8.7 Meta learning元学习全面理解、MAML、Reptile
文章目录
-
- 1、介绍
-
-
- 为什么需要元学习?
- few-shot learning
- reinforcement learning
-
- 2、概念
- 3、 Meta learning 三个步骤
-
- 定义一组learning algorithm
- 损失函数
- 寻找最好的F
- 4、元学习过程总结
-
- 元学习task定义
- 5、Meta Learning实例:Omniglot
-
- N-way K-shot
- 参数初始化
- 6、MAML
-
- 目标函数
- MAML vs transfer learning
- MAML的训练
- MAML Toy Example
- 算法
- 梯度数学推导
- 真正的实现
- MAML 应用:Translation
- 7、Reptile
-
- 梯度更新过程
-
- 训练过程
- 8、More about Meta Learning
- 参考资料
8.7 Meta learning元学习全面理解、MAML、Reptile
8.8LSTM作为元学习器学习梯度下降
1、介绍
元学习Meta learning = 学习如何去学习Learn to learn
为什么需要元学习?
传统深度学习需要大数据,因为使用随机梯度下降更新参数,需要数据进行缓慢地学习。当遇到新数据时,模型必须低效地重新学习它们的参数,以便在不产生灾难性干扰的情况下充分整合新信息。
但是人类在很少的样本学习——例如,一个孩子可以从一本书中的一张图片概括出“长颈鹿”的概念。这激发了我们的兴趣:“one-shot”学习,即从一个单一的例子中学习,和few-shot 学习 即从小样本中学习,和zero-shot 学习 即零样本中学习。这些都和元学习有关,元学习是快速学习的算法。
元学习是对模型的一种研究与学习。相对于deep learning在一个task(任务)中通过对样本的学习以对新样本做出判断,元学习的目标可以看做是将task视作样本,通过对多个task学习元知识和快速学习的能力,以使元模型(meta-learner)能够对新的task做出快速而准确的预测。它研究的不是如何提升模型解决某项具体的任务(分类,回归,检测)的能力,而是研究如何提升模型解决一系列任务的能力。

举个例子就是,机器之前学习了100个task,之后机器学习第101个task的时候,会因为之前学习的100个task所具有的知识,而让第101个task表现得更好。比如说第一个任务是语音识别,第二个任务是图像识别,第一百个任务是文本分类,机器因为之前所学到的任务,所以在后面的任务学习的更好。
这个和life long learning有什么区别吗!好像很像诶。确实,life long learning和meta learning都是要根据以往的task,希望对现在的task有所帮助,但是meta learn所要求的是学习新的task时候有新的model(训练后的),但是life long learning始终是一个模型。
和Life-long方法有所不一样:
| 方法 | 区别 |
|---|---|
| Life-long | 一个模型适用于所有任务 |
| Meta | 如何学习一种新的模型 |
few-shot learning
few-shot learning——小样本学习,是指通过极少的样本学习获得(监督/非监督)回归、分类模型。在现有的研究成果中,小样本学习可以基于fine-tune、metric(如孪生网络)、基于meta-learning等。在基于meta-learning的少样本学习中,已有memory-augmented neural networks (Santoro et al., 2016)、meta-learner LSTM (Ravi & Larochelle, 2017)等经典学习方法。
小样本学习一直和元学习系紧密。元学习的目标就是通过学习大量的task ,从而学习到内在的元知识,从而能够快速的处理新的同类任务,这和少样本学习的目标设定是一样的。我们也希望通过很多task来学习识别物体这种能力,从而面向新的少样本学习任务,能够充分利用已经学习到的识别能力(也就是元知识),来快速实现对新物体的识别。而在这里,通过前面的分析,我们明白了,我们要研究如何通过元学习的方式来让神经网络学会比较这个元知识能力。
reinforcement learning
相比于深度学习,强化学习的训练样本没有标签,是通过环境与决策的奖惩政策来进行学习。强化学习的过程是动态的,强调与环境进行交互,其优势在于解决决策问题,如推荐系统等。在本文中,MAML不仅可适用于few-shot learning,也同样适用于强化学习。
2、概念

机器学习:用Training Data训练由我们设计的Learning Algorithm,得到一个最优算法 f ∗ f^* f∗ ,可以用来完成相应的任务(猫狗识别)

meta learning方法是:依旧给模型很多训练数据,我们将Learning Algorithm当作是一个 F F F(function),我们需要 F F F做的事生成另一个 f ∗ f^* f∗(function),而这个f可以用来做影像识别。我们meta learning的方法就是找到 F F F。

Machine Learning ≈ 根据数据找一个函数 f 的能力
meta learning:用 D t r a i n D_{train} Dtrain 训练由我们设计的F,得到一个完成相应任务的 f ∗ f^* f∗函数 ,怎么感觉和上面没什么区别?
其实不一样,Meta Learning≈ 根据数据找一个找一个函数 f 的函数 F 的能力。 F F F的输入是训练数据,输出是解决一个小问题的 f f f,即
f ∗ = F ( D train ) \large \color{green}{f^{*}=F\left(D_{\text {train }}\right)} f∗=F(Dtrain )
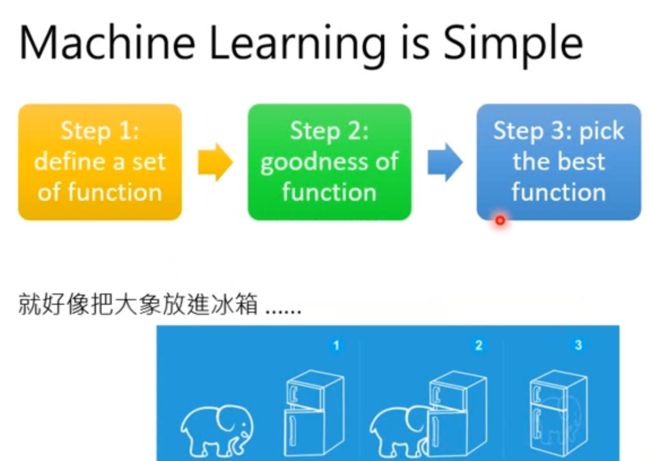
机器学习中是知道函数 f f f,而是训练函数f的参数;机器学习的方法可以简单理解为三步:
-
定义一个function 集合
-
找到一个 f f f好坏的度量指标(loss function)
-
在这个集合中寻找最好的 f f f

元学习是不知道函数 f f f,而是训练函数F找到 f f f(含参数)。
我们meta learning的方法和machine learning的方法是十分相似的,也是三步:
-
定义一组learning algorithm F F F的集合,
-
定义一个判别learning algorithm 好坏的方法
-
找一个最好的learning algorithm做为 F F F。
3、 Meta learning 三个步骤
定义一组learning algorithm
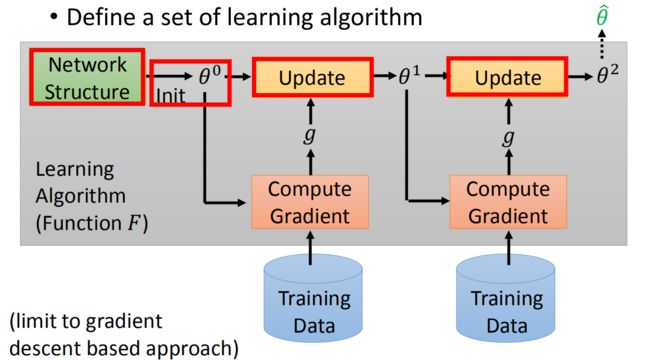
首先,看看如何设置一个learning algorithm set。先来看机器学习中是如何进行learning algorithm的。以基于GD优化的算法为例,先是定义了一个神经网络结构,之后初始化参数值,之后根据训练数据计算梯度,更新参数,图中的每一步的gradient g g g其实不一样,最后得到最优的参数。
红色的格子都是人为设定的,网络结构的选择,参数的初始化,参数更新的方法,都是人为设计的,红框中如果我们定义不同的东西,实际上就是不同的算法。
那么这些部分能否是机器自己设计呢!我们参数的初始值能不能让机器自己初始化呢!假设机器自己初始化参数,机器自己选择参数更新方法,机器自己选择神经网络结构,这就是我们meta learning的learning algorithm set。
Meta Learning 就是把这些 人为设定的模块由机器自行设计,使网络有更强的学习能力和表现。
损失函数
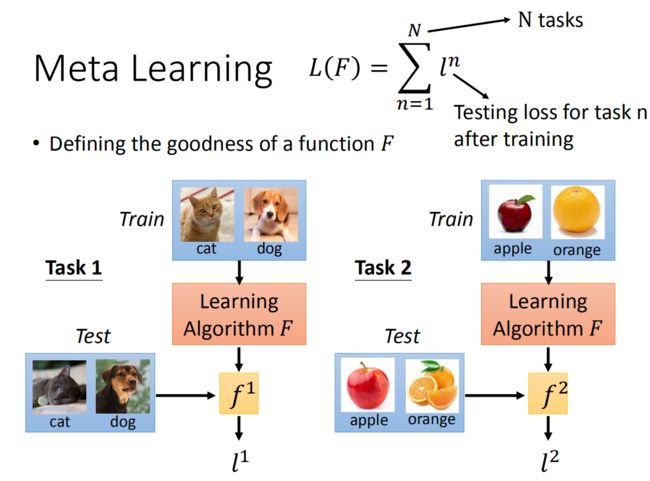
这个过程的损失函数:比如我们用一个learning algorithm F F F。首先用 F F F进行猫狗分类器的学习,之后得到了一个 f 1 f^1 f1, f 1 f^1 f1的训练数据进行测评,得到 f 1 f^1 f1的loss function l 1 l^1 l1。之后再用 F F F进行苹果橘子分类器的学习,得到一个 f 2 f^2 f2, f 2 f^2 f2的训练数据进行测评,得到 f 2 f^2 f2的loss function l 2 l^2 l2。
这里用 F F F完成n个分类task,之后对每一个task求一个 l l l。之后我们把所有的 l l l都加在一起,就变成了我们最后的损失函数 L ( F ) L(F) L(F)。我们就是使用 L ( F ) L(F) L(F)来评估F的。
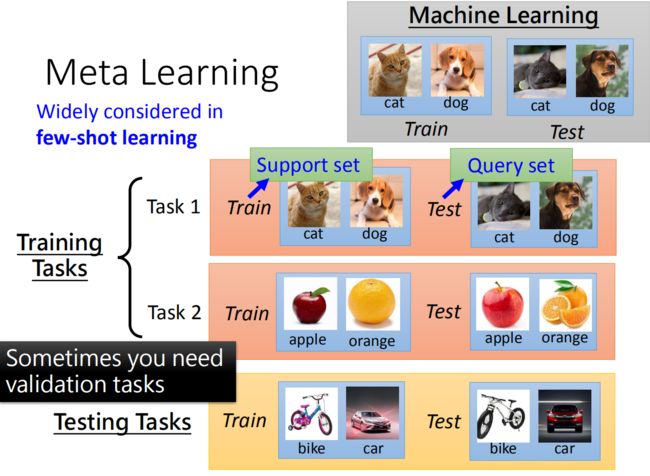
从这里可以看到机器学习和元学习在数据上不一样。一般的机器学习任务是单任务的,所以数据集是一堆训练数据,和测试数据。但是在meta learning的任务是多任务的,所以在这种情况下,我们需要做的是将很多的任务分为训练任务和测试任务,之后每一个小的任务都有训练数据和测试数据。比如说一共有十个任务,我们将其中的八个作为是训练任务,剩余的两个作为测试任务,其中每一个任务都有自己的测试数据和训练数据。以此来检测meta learning的学习能力。
这里要说明:
- 由于元学习有多个任务,每个任务如果有很多数据,那么训练时间会很长很长,因此,元学习中每个任务的数据不会很多,所以元学习也叫few-shot learning,为了和机器学习区分开,训练和测试数据分别叫Support set和Query set。
- 和机器学习一样,当我们的元学习中的训练任务很多的时候,我们可以将其中一部分切出来作为验证任务:validation tasks。
- 元学习中的testing task可以和training task一样,也可以不一样。
寻找最好的F

meta learning损失函数,就是 L ( F ) L(F) L(F),其实就是每一个训练子任务loss function总和。之后我们用梯度下降的方法不断的更新 F F F的参数,得到一个最好的 F ∗ F^* F∗,之后我们将训练好的 F ∗ F^* F∗放入到测试任务集中进行测试,如图,比如第一个测试任务是一个自行车汽车识别器,我们先将少量训练数据放入到 F ∗ F^* F∗中,之后得到一个分类器 f ∗ f^* f∗,之后我们将测试数据放入到 f ∗ f^* f∗中,得到最终的loss,作为这次测试的结果。
4、元学习过程总结
设 X \mathcal{X} X为输入的空间, 和 Y \mathcal{Y} Y是一个离散的标签空间。设 D \mathcal{D} D为 X × Y \mathcal{X} \times \mathcal{Y} X×Y的分布。监督机器学习通常旨在通过对参数化模型和训练集应用学习算法捕获条件分布 p ( y ∣ x ) p(y \mid x) p(y∣x), S train = S_{\text {train}}= Strain= { ( x i , y i ) ∼ D } i = 1 N . \left\{\left(x_{i}, y_{i}\right) \sim \mathcal{D}\right\}_{i=1}^{N} . { (xi,yi)∼D}i=1N.在推理时,模型在测试输入 x x x上进行评估,以估计 p ( y ∣ x ) p(y \mid x) p(y∣x)。推理和学习算法的组合可以写成函数 h h h(一种分类算法)以训练集作为输入,还有测试时输入 x x x,并在标签上输出估计概率分布 p ^ \hat{\mathbf{p}} p^:
p ^ ( x ) = h ( x , S train ) \large \color{green}{\hat{\mathbf{p}}(x)=h\left(x, S_{\text {train }}\right)} p^(x)=h(x,Strain )
在few-shot学习中,我们希望函数 h h h即使在 S train S_{\text {train}} Strain很小的情况下也具有较高的分类精度。Meta learning是一个涵盖了许多提出的经验风险最小化方法的术语。具体来说,他们考虑了参数化分类算法 h ( ⋅ , ⋅ ; w ) h(\cdot, \cdot;\mathbf{w}) h(⋅,⋅;w),并尝试估计一个“好的”参数向量 w \mathbf{w} w,即对应于一个可以很好地从小数据集学习的分类算法。因此,学习这个参数向量可以理解为元学习。
因此学会获取元知识能力的方法有三种:
- 特定的网络结构
- 改变网络的初始化参数
- 参数更新的方法
元学习的目标是针对任务训练而不是数据点。每个任务 T i \mathcal{T}_{i} Ti 都是独立的,其输入为 x t x_{t} xt,输出为 y t y_{t} yt,损失函数是 L i ( x t , y t ) \mathcal{L}_{i}\left(x_{t}, y_{t}\right) Li(xt,yt),一个转移分布 P i ( x t ∣ x t − 1 , y t − 1 ) P_{i}\left(x_{t} \mid x_{t-1}, y_{t-1}\right) Pi(xt∣xt−1,yt−1),任务大小 H i H_{i} Hi .一个元学习器建模分布: π ( y t ∣ x 1 , … , x t ; w ) \pi\left(y_{t} \mid x_{1}, \ldots, x_{t} ; \mathbf{w}\right) π(yt∣x1,…,xt;w). 给定任务的分布 T = P ( T i ) \mathcal{T}=P\left(\mathcal{T}_{i}\right) T=P(Ti), 元学习者的目标是使 w \mathbf{w} w的预期损失最小化。
min w E T i ∼ T [ ∑ t = 0 H i L i ( x t , y t ) ] where x t ∼ P i ( x t ∣ x t − 1 , y t − 1 ) , y t ∼ π ( y t ∣ x 1 , … , x t ; w ) \large \color{green}{\begin{aligned} \min _{\mathbf{w}} & \mathbb{E}_{\mathcal{T}_{i} \sim \mathcal{T}}\left[\sum_{t=0}^{H_{i}} \mathcal{L}_{i}\left(x_{t}, y_{t}\right)\right] \\ \text { where } x_{t} & \sim P_{i}\left(x_{t} \mid x_{t-1}, y_{t-1}\right), y_{t} \sim \pi\left(y_{t} \mid x_{1}, \ldots, x_{t} ; \mathbf{w}\right) \end{aligned}} wmin where xtETi∼T⎣⎡t=0∑HiLi(xt,yt)⎦⎤∼Pi(xt∣xt−1,yt−1),yt∼π(yt∣x1,…,xt;w)
元学习器通过优化从 T \mathcal{T} T中采样的任务(或小批任务)的预期损失来进行训练。在测试过程中,对元学习者进行没遇见过的任务评估,这些任务来自不同的任务分布 T ~ = P ( T ~ i ) \widetilde{\mathcal{T}}=P\left(\widetilde{\mathcal{T}}_{i}\right) T =P(T i),与训练任务分布 T \mathcal{T} T类似。
元学习算法有两个阶段。第一阶段是元训练,估计分类算法的参数向量 w \mathrm{w} w。
- 在元训练过程中,元学习器可以访问一个大型标记数据集 S meta S_{\text {meta}} Smeta,该数据集通常包含大量类的数千张图像 C C C . 在元训练的每次迭代中,元学习器从 S meta S_{\text {meta}} Smeta中抽取一个分类问题样本。也就是说,元学习器首先从 C C C中抽取 m m m类的子集,然后抽取小的"training" 集合 S train S_{\text {train }} Strain 和小的"test" 集合 S test . S_{\text {test }} . Stest .
- 然后,它使用当前的权重向量 w \mathbf{w} w来计算条件概率 h ( x , S train ; w ) h\left(x, S_{\text {train}};\mathbf{w}\right) h(x,Strain;w)用于测试集 S test S_{\text {test}} Stest中的每一个点 ( x , y ) (x, y) (x,y)。注意,在这个过程中, h h h可能执行相当于对 S train S_{\text {train}} Strain进行“training”的内部计算。根据得到的预测, h h h会对于当前 S test S_{\text {test}} Stest 中的每个点造成损失 L ( h ( x , S train ; w ) , y ) L\left(h\left(x, S_{\text {train }} ; \mathbf{w}\right), y\right) L(h(x,Strain ;w),y) 。
- 然后元学习器反向传播总损失的梯度 ∑ ( x , y ) ∈ S test L ( h ( x , S train ; w ) , y ) \sum_{(x, y) \in S_{\text {test }}} L\left(h\left(x, S_{\text {train }} ; \mathbf{w}\right), y\right) ∑(x,y)∈Stest L(h(x,Strain ;w),y)。每次迭代的类数 m m m和每个类的最大训练样本数 n n n是超参数。
第二阶段是元测试阶段,将生成的分类算法用于解决新的分类任务:对每个新任务,分别给出有标记的训练集和未标记的测试示例,分类算法输出类概率。
元学习task定义
元学习的论文中多次出现名词task,模型的训练过程都是围绕task展开的,要正确地理解task,我们需要了解的相关概念包括 D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train , D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test, support set, query set, meta-train classes, meta-test classes等等。
我们假设这样一个场景:我们需要利用元学习算法训练一个数学模型模型 M f i n e − t u n e M_{fine-tune} Mfine−tune ,目的是对未知标签的图片做分类。
D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train 含有10个类别的图片 C 1 ~ C 10 C_1~C_{10} C1~C10 即meta-train classes(每类30个已标注样本),用于帮助训练元学习模型 M m e t a M_{meta} Mmeta 。
D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test含有 5个类别数据 P 1 ~ P 5 P_1~P_5 P1~P5 即meta-test classes(每类5个已标注样本用于训练。另外每类有15个已标注样本用于测试),注意这里的数据和 D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train不一样,即未知标签的图片,是用于训练和测试 M f i n e − t u n e M_{fine-tune} Mfine−tune 的数据集。
训练过程,元学习者首先利用 C 1 ~ C 10 C_1~C_{10} C1~C10 的数据集训练元模型 M m e t a M_{meta} Mmeta,再在 P 1 ~ P 5 P_1~P_5 P1~P5的数据集上精调(fine-tune)得到最终的模型 M f i n e − t u n e M_{fine-tune} Mfine−tune 。我们的实验设置为5-way 5-shot。
根据5-way 5-shot的实验设置,我们在训练 M m e t a M_{meta} Mmeta 阶段,从 C 1 ~ C 10 C_1~C_{10} C1~C10 中随机取5个类别,每个类别再随机取20个已标注样本,组成一个task T {\mathcal T} T 。其中的5个已标注样本称为 T {\mathcal T} T 的support set,另外15个样本称为 的** T {\mathcal T} Tquery set**。这个task T {\mathcal T} T , 就相当于普通深度学习模型训练过程中的一条训练数据。那我们肯定要组成一个batch,才能做随机梯度下降SGD对不对?所以我们反复在训练数据分布中抽取若干个这样的task T {\mathcal T} T ,组成一个batch。在训练 M f i n e − t u n e M_{fine-tune} Mfine−tune 阶段,task、support set、query set的含义与训练 M m e t a M_{meta} Mmeta 阶段均相同。
5、Meta Learning实例:Omniglot
N-way K-shot
N-way K-shot是few-shot learning中常见的实验设置。few-shot learning指利用很少的被标记数据训练数学模型的过程,这也正是MAML擅长解决的问题之一。N-way指训练数据中有N个类别,K-shot指每个类别下有 K K K个被标记数据。
既然 Meta Learning 是 learn to learn,那么如何证明 Meta Learning 算法的有效性呢?显而易见,只需要证明用这种算法得到的网络模型学习能力很强就行了。具体到我们的 MAML 和 Reptile,只需要证明,用它们这些算法初始化之后的神经网络,在新的任务上训练,其收敛速率与准确率比从随机初始化的神经网络要高。
这里所谓“新任务”,一般是指难度比较大的任务,毕竟难度大的任务才有区分度嘛,要是都像 MNIST 数据那么简单,随便一训练就 99% 的准确率,也看不出网络初始化参数所起的作用了。因此一般用 few-shot learning 的任务来评估 Meta Learning 算法的有效性。所谓 few-shot learning,就是指每类只有少量训练数据的学习任务(MNIST 每个数字都有上万张训练图片,因此不是 few-shot learning)。数据集 Omniglot:,是一个类似 MNIST 的手写数据集,如下图所示。该数据集包含 1623 类,每类只有 20 个训练数据,因此它属于 few-shot learning 的范畴,经常作为 benchmark 用来衡量 Meta Learning 算法的性能。
https://github.com/brendenlake/omniglot
• 1623 characters,部分字符:

每一个字符有20个例子,20个例子都是这个标签对应的不同的人写下的例子。


我们这个数据集究竟应该如何去使用呢!我们将整个数据集分为很多的N-ways K-shot classfication的任务。N-ways就是分为N类,K-shot就是每一类种有K个样本。就是一个总共类别有N类,每一类有K个样本的分类器。
举个例子20 ways 1 shot就是总共20类,每一类有1个样本的分类器。上图就是一个20 ways 1 shot的分类器,训练集就是20类,每一类就只有一张图片的图片集。测试集就是一张图片,我们可以看到测试集和训练集中最下面一行中间的那个是一类的。
在我们使用Omniglot数据集的时候,我们先将其中的1623类拆分为训练集和测试集,之后我们再在训练集中采样出 N N N类,每一类采样 K K K个样本作为我们的一个分类任务,当然我们的训练集可以被拆分组合为很多分类任务的。
我们测试集是在测试类中采样出 n n n类,每一类采样 k k k个样本作为我们的测试分类任务。当我们的 F F F在训练集中被训练好以后,我们就开始将其放入到test中进行测试。
参数初始化
训练神经网络的第一步是初始化参数。当前大多数深度学习框架都收录了不同的参数初始化方法,例如均匀分布、正太分布,或者用 xavier_uniform,kaiming_uniform,xavier_normal,kaiming_normal等算法。除了用随机数,也可以用预训练的网络参数来初始化神经网络,也就是所谓 transfer learning,或者更准确地说是 fine-tuning 的技术。
fine-tuning 之所以能 work,是因为预训练的神经网络本身就有很强的特征提取能力,能够提取很多有含义的特征,例如毛皮,耳朵,鼻子,眼睛,分辨猫狗,只需要知道这些特征是如何组合的就好了,这比从头开始学习如何提取毛皮、耳朵、鼻子等特征要高效得多。
预训练的网络比随机初始化的网络有更强的学习能力,因此 fine-tuning 也算是一种 Meta Learning 的算法。它和我们今天要介绍的 MAML 和 Reptile 都是通过初始化网络参数,使神经网络获得更强的学习能力,从而在少量数据上训练后就能有很好的性能。

下面我们来介绍两种meta learning的方法,分别是maml和reptile。前者是2017年的paper,后者是2018年的paper。
6、MAML
目标函数
MAML主要是关注初始化参数 ϕ \phi ϕ 的选择(所有task的Network Structure都是一样的)。其损失函数为:
L ( ϕ ) = ∑ n = 1 N l n ( θ ^ n ) \large \color{green}{L(\phi)=\sum_{n=1}^Nl^n(\hat\theta^n)} L(ϕ)=n=1∑Nln(θ^n)
其中:
θ ^ n \hat\theta^n θ^n : 在第 n n n个测试任务上训练之后的模型参数, θ ^ n \hat\theta^n θ^n 依赖于 ϕ \phi ϕ , l n ( θ ^ n ) l^n(\hat\theta^n) ln(θ^n): 任务 n n n的loss ,在任务 n n n 的测试集上得出。

MAML的框架是两层的循环嵌套,外面这层是更新MAML模型的参数 ϕ \phi ϕ,然后里面这层是更新任务的参数 θ ^ n \hat\theta^n θ^n ,当然这个内部循环只更新一次(实际是两次)。
使用Gradient Descent来最小化 L ( ϕ ) L(\phi) L(ϕ)
ϕ ← ϕ − η ∇ ϕ L ( ϕ ) \large \color{green}{\phi \leftarrow \phi-\eta \nabla_{\phi} L(\phi)} ϕ←ϕ−η∇ϕL(ϕ)
可能很多人看到meta learning的更新参数方法以后就会想到迁移学习中的model pre-training( pre-training: 假设task2的训练集太小不好训练,我们将和task2相似的task1作为先导数据集,进行训练,将训练的结果作为task2的初始化)。
这里要和transfer learning中的pre-train model的损失函数进行区分:
L ( ϕ ) = ∑ n = 1 N l n ( ϕ ) \large \color{green}{L(\phi)=\sum_{n=1}^{N} l^{n}(\phi)} L(ϕ)=n=1∑Nln(ϕ)
那么这两种方法有什么区别呢,可以看到transfer learning是用现有的模型去计算Loss (看模型的当前表现) 而MAML是用 ϕ \phi ϕ 训练之后的模型来计算Loss (看模型潜力) 用图形来表示二者的区别吧
MAML vs transfer learning

对于MAML, 我们不在意 ϕ \phi ϕ 在 training task 上表现如何, 我们在意用 ϕ \phi ϕ 训练出来的 θ n \theta^{n} θn 表现如何,例如图中的 ϕ \phi ϕ, 在task 1和task 2上目前表现并不是最好的, 但是在task 1上, 如果顺着左边的黑色箭头梯度下降,最终可以得到 θ ^ 1 \hat{\theta}^{1} θ^1; 在task 2上,如果顺着右边的黑色箭头梯度下降,最终可以得到 θ ^ 2 \hat{\theta}^{2} θ^2 。
这两个都是最好的结果(全局最优),所以这就是一个好的 ϕ \phi ϕ.
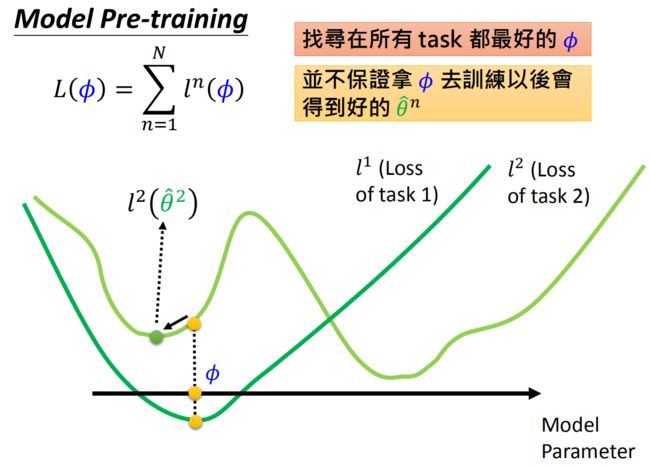
对于transfer learning,我们寻找在所有task都最好的 ϕ \phi ϕ,但并不能保证把 ϕ \phi ϕ拿去训练以后会得到最好的 θ n \theta^n θn ,例如图中 ϕ \phi ϕ在task 1上得到最好的结果,但是拿到task 2上却只能得到一个局部最小值。
总结一下就是,Model Pre-training方法想要得到的参数 ϕ \phi ϕ就是在任何task上都表现良好的参数。但是MEML想要得到的参数是在任务task中经过训练集训练所能得到的比较好的参数。
Model Pre-training看重 ϕ \phi ϕ 现在的表现,但是Meml看重 ϕ \phi ϕ未来的潜力。
MAML的训练
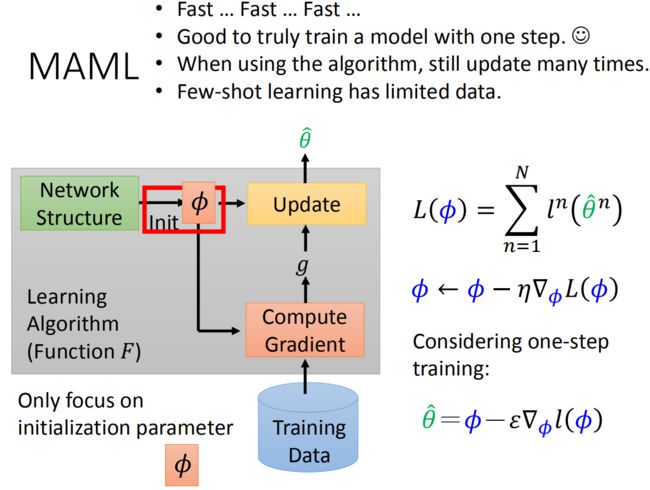
总结起来, MAML算法的框架其实很简单, 值得注意的是两个学习率 ϵ \epsilon ϵ 和 η \eta η 所用的地方不同:
- 对于采样出来的所有任务 θ i \theta^{i} θi, 在support set上计算梯度并更新参数 θ i = ϕ − ϵ ∇ ϕ l ( ϕ ) \large \color{green}{\theta^{i}=\phi-\epsilon \nabla_{\phi} l(\phi)} θi=ϕ−ϵ∇ϕl(ϕ)
- 计算所有任务在query set上的损失之和 L ( ϕ ) = ∑ n = 1 N l n ( θ n ) \large \color{green}{L(\phi)=\sum_{n=1}^{N} l^{n}\left(\theta^{n}\right)} L(ϕ)=∑n=1Nln(θn)
- 更新初始化参数 ϕ ← ϕ − η ∇ ϕ L ( ϕ ) \large \color{green}{\phi \leftarrow \phi-\eta \nabla_{\phi} L(\phi)} ϕ←ϕ−η∇ϕL(ϕ)
MAML更新参数的过程中,一般只会更新一次:
θ ^ = ϕ − ϵ ▽ ϕ l ( ϕ ) \large \color{green}{\hat \theta=\phi-\epsilon\triangledown_{\phi}l(\phi)} θ^=ϕ−ϵ▽ϕl(ϕ)
原因如下:
1,我们的meta learning有很多的任务,假设每一个任务都要更新很多次参数的话,会很慢,所以我们为了追求速度,就让模型只更新一次就好。
2,我们本来的想法就是希望模型非常棒,参数 ϕ \phi ϕ仅仅更新一次就得到这个子任务task的参数 θ \theta θ
3,当我们训练的时候,我们仅仅是让其更新一次,但是当我们真实测试的时候,我们往往可以更新无数次
4,我们的few-shot learning本身就是没有多少训练集,防止over fitting所以我们往往希望可以一次更新就得到参数。
MAML Toy Example

Each task:
• 给定一个正弦函数 y = a sin ( x + b ) y=a\text{sin}(x+b) y=asin(x+b) 作为target function;
• 从正弦函数中采样K个点作为样本;
• 用这K个样本来估计target function。
每一个task就是通过sample出的点还原最开始的方程式。我们可以不断的改变a和b的值,实现多个不同的任务,从而跑我们的mate learning。
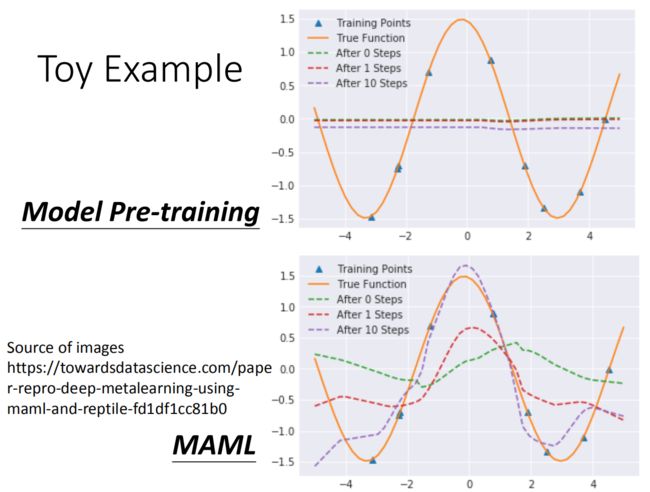
Model Pre-training做出的结果如下图所示:由于Model Pre-training是在所有task都最好的初始化 ϕ \phi ϕ,这里所有的正弦函数叠起来就是一条直线,所以它初始就是直线。训练几次以后,仍然是水平线。
但是使用maml就大不相同,maml一开始的参数是一条波浪线,在训练一次以后大概可以知道哪里是波峰,训练十次以后,波峰和波谷几乎可以发现。
论文中是把maml和其他的meta learning方法做比较,发现maml的方法是比较好的。
算法
考虑一个由参数化函数 f θ f_{\theta} fθ表示的模型,参数为 θ \theta θ。当适应一个新任务 T i \mathcal{T}_{i} Ti时,模型的参数 θ \theta θ变成 θ i ′ \theta_{i}^{\prime} θi′。更新的参数向量 θ i ′ \theta_{i}^{\prime} θi′是通过在任务 T i \mathcal{T}_{i} Ti上使用一个或多个梯度下降更新来计算的。例如,当使用一个梯度更新时,
θ i ′ = θ − α ∇ θ L T i ( f θ ) \large \color{green}{\theta_{i}^{\prime}=\theta-\alpha \nabla_{\theta} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta}\right)} θi′=θ−α∇θLTi(fθ)
步长 α \alpha α可以固定为超参数或meta-learned。为了简单起见,将在其余部分考虑一个梯度更新,但是使用多个梯度更新是一个简单的扩展。
通过优化 f θ i ′ f_{\theta_{i}^{\prime}} fθi′相对于 θ \theta θ的改进来训练模型参数,这些任务是从 p ( T ) p(\mathcal{T}) p(T)采样的。更具体地说,meta目标如下:
min θ ∑ T i ∼ p ( T ) L T i ( f θ i ′ ) = ∑ T i ∼ p ( T ) L T i ( f θ − α ∇ θ L T i ( f θ ) ) \large \color{green}{\min _{\theta} \sum_{\mathcal{T}_{i} \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta_{i}^{\prime}}\right)=\sum_{\mathcal{T}_{i} \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta-\alpha \nabla_{\theta} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta}\right)}\right)} θminTi∼p(T)∑LTi(fθi′)=Ti∼p(T)∑LTi(fθ−α∇θLTi(fθ))
注意meta-优化执行模型参数 θ \theta θ, 而目标是使用更新的模型参数 θ ′ \theta^{\prime} θ′计算的,meta方法旨在优化模型参数,以便在新任务上使用一个或少量梯度步骤将在该任务上产生最大效率的行为。
通过随机梯度下降(SGD)进行跨任务元优化,将模型参数 θ \theta θ更新如下:
θ ← θ − β ∇ θ ∑ T i ∼ p ( T ) L T i ( f θ i ′ ) \large \color{green}{\theta \leftarrow \theta-\beta \nabla_{\theta} \sum_{\mathcal{T}_{i} \sim p(\mathcal{T})} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta_{i}^{\prime}}\right)} θ←θ−β∇θTi∼p(T)∑LTi(fθi′)
其中 β \beta β是元步长。在一般情况下,完整的算法在算法 1. 1 . 1.中概述

第一个Require指的是在 D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train中task的分布。结合我们在上一小节举的例子,这里即反复随机抽取task T {\mathcal T} T ,形成一个由若干个(e.g., 1000个) T {\mathcal T} T 组成的task池,作为MAML的训练集。有的小伙伴可能要纳闷了,训练样本就这么多,要组合形成那么多的task,岂不是不同task之间会存在样本的重复?或者某些task的query set会成为其他task的support set?没错!就是这样!我们要记住,MAML的目的,在于fast adaptation,即通过对大量task的学习,获得足够强的泛化能力,从而面对新的、从未见过的task时,通过fine-tune就可以快速拟合。task之间,只要存在一定的差异即可。再强调一下,MAML的训练是基于task的,而这里的每个task就相当于普通深度学习模型训练过程中的一条训练数据。
第二个Require就很好理解啦。step size其实就是学习率,读过MAML论文的小伙伴一定会对gradient by gradient这个词有印象。MAML是基于二重梯度的,每次迭代包括两次参数更新的过程,所以有两个学习率可以调整。
以上面的5-way 5-shot例子为例,这里我们简单叙述下MAML的算法流程。
-
- 上面我们已经将数据区分成了 D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train和 D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test ,在 D m e t a − t r a i n {\mathcal D}_{meta-train} Dmeta−train和 D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test中我们又将数据区分了support set,query set
-
- 我们用于训练的模型是 M m e t a M_{meta} Mmeta (初始化参数为 ϕ \phi ϕ ),这可能是一个输出节点为5的CNN,训练的目的是为了使得模型有较优秀的初始化参数。最终我们想要学出可以用于数据集 D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test分类的模型是 M f i n e − t u n e M_{fine-tune} Mfine−tune , M f i n e − t u n e M_{fine-tune} Mfine−tune 和 M m e t a M_{meta} Mmeta 的结构是一模一样的,不同的是模型参数。
-
- 我们将1个任务task的support set去训练 M m e t a M_{meta} Mmeta ,这里进行第一种梯度下降,假设每个任务只进行一次梯度下降,也就是 θ ^ 1 ⇐ ϕ − ϵ . ∂ l ( ϕ ) / ∂ ϕ \hat{\theta}^{1}\Leftarrow\phi -\epsilon .\partial l(\phi)/\partial \phi θ^1⇐ϕ−ϵ.∂l(ϕ)/∂ϕ 。那么执行第2个task训练时,有 θ ^ 2 ⇐ ϕ − ϵ . ∂ l ( ϕ ) / ∂ ϕ \hat{\theta}^{2}\Leftarrow\phi -\epsilon .\partial l(\phi)/\partial \phi θ^2⇐ϕ−ϵ.∂l(ϕ)/∂ϕ 。执行第batch size个task后,有 θ ^ b z ⇐ ϕ − ϵ . ∂ l ( ϕ ) / ∂ ϕ \hat{\theta}^{bz}\Leftarrow\phi -\epsilon .\partial l(\phi)/\partial \phi θ^bz⇐ϕ−ϵ.∂l(ϕ)/∂ϕ ,如下图所示。

-
- 上述步骤3用了batch size个task对 M m e t a M_{meta} Mmeta 进行了训练,然后我们使用上述batch 个task中query set去测试参数为 θ ^ i , i ∈ [ 1 , b a t c h s i z e ] \hat{\theta}^{i},i\in[1,batch size] θ^i,i∈[1,batchsize] 的 M m e t a M_{meta} Mmeta 模型效果,获得总损失函数 L ( ϕ ) = ∑ i = 1 b s l i ( θ ^ i ) L(\phi)=\sum_{i=1}^{bs}{l^{i}(\hat{\theta}^{i})} L(ϕ)=∑i=1bsli(θ^i) ,这个损失函数就是一个batch task中每个task的query set在各自参数为 θ ^ i , i ∈ [ 1 , b a t c h s i z e ] \hat{\theta}^{i},i\in[1,batch size] θ^i,i∈[1,batchsize] 的 M m e t a M_{meta} Mmeta 中的损失 l i ( θ ^ i ) l^{i}(\hat{\theta}^{i}) li(θ^i) 之和。
-
- 获得总损失函数后,我们就要对其进行第二种的梯度下降。即更新初始化参数 ϕ \phi ϕ ,也就是 ϕ ⇐ ϕ − η . ∂ L ( ϕ ) / ∂ ϕ \phi\Leftarrow\phi -\eta.\partial L(\phi)/\partial \phi ϕ⇐ϕ−η.∂L(ϕ)/∂ϕ 来更新初始化参数。这样不断地从步骤3开始训练,最终能够在数据集上获得该模型比较好的初始化参数。
-
- 根据这个初始化的参数以及该模型,我们用数据集 D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test 的support set对模型进行微调,这时候的梯度下降步数可以设置更多一点,不像训练时候(在第一次梯度下降过程中)只进行一步梯度下降。
-
- 最后微调结束后,使用 D m e t a − t e s t {\mathcal D}_{meta-test} Dmeta−test 的query set进行模型的评估。
梯度数学推导
GD更新公式为:
ϕ ← ϕ − η ∇ ϕ L ( ϕ ) (1) \large \color{green}{\phi \leftarrow \phi-\eta \nabla_{\phi} L(\phi)\tag{1}} ϕ←ϕ−η∇ϕL(ϕ)(1)
其中损失函数为每个任务的 loss累加
L ( ϕ ) = ∑ n = 1 N l n ( θ ^ n ) (2) \large \color{green}{L(\phi)=\sum_{n=1}^{N} l^{n}\left(\hat{\theta}^{n}\right)\tag{2}} L(ϕ)=n=1∑Nln(θ^n)(2)
其中参数 θ ^ n \hat{\theta}^{n} θ^n 的计算公式为一步更新:
θ ^ = ϕ − ϵ ∇ ϕ l ( ϕ ) (3) \large \color{green}{\hat{\theta}=\phi-\epsilon \nabla_{\phi} l(\phi)\tag{3}} θ^=ϕ−ϵ∇ϕl(ϕ)(3)
公式1中的梯度优化首先要计算损失函数的梯度:
∇ ϕ L ( ϕ ) = ∇ ϕ ∑ n = 1 N l n ( θ ^ n ) = ∑ n = 1 N ∇ ϕ l n ( θ ^ n ) \large \color{green}{\nabla_{\phi} L(\phi)=\nabla_{\phi} \sum_{n=1}^{N} l^{n}\left(\hat{\theta}^{n}\right)=\sum_{n=1}^{N} \nabla_{\phi} l^{n}\left(\hat{\theta}^{n}\right)} ∇ϕL(ϕ)=∇ϕn=1∑Nln(θ^n)=n=1∑N∇ϕln(θ^n)
下面来看梯度 ∇ ϕ l ( θ ^ ) \nabla_{\phi} l(\hat{\theta}) ∇ϕl(θ^) 的求法, 实际上是对每一项求偏导:
∇ ϕ l ( θ ^ ) = [ ∂ l ( θ ^ ) / ∂ ϕ 1 ∂ l ( θ ^ ) / ∂ ϕ 2 ⋮ ∂ l ( θ ^ ) / ∂ ϕ i ⋮ ] \large \color{green}{\nabla_{\phi} l(\hat{\theta})=\left[\begin{array}{c} \partial l(\hat{\theta}) / \partial \phi_{1} \\ \partial l(\hat{\theta}) / \partial \phi_{2} \\ \vdots \\ \partial l(\hat{\theta}) / \partial \phi_{i} \\ \vdots \end{array}\right]} ∇ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂ϕ1∂l(θ^)/∂ϕ2⋮∂l(θ^)/∂ϕi⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
初始化参数 ϕ i \phi_{i} ϕi 是通过很多个 θ i \theta_i θi来影向 l ( θ ^ ) : l(\hat{\theta}): l(θ^):

根据链式法则:
∂ l ( θ ^ ) ∂ ϕ i = ∑ j ∂ l ( θ ^ ) ∂ θ ^ j ∂ θ ^ j ∂ ϕ i (4) \large \color{green}{\frac{\partial l(\hat{\theta})}{\partial \phi_{i}}=\sum_{j} \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_{j}} \frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}\tag{4}} ∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^j(4)
上式中 ∂ l ( θ ^ ) ∂ θ ^ j \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_{j}} ∂θ^j∂l(θ^) 很好计算, 根据损失函数的形式直接求即可,例如如果是交叉嫡,就用交叉嫡求偏导即可。重点来看后面这项: ∂ θ ^ j ∂ ϕ i \frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}} ∂ϕi∂θ^j
根据公式3可知, θ ^ \hat{\theta} θ^ 是一个向量, 所以我们可以找其中一个分量: θ ^ j , \hat{\theta}_{j}, θ^j, 由公式3可得:
θ ^ j = ϕ j − ϵ ∇ ϕ j l ( ϕ ) = ϕ j − ϵ ∂ l ( ϕ ) ∂ ϕ j (5) \large \color{green}{\hat{\theta}_{j}=\phi_{j}-\epsilon \nabla_{\phi_{j}} l(\phi)=\phi_{j}-\epsilon \frac{\partial l(\phi)}{\partial \phi_{j}}\tag{5}} θ^j=ϕj−ϵ∇ϕjl(ϕ)=ϕj−ϵ∂ϕj∂l(ϕ)(5)
对公式5中求 ϕ i \phi_{i} ϕi 的偏导:
当 i ≠ j i \neq j i=j 时
∂ θ ^ j ∂ ϕ i = − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j \large \color{green}{\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=-\epsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}}} ∂ϕi∂θ^j=−ϵ∂ϕi∂ϕj∂l(ϕ)
当 i = j i=j i=j 时
∂ θ ^ j ∂ ϕ i = 1 − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j \large \color{green}{\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=1-\epsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}}} ∂ϕi∂θ^j=1−ϵ∂ϕi∂ϕj∂l(ϕ)
算二次偏导很麻烦, 原论文提出忽略二次偏导项:
当 i ≠ j i \neq j i=j 时
∂ θ ^ j ∂ ϕ i = − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j ≈ 0 (6) \large \color{green}{\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=-\epsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}} \approx 0\tag{6}} ∂ϕi∂θ^j=−ϵ∂ϕi∂ϕj∂l(ϕ)≈0(6)
当 i = j i=j i=j 时
∂ θ ^ j ∂ ϕ i = 1 − ϵ ∂ l ( ϕ ) ∂ ϕ i ∂ ϕ j ≈ 1 (7) \large \color{green}{\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=1-\epsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}} \approx 1\tag{7}} ∂ϕi∂θ^j=1−ϵ∂ϕi∂ϕj∂l(ϕ)≈1(7)
把公式6和公式7代入公式4, 由于当 i ≠ j i \neq j i=j 时, ∂ θ ^ j ∂ ϕ i = 0 , \frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=0, ∂ϕi∂θ^j=0, 所以求和的时候只用考虑 i = j i=j i=j 的情况,即公式4可以写为:
∂ l ( θ ^ ) ∂ ϕ i = ∑ j ∂ l ( θ ^ ) ∂ θ ^ j ∂ θ ^ j ∂ ϕ i ≈ ∂ l ( θ ^ ) ∂ θ ^ i (8) \large \color{green}{\frac{\partial l(\hat{\theta})}{\partial \phi_{i}}=\sum_{j} \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_{j}} \frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}} \approx \frac{\partial l(\hat{\theta})}{\partial \hat{\theta}_{i}}\tag{8}} ∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^j≈∂θ^i∂l(θ^)(8)
利用公式8的估计,梯度矩阵就变成了:
∇ ϕ l ( θ ^ ) = [ ∂ l ( θ ^ ) / ∂ ϕ 1 ∂ l ( θ ^ ) / ∂ ϕ 2 ⋮ ∂ l ( θ ^ ) / ∂ ϕ i ⋮ ] = [ ∂ l ( θ ^ ) / ∂ θ ^ 1 ∂ l ( θ ^ ) / ∂ θ ^ 2 ⋮ ∂ l ( θ ^ ) / ∂ θ ^ i ⋮ ] = ∇ θ ^ l ( θ ^ ) \large \color{green}{\nabla_{\phi} l(\hat{\theta})=\left[\begin{array}{c} \partial l(\hat{\theta}) / \partial \phi_{1} \\ \partial l(\hat{\theta}) / \partial \phi_{2} \\ \vdots \\ \partial l(\hat{\theta}) / \partial \phi_{i} \\ \vdots \end{array}\right]=\left[\begin{array}{c} \partial l(\hat{\theta}) / \partial \hat{\theta}_{1} \\ \partial l(\hat{\theta}) / \partial \hat{\theta}_{2} \\ \vdots \\ \partial l(\hat{\theta}) / \partial \hat{\theta}_{i} \\ \vdots \end{array}\right]=\nabla_{\hat{\theta}} l(\hat{\theta})} ∇ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂ϕ1∂l(θ^)/∂ϕ2⋮∂l(θ^)/∂ϕi⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂θ^1∂l(θ^)/∂θ^2⋮∂l(θ^)/∂θ^i⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤=∇θ^l(θ^)
最后我们的梯度优化项就变成了:
∇ ϕ L ( ϕ ) = ∇ ϕ ∑ n = 1 N l n ( θ ^ n ) = ∑ n = 1 N ∇ ϕ l n ( θ ^ n ) = ∑ n = 1 N ∇ θ ^ n l n ( θ ^ n ) \large \color{green}{\nabla_{\phi} L(\phi)=\nabla_{\phi} \sum_{n=1}^{N} l^{n}\left(\hat{\theta}^{n}\right)=\sum_{n=1}^{N} \nabla_{\phi} l^{n}\left(\hat{\theta}^{n}\right)=\sum_{n=1}^{N} \nabla_{\hat{\theta}^{n}} l^{n}\left(\hat{\theta}^{n}\right)} ∇ϕL(ϕ)=∇ϕn=1∑Nln(θ^n)=n=1∑N∇ϕln(θ^n)=n=1∑N∇θ^nln(θ^n)
真正的实现
先要有一个初始化参数 ϕ 0 \phi^0 ϕ0,然后把一个任务task看做是一个sample,当然可以用多个任务组成mini-batch,然后做GD,这里不是batch,而是用SGD:

基于 ϕ 0 \phi^0 ϕ0计算网络在任务 m 上的损失函数,然后用SGD优化 ϕ 0 \phi^0 ϕ0,以学习率 $\epsilon $ 得到任务 m 独有的网络参数 θ ^ m \hat\theta^m θ^m;

虽然说好只更新一次,但是这里还是更新两次:

接下来,在第二个绿色箭头,基于 θ ^ m \hat\theta^m θ^m计算任务 m 新的损失函数,并求出损失函数在 θ ^ m \hat\theta^m θ^m上的梯度 ∇ ϕ l m ( θ m ) \nabla_{\phi}l^{m}\left(\theta^{m}\right) ∇ϕlm(θm) 。我们不是用这个梯度优化 θ ^ m \hat\theta^m θ^m,而是优化最初的那个 ϕ 0 \phi^0 ϕ0,即 ϕ 1 = ϕ 0 − η ∇ ϕ l m ( θ m ) \large \color{green}{\phi^1 = \phi^0-\eta \nabla_{\phi}l^{m}\left(\theta^{m}\right)} ϕ1=ϕ0−η∇ϕlm(θm)。如第一个蓝色箭头所示,该箭头和第二个绿色箭头是平行的,代表 ϕ 0 \phi^0 ϕ0的更新方向为 θ ^ m \hat\theta^m θ^m处的梯度。
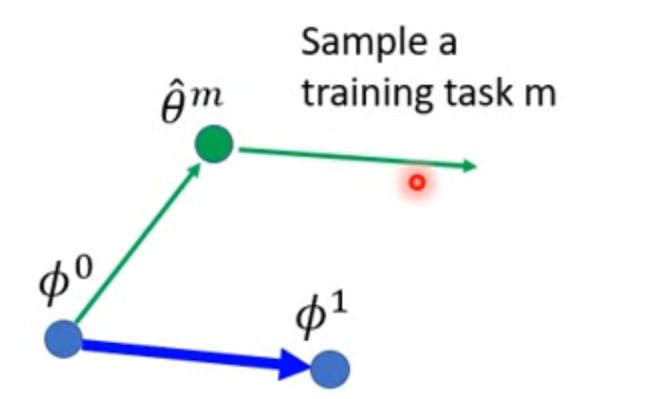
这里需要注意,同向的绿色和蓝色箭头不一定等长,因为LR可能不一样。
然后取一个任务n(Sample a training task n)同样用 ϕ 1 \phi^1 ϕ1 计算出 θ ^ n \hat\theta^n θ^n , 以及 θ ^ n \hat\theta^n θ^n 的下一次梯度方向
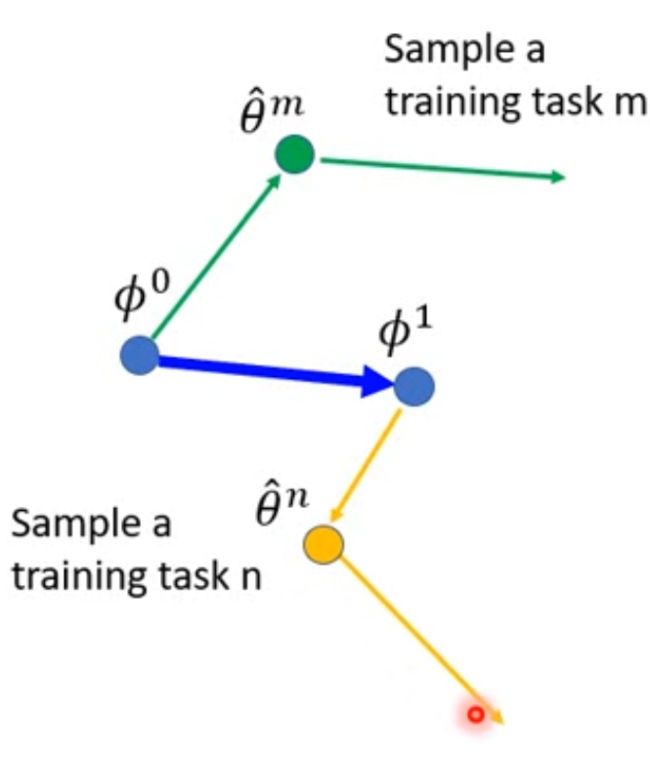
取其方向作为 ϕ 1 \phi^1 ϕ1的梯度更新方向:

这里需要注意,同向的黄色和蓝色箭头不一定等长,因为LR可能不一样。
再次对比transfer learning的Model Pre-training在实现上和MAML有什么不一样:
现有一个初始化参数:
然后计算 θ ^ m \hat\theta^m θ^m
然后沿着绿色箭头更新 ϕ 0 \phi^0 ϕ0

然后不断重复:

MAML 应用:Translation
Meta-Learning for Low-Resource Neural Machine Translation
18 training tasks: 18 different languages translating to English
2 validation tasks: 2 different languages translating to English
实验结果中用的是BLEU来做评估,横轴是数据量,当然数据量越大效果越好。Baseline是多任务学习。先看验证集结果,罗马语翻译为英文

测试任务结果,法语翻译英文

7、Reptile
On First-Order Meta-Learning Algorithms
Reptile算法流程
-
首先初始化一个网络模型的所有参数 ϕ \phi ϕ
-
迭代 N \mathrm{N} N 次, 进行训练, 每次迭代执行:
- 2.1 2.1 2.1 随机抽样一个任务 t t t, 用网络模型进行训练, 对应的loss 是 L t L_{t} Lt, 训练结束后的参数是 ϕ ~ \tilde{\phi} ϕ~
- 2.2 2.2 2.2 在参数 ϕ \phi_{\text { }} ϕ 上使用SGD 或 A d a m A d a m Adam 执行 K K K次梯度下降更新, 得到 ϕ ~ = U t k ( ϕ ) \tilde{\phi}=U_{t}^{k}(\phi) ϕ~=Utk(ϕ)
- 2.3 2.3 2.3 用 ϕ ~ \tilde{\phi} ϕ~ 更新meta网络模型模型参数, ϕ = ϕ + η ( ϕ ~ − ϕ ) \phi=\phi+\eta(\tilde{\phi}-\phi) ϕ=ϕ+η(ϕ~−ϕ)
- 完成上述 N N N次迭代训练, 则结束整个过程
从上面的算法中可以看出, Reptile 是在每个单独的任务执行K次训练后, 就开始真正更新网络模型的参数 (Meta),更新方式不是梯度下降, 但是和梯度下降公式长得很像, 是用上一次的参数 ϕ \phi ϕ 和K次后的参数 ϕ ~ \tilde{\phi} ϕ~ 的差来更新, 更新的步长是 ϵ ∘ \epsilon_{\circ} ϵ∘ 在这个过程中,只有一阶求导 的计算, 就是在任务内部 执 行 K 执行K 执行K次更新的过程中用到的随机梯度下降, 这也是为什么标题中叫 First-Order 的原因。
从这就可以看出和 MAML 算法的不同了:
- MAML:所有任务执行完, 用每个任务测试集上的平均 loss 来更新 meta 参数。
- Reptile: 每个任务执行K次训练后, 用最新的参数和 meta 参数的差来更新 meta 参数。
这里说的meta参数, 就是真正更新网络模型参数的过程
梯度更新过程
ϕ \phi ϕ 代表网络模型初始参数, η , ϵ \eta,\epsilon η,ϵ 分别代表 meta 更新的学习率和 task 更新的学习率, N N N 是meta训练的 batch_size,即 meta 的一个bach有 N N N 个task,每个task内部执行 K K K次训练, N N N个任务都训练完,再来更新meta参数。按照上面的算法过程,meta的一个batch训练完之后,网络模型的参数是:
ϕ = ϕ + η 1 N ∑ i = 1 N ( ϕ ~ i − ϕ ) = ϕ + η ( W − ϕ ) \large \color{green}{\begin{aligned} \phi &=\phi+\eta \frac{1}{N} \sum_{i=1}^{N}\left(\tilde{\phi}_{i}-\phi\right) \\ &=\phi+\eta(W-\phi) \end{aligned}} ϕ=ϕ+ηN1i=1∑N(ϕ~i−ϕ)=ϕ+η(W−ϕ)
其中 W W W 是每个任务最后参数的平均值, 上述公式再进行展开就是这样
W = 1 N ∑ i N w ^ = 1 N ∑ i N ( ϕ − ϵ ∑ j k g i j ) \large \color{green}{W=\frac{1}{N} \sum_{i}^{N} \widehat{w}=\frac{1}{N} \sum_{i}^{N}\left(\phi-\epsilon \sum_{j}^{k} g_{i j}\right)} W=N1i∑Nw =N1i∑N⎝⎛ϕ−ϵj∑kgij⎠⎞
ϕ = ϕ + η ( W − ϕ ) = ϕ + η ( − ϵ N ∑ i N ∑ j k g i j ) = ϕ − ϵ η N [ ( g 11 + g 12 + ⋯ + g 1 k ) + ⋯ + ( g N 1 + g N 2 + ⋯ + g N k ) ] \large \color{green}{\begin{aligned} \phi &=\phi+\eta(W-\phi) \\ &=\phi+\eta\left(-\frac{\epsilon}{N} \sum_{i}^{N} \sum_{j}^{k} g_{i j}\right) \\ &=\phi-\frac{\epsilon \eta}{N}\left[\left(g_{11}+g_{12}+\cdots+g_{1 k}\right)+\cdots+\left(g_{N 1}+g_{N 2}+\cdots+g_{N k}\right)\right] \end{aligned}} ϕ=ϕ+η(W−ϕ)=ϕ+η⎝⎛−Nϵi∑Nj∑kgij⎠⎞=ϕ−Nϵη[(g11+g12+⋯+g1k)+⋯+(gN1+gN2+⋯+gNk)]
假设 N = 2 , K = 3 N=2,K=3 N=2,K=3,即meta每次训练的一个batch 有2个task,每个task内部进行3此迭代,则 meta每次更新模型参数的公式为:
N = 2 , k = 3 W = 1 2 [ ( ϕ − ϵ g 11 − ϵ g 12 − ϵ g 13 ) + ( ϕ − ϵ g 21 − ϵ g 22 − ϵ g 23 ) ] ϕ = ϕ + η ( W − ϕ ) = ϕ − ϵ η 2 [ ( g 11 + g 12 + g 13 ) + ( g 21 + g 22 + g 23 ) ] = ϕ − β ( g 11 + g 12 + g 13 ) − β ( g 21 + g 22 + g 23 ) \large \color{green}{\begin{aligned} &\begin{aligned} N &=2, k=3 \\ W &=\frac{1}{2}\left[\left(\phi-\epsilon g_{11}-\epsilon g_{12}-\epsilon g_{13}\right)+\left(\phi-\epsilon g_{21}-\epsilon g_{22}-\epsilon g_{23}\right)\right] \\ \phi &=\phi+\eta(W-\phi) \\ &=\phi-\frac{\epsilon \eta}{2}\left[\left(g_{11}+g_{12}+g_{13}\right)+\left(g_{21}+g_{22}+g_{23}\right)\right] \\ &=\phi-\beta\left(g_{11}+g_{12}+g_{13}\right)-\beta\left(g_{21}+g_{22}+g_{23}\right) \end{aligned} \end{aligned}} NWϕ=2,k=3=21[(ϕ−ϵg11−ϵg12−ϵg13)+(ϕ−ϵg21−ϵg22−ϵg23)]=ϕ+η(W−ϕ)=ϕ−2ϵη[(g11+g12+g13)+(g21+g22+g23)]=ϕ−β(g11+g12+g13)−β(g21+g22+g23)
训练过程
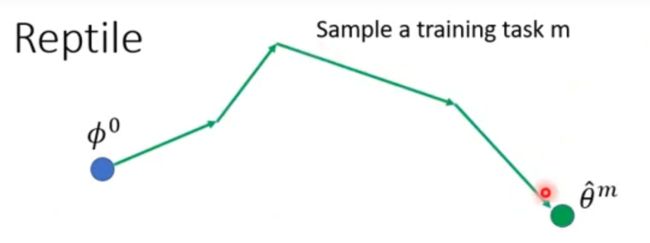
meta 模型的参数更新过程,在几何上就是这样的:

动图看的更加清晰些,其中绿色代表第一个任务,三个绿色箭头代表三次更新时的梯度方向,可以看到,Reptile的模型就是朝着每个任务的梯度和的方向上不断地进行更新。
现有初始化参数 ϕ 0 \phi^0 ϕ0

取一个任务m(Sample a training task m),Reptile没有规定只能更新一次参数,因此:
从 ϕ 0 \phi^0 ϕ0到 θ ^ m \hat\theta^m θ^m 方向就是 ϕ 0 \phi^0 ϕ0 更新的方向:
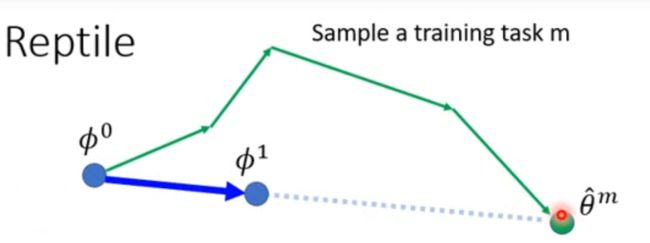
计算出 ϕ 1 \phi^{1} ϕ1 后,取一个任务n (Sample a training task n \mathrm{n} n ) 同样用 ϕ 1 \phi^{1} ϕ1 计算出 θ ^ n \hat{\theta}^{n} θ^n 并更新多次,取 ϕ 1 \phi^{1} ϕ1 到 θ ^ n \hat{\theta}^{n} θ^n 的方向作为 ϕ 1 \phi^{1} ϕ1 的更新方向:

把pre-train, MAML, Reptile都放在一起看下有什么区别:
下面 g 1 g_{1} g1 是pre-train的更新方向 , g 2 g_{2} g2 是MAML的更新方向, g 1 + g 2 g_{1}+g_{2} g1+g2 是Reptile的更新方向, 当然还可以更新更多次.

8、More about Meta Learning
上面讲的MAML和Reptile都是关于用Meta Learning来找初始化参数这个事情,那我们在介绍Meta Learning的时候还有很多红色框框,这些也是可以用Meta Learning来进行研究如何学习的。
下图是用network来设计Architecture & Activation,以及如何更新参数。

我们之前讲的都是用这种方法来更新我们的初始化参数,那么能不能有别的应用呢!其实是可以的,我们可以更新我们的神经网络的结构,也可以更新他们的更新的方法。当让我们用一个网络去更新另一个网络的话,我们是没有办法进行微分的,所以我们经常使用rl的方法进行更新。

其实我们之前是训练如何设置初始化参数 ϕ \phi^{ } ϕ ,但是我们本身就有一个初始化参数 ϕ 0 \phi^{ 0} ϕ0 。
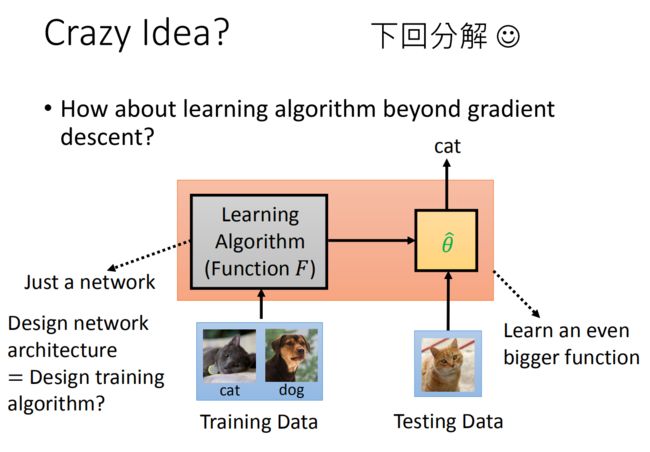
于是我们就有了一个十分疯狂的想法,就是我们让我们的learning algorithm本身就是一个大的network,之后我们去让神经网络输出我们训练的参数θ,之后我们再用参数θ的分类网络去分类,得到我们最终的预测标签。那么我们可不可以把learning algorithm网络和分类网络两个网络都搞在一起呢!就是我们直接将两个网络都设置为黑盒,输入的是training data,之后再黑盒里得到我们的参数和模型,我们不知道参数是什么,不知道模型是什么,我们就可以直接得到我们的分类结果了。
这就是 8.9 元学习网络结构讲解 的内容了。
参考资料
李宏毅2020人类语言处理
课程向:深度学习与人类语言处理
计算机视觉实验室
人工不智能,机器不学习
[meta-learning] 对MAML的深度解析
https://openai.com/blog/reptile/