python3GUI--微博图片爬取工具V1.5(附源码)
文章目录
- 一.准备工作
- 二.预览
-
- 1.启动
- 2.搜索
- 3.运行中
- 4.结果
- 三.设计流程
-
- 1.总体设计
- 2.详细设计
- 四.源代码
-
- 1.Weibo_Pic_Crawl-GUI-V1.5.py
- 2.Weibo_Crawl_Engine.py
- 五.总结说明
鉴于前面python3GUI–微博图片爬取工具(附源码),简单实现了微博大图爬取,简单的界面交互,本次在前篇上进行改进,精简代码量,增加用户搜索接口,展示用户头像,便于精准定位用户,准确爬取用户图片。
一.准备工作
基于Tkinter、requests
Tkinter为内置库,requests为第三方库,需要额外安装一下,具体不多介绍
二.预览
1.启动

去掉了相关图片、图标,界面更加精简。
2.搜索
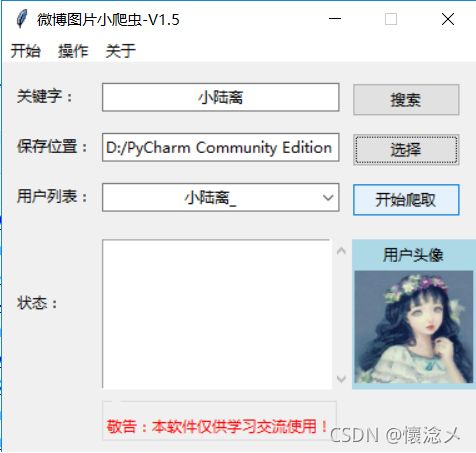
通过调用微博两个搜索接口,将搜索出来的用户展示在分组框,供用户选择,展示搜索出的第一个用户头像,便于用户确定用户。
3.运行中

4.结果

这里仅拿出一张图片用作结果展示
三.设计流程
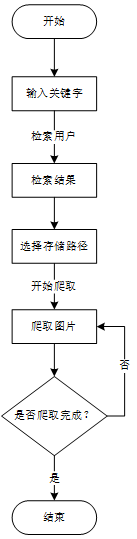
1.总体设计
本程序主要操作流程
2.详细设计
Weibo_Crawl_Engine.py主要思路

四.源代码
1.Weibo_Pic_Crawl-GUI-V1.5.py
import io
import os
import threading
from PIL import ImageTk
from PIL import Image as imim
from tkinter import ttk
from tkinter import *
from tkinter import messagebox
from tkinter.filedialog import *
from tkinter.scrolledtext import ScrolledText
from Weibo_Crawl_Engine import Weibo_Pic_Spider
class App:
def __init__(self):
self.root=Tk()
self.root.title('微博图片小爬虫-V1.5')
self.root.resizable(0,0)
width=380
height=310
left=(self.root.winfo_screenwidth()-width)/2
top=(self.root.winfo_screenheight()-height)/2
self.root.geometry('%dx%d+%d+%d'%(width,height,left,top))
self.s=Weibo_Pic_Spider()
self.create_widgets()
self.set_widgets()
self.place_widgets()
self.root.mainloop()
def create_widgets(self):
self.label1=ttk.Label(self.root,text='关键字:')
self.entry_keyword_var=StringVar()
self.entry_keyword=ttk.Entry(self.root,textvariable=self.entry_keyword_var,justify='center')
self.btn_search=ttk.Button(self.root,text='搜索',command=self.do_search_users)
self.label_disk=ttk.Label(self.root,text='保存位置:')
self.entry_savelocation_var=StringVar()
self.entry_savelocation=ttk.Entry(self.root,textvariable=self.entry_savelocation_var,justify='center')
self.check_opendir_var=BooleanVar(value=False)
self.label_userlist=ttk.Label(self.root,text='用户列表:')
self.combobox_userlist=ttk.Combobox(self.root,value=[],state='readonly',justify='center')
self.btn_set_save_dir=ttk.Button(self.root,text='选择',command=self.select_save_dir)
self.btn_startcrawl=ttk.Button(self.root,text='开始爬取',command=lambda :self.thread_it(self.do_download_pic))
self.label_state=ttk.Label(self.root,text='状态:')
self.scrolltext_state=ScrolledText(self.root)
self.label_show_userimg=ttk.Label(self.root,text='用户头像',justify="center",compound='bottom',background='lightblue',width=20)
self.lableframe=ttk.Labelframe(self.root,text='')
self.lable_tip=ttk.Label(self.lableframe,text='敬告:本软件仅供学习交流使用!',foreground='red')
self.m=Menu(self.root)
self.root['menu'] = self.m
self.s1=Menu(self.m,tearoff=False)
self.s2=Menu(self.m,tearoff=False)
self.s3=Menu(self.m,tearoff=False)
def set_widgets(self):
self.m.add_cascade(menu=self.s1,label='开始')
self.m.add_cascade(menu=self.s2,label='操作')
self.m.add_cascade(menu=self.s3,label='关于')
self.s1.add_command(label='打开文件夹',command=lambda:os.startfile(self.abs_path))
self.s1.add_separator()
self.s1.add_command(label='退出',command=self.quit_window)
self.combobox_userlist.bind("<>" ,self.show_user_head)
self.entry_keyword.bind('' ,self.do_search_users)
self.root.protocol("WM_DELETE_WINDOW",self.quit_window)
self.open_dir_var=IntVar()
#这里只能使用checkbutton用于开关
self.s2.add_command(label='搜索',command=self.do_search_users)
self.s2.add_command(label='开始爬取',command=lambda :self.thread_it(self.do_download_pic))
self.s2.add_separator()
self.s2.add_checkbutton(label='下载完后打开文件夹',variable=self.open_dir_var,command=self.open_dir_after_crawl)
self.btn_startcrawl.config(state=DISABLED)
self.s2.entryconfig("开始爬取", state=DISABLED)
self.s3.add_command(label='关于作者',command=lambda :messagebox.showinfo('作者信息','作者:懷淰メ\nversion:1.5'))
def place_widgets(self):
self.label1.place(x=10,y=15)
self.entry_keyword.place(x=80,y=15,width=190)
self.btn_search.place(x=280,y=15)
self.label_disk.place(x=10,y=55)
self.entry_savelocation.place(x=80,y=55,width=190)
self.btn_set_save_dir.place(x=280,y=55)
self.label_userlist.place(x=10,y=95)
self.combobox_userlist.place(x=80,y=95,width=190)
self.btn_startcrawl.place(x=280,y=95)
self.label_show_userimg.place(x=280,y=140,height=120)
self.label_state.place(x=10,y=180)
self.scrolltext_state.place(x=80,y=140,width=200,height=120)
self.lableframe.place(x=80,y=260)
self.lable_tip.pack(anchor="w",fill=X)
def show_user_head(self,*args):
current_index=self.combobox_userlist.current()
paned_img=PanedWindow(self.label_show_userimg)
head_img=self.search_result[current_index]['user_head_img'].split('?')[0]
image_bytes=self.s.get_img_bytes(head_img)
data_stream = io.BytesIO(image_bytes)
pil_image = imim.open(data_stream)
photo = pil_image.resize((95, 90))
paned_img.image=ImageTk.PhotoImage(photo)
self.label_show_userimg.config(image=paned_img.image,compound='bottom')
def do_search_users(self,*args):
self.combobox_userlist.config(value=[])
try:
self.search_result.clear()
except AttributeError:
pass
key_word=self.entry_keyword_var.get().strip()
if key_word !='':
self.search_result=self.s.get_users(key_word)
if self.search_result:
user_names=[user_['user_name'] for user_ in self.search_result]
self.combobox_userlist.config(value=user_names)
self.btn_startcrawl.config(state=NORMAL)
self.s2.entryconfig("开始爬取", state=NORMAL)
self.combobox_userlist.current(0)
self.show_user_head()
else:
messagebox.showinfo('提示',f'很抱歉,没有检索到关于[{
key_word}]的用户!')
else:
messagebox.showwarning('警告','关键字不能为空!')
def do_download_pic(self):
try:
if self.entry_savelocation_var.get()!='':
current_item=self.search_result[self.combobox_userlist.current()]
user_id=current_item['user_id']
user_name=current_item['user_name']
self.s.set_start_url(user_id)
abs_path=self.entry_savelocation_var.get()+f'/{
user_name}'
self.abs_path=abs_path
self.s.do_make_dirs(abs_path)
for pic in self.s.get_pics_url():
file_name = pic.split('/')[-1]
self.s.do_download_pic(pic,file_name,abs_path)
self.insert_into_scrolltext(f"{
file_name}下载完成...")
else:
self.btn_startcrawl.config(state=NORMAL)
self.s2.entryconfig("开始爬取", state=NORMAL)
if self.open_dir_flag:
os.startfile(self.abs_path)
else:
messagebox.showwarning('警告', '请选择图片保存路径!')
self.select_save_dir()
except AttributeError :
messagebox.showwarning('警告','请先搜索!')
def select_save_dir(self):
while True:
save_dir=askdirectory(title = "选择一个图片保存目录", initialdir='./', mustexist = True)
if save_dir:
self.entry_savelocation_var.set(save_dir)
break
else:
messagebox.showwarning('警告','请选择图片保存的文件夹!')
def open_dir_after_crawl(self):
#图片爬取结束后,打开文件夹
if self.open_dir_var.get()==1:
self.open_dir_flag=True
else:
pass
def insert_into_scrolltext(self,line):
self.scrolltext_state.insert(END,line+'\n')
self.scrolltext_state.yview_moveto(1)
def quit_window(self,*args):
ret=messagebox.askyesno('退出','确定要退出?')
if ret :
self.root.destroy()
else:
pass
def thread_it(self,func,*args):
t=threading.Thread(target=func,args=args)
t.setDaemon(True)
t.start()
if __name__ == '__main__':
a=App()
2.Weibo_Crawl_Engine.py
#coding:utf-8
import threading
import requests
import json
import random
import os
from urllib.parse import quote
from lxml import etree
import urllib3
urllib3.disable_warnings()
class Weibo_Pic_Spider:
def __init__(self):
self.search_api1='https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D3%26q%3D{}%26t%3D0' #微博移动端API搜索
self.search_api2='https://s.weibo.com/user?q={}&Refer=weibo_user' #静态网页搜索
self.header1 = {
'User-Agent': self.get_ua()}
self.user_list=[]
def get_user_list1(self,key_word):
full_url1=self.search_api1.format(key_word)
header1={
'User-Agent': self.get_ua()}
r=requests.get(full_url1,headers=header1)
if r.status_code==200:
_json=json.loads(r.text)
users = _json['data']['cards'][1].get('card_group')
for user_ in users:
item={
}
user_info = user_.get('user')
item['user_name'] = user_info.get('screen_name')
item['user_id'] = user_info.get('id')
item['user_head_img']=user_info.get('profile_image_url')
self.user_list.append(item)
#解析出图片地址
def get_user_list2(self,key_word):
current_username=[user["user_name"] for user in self.user_list]
full_url2=self.search_api2.format(quote(key_word))
self.header2={
'Host': 's.weibo.com',
'Referer':full_url2,
'User-Agent': self.get_ua(),
}
r = requests.get(full_url2, headers=self.header2)
if r.status_code == 200:
res=etree.HTML(r.text)
selector=res.xpath('//div[@id="pl_user_feedList"]/div')
for data in selector:
item={
}
user_name=''.join(data.xpath('.//div/a[1]//text()'))
if user_name in current_username:
#根据API1获取的用户在这里不给予显示
continue
item['user_name']=user_name
item['user_id']=''.join(data.xpath('./div[@class="info"]/div/a[@uid]/@uid'))
item['user_head_img']=''.join(data.xpath('.//div[@class="avator"]/a/img/@src'))
self.user_list.append(item)
def get_users(self,key_word):
"""
通过API1和API2获取检索的用户信息
:param key_word:
:return:
"""
self.get_user_list1(key_word)
self.get_user_list2(key_word)
if len(self.user_list)!=0:
# print(self.user_list)
return self.user_list
else:
return False
五.总结说明
本次在原版(V1.0版本)进行升级改进,仍旧实现微博图片高清原图的解析下载,但是相比之前版本主要提升在于:
1.去除无用功能,精简代码
2.将GUI于爬虫分离开来,解耦
3.在用户检索上,加入了网页版用户搜索API,增加了可被检索的用户数量
4.选择要用户后,会显示指定头像
5.优化程序运行输出逻辑
程序打包好放在了蓝奏云,思路、代码方面有什么不足欢迎各位大佬指正、批评!