开源web框架django知识总结(四)
开源web框架django知识总结(四)
一、ORM查询操作
查询简介:
数据库的查询需要使用管理器对象进行
通过MyModel.objects管理器方法调用查询方法

all()方法
用法:MyModel.objects.all() 作用:查询MyModel实体中所有数据,等同于 select * from table 返回值:QuerySet容器对象,内部存放MyModel实例
#在shell中执行
python manage.py shell
>>> from bookstore.models import Book
>>> books = Book.objects.all()
>>> books
[(1)>, (2)>, (3)>, (4)>, (5)>]>
>>> for book in books:
... print("书名",book.title,"出版社",book.pub) # 注意格式tab键
...
书名 Python 出版社 清华大学出版社
书名 Django 出版社 清华大学出版社
书名 Jquery 出版社 机械工业出版社
书名 Linux 出版社 机械工业出版社
书名 HTML5 出版社 清华大学出版社
>>>
##################################################
#可以在模型类中定义“__str__"方法,自定义QuerySet中的输出格式,例如 注意缩进
def __str__(self):
return '%s_%s_%s_%s'%(self.title, self.pub, self.price, self.market_price)

value(‘列1’,‘列2’,…) 方法
用法:MyModel.objects.value(…) 作用:查询部分列的数据并返回。等同于select 列1,列2 from xxx 返回值:QuerySet 返回查询结果容器,容器内存字典,每个字典代表一条数据,格式为:{‘列1’:值1,‘列2’:值2}
>>> from bookstore.models import Book
>>> books = Book.objects.all()
>>> books
[.00_25.00>, .00_75.00>, .00_85.00>, .00_60.00>, .00_105.00>]>
>>> a2 = Book.objects.values('title','pub')
>>> a2
[{
'title': 'Python', 'pub': '清华大学出版社'}, {
'title': 'Django', 'pub': '清华大学出版社'}, {
'title': 'Jquery', 'pub': '机械工业出版社'}, {
'title': 'Linux', 'pub': '机械工业出版社'}, {
'title': 'HTML5', 'pub': '清华大学出版社'}]>
>>> for book in a2:
... print(book)
...
{
'title': 'Python', 'pub': '清华大学出版社'}
{
'title': 'Django', 'pub': '清华大学出版社'}
{
'title': 'Jquery', 'pub': '机械工业出版社'}
{
'title': 'Linux', 'pub': '机械工业出版社'}
{
'title': 'HTML5', 'pub': '清华大学出版社'}
>>> for book in a2:
... print(book['title'])
...
Python
Django
Jquery
Linux
HTML5
>>>

value_list(‘列1’,‘列2’,…) 方法
用法:MyModel.objects.value_list(…) 作用:返回元组形式的查询结果。等同于select 列1,列2 from xxx 返回值:QuerySet 容器对象,内部存放”元组“,会将查询出来的数据封装到元组中,再封装到查询集合QuerySet 中
>>> a3 = Book.objects.values_list('title','pub')
>>> a3
[('Python', '清华大学出版社'), ('Django', '清华大学出版社'), ('Jquery', '机械工业出版社'), ('Linux', '机械工业出版社'), ('HTML5', '清华大学出版社')]>
>>> for book in a3:
... print(book)
...
('Python', '清华大学出版社')
('Django', '清华大学出版社')
('Jquery', '机械工业出版社')
('Linux', '机械工业出版社')
('HTML5', '清华大学出版社')
>>> for book in a3:
... print(book[0])
...
Python
Django
Jquery
Linux
HTML5

order_by()方法
用法:MyModel.objects.order_by(’-列’,‘列’) 作用:与all()方法不同,它会用SQL语句的ORDER BY子句对查询结果进行,根据某个字段选择性的进行排序
说明:默认是按照升序排序,降序则需要在”列“前增加,‘-’号,表示
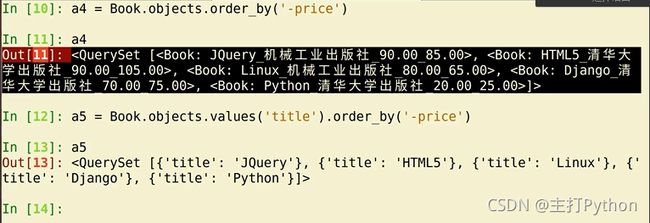
>>> a4 = Book.objects.order_by('-price')
>>> a4
[.00_85.00>, .00_105.00>, .00_60.00>, .00_75.00>, .00_25.00>]>
>>> a5 = Book.objects.values('title').order_by('-price')
>>> a5
[{
'title': 'Jquery'}, {
'title': 'HTML5'}, {
'title': 'Linux'}, {
'title': 'Django'}, {
'title': 'Python'}]>
>>> a5 = Book.objects.order_by('-price').values('title')
>>> a5
[{
'title': 'Jquery'}, {
'title': 'HTML5'}, {
'title': 'Linux'}, {
'title': 'Django'}, {
'title': 'Python'}]>
>>> a5.query
.db.models.sql.query.Query object at 0x7fcfe8247be0>
>>> print(a5.query)
SELECT `book`.`title` FROM `book` ORDER BY `book`.`price` DESC
>>>

mysite3\bookstore\views.py
from django.shortcuts import render
from .models import Book
# Create your views here.
def all_book(request):
all_book = Book.objects.all()
return render(request, 'bookstore/all_book.html', locals())
templates\bookstore\all_book.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>查看所有书籍title>
head>
<body>
<table border="1">
<tr>
<th>idth>
<th>titleth>
<th>pubth>
<th>priceth>
<th>market_priceth>
<th>opth>
tr>
{% for book in all_book %}
<tr>
<td>{
{ book.id }}td>
<td>{
{ book.title }}td>
<td>{
{ book.pub }}td>
<td>{
{ book.price }}td>
<td>{
{ book.market_price }}td>
<td>
<a href="">更新a>
<a href="">删除a>
td>
tr>
{% endfor %}
table>
body>
html>
urls.py(主路由)
path('bookstore/',include('bookstore.urls')),
urls.py(子路由)
path('all_book', views.all_book),
条件查询方法:
filter(条件)
语法:MyModel.objects.filter(属性1=值1,属性2=值2) 作用:返回包含此条件的全部数据集
返回值:QuerySet容器对象,内部存放MyModel实例 说明:当多个属性在一起时,为”与“关系。即当

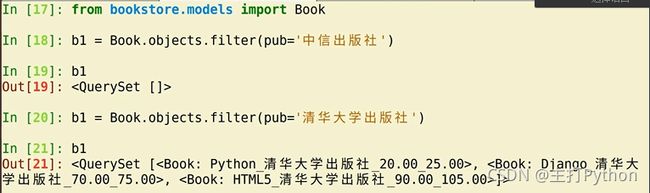
>>> from bookstore.models import Book
>>> b1 = Book.objects.filter(pub='中信出版社')
>>> b1
[]>
>>> b1 = Book.objects.filter(pub='清华大学出版社')
>>> b1
[.00_25.00>, .00_75.00>, .00_105.00>]>
>>> b1 = Book.objects.filter(pub='清华大学出版社',title='Python2')
>>> b1
[]>
>>> b1 = Book.objects.filter(pub='清华大学出版社',title='Python')
>>> b1
[.00_25.00>]>
>>>

exclude(条件)
语法:MyModel.objects.exclude(条件) 作用:返回不包含此条件的全部的数据集
示例:查询 清华大学出版社,定价不等于50意外的全部图书
books = Book.objects.exclude(pub = '清华大学出版社',price = 50)
for book in books:
print(book)
get(条件)
语法:MyModel.objects.get(条件) 作用:返回满足条件的唯一一条数据
all_books = Book.objects.all()
print(all_books.get(title='Python'))
#print(all_books.get(pub='清华大学出版社')) # 查到多条,会报错
说明:该方法只能返回一条数据,查询结果多余一条数据则抛出Model.MultipleObjectsReturned异常;查询结果如果没有数据则抛出Model.DoesNotExist异常
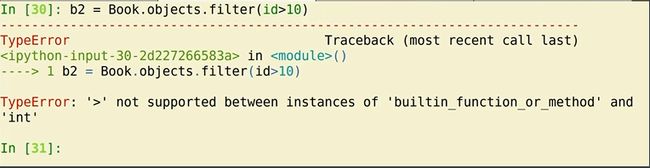
思考:如何做非等值的过滤查询,即 where id > 1
尝试:Book.objects.filter(id>1) ?
解决办法:查询谓词
定义:做更灵活的条件查询时,需要使用查询谓词。 说明:每一个查询谓词是一个独立的查询共嗯
__exact:等值匹配 示例:
from bookstore.models import Author
Author.objects.filter(id__exact=1)
# 等同于select * from author where id = 1
__contains:包含指定值 示例:
Author.objects.filter(name__contains='王')
# 等同于select * from author where name like '%w%'
__startswith:以xxx开始
__endswith:以xxx结束
__gt:大于指定值 样例:
Author.objects.filter(age__gt = 20)
# 等同于 select * from author where age > 20
__gte:大于等于
__lt:小于
__lte:小于等于
__in:查找数据是否在指定查询范围内 样例:
Author.objects.filter(countyr__in=['中国','日本','韩国'])
# 等同于 select * from author where country in ('中国','日本','韩国')
__range:查找数据是否在指定的区间范围内 样例:
# 查找年龄在某一区间内的所有作者
Author.objects.filter(age__range=(30,50))
# 等同于 SELECT ... WHERE Author BETWEEN 30 and 50;
二、更新操作
跟新单个数据
修改单个实体的某些字段值的步骤:
1、查:通过get()得到要修改的实体对象
2、改:通过对象.属性 的方式修改数据
3、保存:通过对象.save()保存数据
>>> b1 = Book.objects.get(id=1)
>>> b1
.00_25.00>
>>> b1.price = 22
>>> b1.save()
>>> b1
.00>
批量更新数据
直接调用QuerySet的update(属性=值),实现批量修改 示例:
>>> books = Book.objects.filter(id__gt=3)
>>> books.update(price=0)
2 #表示修改2条数据
>>> books
[.00_60.00>, .00_105.00>]>
>>> books = Book.objects.all()
>>> books.update(market_price=9.9)
5
>>> books
[.00_9.90>, .00_9.90>, .00_9.90>, .00_9.90>, .00_9.90>]>
>>>
views.py
from django.http import HttpResponse, HttpResponseRedirect
from django.shortcuts import render
from .models import Book
def update_book(request, book_id):
#bookstories/update_book/1
try:
book = Book.objects.get(id=book_id)
except Exception as e:
print('--update book error is %s'%(e))
return HttpResponse('--The book is not existed')
if request.method == 'GET':
return render(request, 'bookstore/update_book.html', locals())
elif request.method == 'POST':
price = request.POST['price']
market_price = request.POST['market_price']
#改
book.price = price
book.market_price = market_price
#保存
book.save()
return HttpResponseRedirect('/bookstore/all_book')
update_book.html
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>更改书籍title>
head>
<body>
<form action="/bookstore/update_book/{
{ book.id }}" method="post">
<p>
title <input type="text" value="{
{ book.title }}" disabled="disabled">
p>
<p>
pub <input type="text" value="{
{ book.pub }}" disabled="disabled">
p>
<p>
price <input type="text" name="price" value="{
{ book.price }}">
p>
<p>
market_price <input type="text" name="market_price" value="{
{ book.market_price }}">
p>
<p>
<input type="submit" value="更新">
p>
form>
body>
html>
补全all_book.html链接
<a href="/bookstore/update_book/{
{ book.id }}">更新a>
bookstore\urls.py(子路由)
path('update_book/' , views.update_book),
三、删除操作
单个数据删除
1、查找查询结果对应的一个数据对象
2、调用这个数据对象的delete()方法实现删除
views.py
# 物理删除
def delete_book(request):
#通过获取查询字符串 book_id 拿到要删除的book的id
book_id = request.GET.get('book_id')
if not book_id:
return HttpResponse('---请求异常')
try:
book = Book.objects.get(id=book_id)
book.delete()
except Exception as e:
print('---delete book get error %s'%(e))
return HttpResponse('---The book id is error')
return HttpResponseRedirect('/bookstore/all_book')
urls.py
path('delete_book', views.delete_book)
all_book.html
<a href="/bookstore/delete_book?book_id={
{ book.id }}">删除a>
批量删除
1、查找查询结果集中满足条件的全部QuerySet查询集合对象
2、调用查询集合对象的delete()方法实现删除
# 删除全部书籍中,id大于2的全部信息
book = Book.objects.filter(id__gt=2)
book.delete()
伪删除(逻辑删除)
实际需求中,通常不会轻易在业务里把数据真正删掉,取而代之的是做伪删除,即在表中添加一个布尔型字段(is_active),默认是True;执行删除时,将欲删除数据的is_active字段设置为False
注意:用伪删除时,确保显示数据的地方,均加了is_active=True的过滤
新增bookstories/models.py中,字段
is_active = models.BooleanField('是否活跃',default = True)
执行迁移
views.py
在def all_book(request):查询中也要加filter(is_active=True)
def delete_book(request):
#通过获取查询字符串 book_id 拿到要删除的book的id
book_id = request.GET.get('book_id')
if not book_id:
return HttpResponse('---请求异常')
try:
book = Book.objects.get(id=book_id,is_active=True)
except Exception as e:
print('---delete book get error %s'%(e))
return HttpResponse('---The book id is error')
#将其is_active 改成False
book.is_active = False
book.save()
#302跳转至all_book
return HttpResponseRedirect('/bookstore/all_book')
url.py
path('delete_book', views.delete_book)
四、F对象和Q对象
F对象
一个F对象代表数据库中某条记录的字段信息
作用:通常是对数据库中的字段值在不获取的情况下进行操作,用于类属性(字段)之间的比较
语法:
from django.db.models import F
F('列名')
views.py
# 将全部图书市场价降价50
from django.db.models import F
def all_book_F(request):
Book.objects.all().update(market_price=F('market_price')-50)
return HttpResponseRedirect('/bookstore/all_book')
urls.py
path('all_book_F',views.all_book_F),
#查出市场价大于定价全部图书
from django.db.models import F
from .models import Book
def all_book_F(request):
all_book=Book.objects.filter(market_price__gt=F('price'))
return render(request, 'bookstore/all_book.html', locals())
Q对象
当在获取查询结果集,使用复杂的逻辑或|、逻辑非~等操作时,可以借助于Q对象进行操作
如:想找出定价低于”20元“或”清华大学出版社“的全部书,可以写成
Book.objects.filter(Q(price__lt=20)|Q(pub="清华大学出版社"))
Q对象在数据包django.db.models中,需要先导入,再使用
作用:在条件中,用来实现除and(&)以外的or(|)或not(~)操作
运算符:&与操作,|或操作,~非操作 语法:
from django.db.models import Q
Q(条件1)|(条件2) # 条件1成立或条件2成立
Q(条件1)&(条件2) # 条件1成立和条件2同时成立
Q(条件1)&~(条件2) # 条件1成立且条件2不成立
...
示例:
views.py
#想找出定价低于”75“且”清华大学出版社“的全部书
from django.db.models import Q
def all_book_Q(request):
all_book = Book.objects.filter(Q(price__lt=75)&Q(pub='清华大学出版社'))
return render(request, 'bookstore/all_book.html', locals())
urls.py
path('all_book_Q',views.all_book_Q),
五、聚合查询和原生数据库操作
聚合查询:是指对一个数据表中的字段的数据进行部分或全部进行统计查询,查bookstore_book数据表中的全部书的平均价格,查询所有书的总个数等都要使用聚合查询。
聚合查询分为:整表聚合,分组聚合
整表聚合,不带分组的聚合查询是指将全部数据进行集中统计查询
聚合函数【需要导入】
导入方法: from django.db.models import * 聚合函数:Sum,Avg,Count,Max,MIn
语法:MyModel.objects.aggregate(结果变量名=聚合函数(‘列’))
返回结果:结果变量名和值,组成的字典 格式为:{“结果变量名”:值}
>>> from django.db.models import Count
>>> from bookstore.models import Book
>>> Book.objects.aggregate(res=Count('id'))
{
'res': 4}
>>>
>>> Book.objects.aggregate(res=Count('id')).get('res')
4
分组聚合:是指通过查询结果中每一个对象所关联的对象集合,从而得出总结算值(也可以是平均值或总和),即为查询集的每一项生成聚合。
语法:QuerySet.annotate(结果变量名=聚合函数(‘列’)) 返回值:QuerySet
1、通过先用查询结果MyModel.objects.values查找查询需要分组聚合的列 MyModel.objects.values(‘列1’,‘列2’),如:
>>> pub_set = Book.objects.values('pub')
>>> pub_set
[{
'pub': '清华大学出版社'}, {
'pub': '清华大学出版社'}, {
'pub': '机械工业出版社'}, {
'pub': '机械工业出版社'}]>
2、通过返回结果的QuerySet.annotate方法分组聚合得到分组结果
QuerySet.annotate(名=聚合函数(‘列))
>>> pub_count_set = pub_set.annotate(myCount=Count('pub'))
>>> pub_count_set
[{
'pub': '清华大学出版社', 'myCount': 2}, {
'pub': '机械工业出版社', 'myCount': 2}]>
原生数据库操作(自己卡一下就好)
Django也可以支持直接用sql语句的方式通信数据库
查询:使用MyModel.objects.raw()进行数据库查询操作
语法:MyModel.objects.raw(sql语句,拼接参数)
返回值:RawQuerySet集合对象【只支持基本操作,比如循环】
books = models.Book.objects.raw('select * from bookstore_book')
for book in books:
print(book)
使用原生语句时小心SQL注入
定义:用户通过数据上传,将恶意的sql语句提交给服务器,从而达到攻击效果
案例1:用户在搜索好友的表单框输入 ‘1 or 1=1’
s1 = Book.objects.raw('select * from bookstore_book where id=%s'%('1 or 1=1'))
攻击结果:可查询出所有用户数据

原生数据库操作–cursor
完全跨过模型类操作数据库:查询、更新、删除
1、导入cursor所在包 from django.db import connection
2、用创建cursor类的构造函数创建cursor对象,再使用cursor对象,为保证在出现异常时能释放cursor资源,通常使用with语句进行创建操作
from django.db import connection
with connection.cursor() as cur:
cur.execute('执行SQL语句','拼接参数')

