Redis总结
文章目录
- 1.常见的5种数据类型
-
- 1.1string
-
- 1.1.1sds讲解
- 1.2list:双向链表
- 1.3hash
- 1.4set(存储大量数据)
- 1.5z_set(排序的set)
- 1.6bitmaps(位数组)
- 2.缓存问题
-
- 2.1.缓存雪崩
- 2.2缓存穿透
- 2.3缓存击穿
- 2.4布隆过滤器失效key
- 3.redis的三种缓存策略
-
- 3.1旁路缓存策略
- 3.2读写穿透策略
- 3.3异步缓存写入
- 3.4旁路缓存策略(提高)
-
- 3.4.1先写数据库,在删除缓存(推荐):
- 3.4.2先删除缓存,再写入数据库:
- 4.Redis单线程下的事务
-
- 4.1单线程
- 4.2事务
- 4.3watch命令
- 5.Redis持久化
-
- 5.1RDB
- 5.2AOF
- 5.3AOF重写
- 5.4比较
- 6.Redis的过期和缓存策略
-
- 6.1key的过期策略
- 6.2redis数据库的结构
- 6.3淘汰策略
- 7.Redis主从复制
-
- 7.1为什么需要?
- 7.2过程
- 7.3.心跳机制部分注意事项
- 8.Redis哨兵
-
- 8.1为什么需要?
- 8.2过程
- 9.Redis发布订阅模式
-
- 9.1典型场景
- 9.2redis命令
- 9.3源码
- 10.Redis的分布式集群
-
- 10.1redis的cluster?
- 10.2负载均衡算法
- 10.3分布式Session
- 10.4redis cluster(重点来了)
- 10.5补充,为什么槽的大小是16384,不是65536?
redis是基于c语言的一个开源的非关系型数据库!!!!单线程的
1.常见的5种数据类型
1.1string
set key value
常见场景:数据库分表的id值,以及计数器(string类型的incr和decr命令:自增),计数器:如微博的评论数、点赞数、分享数,抖音作品的收藏数,京东商品的销售量、评价数等。
1.1.1sds讲解
redis的string内部格式如下:
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
- 所以可以看到变量len,也就说明了我们获取长度为O(1)
- 并且也因为len,我们可以保存二进制文件,因为不在以/0为结尾判断,所以是Api安全;而c中的因为以/0为结尾判断,所以可能会丢失某些数据
- 另外,对append函数的优化,c来说每次就会重新分配内存,而sds优化后,当不足的时候也会重新分配,但是同时会将free = len,也就说明了扩大了一倍容量,下次append的时候就不用再次分配,当然会有一些空间的损失,但是因为append一般不是很大所以还好。
注:真实看源码就知道这些大佬的牛!!!
1.2list:双向链表
lpush key value
常见场景:朋友圈点赞的展示,像这种有序的。
1.3hash
hset key filed value
常见场景:购物车,即
{
顾客:
商品1:数量,
商品2:数量
}
1.4set(存储大量数据)
sadd key value
常见场景:不重复
共同好友的推荐、同类信息的关联检索
1.5z_set(排序的set)
zadd key score1 value
常见场景:
范围查找、访问量的统计排序。
1.6bitmaps(位数组)
getbit key offset
常见场景:
一般用于是否点赞等等,并且布隆过滤器也是用的其存储,还有像位图法:从一个大量的数据中,找到某一些值,我们可以利用为数组,某一位存储一个数,则内存量大大降低。
2.缓存问题
2.1.缓存雪崩
定义: 就是在同一时间内,有大量的key到期失效,所以都访问了数据库,从而导致数据库负载增加,甚至崩溃。
分析:
1)因为是同一时间段,大量的失效,说明可能是redis崩溃了或者是有大量的请求
2)或者是很多key设置的到期时间是差不多的
解决:
1.1)针对第一种,咱们可以设置集群来减轻redis服务器的压力。
1.2)针对第一种,还可以进行限流(限制客户端的连接数量):
- 1:计数器
一定时间内只能有10个客户端来进行连接,然后不断的计时。 - 2:令牌桶算法
java的定时任务也可以完成,简单思想就是:存在并维护一个list,加入一些值作为令牌,当有客户端来的时候,如果list有令牌,则可以进行访问;反之认为超出范围,拒绝访问。
比较:明显的来说,计时器关注时间,而令牌桶算法则关注连接量。
2)针对第二种,咱们可以对于其key的到期时间设置一个基础值+随机值,防止其同时到期。
2.2缓存穿透
定义: 访问大量的不存在的key,导致redis无法缓存,直接访问数据库,导致数据库访问量增大。
分析:
1)由于不存在的key,数据库没有,一般不会缓存
解决:
1)针对不存在的key,我们也缓存,但是必须设置一个到期时间,不然的话太浪费空间
2)布隆过滤器来解决:
- 思路:多个hash,bitmap
当一个key查询来的时候,不同的hash分别得到一个值,然后%,分别在bitmap的响应位查看是否是0/1,如果有一个是0,则直接认为不合法,而肯定会有一些错判,但是我们可以增加使用一些高效的hash或者增加bitmap的容量。
注意:可能会有个疑问,数据什么时候写入呢,应该是当往数据库插入的时候,以及同步到缓存后。

2.3缓存击穿
定义: 不同于缓存雪崩,其主要是大量请求同一个失效的key/同一条数据,而缓存雪崩是不同的key。
分析: 主要是key失效,还是热点key
解决方法:
1)明显的解决方法就是增加其时间,或者说设置key永不失效
2)还有个策略就是对热点key进行加锁,保证同一时间内只有一个客户端访问它。但是加锁明显会降低效率,所以一般要慎用。
2.4布隆过滤器失效key
- 其实对于redis实现的布隆过滤器,我们无法单独的让一个key失效,而真正的做法,expire key 0,只能说这样整体会失效
- 而对于一个值失效来说,我们需要自己手动实现一个布隆过滤器,这个布隆过滤器,在实现上要用一个计时器的功能,可以用Java自己模拟一个(简单说一下细节):
- 1.定义一个类
- 2.这个类有3-5个hash函数
- 3.声明一个hashmap
- 4.对于添加的每个数,进行hash函数生成,然后在hashmap的指定位置上,进行插入(数+个数)
- 5.对于查询每个数,同理进行hash函数生成,如果有一个数不存在(值为0),则不存在;反之,存在
- 6.对于删除一个数,同理进行hash函数生成,如果有一个数不存在(值为0),则不存在;反之,则在hashmap的指定位置上进行-1操作。
参考链接:
https://www.zhihu.com/question/399145557/answer/1270059584
3.redis的三种缓存策略
3.1旁路缓存策略
-
写:
1)先更新数据库
2)直接删除(应该是全部删除)
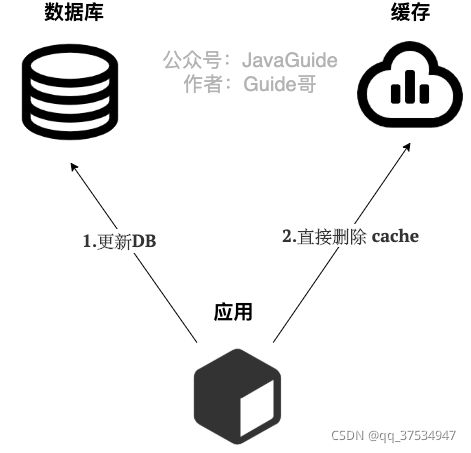
顺序不能变:
如果先删除cache,在修改数据库:
如果A删除了cache,B来拿数据库拿数据,此时A在修改数据库,就出现了缓存不一致问题
而先修改数据库,在删除cache也是有问题:
B先拿到数据库的数据,而此时A完成了写操作(更新数据库,删除cache),之后B才更新cache,也是会出现问题,但是一般来说缓存的写入是比数据库的写入快很多的。 -
读:
1)先从缓存中找,找到返回
2)找不到,上数据库找,找不到返回
3)数据库找到,返回,并把数据存到缓存中。

3.2读写穿透策略
上面的旁路缓存策略明显有一个问题,就是修改就会使得缓存失效,所以不适合写比较频繁:
而读写穿透策略:
- 写:
先查cache,cache存在,修改cache,然后cache同步更新数据库(即缓存和数据库同时及进行);
没有的话,直接更新数据库。
所以可以看到之前的缓存未失效。
- 读:
先查cache,cache存在,直接读取;
没有的话,从数据库加载到缓存中,然后写到cache中并返回。

注:但是有一个问题,就是如果多次写的话,则需要多次cache和数据库同时修改,而旁路缓存对于cache只修改一次,所以一般还是旁路缓存策略 + 一些方法。
3.3异步缓存写入
其实和上面读写穿透策略几乎一样,读是一样的,但是不同的是写:
1)当cache不存在,则直接更新数据库
2)当cache存在,更新缓存,但是不同时更新数据库,而是异步更新。
3.4旁路缓存策略(提高)
3.4.1先写数据库,在删除缓存(推荐):
缓存不一致问题:数据库更新成功后,但是缓存删除失败,则会导致缓存不一致的问题。
- 解决方案:消息队列
- 先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果。
- 缺陷:引入了消息队列,则必然有着更大的消耗,以及消息队列本身的问题。
3.4.2先删除缓存,再写入数据库:
缓存不一致问题:删除了缓存,还没来得及更新数据库,线程B读取的是旧的数据,然后保存缓存,仍会出现缓存不一致问题
- 解决方案:延时双删
- 删除缓存,写入数据库后,sleep后一段时间,再次删除缓存。sleep的时间一般大于线程2读数据+写缓存的时间。
参考链接:
https://blog.csdn.net/qq_41884972/article/details/113883886?utm_term=Redis%E6%97%81%E8%B7%AF%E7%BC%93%E5%AD%98%E6%A8%A1%E5%BC%8F&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allsobaiduweb~default-4-113883886&spm=3001.4430
4.Redis单线程下的事务
4.1单线程
Redis是单线程的,当然高版本是多线程的(6.0,就不考虑了),为什么设计成单线程,主要是:因为其是内存型数据库,所以其瓶颈不在cpu,而真正的在于网络的IO,所以单线程下也利用了IO多路复用来解决客户端和服务端之间的网络传输延迟。
4.2事务
虽然是单线程的,但是仍会有并发问题,因为会有多个请求,所以在处理的时候不同的请求A、B可能在处理上会有交互,所以会有问题,所以仍需要事务:
multi
set xx xx
get xxx
exec/discard
事务在exec的那一时刻,保证了set、get命令的原子执行,所以不会出现问题,当然可以用discard撤销事务。
注:另外比较重要的是,redis的事务不支持归滚,因为设计之初,对于事务出现错误主要就是程序员的编码问题,所以这需要自己回滚(所以我们写的时候要注意);当然对于一些编码错误,如:set set这种语法错发,会全部失败,但是如果出现:set key 1,2 把lpush的语法弄过来的话,则其他正确会继续执行,所以不会回滚,记住不能回滚(就是出现错误,不全部失败)。
4.3watch命令
为保证事务执行前,某个key不变化,在watch的一瞬间其值就不能变了,当你exec的时候,发现监控的监控的值进行了操作,则认为不安全,事务失败。
5.Redis持久化
5.1RDB
RDB持久化方式:是将当前内存中的所有缓存进行保存,所以明显其保存效率低,但是恢复速度是比较快的。
- 命令:save second changes //在多少s时间内有多少次变化,就会执行
- 方式:当前进程fork子进程进行异步的保存
5.2AOF
AOF持久化方式:保存所有的命令(当然只涉及修改),其保存速度快,但是恢复速度慢,需要一步步的执行。
三种方式:
- always:只要有修改命令,就会追加到aof文件
- everysec:有1s的缓存,将这1s的数据进行保存到aof(推荐)
- no:操作系统自己玩(不推荐)
5.3AOF重写
因为涉及到许多命令,但是很有可能许多都没有了:
- 一条语句多次set;只需要最后一次set
- lpush key a lpush key b----lpush key a b
- 已过期的key
作用:降低磁盘的容量;恢复的时候更加快。
5.4比较
可以看到一般RDB用于主从复制,作为备份(全量复制);而AOF一般用于对数据比较敏感的,像everysec最多只有1s的数据损失,而RDB一般最后一次的损失挺大的。另外RDB保存慢,但是恢复快;而AOF相反;并且两者都是开启子进程进行异步操作的。
6.Redis的过期和缓存策略
6.1key的过期策略
- 命令:setex key value second(只有string); set w3ckey value;EXPIRE w3ckey 60
- 对于一些过期的key,如果操作,分为三种:
- 1.定时删除:到期就删除,明显会吃紧cpu,对内存友好
- 2.惰性删除:知道再次使用的时候,在删除,对cpu友好,对内存不友好
- 3.定期删除:每xx秒进行一次serverCron()
对每个redis数据库的expires[x],进行随机选择W个key,如果key过期就删除;如果最后删除的大于W*25%,那就继续循环,否则进行下一个数据库的expires[x]扫描. - 一般redis使用惰性删除和定期删除结合,因为定期删除可能会有一些过期的一直没有删除(随机性导致的)
6.2redis数据库的结构
redis数据库本身存储的就是key - value,其实内部还有一个东西叫expires,而这个expires主要保存的是:每个key的value地址以及对应的到期时间,所以主要是保存设置到期时间的key
6.3淘汰策略
类似于操作系统的页面置换,我们要把没用的删除:
- 对expires的删除
- 1:volatile-lru
- 2:volatile-lfu
- 3:voliate-random
- 4:volatile-ttl
- 对all-key的删除
- 1:allkeys-lru
- 2:allkeys-lfu
- 3:allkeys-random
- 不进行任何操作的删除
- no-enviction(报错)
注:其中lru,是最近最久未使用算法;lfu是最近不常用的算法;类似于操作系统,简单说一下:LRU:对已存在的某些key,进行往前查找,谁用的最早就删除;LFU:在给定的一段时间内,谁用的频率越少,就删除谁。
7.Redis主从复制
7.1为什么需要?
主从复制的原因可以从这几个方面看一下:
1)读写分离,分担一个redis数据库的压力,主节点主要是写,然后同步到从节点,从节点主要负责读
2)数据备份,是持久化的另一种数据保存
3)故障恢复,当主节点凉凉的时候,可以选择一个从节点作为主节点
7.2过程

主要分为三步:
- 建立连接
从节点和主节点进行连接,从节点保存主节点的ip+端口;主节点保存从节点的端口;
主要是建立的socket连接,内部包含一些授权操作。 - 数据同步
主要分为两步:
2.1)全量复制
- 从节点发送psync2指令;
- 主节点执行bgSave指令,保存RDB文件
- 同时记录runid + offest
- 将上面的RDB、offset、runid发送给从节点
- 从节点进行恢复RDB
2.2)增量复制
- 从节点再次发送指令psync2 runid offset 指令
- 主节点判断自身的offset > offset(slave)
- 将这部分的内容 + offset 发给从节点
- 从节点收到这些命令进行bgwriteaof,进行恢复数据,并保存新的offset(slave) - 命令传播(心跳机制)
这部分其实就是 增量复制的过程,只是中途可能出现主从节点的一个网络问题,导致重新进行第二步的数据同步:
-主节点每10s发送ping 指令来判断从节点是否在线
-而从节点每1s发送 ** replconf ack{offset}**指令,进行判断主节点是否在线,以及增量复制
-增量复制(完整版)
1:主节点判断从节点的runid和offset
2:如果runid不同,直接全量复制
3:如果offset(slave)不在slave,全量复制
4:当offset(slave) = offset(master),不发送
5:当offset(slave)!= offset(master),发送offset(master)和中间部分的内容
7.3.心跳机制部分注意事项
当slave多数掉线 + 延迟过高,则master则会拒绝同步
如:slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
8.Redis哨兵
8.1为什么需要?
接着上篇的主从复制,我们直到主从复制如果主节点宕机后,我们需要人工的选择一个从节点代替它,所以不免有些费劲,所以哨兵为我们解决了这个问题,它会监控所有的主从节点,当主节点挂了后,由其自动选,自动恢复!!
8.2过程
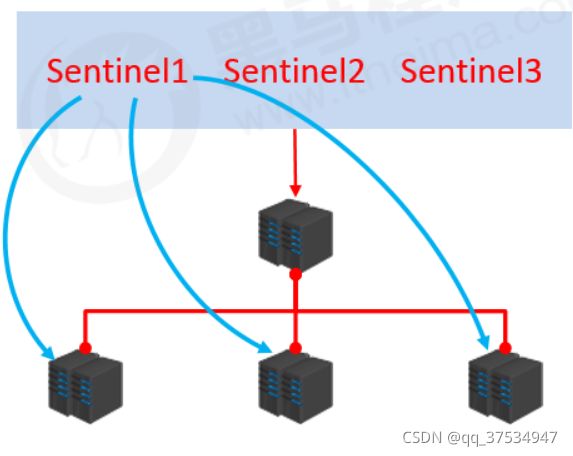
主要分为三个阶段:
1.监控阶段
不断的检查主从节点是否正常运行(连接过程)
- 所有的哨兵服务器,之间是发布订阅模式,并且所有的哨兵订阅者主节点(因为主节点包含从节点的信息,所以也可以认为一直监控着主节点、从节点)
2.通知阶段
当哨兵向主从节点发送ping指令的时候,然后将收到的消息(正常)全部在哨兵中进行同步。
3.故障转移阶段
- 主观下线
当哨兵向主从节点发送ping指令的时候,发现主节点下线,标记为主观下线 - 客观下线
有一半的哨兵发现主节点下线,此时为客观下线 - 哨兵竞选
所有的哨兵同时作为参选者和投票者进行竞选 - 选新的主节点
选出的哨兵选一个从节点作为新的主节点,其中其向新的主节点发送slave 命令,向其他从节点以及原来的主节点发送命令告诉他们新的主节点的ip + 端口
注意:在选从节点的时候,也是有策略,一般选在线的、响应快的等等。
9.Redis发布订阅模式
9.1典型场景
邮件发送:100个人订阅了一个人,而这个博主发送了一个博客, 那么这100个人都会收到
读写分离场景:保证在写入的同时,进行同时的分发到各个从节点(读)的中
9.2redis命令
1.subscribe(订阅一个通道/多个通道)
- 用法:subscribe channel [channel]

2.publish(向指定通道发布消息)
- 用法:publish channel msg
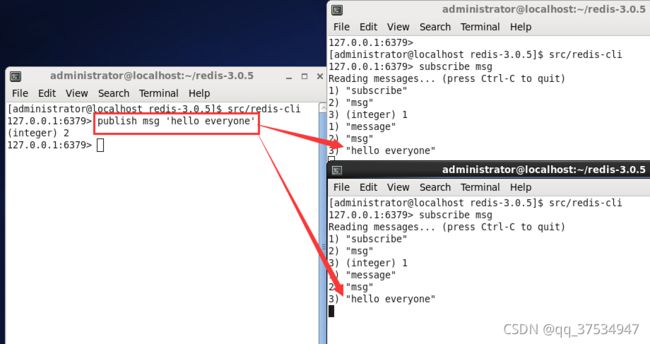
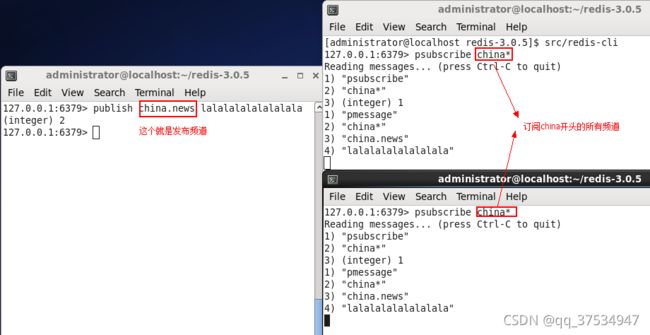
3.psubscibe(模糊订阅通道)
- 用法:psubscribe chan*
9.3源码
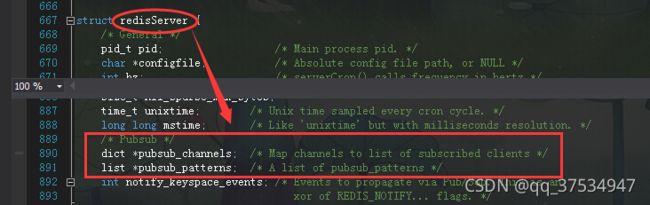
注:
pubsub-channels 字典{
key:channel
value:[client1、client2]
}
pubsub_patterns: [client1、client2] //模糊匹配的客户端/订阅者

结果:发布者发布消息的的时候,会获取当前通道的所有的客户端,然后通过addReply函数发布给每个客户端;那个模糊订阅同理;对于addRpely函数目前就不探讨了!!!!!
参考链接:
https://blog.csdn.net/weixin_33795093/article/details/85743750?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163067045716780264085192%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163067045716780264085192&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v29-1-85743750.pc_search_result_cache&utm_term=redis%E5%8F%91%E5%B8%83%E8%AE%A2%E9%98%85&spm=1018.2226.3001.4187
10.Redis的分布式集群
10.1redis的cluster?
- 分散一台服务器的访问压力,将数据分散在不同的数据库服务器,实现负载均衡
- 分散一台服务器的存储压力
- 容易实现可扩展性
10.2负载均衡算法
- CRC16:(了解)
g(x)=1·x8+0·x7+0·x6+1·x5+1·x4+0·x3+0·x2 +0·x1+1·x0,即对应的二进制数为100110001;
每一位 - 轮询
- 加权轮询
- 随机
- hash(ip)
10.3分布式Session
上面讲到了hash(ip),这里就说一下,对于分布式来说,我们要保证分布式session的实现:
- hash(ip):保证一台主机一直访问一台服务器
- 共享session:维护一个session服务器库,所有的服务器都从这里取
- 同步session:所有的服务器,只要一个修改,其他的都要同步。
10.4redis cluster(重点来了)

客户段请求的key,经过CRC16得到一个值,然后对16384取余,来决定放置到哪个槽,每个节点负责一部分的槽,如:

两次寻址过程:
- 1 当前的节点通过crc16进行计算,如果是自己则进行执行
- 2 如果不是自己,返回错误Moved,然后告诉他哪个节点找
- 3 注意的是每个数据库会维护一部分槽slot,并且节点之间知道每个节点的slot的部分范围
-
10.5补充,为什么槽的大小是16384,不是65536?
- 在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K),也就是说使用2k的空间创建了16k的槽数。
- 虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包,
作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
综合来说:就是进行hash槽信息的同步的时候,保证发送的信息量少,并且一般不会超过1000个节点(一般不超过1000个也说明节点数不能太多,所以16384够用了!)
参考链接:
https://www.jianshu.com/p/de268f62f99b