今天来分享一篇字节跳动抖音电商的面经,希望对小伙伴们有所帮助~
文章目录:

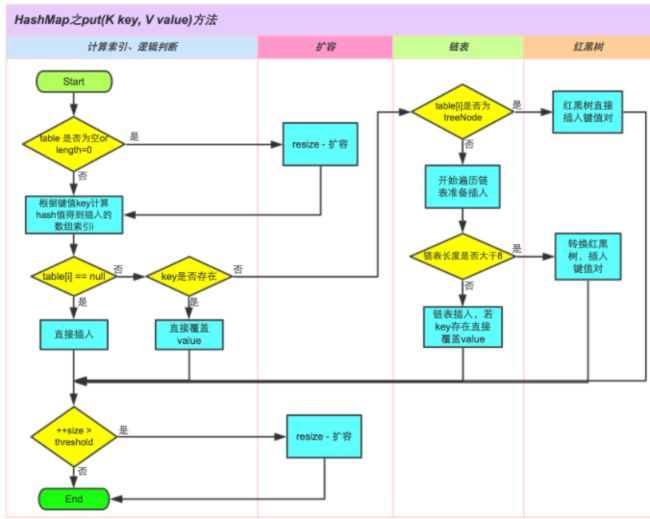
HashMap的put方法
put方法过程:
- 如果table没有初始化就先进行初始化过程
- 使用hash算法计算key的索引
- 判断索引处有没有存在元素,没有就直接插入
- 如果索引处存在元素,则遍历插入,有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入
- 链表的数量大于阈值8,就要转换成红黑树的结构
- 添加成功后会检查是否需要扩容
HashMap的扩容过程
1.8扩容机制:当元素个数大于threshold时,会进行扩容,使用2倍容量的数组代替原有数组。采用尾插入的方式将原数组元素拷贝到新数组。1.8扩容之后链表元素相对位置没有变化,而1.7扩容之后链表元素会倒置。
由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因是数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标计算。也就是说,在元素拷贝过程不需要重新计算元素在数组中的位置,只需要看看原来的hash值新增的那个bit是1还是0,是0的话索引没变,是1的话索引变成“原索引+oldCap”(根据e.hash & (oldCap - 1) == 0判断) 。
这样可以省去重新计算hash值的时间,而且由于新增的1bit是0还是1可以认为是随机的,因此resize的过程会均匀的把之前的冲突的节点分散到新的bucket。
自定义协议怎么解决粘包问题
- 固定长度的数据包。为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。
- 以指定字符串为包的结束标志。当字节流中遇到特殊的符号值时就认为到一个包的结尾。
- header + body格式。这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中含有一个字段来表明包体有多大。
LeetCode129题(求根节点到叶节点数字之和)
深度优先搜索。从根节点开始,遍历每个节点,如果遇到叶子节点,则将叶子节点对应的数字加到数字之和。如果当前节点不是叶子节点,则计算其子节点对应的数字,然后对子节点递归遍历。
没有困难的题目,只有勇敢的刷题人!
// 输入: [1,2,3]
// 1
// / \
// 2 3
// 输出: 25
class Solution {
public int sumNumbers(TreeNode root) {
if (root == null) {
return 0;
}
return sumNumbersHelper(root, 0);
}
private int sumNumbersHelper(TreeNode node, int sum) {
if (node == null) {
return 0;
}
if (sum > Integer.MAX_VALUE / 10 || (sum == Integer.MAX_VALUE / 10 && node.val > Integer.MAX_VALUE % 10)) {
throw new IllegalArgumentException("exceed max int value");
}
sum = sum * 10 + node.val;
if (node.left == null && node.right == null) {
return sum;
}
return sumNumbersHelper(node.right, sum) + sumNumbersHelper(node.left, sum);
}
}MySQL的索引结构
MySQL 数据库使用最多的索引类型是BTREE索引,底层基于B+树数据结构来实现。
B+ 树是基于B 树和叶子节点顺序访问指针进行实现,它具有B树的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ 树中,节点中的 key 从左到右递增排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
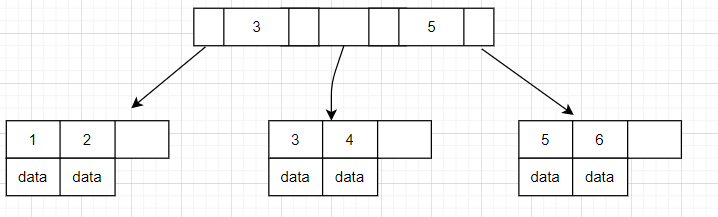
进行查找操作时,首先在根节点进行二分查找,找到key所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的数据项。
为什么用B+树
B+树的特点就是够矮够胖,能有效地减少访问节点次数从而提高性能。
二叉树:二分查找树,虽然也有很好的查找性能log2N,但是当N比较大的时候,树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差。最坏的情况会退化成链表。所以,B+树更适合作为MySQL索引结构。
B树:因为B+的分支结点存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,而由于B+树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可。所以B+树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以B+树更适合用于数据库索引。
having的作用
having 用来分组查询后指定一些条件来输出查询结果,having作用和where类似,但是having只能用在group by场合,并且必须位于group by之后order by之前。
SELECT cust_id, COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;聚簇索引
聚集索引的叶子节点就是整张表的行记录。InnoDB 主键使用的是聚簇索引。聚集索引要比非聚集索引查询效率高很多。聚集索引叶子节点的存储是逻辑上连续的,使用双向链表连接,叶子节点按照主键的顺序排序,因此对于主键的排序查找和范围查找速度比较快。
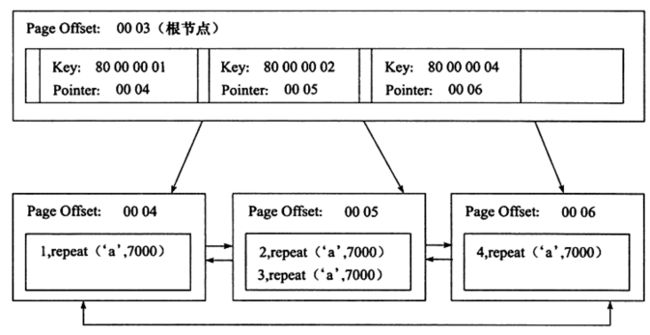
对于InnoDB来说,聚集索引一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为NULL的唯一索引。如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键长度为6个字节,它的值会随着数据的插入自增。
聚簇索引相比非聚簇索引的优点
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快;
- 聚集索引叶子节点的存储是逻辑上连续的,所以对于主键的排序查找和范围查找速度会更快。
线程池的七大参数
ThreadPoolExecutor 的通用构造函数:
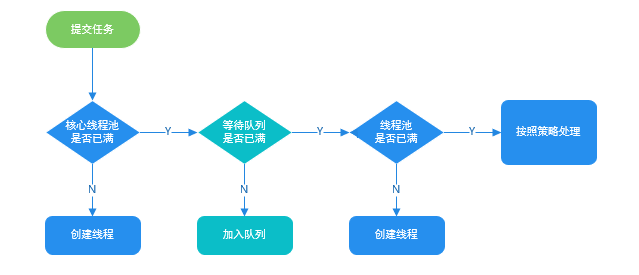
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler); - corePoolSize:当有新任务时,如果线程池中线程数没有达到线程池的基本大小,则会创建新的线程执行任务,否则将任务放入阻塞队列。当线程池中存活的线程数总是大于 corePoolSize 时,应该考虑调大 corePoolSize。
- maximumPoolSize:当阻塞队列填满时,如果线程池中线程数没有超过最大线程数,则会创建新的线程运行任务。否则根据拒绝策略处理新任务。非核心线程类似于临时借来的资源,这些线程在空闲时间超过 keepAliveTime 之后,就应该退出,避免资源浪费。
- BlockingQueue:存储等待运行的任务。
- keepAliveTime:非核心线程空闲后,保持存活的时间,此参数只对非核心线程有效。设置为0,表示多余的空闲线程会被立即终止。
TimeUnit:时间单位
TimeUnit.DAYS TimeUnit.HOURS TimeUnit.MINUTES TimeUnit.SECONDS TimeUnit.MILLISECONDS TimeUnit.MICROSECONDS TimeUnit.NANOSECONDSThreadFactory:每当线程池创建一个新的线程时,都是通过线程工厂方法来完成的。在 ThreadFactory 中只定义了一个方法 newThread,每当线程池需要创建新线程就会调用它。
public class MyThreadFactory implements ThreadFactory { private final String poolName; public MyThreadFactory(String poolName) { this.poolName = poolName; } public Thread newThread(Runnable runnable) { return new MyAppThread(runnable, poolName);//将线程池名字传递给构造函数,用于区分不同线程池的线程 } }RejectedExecutionHandler:当队列和线程池都满了时,根据拒绝策略处理新任务。
AbortPolicy:默认的策略,直接抛出RejectedExecutionException DiscardPolicy:不处理,直接丢弃 DiscardOldestPolicy:将等待队列队首的任务丢弃,并执行当前任务 CallerRunsPolicy:由调用线程处理该任务
线程池的运行过程
mysql的四个隔离级别
先了解下几个概念:脏读、不可重复读、幻读。
- 脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
- 不可重复读是指在对于数据库中的某行记录,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,另一个事务修改了数据并提交了。
- 幻读是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行,就像产生幻觉一样,这就是发生了幻读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务,不同的是不可重复读的重点是修改,幻读的重点在于新增或者删除。
事务隔离就是为了解决上面提到的脏读、不可重复读、幻读这几个问题。
MySQL数据库为我们提供的四种隔离级别:
- Serializable (串行化):通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。
- Repeatable read (可重复读):MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行,解决了不可重复读的问题。
- Read committed (读已提交):一个事务只能看见已经提交事务所做的改变。可避免脏读的发生。
- Read uncommitted (读未提交):所有事务都可以看到其他未提交事务的执行结果。
查看隔离级别:
select @@transaction_isolation;设置隔离级别:
set session transaction isolation level read uncommitted;dubbo的负载均衡策略
Dubbo提供了多种均衡策略,默认为Random随机调用。
Random LoadBalance
基于权重的随机负载均衡机制。
- 随机,按权重设置随机概率
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重
RoundRobin LoadBalance
基于权重的轮询负载均衡机制,不推荐。
- 轮循,按公约后的权重设置轮循比率
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上
LeastActive LoadBalance
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大
ConsistentHash LoadBalance
- 一致性 Hash,相同参数的请求总是发到同一提供者。(如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性hash策略。)
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
参考资料: https://blog.csdn.net/yjn1995...
java的动态代理
动态代理:代理类在程序运行时创建,在内存中临时生成一个代理对象,在运行期间对业务方法进行增强。
JDK实现代理只需要使用newProxyInstance方法:
static Object newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h )参数说明:
- ClassLoader loader:指定当前目标对象使用的类加载器
- Class[] interfaces:目标对象实现的接口的类型
- InvocationHandler h:当代理对象调用目标对象的方法时,会触发事件处理器的invoke方法()
以下是JDK动态代理Demo:
public class DynamicProxyDemo { public static void main(String[] args) { //被代理的对象 MySubject realSubject = new RealSubject(); //调用处理器 MyInvacationHandler handler = new MyInvacationHandler(realSubject); MySubject subject = (MySubject) Proxy.newProxyInstance(realSubject.getClass().getClassLoader(), realSubject.getClass().getInterfaces(), handler); System.out.println(subject.getClass().getName()); subject.rent(); }}interface MySubject { public void rent();}class RealSubject implements MySubject { @Override public void rent() { System.out.println("rent my house"); }}class MyInvacationHandler implements InvocationHandler { private Object subject; public MyInvacationHandler(Object subject) { this.subject = subject; } @Override public Object invoke(Object object, Method method, Object[] args) throws Throwable { System.out.println("before renting house"); //invoke方法会拦截代理对象的方法调用 Object o = method.invoke(subject, args); System.out.println("after rentint house"); return o; }}Spring哪里用到了动态代理?
Spring AOP 是通过动态代理技术实现的。
什么是AOP?
AOP,面向切面编程,作为面向对象的一种补充,将公共逻辑(事务管理、日志、缓存等)封装成切面,跟业务代码进行分离,可以减少系统的重复代码和降低模块之间的耦合度。切面就是那些与业务无关,但所有业务模块都会调用的公共逻辑。
动态代理的实现方式?
动态代理技术的实现方式有两种:
- 基于接口的 JDK 动态代理。
- 基于继承的 CGLib 动态代理。在Spring中,如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。
说一下CGlib动态代理
CGLIB(Code Generator Library)是一个强大的、高性能的代码生成库。其被广泛应用于AOP框架(Spring、dynaop)中,用以提供方法拦截操作。CGLIB代理主要通过对字节码的操作,为对象引入间接级别,以控制对象的访问。
CGLib 动态代理相对于 JDK 动态代理局限性就小很多,目标对象不需要实现接口,底层是通过继承目标对象产生代理子对象。
MQ如何保证消息不会丢失?
消息丢失场景:生产者生产消息到RabbitMQ Server消息丢失、RabbitMQ Server存储的消息丢失和RabbitMQ Server到消费者消息丢失。
消息丢失从三个方面来解决:生产者确认机制、消费者手动确认消息和持久化。以下实现以 RabbitMQ 为例。
生产者确认机制
生产者发送消息到队列,无法确保发送的消息成功的到达server。
解决方法:
- 事务机制。在一条消息发送之后会使发送端阻塞,等待RabbitMQ的回应,之后才能继续发送下一条消息。性能差。
- 开启生产者确认机制,只要消息成功发送到交换机之后,RabbitMQ就会发送一个ack给生产者(即使消息没有Queue接收,也会发送ack)。如果消息没有成功发送到交换机,就会发送一条nack消息,提示发送失败。
在 Springboot 是通过 publisher-confirms 参数来设置 confirm 模式:
spring: rabbitmq: #开启 confirm 确认机制 publisher-confirms: true在生产端提供一个回调方法,当服务端确认了一条或者多条消息后,生产者会回调这个方法,根据具体的结果对消息进行后续处理,比如重新发送、记录日志等。
// 消息是否成功发送到Exchangefinal RabbitTemplate.ConfirmCallback confirmCallback = (CorrelationData correlationData, boolean ack, String cause) -> { log.info("correlationData: " + correlationData); log.info("ack: " + ack); if(!ack) { log.info("异常处理...."); } };rabbitTemplate.setConfirmCallback(confirmCallback);Return消息机制
生产者确认机制只确保消息正确到达交换机,对于从交换机路由到Queue失败的消息,会被丢弃掉,导致消息丢失。
对于不可路由的消息,可以通过 Return 消息机制来处理。
Return消息机制提供了回调函数 ReturnCallback,当消息从交换机路由到Queue失败才会回调这个方法。需要将mandatory 设置为 true ,才能监听到路由不可达的消息。
spring: rabbitmq: #触发ReturnCallback必须设置mandatory=true, 否则Exchange没有找到Queue就会丢弃掉消息, 而不会触发ReturnCallback template.mandatory: true通过 ReturnCallback 监听路由不可达消息。
final RabbitTemplate.ReturnCallback returnCallback = (Message message, int replyCode, String replyText, String exchange, String routingKey) -> log.info("return exchange: " + exchange + ", routingKey: " + routingKey + ", replyCode: " + replyCode + ", replyText: " + replyText);rabbitTemplate.setReturnCallback(returnCallback);当消息从交换机路由到Queue失败时,会返回 return exchange: , routingKey: MAIL, replyCode: 312, replyText: NO_ROUTE。
消费者手动消息确认
有可能消费者收到消息还没来得及处理MQ服务就宕机了,导致消息丢失。因为消息者默认采用自动ack,一旦消费者收到消息后会通知MQ Server这条消息已经处理好了,MQ 就会移除这条消息。
解决方法:消费者设置为手动确认消息。消费者处理完逻辑之后再给broker回复ack,表示消息已经成功消费,可以从broker中删除。当消息者消费失败的时候,给broker回复nack,根据配置决定重新入队还是从broker移除,或者进入死信队列。只要没收到消费者的 acknowledgment,broker 就会一直保存着这条消息,但不会 requeue,也不会分配给其他 消费者。
消费者设置手动ack:
#设置消费端手动 ackspring.rabbitmq.listener.simple.acknowledge-mode=manual消息处理完,手动确认:
@RabbitListener(queues = RabbitMqConfig.MAIL_QUEUE) public void onMessage(Message message, Channel channel) throws IOException { try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } long deliveryTag = message.getMessageProperties().getDeliveryTag(); //手工ack;第二个参数是multiple,设置为true,表示deliveryTag序列号之前(包括自身)的消息都已经收到,设为false则表示收到一条消息 channel.basicAck(deliveryTag, true); System.out.println("mail listener receive: " + new String(message.getBody())); }当消息消费失败时,消费端给broker回复nack,如果consumer设置了requeue为false,则nack后broker会删除消息或者进入死信队列,否则消息会重新入队。
持久化
如果RabbitMQ服务异常导致重启,将会导致消息丢失。RabbitMQ提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重启RabbitMQ,消息也不会丢失。
消息持久化需要满足以下条件:
- 消息设置持久化。发布消息前,设置投递模式delivery mode为2,表示消息需要持久化。
- Queue设置持久化。
- 交换机设置持久化。
当发布一条消息到交换机上时,Rabbit会先把消息写入持久化日志,然后才向生产者发送响应。一旦从队列中消费了一条消息的话并且做了确认,RabbitMQ会在持久化日志中移除这条消息。在消费消息前,如果RabbitMQ重启的话,服务器会自动重建交换机和队列,加载持久化日志中的消息到相应的队列或者交换机上,保证消息不会丢失。
面经原贴来自牛客网,我自己整理的答案,有问题的小伙伴可以在评论区留言指出。