2021-09-23 opencv学习笔记(图像变换,二值化,滤波器介绍及python实现)

opencv学习笔记
- 颜色空间
-
- 改变颜色空间(cv2.cvtColor())
- 目标追踪
- 如何查找某个颜色的HSV值
- 图形变换
-
- 缩放(cv2.resize())
- 平移
- 旋转
- 仿射变换
- 透视变换
- 二值化
-
- 简单阈值法
- 自适应阈值
- Otsu二值化(俗称大津法)
- Otsu 二值化原理
- 滤波
-
- 二维卷积(图像滤波)
- 图像模糊(图像平滑)
-
- 均值滤波
- 高斯滤波
- 中值滤波
- 双边滤波
颜色空间
改变颜色空间(cv2.cvtColor())
在 OpenCV 中有超过 150 种颜色空间转换的方法。但我们仅需要研究两个最常使用的方法,他们是 BGR 到 GRAY,BGR 到 HSV。
我们使用 cv.cvtColor(input_image, flag)函数进行颜色转换,其中 flag 决定了转换的类型。
对于 BGR 到 Gray 转换我们令 flag 为 cv2.COLOR_BGR2GRAY。 同样,对于 BGR 到 HSV, 我们令 flag 为 cv2.COLOR_BGR2HSV。
代码:
import cv2
BGR = cv2.imread("C:/Users/Zhang-Lei/Desktop/snack.png")
GRAY = cv2.cvtColor(BGR, cv2.COLOR_BGR2GRAY)
HSV = cv2.cvtColor(BGR, cv2.COLOR_BGR2HSV)
cv2.imshow('BGR', BGR)
cv2.imshow('GRAY', GRAY)
cv2.imshow('HSV', HSV)
cv2.resizeWindow('BGR', 500, 800)
cv2.resizeWindow('GRAY', 500, 800)
cv2.resizeWindow('HSV', 500, 800)
cv2.waitKey()
cv2.destroyAllWindows()
结果:
如想得到其他 flag 值,我们只需要输入代码查看:
代码:
flags = [i for i in dir(cv2) if i.startswith('COLOR_')]
print(flags)
种类过多,这里就不展示结果了。
注意: 对于 HSV, 色调(Hue)范围为 [0,179], 饱和度(Saturation)范围为 [0,255] ,明亮度(Value)为 [0,255]. 不同的软件使用不同的比例. 所以如果你想用 OpenCV 的值与别的软件的值作对比,你需要归一化这些范围。
目标追踪
现在我们知道了如何将 BGR 图片转化为 HSV 图片,我们可以使用它去提取彩色对象。HSV 比 BGR 在颜色空间上更容易表示颜色。在我们的应用中,我们会尝试提取一个蓝色的彩色对象,方法为:
- 提取每一视频帧。
- 将 BGR 转化为 HSV 颜色空间。
- 我们用蓝色像素的范围对该 HSV 图片做阈值。
- 现在提取出了蓝色对象,我们可以随意处理图片了 。
代码:
import cv2
import numpy as np
cap = cv2.VideoCapture(0) # 读取摄像头影像
while 1:
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) # 转为HSV图
lower_blue = np.array([110, 50, 50]) # 限定蓝色范围下限
upper_blue = np.array([130, 255, 255]) # 限定蓝色范围上限
mask = cv2.inRange(hsv, lower_blue, upper_blue) # 限定HSV图像范围
res = cv2.bitwise_and(frame, frame, mask=mask) # 按位与
cv2.imshow('frame', frame)
cv2.imshow('mask', mask)
cv2.imshow('res', res)
k = cv2.waitKey(5) & 0xFF # 检测是否按下Esc 引用&0xff,
# 正是为了只取按键对应的ASCII值后8位来排除不同按键的干扰进行判断按键是什么。
if k == 27:
break
cv2.destroyAllWindows()
结果:

可以看到这本书的蓝色对象被我们提取了出来。
如何查找某个颜色的HSV值
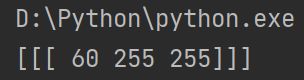
你可以使用相同的函数:cv2.cvtColor()。 不需要输入图片,你只需要输入你需要的 BGR 值即可. 例如, 为了找到绿色的 HSV 值,
代码:
green = np.uint8([[[0, 255, 0]]])
hsv_green = cv2.cvtColor(green, cv2.COLOR_BGR2HSV)
print(hsv_green)
结果:
图形变换
缩放(cv2.resize())
缩放是调整图片的大小。 OpenCV 使用 cv2.resize() 函数进行调整。可以手动指定图像的大小,也可以指定比例因子。可以使用不同的插值方法。对于下采样(图像上缩小),最合适的插值方法是 cv2.INTER_AREA 对于上采样(放大),最好的方法是 cv2.INTER_CUBIC (速度较慢)和 cv2.INTER_LINEAR (速度较快)。默认情况下,所使用的插值方法都是 cv2.INTER_AREA 。你可以使用如下方法调整输入图片大小:
代码:
import cv2
img = cv2.imread("C:/Users/Zhang-Lei/Desktop/snack.png")
res1 = cv2.resize(img, None, fx=1/2, fy=1/2, interpolation=cv2.INTER_CUBIC) # fx和fy分别对应横纵轴图像放大倍数
height, width = img.shape[:2]
res2 = cv2.resize(img, (width//2, height//2), interpolation=cv2.INTER_CUBIC) # 第二种方法
cv2.imshow('img', img)
cv2.imshow('res1', res1)
cv2.imshow('res2', res2)
cv2.waitKey()
cv2.destroyAllWindows()
结果:
可以看出两种方法都将图片的大小缩小为原来大小的一半。
平移
平移变换是物体位置的移动。如果知道 (x,y) 方向的偏移量,假设为 (t_x,t_y),则可以创建如下转换矩阵 M:

您可以将变换矩阵存为 np.float32 类型的 numpy 数组,并将其作为 cv.warpAffine 的第二个参数。请参见以下转换(100,50)的示例:
代码:
import cv2
import numpy as np
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', cv2.IMREAD_UNCHANGED)
rows, cols = img.shape
M = np.float32([[1, 0, 100], [0, 1, 50]])
res = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('img', img)
cv2.imshow('res', res)
cv2.waitKey()
cv2.destroyAllWindows()
结果:
这里可以看到得到的图像相比于原图像是向右下方平移了的。
注意:cv2.warpAffine 函数的第三个参数是输出图像的大小,其形式应为(宽度、高度)。记住宽度=列数,高度=行数。
旋转
以θ角度旋转图片的转换矩阵形式为:

但 Opencv 提供了可变旋转中心的比例变换,所以你可以在任意位置旋转图片,修改后的转换矩阵为:
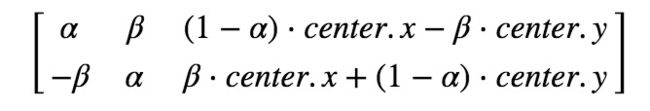
其中:

为了找到这个转换矩阵,opencv 提供了一个函数
cv2.getRotationMatrix2D 。
请查看下面的示例,它将图像相对于中心旋转 90 度,而不进行任何缩放。
代码:
import cv2
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', cv2.IMREAD_UNCHANGED)
rows, cols = img.shape
M = cv2.getRotationMatrix2D(((cols-1)/2.0, (rows-1)/2.0), 90, 1)
res = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('img', img)
cv2.imshow('res', res)
cv2.waitKey()
cv2.destroyAllWindows()
结果:
可见图片已经发生了逆时针90°的旋转。
仿射变换
在仿射变换中,原始图像中的所有平行线在输出图像中仍然是平行的。为了找到变换矩阵,我们需要从输入图像中取三个点及其在输出图像中的对应位置。然后 cv2.getPerspectiveTransform 将创建一个 2x3 矩阵,该矩阵将传递给cv2.warpAffine 。
代码:
import cv2
import matplotlib.pyplot as plt
import numpy as np
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/drawing.png')
rows, cols, ch = img.shape
pts1 = np.float32([[50, 50], [200, 50], [50, 200]])
pts2 = np.float32([[10, 100], [200, 50], [100, 250]])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(img, M, (cols, rows))
plt.subplot(121), plt.imshow(img), plt.title('Input')
plt.subplot(122), plt.imshow(dst), plt.title('Output')
plt.show()
结果:
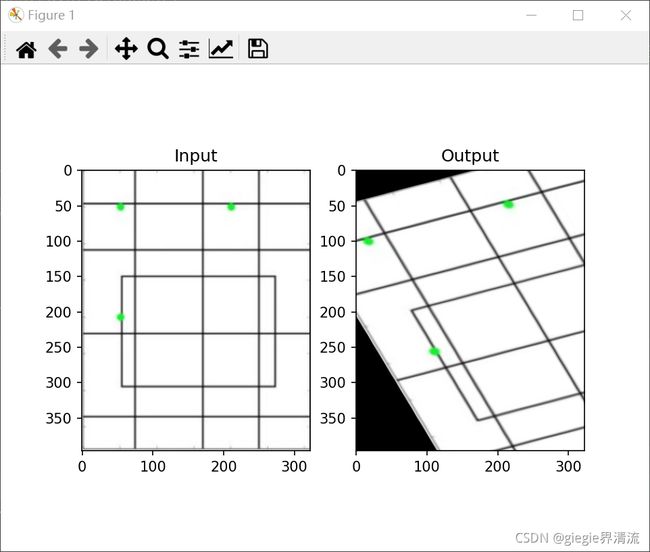
透视变换
对透视转换,你需要一个 3x3 变换矩阵。即使在转换之后,直线也将保持直线。要找到这个变换矩阵,需要输入图像上的 4 个点和输出图像上的相应点。在这四点中,任意三点不应该共线。然后通过 cv2.getPerspectiveTransform 找到变换矩阵。然后对这个 3x3 变换矩阵使用 cv2.warpPerspective。
代码:
import cv2
import matplotlib.pyplot as plt
import numpy as np
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/sudoku.png')
rows, cols, ch = img.shape
pts1 = np.float32([[56, 65], [368, 52], [28, 387], [389, 390]])
pts2 = np.float32([[0, 0], [300, 0], [0, 300], [300, 300]])
M = cv2.getPerspectiveTransform(pts1, pts2)
dst = cv2.warpPerspective(img, M, (300, 300))
plt.subplot(121), plt.imshow(img), plt.title('Input')
plt.subplot(122), plt.imshow(dst), plt.title('Output')
plt.show()
结果:
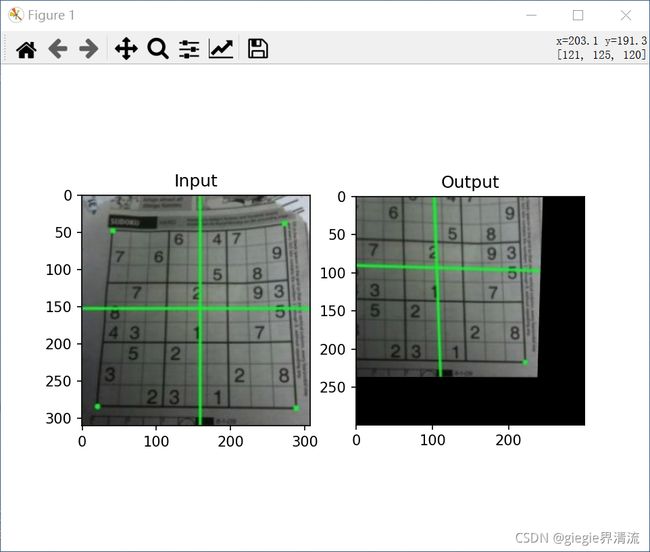
二值化
简单阈值法
此方法是直截了当的。如果像素值大于阈值,则会被赋为一个值(可能为白色),否则会赋为另一个值(可能为黑色)。使用的函数是 cv2.threshold。第一个参数是源图像,它应该是灰度图像。第二个参数是阈值,用于对像素值进行分类。第三个参数是 maxval,它表示像素值大于(有时小于)阈值时要给定的值。opencv 提供了不同类型的阈值,由函数的第四个参数决定。不同的类型有:
- cv.THRESH_BINARY
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV
获得两个输出。第一个是 retval,稍后将解释。第二个输出是我们的阈值图像。
代码:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', cv2.IMREAD_UNCHANGED)
ret1, thresh1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
ret2, thresh2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
ret3, thresh3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
ret4, thresh4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
ret5, thresh5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i+1)
plt.imshow(images[i], cmap='gray')
plt.title(titles[i])
plt.xticks([])
plt.yticks([])
plt.show()
结果:

可以看到,其他五幅图像都以不同的方式区分像素。
自适应阈值
在前一节中,我们使用一个全局变量作为阈值。但在图像在不同区域具有不同照明条件的条件下,这可能不是很好。在这种情况下,我们采用自适应阈值。在此,算法计算图像的一个小区域的阈值。因此,我们得到了同一图像不同区域的不同阈值,对于不同光照下的图像,得到了更好的结果。
它有三个“特殊”输入参数,只有一个输出参数。
-
Adaptive Method :它决定如何计算阈值。
-
cv2.ADAPTIVE_THRESH_MEAN_C :阈值是指邻近地区的平均值。
-
cv2.ADAPTIVE_THRESH_GAUSSIAN_C :阈值是权重为高斯窗的邻域值的加权和。
-
Block Size :它决定了计算阈值的窗口区域的大小。
-
C :它只是一个常数,会从平均值或加权平均值中减去该值。
下面的代码比较了具有不同照明的图像的全局阈值和自适应阈值:
代码:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', 0)
img = cv2.medianBlur(img, 5)
ret, thresh1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
thresh2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY, 11, 2)
thresh3 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY, 11, 2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, thresh1, thresh2, thresh3]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
结果:
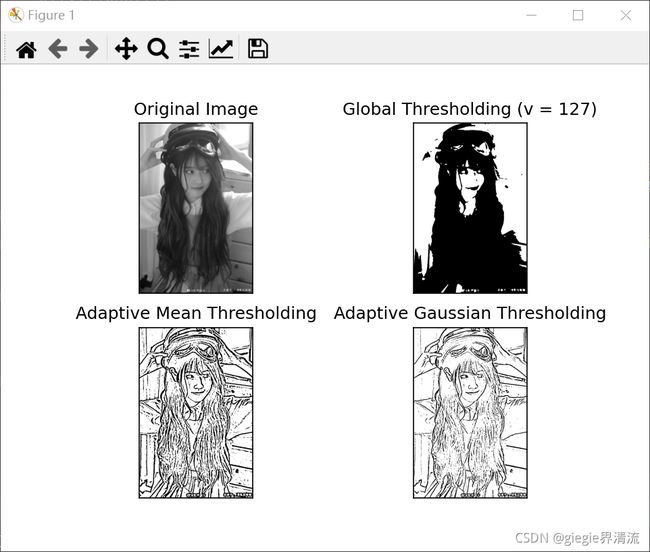
Otsu二值化(俗称大津法)
在第一部分中,有一个参数 retval。当我们进行 Otsu 二值化时,它的用途就来了。那是什么?
在全局阈值化中,我们使用一个任意的阈值,对吗?那么,我们如何知道我们选择的值是好的还是不好的呢?答案是,试错法。但是考虑一个双峰图像(简单来说,双峰图像是一个直方图有两个峰值的图像)。对于那个图像,我们可以近似地取这些峰值中间的一个值作为阈值,对吗?这就是 Otsu 二值化所做的。所以简单来说,它会自动从双峰图像的图像直方图中计算出阈值。(对于非双峰图像,二值化将不准确。)
为此,我们使用了 cv2.threshold 函数,但传递了一个额外的符号 cv2.THRESH_OTSU 。对于阈值,只需传入零。然后,该算法找到最佳阈值,并作为第二个输出返回 retval。如果不使用 otsu 阈值,则 retval 与你使用的阈值相同。
查看下面的示例。输入图像是噪声图像。在第一种情况下,我应用了值为 127 的全局阈值。在第二种情况下,我直接应用 otsu 阈值。在第三种情况下,我使用 5x5 高斯核过滤图像以去除噪声,然后应用 otsu 阈值。查看噪声过滤如何改进结果。
代码:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/noisy.png', 0)
# 全局阈值
ret1, thresh1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# Otsu 阈值
ret2, thresh2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 经过高斯滤波的 Otsu 阈值
blur = cv2.GaussianBlur(img, (5, 5), 0)
ret3, thresh3 = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 画出所有的图像和他们的直方图
images = [img, 0, thresh1, img, 0, thresh2, blur, 0, thresh3]
titles = ['Original Noisy Image', 'Histogram', 'Global Thresholding (v=127)',
'Original Noisy Image', 'Histogram', "Otsu's Thresholding",
'Gaussian filtered Image', 'Histogram', "Otsu's Thresholding"]
for i in range(3):
plt.subplot(3, 3, i * 3 + 1), plt.imshow(images[i * 3], 'gray')
plt.title(titles[i * 3]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 2), plt.hist(images[i * 3].ravel(), 256)
plt.title(titles[i * 3 + 1]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 3), plt.imshow(images[i * 3 + 2], 'gray')
plt.title(titles[i * 3 + 2]), plt.xticks([]), plt.yticks([])
plt.show()
结果:
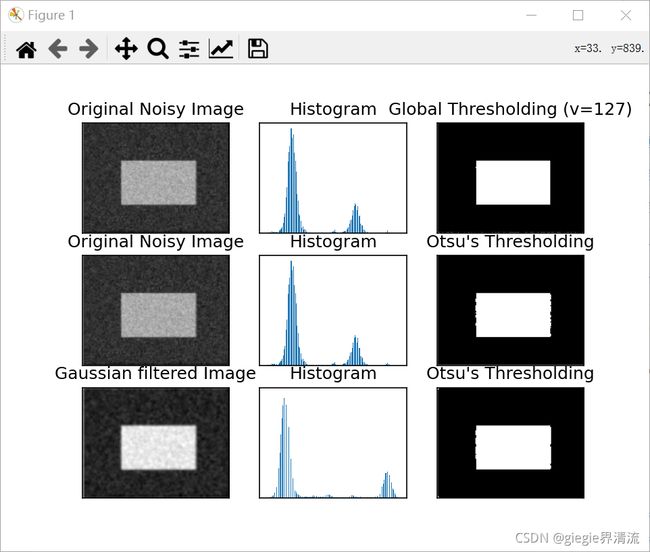
Otsu 二值化原理
本节演示了 otsu 二值化的 python 实现,以展示它的实际工作原理。
由于我们使用的是双峰图像,因此 Otsu 的算法试图找到一个阈值(t),该阈值将由下式计算得到的类内加权方差最小化:

其中:

它实际上找到一个 T 值,它位于两个峰值之间,使得两个类的方差最小。它可以简单地在 python 中实现,如下所示:
代码:
import cv2
import numpy as np
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/noisy.png', 0)
blur = cv2.GaussianBlur(img, (5, 5), 0)
# 找到归一化直方图还有累计分布函数
hist = cv2.calcHist([blur], [0], None, [256], [0, 256])
hist_norm = hist.ravel() / hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in range(1, 256):
p1, p2 = np.hsplit(hist_norm, [i]) # 概率
q1, q2 = Q[i], Q[255] - Q[i] # 类别总和
b1, b2 = np.hsplit(bins, [i]) # 权重
# f 找到均值与方差
m1, m2 = np.sum(p1 * b1) / q1, np.sum(p2 * b2) / q2
v1, v2 = np.sum(((b1 - m1) ** 2) * p1) / q1, np.sum(((b2 - m2) ** 2) * p2) / q2
# 计算最小函数
fn = v1 * q1 + v2 * q2
if fn < fn_min:
fn_min = fn
thresh = i
# 用 Opencv2 函数的 otsu'阈值
ret, otsu = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
print("{} {}".format(thresh, ret))
结果:

滤波
二维卷积(图像滤波)
与一维信号一样,图像也可以通过各种低通滤波器(LPF)、高通滤波器(HPF)等进行过滤。LPF 有助于消除噪音、模糊图像等。HPF 滤波器有助于在图像中找到边缘。
opencv 提供了函数 cv2.filter2D(),用于将内核与图像卷积起来。作为一个例子,我们将尝试对图像进行均值滤波操作。5x5 均值滤波卷积核如下:
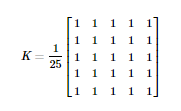
操作如下:将该内核中心与一个像素对齐,然后将该内核下面的所有 25 个像素相加,取其平均值,并用新的平均值替换这个25x25窗口的中心像素。它继续对图像中的所有像素执行此操作。试试下面这段代码并观察结果:
代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/noisy.png')
kernel = np.ones((5, 5), np.float32) / 25
dst = cv2.filter2D(img, -1, kernel)
plt.subplot(121), plt.imshow(img), plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(dst), plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
结果:
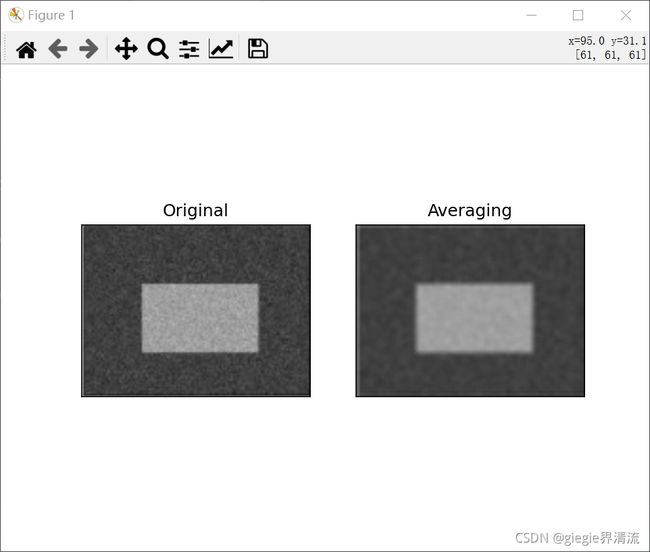
可见图像在滤波的作用下变得模糊了。
图像模糊(图像平滑)
图像模糊是通过将图像与低通滤波核卷积来实现的。它有助于消除噪音。它实际上从图像中删除高频内容(例如:噪声、边缘)。所以在这个操作中边缘有点模糊。(好吧,有一些模糊技术不会使边缘太模糊)。OpenCV 主要提供四种模糊技术。
均值滤波
这是通过用一个归一化的滤波器内核与图像卷积来完成的。它只需取内核区域下所有像素的平均值并替换中心元素。这是通过函数 cv2.blur()或 cv2.boxFilter() 完成的。有关内核的更多详细信息,请查看文档。我们应该指定滤波器内核的宽度和高度。3x3 标准化框滤波器如下所示:
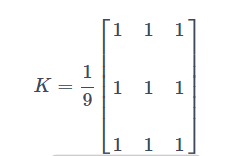
注意 :如果你不用标准化滤波,使用cv2.boxFilter(),传入 normalize=False 参数。
5x5 核的简单应用如下所示:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/opencv.jpg')
blur = cv2.blur(img, (5, 5))
plt.subplot(121), plt.imshow(img), plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(blur), plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
结果:
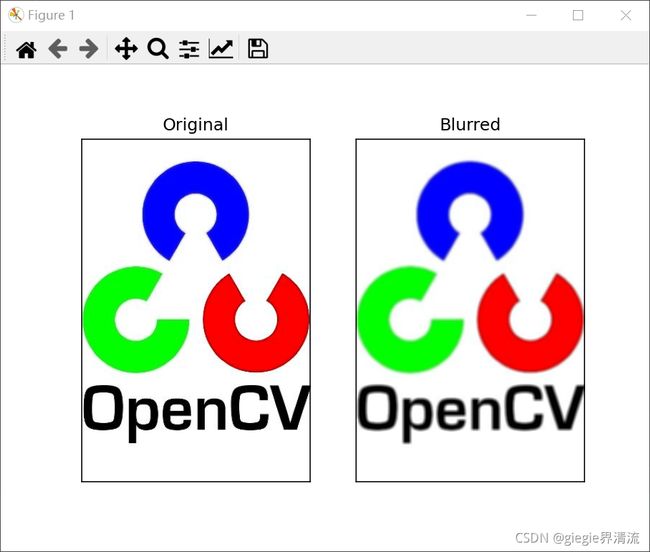
高斯滤波
在这种情况下,使用高斯核代替了核滤波器。它是通过函数 **cv2.GaussianBlur()**完成的。我们应该指定内核的宽度和高度,它应该是正数并且是奇数(奇数才有一个中位数)。我们还应该分别指定 x 和 y 方向的标准偏差、sigmax 和 sigmay。如果只指定 sigmax,则 sigmay 与 sigmax 相同。如果这两个值都是 0,那么它们是根据内核大小计算出来的。高斯模糊是消除图像高斯噪声的有效方法。
如果需要,可以使用函数 cv.getGaussianKernel() 创建高斯内核。
上述代码可以修改为高斯滤波器:
blur = cv2.GaussianBlur(img,(5,5),0)
代码:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/opencv.jpg')
blur = cv2.GaussianBlur(img, (5, 5), 0)
plt.subplot(121), plt.imshow(img), plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(blur), plt.title('GaussianBlurred')
plt.xticks([]), plt.yticks([])
plt.show()
结果:

中值滤波
在这里,函数 cv2.medianBlur() 取内核区域下所有像素的中值,将中央元素替换为该中值。这对图像中的椒盐噪声非常有效。有趣的是,在上面的过滤器中,中心元素是一个新计算的值,它可能是图像中的像素值,也可能是一个新值。但在中值模糊中,中心元素总是被图像中的一些像素值所取代,可以有效降低噪音。它的内核大小应该是一个正的奇数整数。
在这个演示中,我在原始图像中添加了 5000个椒盐噪声,并应用了中间模糊。只需要将上面代码改为中值滤波器:
median = cv2.medianBlur(img,5)
代码:
import random
import cv2
from matplotlib import pyplot as plt
# 添加椒盐噪声
def noise(dst):
height, width = dst.shape[:2]
for _ in range(height*width//4):
x = random.randint(0, height-1)
y = random.randint(0, width-1)
dst[x, y] = 255 # 添加盐噪声
p = random.randint(0, height-1)
q = random.randint(0, width-1)
dst[p, q] = 0 # 添加椒噪声
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', 0)
plt.subplot(131), plt.imshow(img, cmap='gray'), plt.title('Original')
plt.xticks([]), plt.yticks([])
noise(img)
plt.subplot(132), plt.imshow(img, cmap='gray'), plt.title('Noise')
plt.xticks([]), plt.yticks([])
median = cv2.medianBlur(img, 5)
plt.subplot(133), plt.imshow(median, cmap='gray'), plt.title('MedianBlurred')
plt.xticks([]), plt.yticks([])
plt.show()
结果:
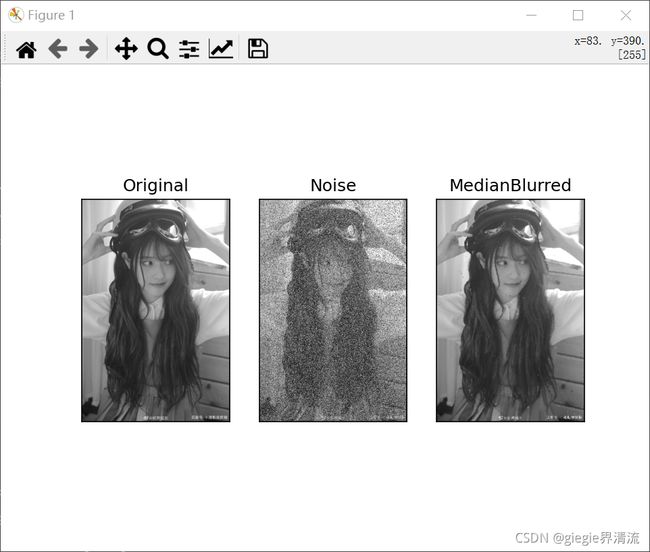
可以看到,第二张照片是在原图的基础上添加了噪声,第三张图片虽然去除了噪声,但仍然会有部分模糊。
双边滤波
cv2.bilateralFilter() 在保持边缘锐利的同时,对噪声去除非常有效。但与其他过滤器相比,操作速度较慢。我们已经看到高斯滤波器取像素周围的邻域并找到其高斯加权平均值。该高斯滤波器是一个空间函数,即在滤波时考虑相邻像素。但是它不考虑像素是否具有几乎相同的强度,也不考虑像素是否是边缘像素。所以它也会模糊边缘,这是我们不想做的。
双边滤波器在空间上也采用高斯滤波器,而另一个高斯滤波器则是像素差的函数。空间的高斯函数确保模糊只考虑邻近像素,而强度差的高斯函数确保模糊只考虑与中心像素强度相似的像素。所以它保留了边缘,因为边缘的像素会有很大的强度变化。
下面的示例显示使用双边滤波,同样的,只需要将上面代码改为双边滤波器:
blur = cv2.bilateralFilter(img,9,75,75)
代码:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('C:/Users/Zhang-Lei/Desktop/snack_gray.png', 0)
plt.subplot(121), plt.imshow(img, cmap='gray'), plt.title('Original')
plt.xticks([]), plt.yticks([])
blur = cv2.bilateralFilter(img, 9, 75, 75)
plt.subplot(122), plt.imshow(blur, cmap='gray'), plt.title('BilateralBlurred')
plt.xticks([]), plt.yticks([])
plt.show()
结果:

可见图像经过双边滤波变得模糊了一些。
