java开发神器——MyEclipse CI 2019.4.0 全新发布(附下载)
chushi6862
开发工具javaui
MyEclipse线上特惠,在线立享专属折扣!火热开启中>>MyEclipse2019的升级版本中,推出对Java11的支持、性能改进及新的连接器等。【MyEclipseCI2019.4.0安装包下载】增强Java功能Java11MyEclipse附带了一个集成的OpenJDK11版本,因此它不仅可以在Java11上运行,而且还完全支持Java11开发。如果要使用Java11功能,可以使用快速修复
- 【智能算法】哈里斯鹰算法(HHO)原理及实现
小O的算法实验室
智能算法算法智能算法
目录1.背景2.算法原理2.1算法思想2.2算法过程3.代码实现4.参考文献1.背景2019年,Heidari等人受到哈里斯鹰捕食行为启发,提出了哈里斯鹰算法(HarrisHawkOptimization,HHO)。2.算法原理2.1算法思想根据哈里斯鹰特性,HHO分为探索-过渡-开发三个阶段。2.2算法过程探索:哈里斯鹰以其强大的视力追踪和检测猎物,但有时猎物不易察觉。它们会在沙漠地区等待、观察
- FragPipe: 一个强大的蛋白质组学数据分析平台
2401_87189860
数据分析数据挖掘
FragPipe简介FragPipe是一个由Nesvizhskii实验室开发的综合性蛋白质组学数据分析平台。它以MSFragger搜索引擎为核心,集成了多种功能强大的分析工具,为研究人员提供了从原始数据处理到生物学解释的一站式解决方案。FragPipe具有用户友好的Java图形用户界面(GUI),同时也支持命令行模式,可以在Windows、Linux或云环境中运行。FragPipe的主要特点快速高
- Lucene常用的字段类型&lucene检索打分原理
学会了没
全文检索lucene打分字段
在ApacheLucene中,Field类是文档中存储数据的基础。不同类型的Field用于存储不同类型的数据(如文本、数字、二进制数据等)。以下是一些常用的Field类型及其底层存储结构:TextField:用途:用于存储文本数据,并对其进行分词和索引。底层存储结构:文本数据会被分词器(Analyzer)处理,将文本分割成词项(terms)。每个词项会被存储在倒排索引(invertedindex)
- Pytorch 基础之张量索引
攻城狮随笔
Pytorch机器学习pytorch深度学习python
本次将介绍一下Tensor张量常用的索引与切片的方法:1.index索引index索引值表示相应维度值的对应索引a=torch.rand(4,3,28,28)print(a[0].shape)#返回维度一的第0索引tensorprint(a[0,0].shape)#返回维度一0索引位置,维度二0索引位置的tensorprint(a[0,0,0].shape)#返回维度一0索引,维度二0索引,维度三
- 安装数据库首次应用
Array_06
javaoraclesql
可是为什么再一次失败之后就变成直接跳过那个要求
enter full pathname of java.exe的界面
这个java.exe是你的Oracle 11g安装目录中例如:【F:\app\chen\product\11.2.0\dbhome_1\jdk\jre\bin】下的java.exe 。不是你的电脑安装的java jdk下的java.exe!
注意第一次,使用SQL D
- Weblogic Server Console密码修改和遗忘解决方法
bijian1013
Welogic
在工作中一同事将Weblogic的console的密码忘记了,通过网上查询资料解决,实践整理了一下。
一.修改Console密码
打开weblogic控制台,安全领域 --> myrealm -->&n
- IllegalStateException: Cannot forward a response that is already committed
Cwind
javaServlets
对于初学者来说,一个常见的误解是:当调用 forward() 或者 sendRedirect() 时控制流将会自动跳出原函数。标题所示错误通常是基于此误解而引起的。 示例代码:
protected void doPost() {
if (someCondition) {
sendRedirect();
}
forward(); // Thi
- 基于流的装饰设计模式
木zi_鸣
设计模式
当想要对已有类的对象进行功能增强时,可以定义一个类,将已有对象传入,基于已有的功能,并提供加强功能。
自定义的类成为装饰类
模仿BufferedReader,对Reader进行包装,体现装饰设计模式
装饰类通常会通过构造方法接受被装饰的对象,并基于被装饰的对象功能,提供更强的功能。
装饰模式比继承灵活,避免继承臃肿,降低了类与类之间的关系
装饰类因为增强已有对象,具备的功能该
- Linux中的uniq命令
被触发
linux
Linux命令uniq的作用是过滤重复部分显示文件内容,这个命令读取输入文件,并比较相邻的行。在正常情 况下,第二个及以后更多个重复行将被删去,行比较是根据所用字符集的排序序列进行的。该命令加工后的结果写到输出文件中。输入文件和输出文件必须不同。如 果输入文件用“- ”表示,则从标准输入读取。
AD:
uniq [选项] 文件
说明:这个命令读取输入文件,并比较相邻的行。在正常情况下,第二个
- 正则表达式Pattern
肆无忌惮_
Pattern
正则表达式是符合一定规则的表达式,用来专门操作字符串,对字符创进行匹配,切割,替换,获取。
例如,我们需要对QQ号码格式进行检验
规则是长度6~12位 不能0开头 只能是数字,我们可以一位一位进行比较,利用parseLong进行判断,或者是用正则表达式来匹配[1-9][0-9]{4,14} 或者 [1-9]\d{4,14}
&nbs
- Oracle高级查询之OVER (PARTITION BY ..)
知了ing
oraclesql
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
select e.ename, e.job, e.sal, e.deptno
from scott.emp e,
(se
- Python调试
矮蛋蛋
pythonpdb
原文地址:
http://blog.csdn.net/xuyuefei1988/article/details/19399137
1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:
IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:
http://www.ibm.com/d
- webservice传递自定义对象时函数为空,以及boolean不对应的问题
alleni123
webservice
今天在客户端调用方法
NodeStatus status=iservice.getNodeStatus().
结果NodeStatus的属性都是null。
进行debug之后,发现服务器端返回的确实是有值的对象。
后来发现原来是因为在客户端,NodeStatus的setter全部被我删除了。
本来是因为逻辑上不需要在客户端使用setter, 结果改了之后竟然不能获取带属性值的
- java如何干掉指针,又如何巧妙的通过引用来操作指针————>说的就是java指针
百合不是茶
C语言的强大在于可以直接操作指针的地址,通过改变指针的地址指向来达到更改地址的目的,又是由于c语言的指针过于强大,初学者很难掌握, java的出现解决了c,c++中指针的问题 java将指针封装在底层,开发人员是不能够去操作指针的地址,但是可以通过引用来间接的操作:
定义一个指针p来指向a的地址(&是地址符号):
- Eclipse打不开,提示“An error has occurred.See the log file ***/.log”
bijian1013
eclipse
打开eclipse工作目录的\.metadata\.log文件,发现如下错误:
!ENTRY org.eclipse.osgi 4 0 2012-09-10 09:28:57.139
!MESSAGE Application error
!STACK 1
java.lang.NoClassDefFoundError: org/eclipse/core/resources/IContai
- spring aop实例annotation方法实现
bijian1013
javaspringAOPannotation
在spring aop实例中我们通过配置xml文件来实现AOP,这里学习使用annotation来实现,使用annotation其实就是指明具体的aspect,pointcut和advice。1.申明一个切面(用一个类来实现)在这个切面里,包括了advice和pointcut
AdviceMethods.jav
- [Velocity一]Velocity语法基础入门
bit1129
velocity
用户和开发人员参考文档
http://velocity.apache.org/engine/releases/velocity-1.7/developer-guide.html
注释
1.行级注释##
2.多行注释#* *#
变量定义
使用$开头的字符串是变量定义,例如$var1, $var2,
赋值
使用#set为变量赋值,例
- 【Kafka十一】关于Kafka的副本管理
bit1129
kafka
1. 关于request.required.acks
request.required.acks控制者Producer写请求的什么时候可以确认写成功,默认是0,
0表示即不进行确认即返回。
1表示Leader写成功即返回,此时还没有进行写数据同步到其它Follower Partition中
-1表示根据指定的最少Partition确认后才返回,这个在
Th
- lua统计nginx内部变量数据
ronin47
lua nginx 统计
server {
listen 80;
server_name photo.domain.com;
location /{set $str $uri;
content_by_lua '
local url = ngx.var.uri
local res = ngx.location.capture(
- java-11.二叉树中节点的最大距离
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class MaxLenInBinTree {
/*
a. 1
/ \
2 3
/ \ / \
4 5 6 7
max=4 pass "root"
- Netty源码学习-ReadTimeoutHandler
bylijinnan
javanetty
ReadTimeoutHandler的实现思路:
开启一个定时任务,如果在指定时间内没有接收到消息,则抛出ReadTimeoutException
这个异常的捕获,在开发中,交给跟在ReadTimeoutHandler后面的ChannelHandler,例如
private final ChannelHandler timeoutHandler =
new ReadTim
- jquery验证上传文件样式及大小(好用)
cngolon
文件上传jquery验证
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="jquery1.8/jquery-1.8.0.
- 浏览器兼容【转】
cuishikuan
css浏览器IE
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设
- Shell特殊变量:Shell $0, $#, $*, $@, $?, $$和命令行参数
daizj
shell$#$?特殊变量
前面已经讲到,变量名只能包含数字、字母和下划线,因为某些包含其他字符的变量有特殊含义,这样的变量被称为特殊变量。例如,$ 表示当前Shell进程的ID,即pid,看下面的代码:
$echo $$
运行结果
29949
特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个
- 程序设计KISS 原则-------KEEP IT SIMPLE, STUPID!
dcj3sjt126com
unix
翻到一本书,讲到编程一般原则是kiss:Keep It Simple, Stupid.对这个原则深有体会,其实不仅编程如此,而且系统架构也是如此。
KEEP IT SIMPLE, STUPID! 编写只做一件事情,并且要做好的程序;编写可以在一起工作的程序,编写处理文本流的程序,因为这是通用的接口。这就是UNIX哲学.所有的哲学真 正的浓缩为一个铁一样的定律,高明的工程师的神圣的“KISS 原
- android Activity间List传值
dcj3sjt126com
Activity
第一个Activity:
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import android.app.Activity;import android.content.Intent;import android.os.Bundle;import a
- tomcat 设置java虚拟机内存
eksliang
tomcat 内存设置
转载请出自出处:http://eksliang.iteye.com/blog/2117772
http://eksliang.iteye.com/
常见的内存溢出有以下两种:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Java heap space
------------
- Android 数据库事务处理
gqdy365
android
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用setTransactionSuccessful() 方法则回滚事务。事
- Java 打开浏览器
hw1287789687
打开网址open浏览器open browser打开url打开浏览器
使用java 语言如何打开浏览器呢?
我们先研究下在cmd窗口中,如何打开网址
使用IE 打开
D:\software\bin>cmd /c start iexplore http://hw1287789687.iteye.com/blog/2153709
使用火狐打开
D:\software\bin>cmd /c start firefox http://hw1287789
- ReplaceGoogleCDN:将 Google CDN 替换为国内的 Chrome 插件
justjavac
chromeGooglegoogle apichrome插件
Chrome Web Store 安装地址: https://chrome.google.com/webstore/detail/replace-google-cdn/kpampjmfiopfpkkepbllemkibefkiice
由于众所周知的原因,只需替换一个域名就可以继续使用Google提供的前端公共库了。 同样,通过script标记引用这些资源,让网站访问速度瞬间提速吧
- 进程VS.线程
m635674608
线程
资料来源:
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000 1、Apache最早就是采用多进程模式 2、IIS服务器默认采用多线程模式 3、多进程优缺点 优点:
多进程模式最大
- Linux下安装MemCached
字符串
memcached
前提准备:1. MemCached目前最新版本为:1.4.22,可以从官网下载到。2. MemCached依赖libevent,因此在安装MemCached之前需要先安装libevent。2.1 运行下面命令,查看系统是否已安装libevent。[root@SecurityCheck ~]# rpm -qa|grep libevent libevent-headers-1.4.13-4.el6.n
- java设计模式之--jdk动态代理(实现aop编程)
Supanccy2013
javaDAO设计模式AOP
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
&
- Spring 4.2新特性-对java8默认方法(default method)定义Bean的支持
wiselyman
spring 4
2.1 默认方法(default method)
java8引入了一个default medthod;
用来扩展已有的接口,在对已有接口的使用不产生任何影响的情况下,添加扩展
使用default关键字
Spring 4.2支持加载在默认方法里声明的bean
2.2
将要被声明成bean的类
public class DemoService {