机器学习实战——人脸表情识别
基于keras创建及训练卷积神经网络,OpenCV对图像数据集进行处理,pyqt5对GUI界面的创建。
本项目基于python设计对于人脸表情的情绪识别,通过使用日本拍摄的jaffe数据集对卷积神经网络进行训练,并保存训练的参数对新的人脸情绪进行识别,并设计出GUI窗口方便使用。
本项目采用的数据集是日本的jaffe数据集,该数据库包含213张由10位日本女模特构成的7种面部表情(6种基本面部表情+ 1个中性)的图像,图片为256x256灰度图,这7种表情分别是sad(悲伤)、happy(开心)、angry(生气)、disgust(厌恶)、surprise(惊讶)、fear(恐惧)、neutral(中性),每组大概20张样图。
表1是本次所用的包以及开发工具:
| 名称 |
版本 |
作用 |
| python |
3.8.3 |
开发语言 |
| Keras |
3.4.3 |
构建卷积神经网络并训练卷积神经网络 |
| pyqt5 |
5.15.4 |
构建GUI窗口 |
| numpy |
1.18.5 |
数据处理 |
| pandas |
1.0.5 |
读取数据文件 |
| OpenCV |
4.5.1 |
调用训练好的xml文件得出脸部数据 |
表1 开发工具介绍
一、环境搭建及数据获取
本人采用anaconda进行搭建,anaconda具备了大多数我们所需要的第三方库,而另外需要的OpenCV和qt-designer则需另外下载。
可打开Anaconda Prompt 输入如下命令进行下载OpenCV以及qt-designer。
pip install opencv-python
pip install PyQt5-tool获取数据集
二、数据预处理
由于所得的数据集为人上身照片(头到肩部的灰度图片),项目任务是通过脸部数据进行识别,在训练卷积神经网络时,头发以及肩部动作等难免会对训练过程造成干扰,通过利用OpenCV训练好的xml文件对人脸进行识别,利用os库对数据集文件进行读取,分别获得人脸部主要数据,将其获取后存为csv文件并记录下对应的标签数据。emotion为标签,对应的情绪字典为emotion = {0: 'Angry', 1: 'Disgust', 2: 'Fear', 3: 'Happy', 4: 'Sad', 5: 'Surprise', 6: 'Neutral'},pixels为所取像素点数据。
import os
import cv2
import numpy as np
import csv
'''
对jaffe数据集进行人脸识别,裁剪并保存得到大小为48x48的图片
整个数据库一共有213张图像,10个人,全部都是女性,每个人做出7种表情,这7种表情分别是sad、happy、angry、disgust、surprise、fear、neutral,每组大概20张样图。
该数据库包含213张由10位日本女模特构成的7种面部表情(6种基本面部表情+ 1个中性)的图像。图片为256x256灰度级
'''
# 获取脸部数据
def detect(img, cascade):
rects = cascade.detectMultiScale(img, scaleFactor=1.2, minNeighbors=3,
minSize=(30, 30)) # ,flags=cv2.CASCADE_SCALE_IMAGE
if len(rects) == 0:
return []
rects[:, 2:] += rects[:, :2]
return rects
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
cascade.load("haarcascade_frontalface_default.xml")
f = "..\\jaffe"
fs = os.listdir(f)
data = np.zeros([213, 48 * 48], dtype=np.uint8)
label = np.zeros([213], dtype=int)
i = 0
for f1 in fs:
tmp_path = os.path.join(f, f1)
for f2 in os.listdir(tmp_path):
tmp_path2 = os.path.join(f1, f2)
if not os.path.isdir(tmp_path2):
tmp_path3 = tmp_path + '\\' + f2
img = cv2.imread(tmp_path3, 0)
rects = detect(img, cascade)
for x1, y1, x2, y2 in rects:
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 255), 2)
# 调整截取脸部区域大小
img_roi = np.uint8([y2 - y1, x2 - x1])
roi = img[y1:y2, x1:x2]
img_roi = roi
re_roi = cv2.resize(img_roi, (48, 48))
# 获得表情label
img_label = f1
#print(img_label)
if img_label == 'anger':
label[i] = 0
elif img_label == 'disgust':
label[i] = 1
elif img_label == 'fear':
label[i] = 2
elif img_label == 'happiness':
label[i] = 3
elif img_label == 'sadness':
label[i] = 4
elif img_label == 'surprise':
label[i] = 5
elif img_label == 'neutral':
label[i] = 6
else:
print("get label error.......\n")
data[i][0:48 * 48] = np.ndarray.flatten(re_roi)
i = i + 1
with open(r"./jaffe_face.csv", "w") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['emotion', 'pixels'])
for i in range(len(label)):
data_list = list(data[i])
b = " ".join(str(x) for x in data_list)
l = np.hstack([label[i], b])
writer.writerow(l)
三、卷积神经网络的搭建及训练
搭建的卷积神经网络为两层卷积核大小为5×5卷积层,激活函数为relu、再经过两层池化层进行下采样去除冗余信息,最后展开为全连接层,其激活函数为relu,再经过Dropout随机丢弃50%的信息,防止过拟合、提升模型泛化能力,最后经过输出通道为7、激活函数为softmax的全连接层,分别得出对应情绪字典的各类情绪分类。
训练过程中采用的损失函数为categorical_crossentropy,优化器采用rmsprop。
(1)Relu激活函数:
![]()
性质:①非线性函数,单侧是线性函数
虽然ReLU在数学上的定义x=0处是不可导的,但是实际中为了解决这个问题直接将处的导数设置为1 ,当x>0时,f’(x) = 1, 当x<=0时,f’(x) = 0。
优点:
①计算量小,相对于sigmoid和Tanh激活函数需要进行指数运算,使用ReLu的计算量小很多,在使用反向传播计算的时候也要收敛更更快。
②缓解了在深层网络中使用sigmoid和Tanh激活函数造成了梯度消失的现象(右侧导数恒为1)。
③缓解过拟合的问题。由于函数的会使小于零的值变成零,使得一部分神经元的输出为0,造成网络的稀疏性,减少参数相互依赖的关系缓解过拟合的问题。
缺点:
①造成神经元的“死亡”;
②ReLU的输出不是0均值的;
(2)Softmax激活函数:
![]()
映射区间[0,1]
主要用于:离散化概率分布
(3)categorical_crossentropy(交叉熵损失函数):
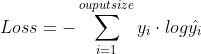
可以发现,因为 要么是0,要么是1。而当等于0时,结果就是0,当且仅当等于1时,才会有结果。也就是说categorical_crossentropy只专注于一个结果,因而它一般配合softmax做单标签分类。
要么是0,要么是1。而当等于0时,结果就是0,当且仅当等于1时,才会有结果。也就是说categorical_crossentropy只专注于一个结果,因而它一般配合softmax做单标签分类。
(4)优化器rmsprop:
| RMSProp算法 |
| Require:全局学习率lr,衰减速率ρ Require:初始参数θ Require:小参数δ,通常设为 初始化积累变量r=0 while没有达到停止准则do 从训练集中采 计算梯度: 累积平方梯度: 计算参数更新: 应用更新: end while |
表2 RMSProp算法介绍
import numpy as np
import pandas as pd
from keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
# 表情类别
emotion = {0: 'Angry', 1: 'Disgust', 2: 'Fear', 3: 'Happy', 4: 'Sad', 5: 'Surprise', 6: 'Neutral'}
# 读取数据
data = pd.read_csv(r'jaffe_face.csv', dtype='a')
# 读取标签列表
label = np.array(data['emotion'])
# 图像列表
img_data = np.array(data['pixels'])
# 图像数量
N_sample = label.size
# (213, 2304)
Face_data = np.zeros((N_sample, 48 * 48))
# (213, 7)
Face_label = np.zeros((N_sample, 7), dtype=np.float)
for i in range(N_sample):
x = img_data[i]
x = np.fromstring(x, dtype=float, sep=' ')
x = x / x.max()
Face_data[i] = x
Face_label[i, int(label[i])] = 1.0
# 训练数据数量
train_num = 200
# 测试数据数量
test_num = 13
# 训练数据
train_x = Face_data[0:train_num, :]
train_y = Face_label[0:train_num, :]
train_x = train_x.reshape(-1, 48, 48, 1) # reshape
# 测试数据
test_x = Face_data[train_num: train_num + test_num, :]
test_y = Face_label[train_num: train_num + test_num, :]
test_x = test_x.reshape(-1, 48, 48, 1) # reshape
# 序贯模型
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=(48, 48, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
# 扩增数据
datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
datagen.fit(train_x)
model.fit_generator(datagen.flow(train_x, train_y, batch_size=10), steps_per_epoch=len(train_x), epochs=20)
model.fit(train_x, train_y, batch_size=10, epochs=100)
score = model.evaluate(test_x, test_y, batch_size=10)
print("score:", score)
model.save("keras.h5")
model.summary()
四、GUI窗口的创建与预测功能的实现
下载好的qt designer在存储路径D:\Anaconda3\Lib\site-packages\pyqt5-tools\下,利用qt designer设计出大体框架,按钮布局等,生成ui文件,利用powershell命令将其转化为py文件。
通过将训练好的模型参数保存下来,保存为keras.h5文件,再将其加载入模型中对新图片进行预测,同样,新图片结果由OpenCV训练好的xml文件得出脸部数据,将处理后的数据载入对新图片进行训练,得出最终结果,再根据字典{0: 'Angry', 1: 'Disgust', 2: 'Fear', 3: 'Happy', 4: 'Sad', 5: 'Surprise', 6: 'Neutral'}对其进行判别属于何种种类。
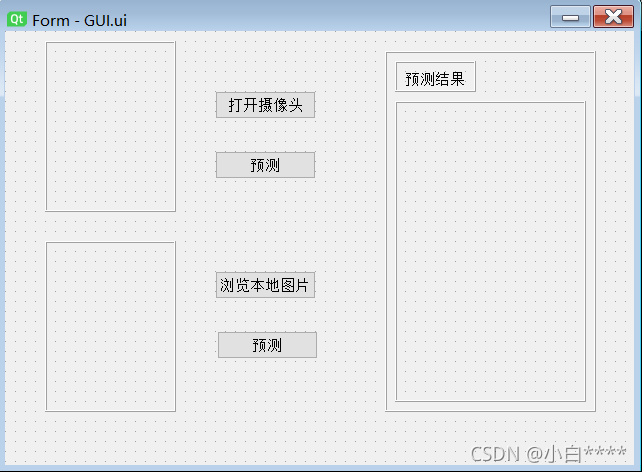
图1 GUI布局示例

图2 PowerShell命令转换文件
如若不想下载或下载qt designer失败,也可通过以下代码实现对GUI的构建。
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'GUI.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
# 此处代码仅构建出GUI窗口的布局,无法运行展示,需调用才可展示
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_GUI(object):
def setupUi(self, GUI):
GUI.setObjectName("GUI")
GUI.resize(629, 434)
self.predict_bottom = QtWidgets.QPushButton(GUI)
self.predict_bottom.setGeometry(QtCore.QRect(210, 120, 101, 28))
self.predict_bottom.setObjectName("predict_bottom")
self.carema = QtWidgets.QFrame(GUI)
self.carema.setGeometry(QtCore.QRect(40, 10, 131, 171))
self.carema.setFrameShape(QtWidgets.QFrame.Box)
self.carema.setFrameShadow(QtWidgets.QFrame.Raised)
self.carema.setObjectName("carema")
self.cameraimage = QtWidgets.QLabel(self.carema)
self.cameraimage.setGeometry(QtCore.QRect(1, 0, 131, 171))
self.cameraimage.setText("")
self.cameraimage.setObjectName("cameraimage")
self.open_camera_bottom = QtWidgets.QPushButton(GUI)
self.open_camera_bottom.setGeometry(QtCore.QRect(210, 60, 101, 28))
self.open_camera_bottom.setObjectName("open_camera_bottom")
self.localimage = QtWidgets.QFrame(GUI)
self.localimage.setGeometry(QtCore.QRect(40, 210, 131, 171))
self.localimage.setFrameShape(QtWidgets.QFrame.Box)
self.localimage.setFrameShadow(QtWidgets.QFrame.Raised)
self.localimage.setObjectName("localimage")
self.showimage = QtWidgets.QLabel(self.localimage)
self.showimage.setGeometry(QtCore.QRect(0, 0, 131, 171))
self.showimage.setText("")
self.showimage.setObjectName("showimage")
self.textlabel = QtWidgets.QLabel(GUI)
self.textlabel.setGeometry(QtCore.QRect(400, 40, 61, 16))
self.textlabel.setAutoFillBackground(False)
self.textlabel.setObjectName("textlabel")
self.result = QtWidgets.QFrame(GUI)
self.result.setGeometry(QtCore.QRect(380, 20, 211, 361))
self.result.setFrameShape(QtWidgets.QFrame.Box)
self.result.setFrameShadow(QtWidgets.QFrame.Raised)
self.result.setObjectName("result")
self.textlabel_frame = QtWidgets.QFrame(self.result)
self.textlabel_frame.setGeometry(QtCore.QRect(10, 10, 81, 31))
self.textlabel_frame.setFrameShape(QtWidgets.QFrame.Box)
self.textlabel_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.textlabel_frame.setObjectName("textlabel_frame")
self.resultframe = QtWidgets.QFrame(self.result)
self.resultframe.setGeometry(QtCore.QRect(10, 50, 191, 301))
self.resultframe.setFrameShape(QtWidgets.QFrame.Box)
self.resultframe.setFrameShadow(QtWidgets.QFrame.Raised)
self.resultframe.setObjectName("resultframe")
self.resultlabel = QtWidgets.QLabel(self.resultframe)
self.resultlabel.setGeometry(QtCore.QRect(10, 10, 171, 281))
self.resultlabel.setText("")
self.resultlabel.setObjectName("resultlabel")
self.select_image = QtWidgets.QPushButton(GUI)
self.select_image.setGeometry(QtCore.QRect(210, 240, 101, 28))
self.select_image.setObjectName("select_image")
self.predict_local_bottom = QtWidgets.QPushButton(GUI)
self.predict_local_bottom.setGeometry(QtCore.QRect(212, 300, 101, 28))
self.predict_local_bottom.setObjectName("predict_local_bottom")
self.label = QtWidgets.QLabel(GUI)
self.label.setGeometry(QtCore.QRect(40, 390, 131, 41))
self.label.setText("")
self.label.setObjectName("label")
self.retranslateUi(GUI)
QtCore.QMetaObject.connectSlotsByName(GUI)
def retranslateUi(self, GUI):
_translate = QtCore.QCoreApplication.translate
GUI.setWindowTitle(_translate("GUI", "Form"))
self.predict_bottom.setText(_translate("GUI", "预测"))
self.open_camera_bottom.setText(_translate("GUI", "打开摄像头"))
self.textlabel.setText(_translate("GUI", "预测结果"))
self.select_image.setText(_translate("GUI", "浏览本地图片"))
self.predict_local_bottom.setText(_translate("GUI", "预测"))
将训练好的权重文件加载到神经网络中,对新的图片进行预测,即可得到对新表情的预测。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
import cv2
import numpy as np
test_img = np.zeros([1, 48 * 48], dtype=np.uint8)
def main(imgpath):
test_image = cv2.imread(imgpath, 0)
rects = detect(test_image, cascade)
for x1, y1, x2, y2 in rects:
cv2.rectangle(test_image, (x1, y1), (x2, y2), (0, 255, 255), 2)
# 调整截取脸部区域大小
img_roi = np.uint8([y2 - y1, x2 - x1])
roi = test_image[y1:y2, x1:x2]
img_roi = roi
re_roi = cv2.resize(img_roi, (48, 48))
global test_img
test_img[0][0:48 * 48] = np.ndarray.flatten(re_roi)
data_img = np.array(test_img)
Face_data = np.zeros((1, 48 * 48))
x = data_img[0]
Face_data[0] = x
test_x = Face_data[:]
test_x = test_x.reshape(-1, 48, 48, 1)
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=(48, 48, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.load_weights("keras.h5")
accuracy = model.predict_classes(test_x)
print(accuracy)
if accuracy == 0:
result = "生气"
elif accuracy == 1:
result = "厌恶"
elif accuracy == 2:
result = "恐惧"
elif accuracy == 3:
result = "开心"
elif accuracy == 4:
result = "悲伤"
elif accuracy == 5:
result = "惊讶"
elif accuracy == 6:
result = "中性"
return result
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
cascade.load("haarcascade_frontalface_default.xml")
def detect(img, cascade):
rects = cascade.detectMultiScale(img, scaleFactor=1.2, minNeighbors=3,
minSize=(30, 30)) # ,flags=cv2.CASCADE_SCALE_IMAGE
if len(rects) == 0:
return []
rects[:, 2:] += rects[:, :2]
return rects
if __name__ == '__main__':
main()
再通过调用构建好的GUI进行预测即可非常直观地对图片进行预测了。
import time
from GUI import Ui_GUI
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
import sys
import cv2
import predict
class Ui_GUI(QMainWindow, Ui_GUI):
def __init__(self):
super(Ui_GUI, self).__init__()
self.setupUi(self)
self.retranslateUi(self)
self.select_image.clicked.connect(self.open_local_image)
self.timer_camera = QtCore.QTimer() # 初始化定时器
self.cap = cv2.VideoCapture() # 初始化摄像头
self.CAM_NUM = 0
self.slot_init()
self.predict_local_bottom.clicked.connect(self.test)
def open_local_image(self):
imgName, imgType = QFileDialog.getOpenFileName(self, "浏览本地图片", "", "*.jpg;;*.png;;All Files(*)")
jpg = QtGui.QPixmap(imgName).scaled(self.showimage.width(), self.showimage.height())
self.showimage.setPixmap(jpg)
self.label.setText(str(imgName))
def slot_init(self): # 建立通信连接
self.open_camera_bottom.clicked.connect(self.button_open_camera_click)
self.timer_camera.timeout.connect(self.show_camera)
self.predict_bottom.clicked.connect(self.capx)
def button_open_camera_click(self):
if self.timer_camera.isActive() == False:
flag = self.cap.open(self.CAM_NUM)
if flag == False:
msg = QtWidgets.QMessageBox.Warning(self, u'Warning', u'请检测相机与电脑是否连接正确',
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
self.timer_camera.start(30)
self.open_camera_bottom.setText(u'关闭摄像头')
else:
self.timer_camera.stop()
self.cap.release()
self.cameraimage.clear()
self.open_camera_bottom.setText(u'打开摄像头')
def show_camera(self):
flag, self.image = self.cap.read()
show = cv2.resize(self.image, (140, 180))
# opencv格式不能直接显示,需要用下面代码转换一下
show = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
self.showImage = QtGui.QImage(show.data, show.shape[1], show.shape[0], QtGui.QImage.Format_RGB888)
self.cameraimage.setPixmap(QtGui.QPixmap.fromImage(self.showImage))
def capx(self):
FName = fr"images\cap{time.strftime('%Y%m%d%H%M%S', time.localtime())}"
print(FName)
self.cameraimage.setPixmap(QtGui.QPixmap.fromImage(self.showImage))
self.showImage.save(FName + ".jpg", "JPG", 100)
cv2.imwrite("test.jpg", self.image)
impath = "test.jpg"
self.resultlabel.setText((str(predict.main(impath))))
def test(self):
imgpath = self.label.text()
self.resultlabel.setText(str(predict.main(imgpath)))
if __name__ == '__main__':
app = QApplication(sys.argv)
ui = Ui_GUI()
ui.show()
sys.exit(app.exec_())
五、效果预览

图3 运行主界面

图4 读取本地图片预测效果
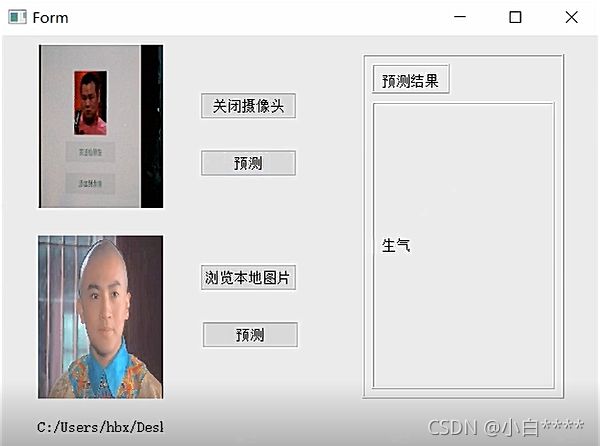
图5 打开相机预测效果