「Scrapy 爬虫框架」命令行工具(Command line tool)详解
文章目录
- 内容介绍
- 配置设置
- Scrapy项目的默认结构
- 在项目之间共享根目录
- Scrapy的工具
-
- 命令汇总
- 全局命令
- 项目命令
内容介绍
开发环境为 Python3.6,Scrapy 版本 2.4.x ,爬虫项目全部内容索引目录
看懂Python爬虫框架,所见即所得一切皆有可能
本章带你学习基于 Python3 的 Scrapy 爬虫框架 中数据爬取过程中Scrapy工具提供的每个命令都接受一组不同的参数和选项。可以使用命令行完成对应设置内容。
代码内容基于「Scrapy 爬虫框架」源码版本 2.4.0 ,更新内容会进行标记说明对应版本。
配置设置
每个 scrapy 项目下都会生成一个 scrapy.cfg 配置文件,这部分内容自动生成不需要进行操作,未来配置一下项目中可能会进行调整。
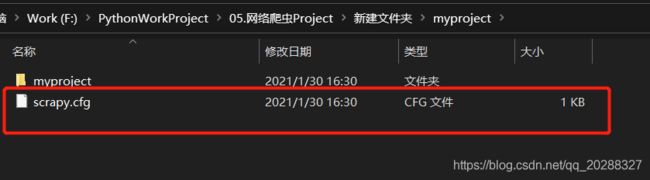
Scrapy项目的默认结构
使用命令行创建目录
scrapy startproject myproject
默认生成目录结构
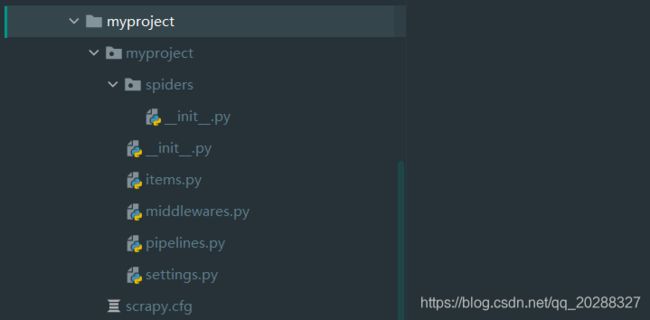
根目录下的 scrapy.cfg 默认生成,包含设置中的配置模块
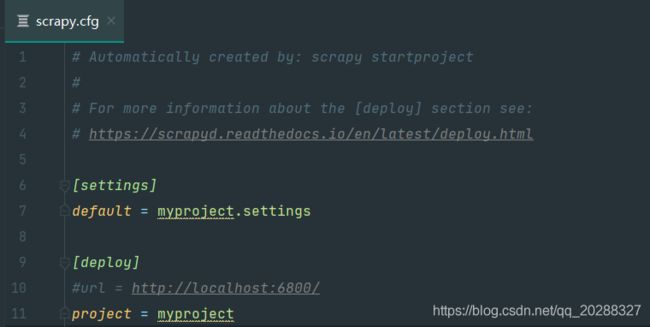
在项目之间共享根目录
多个项目可以共享 scrapy.cfg 但是要设置项目需要settings
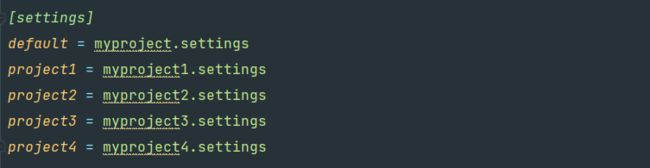
默认使用default设置,可以使用命令行进行修改。
export SCRAPY_PROJECT=project2
scrapy settings --get BOT_NAME
Scrapy的工具
命令汇总
scrapy -h # 查看所有可用命令
scrapy <command> -h # 查看对应命令的帮助
全局命令:
startproject:scrapy startproject <project_name> [project_dir] # 创建项目
genspider:scrapy genspider [-t template] <name> <domain> # 创建新的Spider
settings:scrapy settings [options] # 获取配置
runspider:scrapy runspider <spider_file.py> # 运行Python文件里的Spider,不需要创建项目
shell:scrapy shell [url] # 启动Scrapy交互终端,可用于调试
fetch:scrapy fetch <url> # 使用Scrapy下载器下载给定的URL,并将获取的内容送到标准输出
view:scrapy view <url> # 浏览器中打开URL
version:scrapy version [-v] # 打印版本
项目命令:
crawl:scrapy crawl <spider> # 使用spider进行爬取
check:scrapy check [-l] <spider> # 运行contract检查
list:scrapy list # 列出当前项目可用的所有spider
edit:scrapy edit <spider> # 使用EDITOR环境变量中设定的编辑器编辑spider
parse:scrapy parse <url> [options] # 获取给定的URL并使用spider分析处理
bench:scrapy bench # 运行benchmark测试
全局命令
- 1. startproject 创建项目
# 基础语法
scrapy startproject <project_name> [project_dir]
# 创建一个名称为myproject的项目
scrapy startproject myproject
- 2. genspider 创建蜘蛛spider
# 基础语法
scrapy genspider [-t template] <name> <domain>
# 创建一个名称为myspider的根蜘蛛 就是爬虫文件
cd [project_dir]
scrapy myspider mydomain.com # 创建一个新的含作用域的Spider
或
scrapy myspider " " # 创建一个新的不含作用域的Spider
- 3. fetch 输出打印页面内容
# 基础语法
scrapy fetch <url>
# 输出内容举例
scrapy fetch --nolog http://xxxxx.com/xxx.html
- 4. view 浏览器打开url
# 基础语法
scrapy view <url>
# 输出内容举例
scrapy view --nolog http://xxxxx.com/xxx.html
- 5. shell 终端调试
# 基础语法
scrapy shell <url>
# 输出内容举例,调试命令
scrapy shell http://xxxxx.com/xxx.html

- 6. settings 获取配置信息
# 基础语法
scrapy settings [options]
# 获取配置文件设置信息,鸡肋 直接打开文件看就行了
scrapy settings --get BOT_NAME
scrapy settings --get DOWNLOAD_DELAY
- 7. runspider 直接执行spider文件
# 基础语法
scrapy runspider <spider_file.py>
scrapy runspider myspider.py
- 8.version 打印版本
# 基础语法
scrapy version [-v]
scrapy version
项目命令
- 1. crawl 执行爬虫spider文件
# 基础语法
scrapy crawl <spider>
# 执行创建好的myspider文件
scrapy crawl myspider
- 2. check 合同检查
# 基础语法
scrapy check [-l] <spider>
# 执行创建好的myspider文件
scrapy check -l myspider
- 3. list spider列表
# 基础语法
scrapy list
# 打印项目中的全部spider文件
scrapy list
- 4. edit 编辑spider
# 基础语法
scrapy edit <spider>
# 编辑spider文件,很鸡肋直接用IDE
scrapy edit myspider
- 5. parse 解析页面
# 基础语法
scrapy parse <url> [options] # 使用spider分析处理
# options参数说明
--spider=SPIDER*绕过蜘蛛自动检测和强制使用特定蜘蛛
--a NAME=VALUE设置蜘蛛参数(可以重复)
--callback或-c:用作解析响应的回调的Spider方法
--meta或-m::将传递给回调请求的其他请求元。这必须是一个有效的json字符串。示例:-meta=‘{
“foo:”bar“}’
--cbkwargs::将传递给回调的其他关键字参数。这必须是一个有效的json字符串。示例:-cbkwargs=‘{
“foo:”bar“}’
--pipelines*通过管道处理项目
--rules或-r*使用CrawlSpider用于解析响应的回调规则(即蜘蛛方法)
--noitems::不要显示擦伤的物品
--nolinks*不要显示提取的链接
--nocolour*避免使用配色器对输出进行着色。
--depth或-d*应该递归跟踪请求的深度级别(缺省值:1)
--verbose或-v*显示每个水深级别的信息
--output或-o将刮过的项目转储到文件中
# 解析某个页面
scrapy parse http://xxxxx.com/xxx.html [-options]
- 6. bench 运行benchmark测试
# 基础语法
scrapy bench
# 执行benchmark测试
scrapy bench