火车头抓取豆瓣影评案例
使用工具:
火车头采集器
任务实例:
采集豆瓣电影上的影评,包括评论电影、评论时间、评论用户、评论内容。
1.新建任务分组

2.新建任务规则,并添加起始网址
选中刚刚新建的任务分组,点击新建任务规则;

于是来到规则填写页面;

前往豆瓣电影https://movie.douban.com/,选取任意想要抓取影评的电影,获取所需要的起始网址,本文选择抓取《头号玩家》这部电影;

然后找到《头号玩家》电影的短评,点击全部;

就找到了我们想要抓取评论的起始页;

请注意, https://movie.douban.com/subject/4920389/comments?status=P这个并不是起始网址的url,因为我们是通过点击“全部”这个按钮跳转到这个页面,所以上面的url其实是我们点击“全部”发送的GET请求。
那怎么找到起始网址的url呢?接下来就是找规律的时间了。
一般来说,评论都是分页显示的,通过发送相似的url请求来访问具体某一页评论。所以,我们点击“后页”来寻找规律。

第二页,即点击第一次“后页”按钮,之后显示的页面;
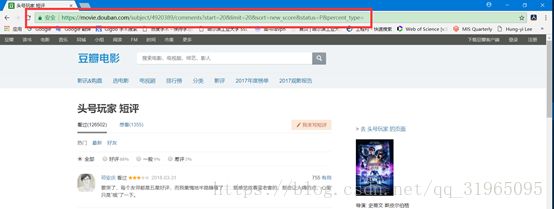
第三页,即点击第二次“后页”按钮,然后显示的页面;
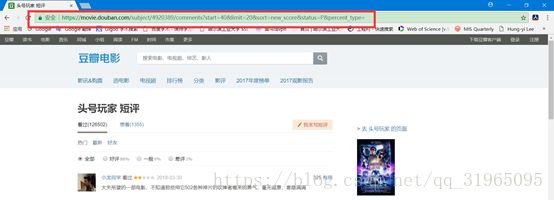
相信到这里,同学们已经大致知道规律了吧!
根据规律,我们可以得出《头号玩家》这部电影影评的起始网址的url其实就是https://movie.douban.com/subject/4920389/comments?start=0&limit=20&sort=new_score&status=P&percent_type=;不妨将该url复制然后在浏览器访问,看看是否是之前看到过的起始页。
虽然我们已经找到起始页的网址,但是还有一点小问题,那就是点击“后页”按钮后,显示的网页的源代码是一串json格式的字符串。

其实是因为在访问下一页评论页的时候,我们向服务器发送了过多的参数,导致服务器认为我们是想要获取json格式的字符串,所以我们可以删减一些不必要的重复性的参数。(这是经验之谈)。
https://movie.douban.com/subject/4920389/comments?start=0;这个才是起始页真正的网址url,访问该url后查看网页源代码,浏览器显示的是标准的html网页的源码,到这里我们才真正找到了起始页的url;
https://movie.douban.com/subject/4920389/comments?start=20;这是第二页即后页的网址url;同学们不妨试一下,看看是否正确,看看检查网页源代码,浏览器是否显示的是标准的html格式。
到这里,我们已经找到了起始网址url,并且知道了《头号玩家》电影影评翻页的规律。https://movie.douban.com/subject/4920389/comments?start=[参数];
接下来,将 https://movie.douban.com/subject/4920389/comments?start=0;这个 url 填入起始网址一栏,并且为我们的 任务规则命名。一般大型的网站,比如百度贴吧、豆瓣等等,只有在登录之后才能观看更多的评论内容,抓取数据也是一样的道理,只有模拟登录之后,才能抓取所有的评论内容。我们可以通过火车头采集器进行设置,模拟登录状态。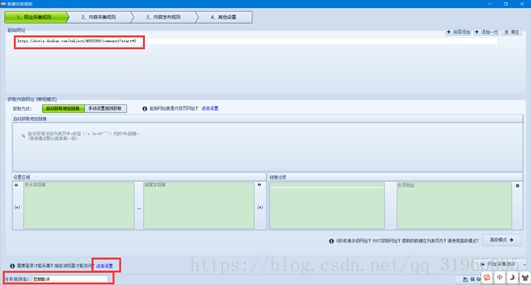
“点击设置”按钮触发之后,火车头工具显示的是;
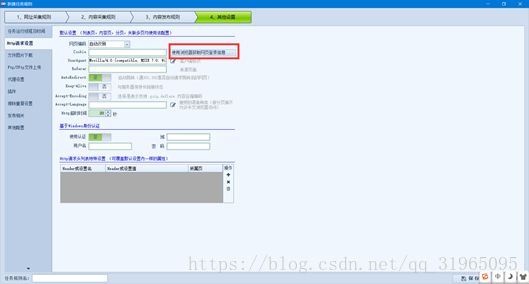
点击红框选中的按钮“使用浏览器获取网页登录信息”,并且输入我们所需要登录的豆瓣电影的url,或者输入起始页url也可以;

然后,完成登录即可;

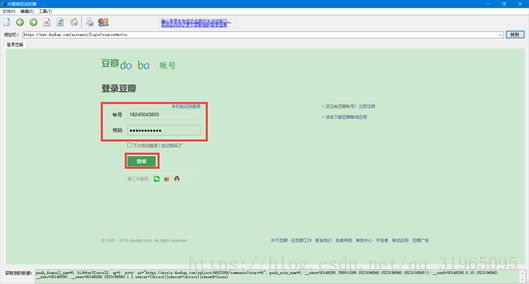
当导航栏中显示我们的个人用户信息之后,代表我们已经模拟登录成功,叉掉内置微型流量器页面;

到现在为止,我们已经做好了抓取数据的准备工作,接下来是抓取数据的重点——设置内容抓取规则;
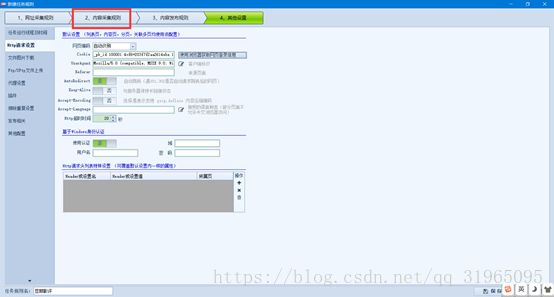
3.设置内容抓取规则
首先,定义我们抓取的数据的标签,在这里我们需要获取影评时间、影评内容、影评用户、以及该影评所属的电影名称;
通过右边操作栏中加号、重命名等工具添加完成;
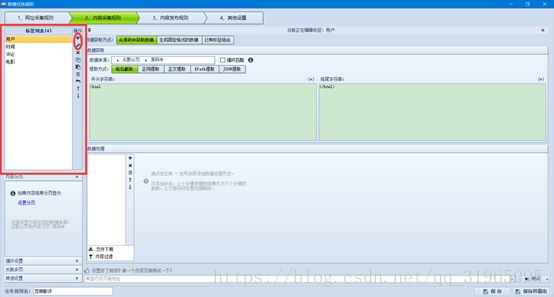
接下来设置每个标签的获取规则;
首先,设置标签“用户”的规则;在这里我们选择 正则提取,因为正则提取到的数据准确率比较高;并且, 将循环匹配选择框打上√;
然后,我们到网页的源代码找到显示豆瓣用户的html代码;


我们可以看出,

以此类推,我们可以得出其他标签的规则;


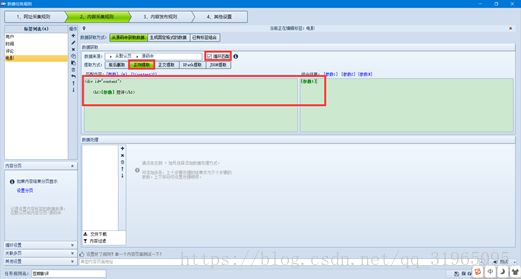
到这一步,我们就已经设置好了标签数据的获取规则;接下来要设置的是内容分页、以及循环设置;

设置内容分页的时候,我们要在源代码中找到翻页按钮的html代码,然后提取规则;

从上面红框选中源代码中,我们可以看出翻页的html代码。
提取翻页规则时,首先要确定开始提取的区域和结束的区域;在这里,我们选择“< 前页”与“后页 >”作为我们开始和结束的字符串。
接着,我们选择手动设置规则,因为设置这种方式会使得火车头采集器在爬取数据的时候更加准确的翻页;在分页格式提取一栏中填入我们提取出的规则,即找到的翻页规律,“[参数]&limit=20&sort=new_score&status=P&percent_type="data-page="" class="next">”,我们所需要的就是start后面带的那个参数,在上面我们已经讨论过原因了。
然后,在实际地址拼接一栏中,填写上我们找到的翻页规则,“https://movie.douban.com/subject/4920389/comments?start=[参数1]”。
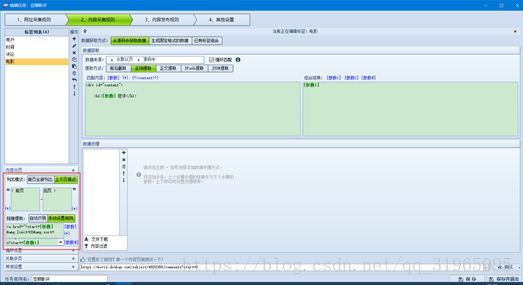
然后进行循环设置;选择“添加为新纪录”,在分隔符的选择上,我们使用换行,而不是###,然后不足记录时使用第一条补足;

内容采集规则设置完毕;接下来进行内容采集的其他设置;

然后进行任务的其他设置;

4.其他设置
不要设置过大的线程数,虽然抓取的速度会很快,但是会被豆瓣查封IP,因为设置的线程数过多,抓取速度快,翻页的速度也快,导致豆瓣认为你不是在观看评论,而是在抓取数据。

设置完毕之后点击“保存并退出”。
5.开始任务
右击我们设置的任务规则,选择开始;(请注意,如果已经运行任务规则,需要先清空采集数据!)

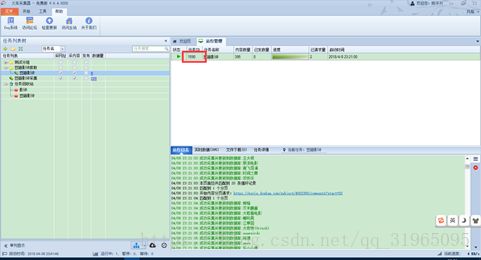
其中1590就是我们任务的ID;几分钟、十几分钟过后,抓取结束。
到安装火车头的目录下的Data文件夹中选择任务ID号的文件夹,查看获取的后缀为db3的文件,里面存储了我们想要抓取的数据。该类型的文件可以在navicat premium上查看。
将db3文件拖拽到navicat客户端中,可以显示: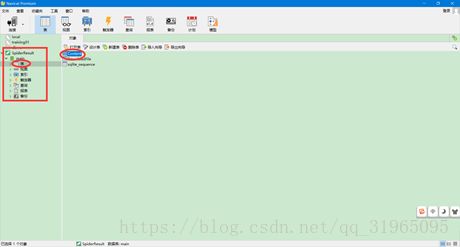
选中Content表,查看获取数据;

到此结束抓取!