HDFS RBF模式RPC吞吐量瓶颈的优化探索
文章目录
- 前言
- RBF模式的RPC吞吐量问题原因猜想
- 网络延时的影响
- Router本身服务处理的影响
- Router和NameNode之间的通信问题
- Router的Handler异步化改造
- Router,NN之间的SASL加密过程的优化调整
- 参考资料
前言
之前笔者介绍过HDFS的RBF方案来解决HDFS NameNode单点瓶颈的问题。目前也是有越来有多的公司采用RBF的方案来做HDFS集群的统一管理。笔者在最近一段时间也是在调研RBF的特性同时也是测测这里面还有没有一些没有被发现的问题。在此期间,我和同事小伙伴发现里面最大的一个问题:上了RBF后,RPC的上限吞吐量比之前直连NN时降了非常之多。之前直连NN测试时,我们可以压到30k+的水准,在RBF模式下,这个数字只能到26.7k的样子。这里面性能差距在10%~20%之间。后续我们一直在尝试找里面的原因,最后发现是由于Sasl的加解密阶段导致的性能开销。但这其中的排查过程并不是那么简单,本文笔者就来聊聊这个问题的排查过程。
RBF模式的RPC吞吐量问题原因猜想
在RBF模式下,用户面对的直接服务是Router服务,而不是NN。所以用户的RPC请求,首先经过的是Router,然后再由Router转发到NN上去。简单来说,在RBF模式下,RPC的整个调用链路长了很多。这样很自然我们会有一种猜想:是否就是因为多了这一步的RPC请求转发,造成的RPC吞吐量的影响呢?
当然上面这个猜想说的还不是很具体,Router的这边的处理其实包含了许多细节的操作,里面每一中具体操作的延时都可能造成RPC的影响。这里如果展开来讨论的话,大致会有以下几类情况:
- Router的请求转发的网络延时造成的RPC吞吐量的下降(上面提到的这个猜想)。
- Router服务本身对RPC的处理造成的影响,比如Router做路径解析,构建connection等等操作。
- Router和NameNode之间的通信问题,增加RPC的开销。另外,这里也可能是NN的问题,比如下游NameNode callqueue被打满了导致处理的变慢。
下面我们逐一对上面的原因猜想做验证。
网络延时的影响
测试Router到NN的网络延时,办法很简单,登录Router,用ping命令测从Router到目标NN的网络延时。通过Ping命令,我们还能看到这过程里面是否存在丢包的情况。
后来,通过ping命令的测试,我们内部的Router到NN的延时只有0.01毫秒,这里面的延时基本上是可以忽略的。
Router本身服务处理的影响
在RBF模式中,Router主要做的一个事情是做PRC请求的路径解析以及转发功能。在这个过程中,它会做一些与底层NN的connection管理。Router内部在内部维护了一个connection pool的概念,来管理它与每个NN的请求连接。
那么我们如何知道Router在这块操作上的一个耗时情况呢?这里好在Router内部已经有相关的metric指标来统计这块的时间,如下图所示:

上面ProcessingAvgTime的意思就是指Router从接收刚刚接收client请求开始到转发往下游NN之前所消耗的时间。这里面包括了路径的解析,与下游NN的connection的建立等等操作。不过从上面metric值来看,这里面的耗时只有0.01ms左右,所在Router本身处理逻辑这块的开销其实也不大。
Router和NameNode之间的通信问题
如果说Router本身处理的时间没问题,那么还有一种情况是它和NN之间的通信问题,这个步骤可能会花比较长的时间。Router在RPC的处理过程中,会将请求转发给目标NN,然后拿到返回结果返回给客户端。这个metric指标如下所示:

上面Router的ProxyAvgTime表示的就是Router转发到底层NN然后再拿到执行结果的一个时间开销。我们能够看到,这里花的时间非常的长,高达几十毫秒。这里上面这个数据是在做压测时跑的数据,正常Router处理RPC请求的ProxyAvgTime还是比较低的。
ProxyAvgTime时间高的原因不能单纯下结论说就是下游NN处理慢了。我们在压测数据的时候,同时观察NN的callqueue情况,意外发现NN的callqueue只有在最开始的时候升高了一点点,后面callqueue积压长度一直为0.

这说明NN的处理能力完全是够的,因为如果是NN处理的慢了,后面的请求会积压在它的callqueue里面的。
于是这个时候,我们再次把目标转向了Router这边,是Router这边发请求的Handler被用满了,然后导致的请求发的少了?带着这个疑问,我们进行了后续的改进尝试。
Router的Handler异步化改造
从上面我们比较坚定地怀疑是Router里面的Handler的性能问题后。我们首先对它的Handler数据进行了增大,然后再进行数据的压测。我们将它的Handler数从64,128逐步往上升,但是发现到128后,几乎Router的QPS就上不去了,而且此时Router的QPS值和直连NN相比,还是有比较大的差异。
后来我们对Router进行了一个profile,想看看这些忙碌的Handler到底把时间都花在哪里了,火焰图结果如下:
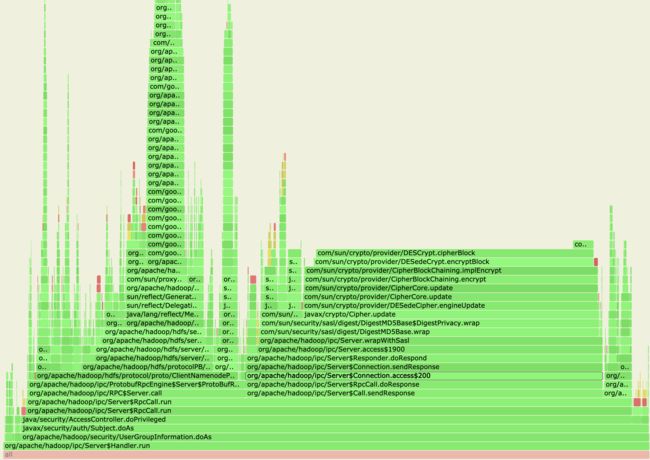
通过截取出Handler处理调用的部分火焰图来看,我们看到Handler很多时间都花在了RPC的response的返回阶段。而在返回阶段中,它又大部分时间花在了加密操作。RPC的response返回的处理也是在Handler资源里做的,如果因为繁重的response返回占住了有限的资源,那么必然它会影响到Handler去快速地接受更多的RPC来进行处理。
于是,我们首先进行了类似HDFS async editlog的改造,将它的返回结果处理从Handler处理中挪出来,放到另外的线程里独立处理,从而使得Handler资源能够提早释放出来。为了实现的简单性,我们挑了读类型操作getBlockLocations方法,对其进行了异步化response的改造。我们在这个方法里,拿到了当前处理的RPC,进行了postpone的方法处理。从后面测试的效果来看,改进的效果还是一般般。
这个时候,我们陷入了疑惑中,这里面的性能问题到底出在哪里呢?
Router,NN之间的SASL加密过程的优化调整
在经过了前面Handler的异步化调整之后,我们尝试再从profile结果中能够找到一些有用的线索。通过仔细观察,除了Handler部分占了比较多此处理时间外,还有另外2个部分也占据了Router比较多的处理时间,如下图红色区域:
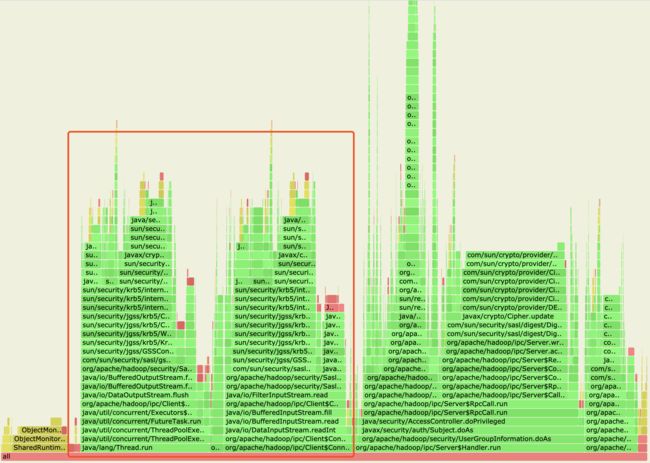
点开这2个区域的火焰图来看,profile结果如下:

我们看到上面的操作在做请求的加密操作,然后是在执行connection的run方法,我们大致可以猜测它表示的是Router在做往下游NN的请求转发操作,然后这个阶段在做RPC的加密操作。这里用的是SaslRpcClient。
然后我们接着来看它旁边区域的火焰图:
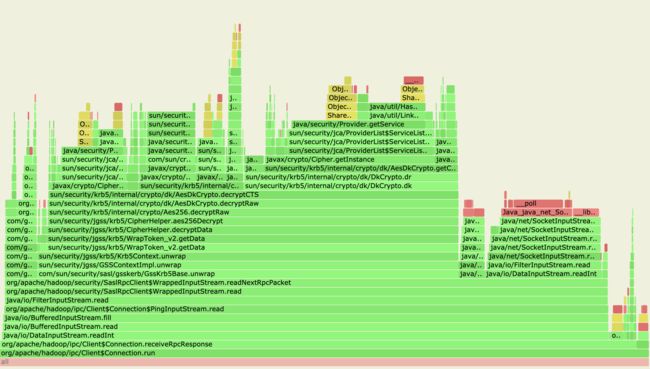
从上面火焰图我们看到,Router在做receiveRpcResponse操作,这里指的是它在做接受下游NN的返回结果的操作,然后这里面的主要耗时都在做response内容的解密操作。调用的对象同样是SaslRpcClient。
分析到这里,我们不免怀疑是否是这过程中的Sasl的加解密操作影响到了Router的RPC处理呢?如果我们想把这里面的加解密操作去掉,应该如何调整这里的Sasl认证机制?
后来经过对Hadoop Sasl认证的了解,Hadoop在内部使用了Sasl认证对RPC的通信做了保护,这个保护级别从低到高分别为authentication,integrity,privacy三个级别,3个级别的保护操作范围如下:
- authentication,只做认证
- integrity,做认证操作+数据完整性检查。
- privacy,做认证操作+数据完整性检查+数据的加解密。
然后笔者看了下我们内部集群的设置,我们是开了最高级别的privacy,因此在RPC的通信过程中,它会做请求的加解密操作。最高安全级别策略一方面带来了通信的安全性保证,另外一方面也是影响到了RPC的处理性能。
既然找到了问题的root cause后,我们在想如何在不影响NN和其它client之间的SASL认证级别的情况下,单独将NN和Router之间的SASL认证级别变为最低级别的authentication。后来我们采用了一个比较特殊的办法,通过新增特定的配置来控制NN和Router之间的rpc procetec设置。这样就不会break原先NN和其它client之间的SASL认证级别。
。在我们将NN和Router间的SASL保护级别调成authentication后,他们之间通信过程的加解密操作就不会进行了,从新的火焰图中可以明显看到这个变化:
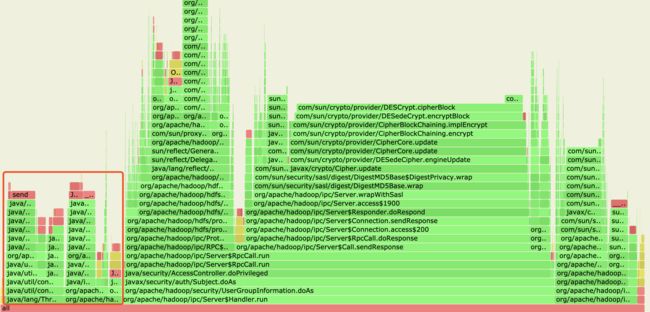
我们可以看到左边区域所占比例明显缩小,而且里面已经没有Sasl的加解密操作了,
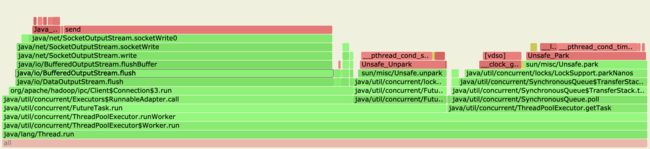

在上了这个优化改动后,在RBF模式下的RPC吞吐量已经和直连NN时的情况相差无几了,从测试结果来看,这个gap差距在5%以内。自此,前前后后耗时数月的时间,我们才真正解决了RBF的RPC吞吐量的问题。关于SASL认证对于NN的性能影响,感兴趣的同学可以阅读参考资料里的链接地址进行进一步的了解。
参考资料
[1]. https://tech.ebayinc.com/engineering/secure-communication-in-hadoop-without-hurting-performance/