这就是神经网络 11:深度学习-语义分割-DFN、BiSeNet、ExFuse
前言
本篇介绍三篇旷视在2018年的CVPR及ECCV上的文章。旷视做宣传做的很好,出的论文解读文章很赞,省去了我从头开始理解的痛苦,结合论文基本能很快了解全貌。
语义分割任务同时需要 Spatial Context 和 Spatial Detail ,也就是分类的语义信息和形状的空间信息。不同的网络从不同的角度解决这两个问题,做不同的妥协。

DFN
这是在CVPR2018上被接收的文章。DFN是Discriminative Feature Network的简称,也就是能生成具有判别力特征的网络。
动机
本文动机是解决两个问题:
- 标签相同但外观不同的图像块,称之为类内不一致
- 两个相邻的图像块,标签不同但外观相似,称之为类间无差别
也就是说,长得像的未必是一家,不像的未必不是一家。

第一行中,图中牛的左下角被识别为马,这属于类内不一致问题。第二行中,电脑主机上的蓝光及黑色机壳与显示器相似,因此难以区分,这属于类间无差别问题。
本文提出一个全新的判别特征网络(DFN) 以学习特征表征,同时兼顾类内一致(intra-class consistency)与类间差别(inter-class variation)。
DFN 有两个组件:Smooth Network 和 Border Network。旷视的文章说Smooth Network主要用于解决类内不一致,Border Network用于解决类间无差别。
网络结构
DFN的网络结构如下:

DFN的中间和右侧组合在一起就是一个U形的encoder-decoder网络。最左侧的部分被称为Border Network,右侧被称为Smooth Network。
上体中的蓝色箭头代表下采样,红色箭头代表上采样,绿色箭头只传递特征不改变大小。
注意Border Network仅仅在训练时使用,这是一个倒U形的网络。用于输出物体的轮廓,其loss值和右侧的分割loss一起监督网络训练。推理的时候左侧是不需要的。
Smooth Network
按照旷视的文章说法,Smooth Network主要为了解决类内不一致的问题。类内不一致的问题主要在于上下文的缺失。为此作者提出带有全局平均池化的全局语境, 为网络引入最强的一致性约束作为指导。也就是上面网络结构最下面那个蓝色的箭头。作者所说的引入一致性,其实就是更大范围的上下文信息、更大的视野域。
Smooth Network还有两个子模块:通道注意力模块和优化残差模块。
通道注意力模块:FCN那些网络暗示了不同通道的权重是平等的,旷视自己在文章中说不同阶段的特征判别力不同,造成预测的一致性各不相同。为实现类内一致预测,应该提取判别特征,并抑制非判别特征,从而可以逐阶段地获取判别特征以实现预测类内一致。
通道注意力模块的idea应该来自SENet。简化的效果图如下:
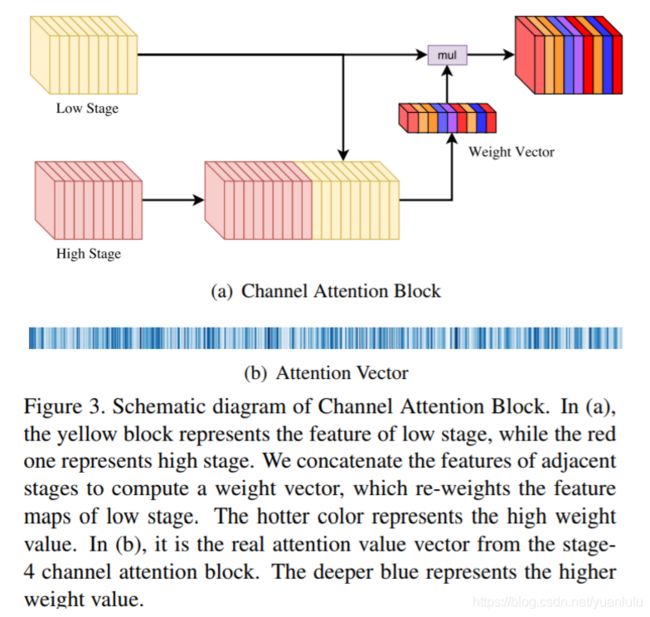
在(a)中,黄色模块表征低级阶段的特征,红色模块表征高级阶段的特征。作者结合相邻阶段的特征以计算权重向量,从而更新低级阶段特征图的权重。较深色模块表征高权重值。(b)是第 4 阶段通道注意力模块的真实注意力值向量。蓝色越深,表征权重值越大。
优化残差模块:在decoder阶段使用残差跳跃连接可能是受RefineNet的启发。该模块的第 1 个组件是 1 x 1 卷积层,作者用它把通道数量统一为 512。接着是一个基本的残差模块,它可以优化特征图。
Border Network
Border Network输出的是物体的边界框。就像下面:

Border Network是为了训练时监督encoder部分学习语义边界,推理时并不需要。要精确地提取语义边界,需要两边的特征更加可区分,而这正是作者的目的所在。
(个人觉得,把识别边界解释成提高类内一致性也通,现在的各种深度学习论文都是刷榜先行,然后各种解释有点牵强附会,都是黑盒,不算很严谨的理论,只能是一些推测)
但是看涨点数的话,效果有,但是不很大。

北航有篇论文同时做分割和边缘提取和本网络有异曲同工之妙。介绍见《ECCV 2018 | 中山大学&商汤提出部分分组网络PGN,解决实例级人体解析难题》。
测试结果

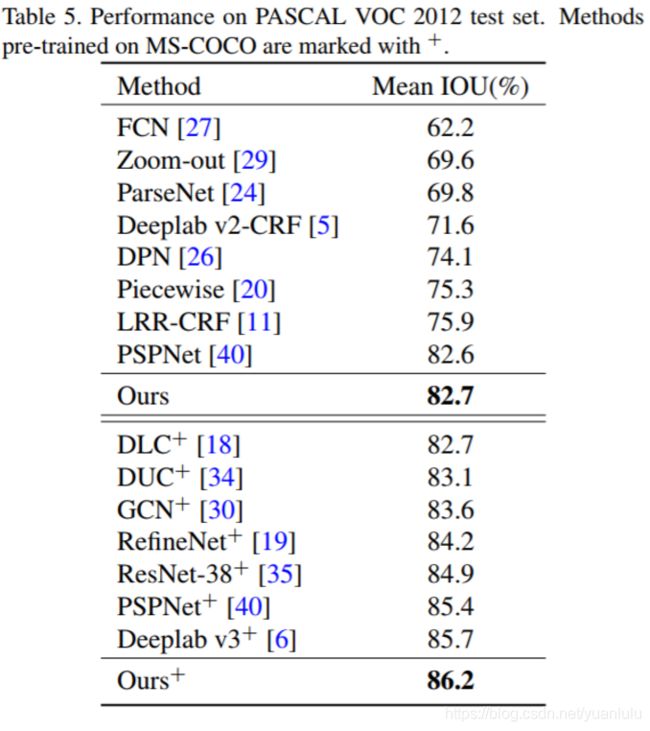
DFN(2018年出)其实也就比PSPNet(2016年出)好了一点点,时间都过了两年了。
BiSeNet
BiSeNet是一个面向工程、追求快速的语义分割网路。
动机
论文中总结了三种加速语义分割的方法:
- 通过剪裁或 resize 来限定输入大小。这种方法简单而有效,空间细节会有较大损失
- 减少网络通道数量。但是这会弱化空间信息。
- 丢弃模型的最后阶段(比如ENet)。抛弃最后阶段的下采样,这会导致模型的感受野不足以涵盖大物体,导致判别能力较差。
上面三个方案都具有不可克服的缺点。语义分割一般都是用U形结构,先将特征图缩小提取语义,然后上采样融合更大的特征图弥补空间细节。完整的U形结构本身具有很大的计算量,减少通道数又会导致空间信息的丢失,减少U形结构的层数会导致感受野不足。所以采用U形结构本身有一定缺陷,加速语义分割需要对U形结构做改进。
网络结构
本文提出了双向分割网络(Bilateral Segmentation Network/BiseNet),它包含两个部分:Spatial Path (SP) 和 Context Path (CP)。顾名思义,这两个组件分别用来解决空间信息缺失和感受野缩小的问题。
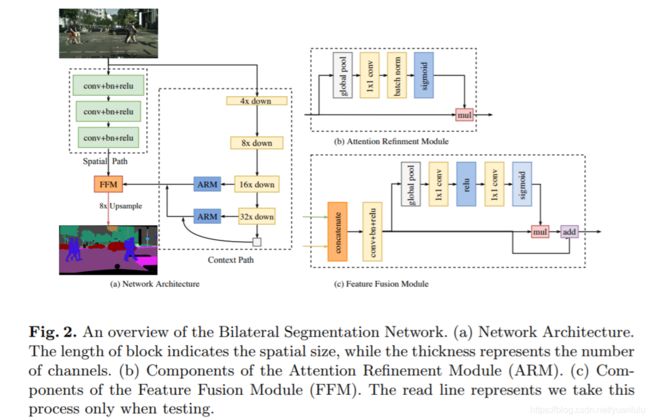
Spatial Path只叠加三个卷积层以获得 1/8 特征图,通道数较多,其保留着丰富的空间细节。三个卷积层均是大小3x3步长为2的卷积核。
Context Path使用预训练的轻量网络Xception39作为backbone的FCN-8S,并在网络的最后一层添加了一个全局平均池化操作获取全局的感受野,两层特征相加之前使用一个通道注意力模块(Attention Refinment Module)对特征通道学习不同的权重。但是上图画的Context Path过于简单,没有体现出上采样和相加的操作。
Spatial Path和Context Path最后都提供了1/8原图大小的特征。这两部分的特征通过FFM模块融合后输出。FFM模块先将两部分特征拼接在一起,然后用“卷积+BN+ReLU”进行变换,后面是一个Resnet_SE模块(可以参考SENet论文)。
辅助损失
作者在论文里说在加了两个辅助损失在Context Path,而且这两个辅助损失否是softmax loss,暂时还没看代码,我猜测着两个辅助损失就是FCN-32S和FCN-18S。两个辅助损失的权重参数都是1。
速度
虽然Spatial Path保留了丰富的空间细节,但是只有三层卷积操作,所以计算量很少,右侧Context Path采用Xception39这种精简网络进行快速的下采样提取语义信息,最终两个路径的信息通过FFM融合输出。
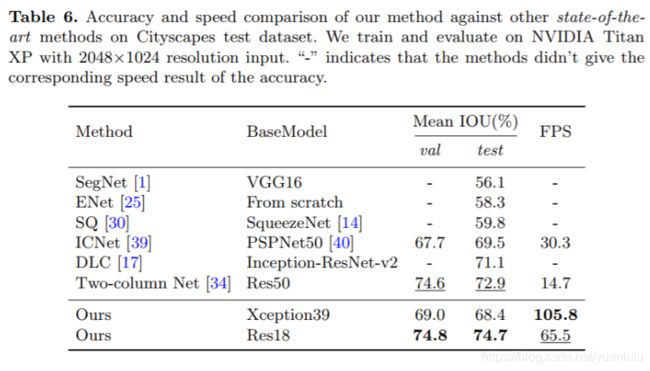
从Table 4可以看到,BiSeNet参数量很少,计算量更少。Table 5里列举了不同网络的速度,可以看到BiSeNet的速度优势。
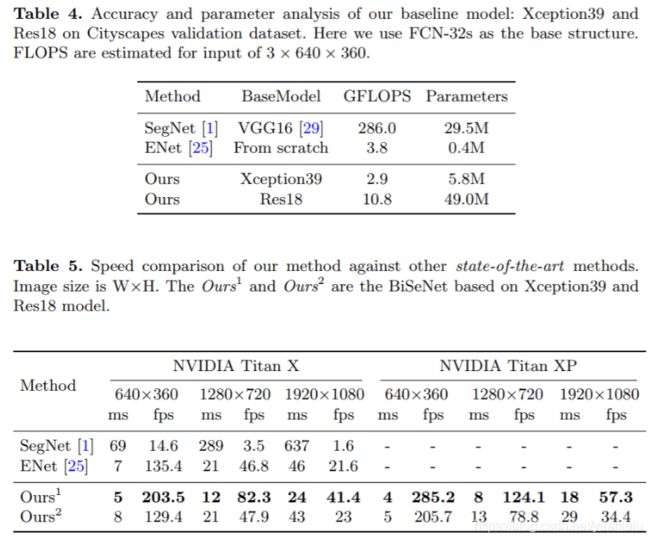
Table 6可以看到,BiSeNet在快速的语义分割网络里属于最快最好的。
对比试验
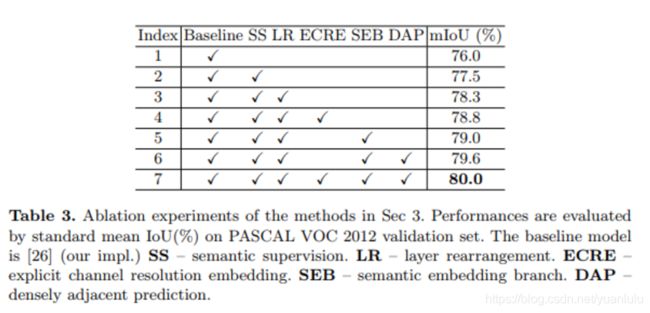
作者做了比较多的试验来说明每个trick对于分割结果的收益:

跟主流分割网络相比,性价比很高,参数上来了比PSPNet也能一战:
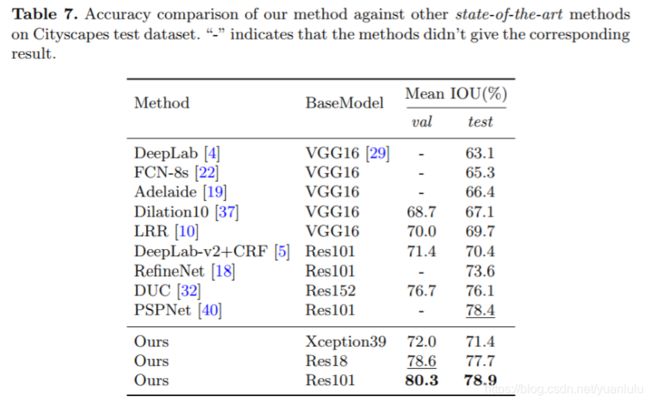
看作者贴的效果,还行的:

小结
可以看到BiSeNet和DFN共享了一些trick,比如SE模块、全局平均池化。
ExFuse
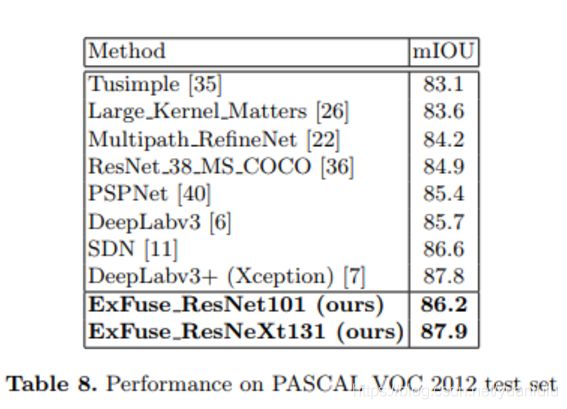
这是旷视在ECCV 2018上发表的论文,时至今日(19年3月)仍在PASCAL VOC 2012语义分割的第五名位置。
我看网上除了一篇旷视的文章和一篇CSDN博客以外,几乎没有介绍ExFuse的文章。但是通读论文下来,我觉得本文的大部分技巧都是可以迁移到其他机器视觉任务中的,值得细细品味。
动机
绝大多数当前最优的语义分割框架基于全卷积网络(Fully Convolutional Network/FCN)而设计,FCN 有一个典型的编码器-解码器结构。比如U-Net,其核心思想是使用一个预训练的分类网络提取图像特征,然后逐渐融合顶层的高级、低分辨率特征和底层的低级、高分辨率特征。
一般而言,低级特征和高级特征相铺相成。低级特征空间信息丰富,但是缺乏语义信息;高级特征则与之相反。
这里作者做了一个思想实验:那就是低级特征只包含低级概念,比如点、线或者边缘;高级特征只包含语义信息。那这样融合能获得好的效果吗?经验告诉我们是不能的。相反,如果低级特征包含更多的语义信息,高级特征就能更容易与边界对齐,如果高级特征中嵌入更多的空间信息,高级特征可以通过对齐最近的边界来自我优化。

上图就是普通U形语义分割网络与本网络的区别。总结下就一句话:把更多的语义信息引入低级特征,在高级特征中嵌入更多的空间信息。
上面这句话就是本论文的核心思想。本文就是要弥补高级特征与低级特征之间的鸿沟。
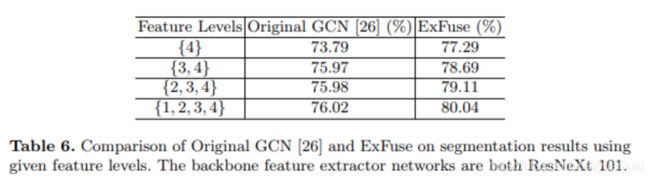
该论文的网络是在GCN基础上修改而来,baseline也是GCN。为了证明传统高低特征的融合方式是低效的,本文对 GCN 特征融合的有效性作了评估,在GCN各个decode阶段输出分割结果,发现融合两次后收益很快就收敛了,后面的两次融合收益很小。而ExFuse就是为了改变这种情况。

网络结构
网络结构修改自GCN,跟原版的GCN大体还是很像的。注意下图虽然没把GCN的Boundary Refinement模块画出来,其实还是在的,作者应该是为了好理解做的简化画法。

上图中的实线都是原版GCN的元素,虚线的都是ExFuse增加的。
把更多的语义信息引入低级特征
为了把更多的语义信息引入低级特征,作者使用了卷积重排列(LR)、多层语义监督(SS)、高级语义嵌入(SEB)这几个方法。
该策略启发于这一事实:对于卷积神经网络来说,特征图与语义监督(如分类损失)相似,倾向于编码更多语义信息。
卷积重排列(Layer Rearrangement)
一般的主干网络都分为5个阶段,其中后4 个阶段的特征会用于分割的融合。既然特征图倾向于编码更多语义信息,在低级特征阶段增加更多的卷积层就可以在低级特征里引入更多的语义信息。
以ResNeXt 101为例,后四个阶段的层数分别是{3, 4, 23, 3} ,本文没有额外增加卷积层,而是把卷积层迁移了,第2-5阶段的卷积层数调整后变为{8, 8, 9, 8}。这样调整虽然对分类任务几乎没有影响,对分割任务却有0.8%的涨点功效。
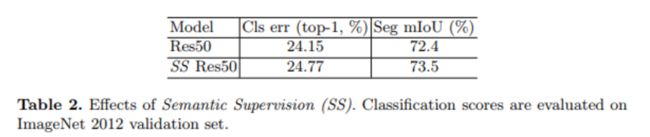
多层语义监督(Semantic Supervision)
通过在分类网络的每个阶段添加辅助的语义监督(分类)分支,强迫低级网络特征包含更多语义信息。语义监督分支如下:

虽然对ResNet和ResNeXt来说,语义监督会伤害分类的性能,但是却会促进分割任务涨点。
高级语义嵌入(Semantic Embedding Branch)
用公式来表达的话,GCN中每次融合对应的公式如下:

也就是下一阶段的特征上采样后和本阶段特征相加,ExFuse创造性的增加了一个语义嵌入分支,将所有高于本阶段的特征全部融合再一起做点乘,再和上采样后的上一级特征相加。对应的新公式如下:

语义嵌入分支的结构如下:
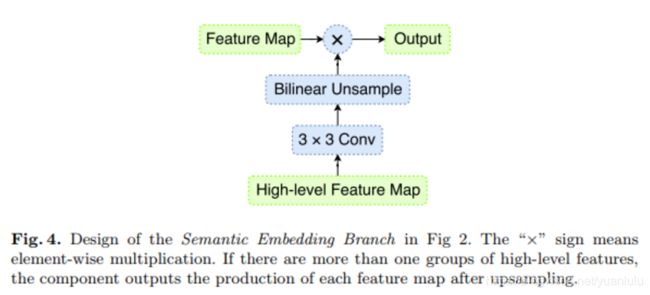
图里只涉及上一层特征,与公式对应不起来。官方没有开源代码,也没有别人实现,所以不清楚level1和level2的语义嵌入分支到底嵌入了几个层次的特征。
为了好理解,我先当成两个吧。
个人理解:因为语义嵌入是通过点乘实现的,所以这就类似SENet的通道注意力机制,属于一种element-wise注意力机制。而且我感觉CVPR2019的HRNet和本文的语义嵌入有异曲同工之妙,都是高低特征的排列组合式融合,然后由网络学习特征权重。这两点都是自己琢磨的,不一定对。
在高级特征中嵌入更多的空间信息
大多分类网络中,高级特征往往包含较低的空间分辨率,一个常用的解决方案是 dilated strategy(空洞卷积),可以增大分辨率而无需再训练 backbone,但弊端是加大了网络的计算量。本文摈弃这种“物理式”方法,转个方向,试图在通道之中编码更多的分辨率信息。
本文用了两个方法来实现此目的:显式通道内嵌空间信息(ECRE)和密集邻域预测(DAP)
显式通道内嵌空间信息(Explicit Channel Resolution Embedding)
为了让高级语义学习空间信息,作者又使出了辅助损失监督大法。
一开始作者试图在分类网络的最后一个特征图后面做反卷积上采样,然后加一个辅助损失监督分支,但是这样没有见效。作者猜测应该是因为反卷积层包含了权重参数,这回导致空间嵌入不够直接(需要反卷积参数自己去学习),为此本文采用一种无需调参的上采样方法——Sub-pixel Upsample(子像素卷积上采样)——以替代原先的反卷积。
子像素卷积上采样就是用四个像素拼接在一起达到上采样的目的,示意图如下:
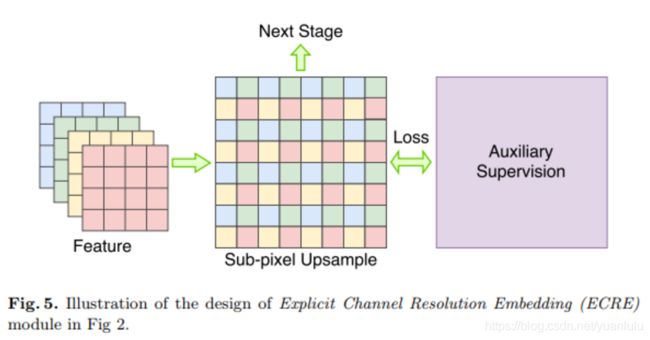
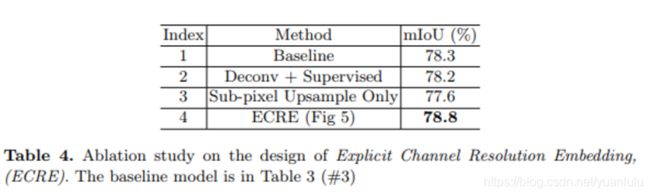
多说一句:常用的上采样包括线性插值、反卷积和子像素卷积。其中线性插值和子像素卷积均不需要权重参数,是train-free的。为了证明对分割的改善是辅助损失监督起到的效果而不是子像素卷积本身,作者做了对比测试:
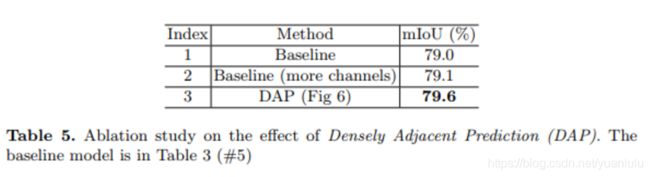
密集邻域预测(Densely Adjacent Prediction)
论文里的所有技巧,这一个是最费解的,看了好多遍才懂。
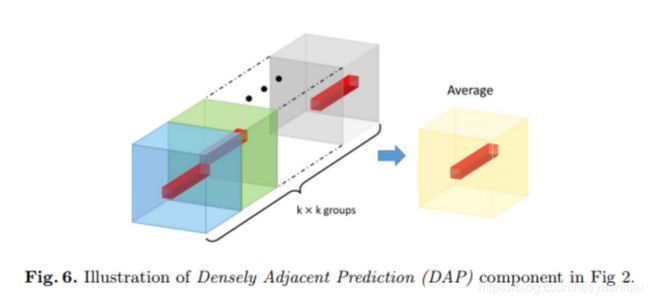
首先DAP模块是放在语义分割输出之前的最后一个模块,为了可能多地把空间信息编码进通道,本文提出一种全新的机制,强迫每个element可以预测相邻位置的结果,从而使每个特征元素学习到更多的空间信息。
普通的语义分割网络,到了最后的时候,空间定位 (i,j) 上的特征点主要负责相同位置的语义信息。而ExFuse每个位置的特征要由相邻的kxk窗口大小的特征求平均得到。本文取K为3。
原始GCN最后阶段为21通道(对应21个分类)。在K为3的情况下,特征被扩展到189个(21x3x3),共9组(3x3)。用下面的公式变换得到21通道的特征:
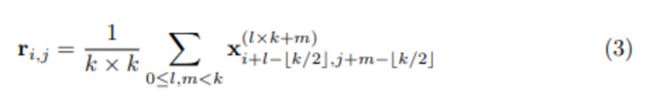
这个公式说实在的我起初也没看懂,后来自己琢磨明白了。
最后21通道的特征上,每个element都是通过3x3个元素求平局得到的。这个3x3的窗口对应9个元素,每个元素来自一组。刚好前面有9组特征。也就是说,每组负责提供3x3窗口上的一个元素。
比如求(1,1)位置上的特征元素,那么以这个位置为中心画一个3x3的方框,第一个元素来自第一组的(0,0)位置,第二个元素来自第二组的(0,1)位置,第三个来自第三组的(0,2)位置,第四个元素来自第四组的(1,0)位置,依次类推,共9个元素求平均得到(1,1)位置上的特征元素。
9组特征每组都是21通道。每次求平均,每一组都贡献一个元素值。第一组总是贡献3x3窗口左上角的值,最后一组总是贡献右下角的值。不管你有没有明白,我反正明白了。
示意如下:
为了证明不是参数变多引起的大力出奇迹,作者对比了DAP和相同参数量的普通卷积,发现DAP对性能有0.6%的提升,而纯粹增加通道数只有0.1%。
对比试验
作者做了一系列的对比试验来证明各个trick的提升效果:
作者开头说GCN收益收敛的事也基本解决了:
测试效果
当时的测试效果为PASCAL VOC 2012语义分割排行榜首位。相同backbone基础上也比DeepLabv3要好。但是相对DeepLabv3+优势并不大,目前榜首前十还多是DeepLabv3+的各种变体或版本。
训练过程
先用COCO数据集预训练分类网络(我猜SS应该在这时使用的),因为COCO包含80个类,只训练了包含在VOC 2012中的20个类,其它都作为背景。后续分割训练分三个阶段:
- COCO, SBD and standard PASCAL VOC 2012
- SBD and PASCAL VOC 2012
- only employ standard PASCAL VOC
这个过程和GCN很像,都是从多个数据集收缩到打榜的目标数据集。
展望
对于本文的这些技巧是否能推广到其他视觉任务中,作者认为是可以的但没有展开讨论。我认为因为U-Net和SSD结构天然接近,所有这些技巧用于SSD类的目标检测是肯定可以的。
论文
Learning a Discriminative Feature Network for Semantic Segmentation
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
ExFuse: Enhancing Feature Fusion for Semantic
Segmentation
参考资料
Sub-pixel Convolution(子像素卷积)
本文的部分文字内容摘抄自旷视的下面几篇文章:
语义分割江湖的那些事儿——从旷视说起
CVPR 2018 | 旷视科技Face++提出用于语义分割的判别特征网络DFN
ECCV 2018 | 旷视科技提出双向网络BiSeNet:实现实时语义分割
ECCV 2018:旷视科技提出ExFuse——优化解决语义分割特征融合问题