【计量经济学导论】05. 异方差
文章目录
- 异方差
-
- 异方差的含义
- 异方差的产生原因
- 异方差的后果
- 异方差的检验方法
- 异方差的修正措施
异方差
在上一节的讨论中,完全共线性问题违背了基本假定 MLR.3 ,而多重共线性没有违背任何一个基本假定,因此 OLS 估计量仍然具有 BLUE 性质。这一篇笔记我们主要来讨论异方差问题,即如果违背了同方差假定 MLR.5 的情况。
异方差的含义
在介绍异方差之前,我们先回顾一下同方差的情况。方差是度量被解释变量的观测值围绕回归线的分散程度,因此同方差假定指的是所有观测值的分散程度相同。
V a r ( u ∣ X ) = [ σ 2 σ 2 ⋱ σ 2 ] = σ 2 [ 1 1 ⋱ 1 ] = σ 2 I n . {\rm Var}(\boldsymbol{u}|\boldsymbol{X}) = \left[ \begin{array}{cccc} \sigma^2 & & & \\ & \sigma^2 & & \\ & & \ddots & \\ & & & \sigma^2 \\ \end{array} \right] = \sigma^2 \left[ \begin{array}{cccc} 1 & & & \\ & 1 & & \\ & & \ddots & \\ & & & 1 \\ \end{array} \right] = \sigma^2\boldsymbol{I}_n \ . Var(u∣X)=⎣⎢⎢⎡σ2σ2⋱σ2⎦⎥⎥⎤=σ2⎣⎢⎢⎡11⋱1⎦⎥⎥⎤=σ2In .
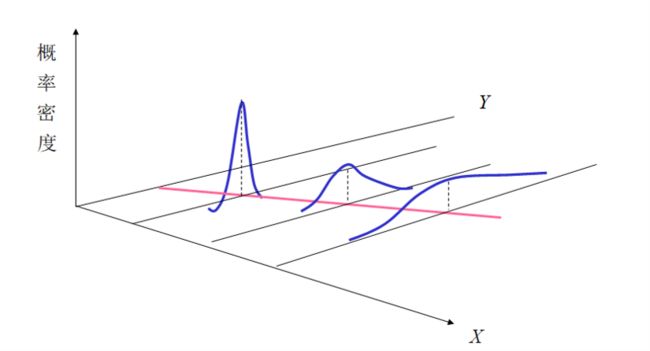
异方差指的是对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同的。即如果 u u u 的方差随 x x x 变化,那么称随机干扰项是具有异方差的。当异方差发生的时候,随机干扰项的条件方差是关于解释变量的函数:
V a r ( u ∣ X 1 , X 2 , . . . , X k ) = g ( X 1 , X 2 , . . . X k ) . {\rm Var}(u|X_1,X_2,...,X_k)=g(X_1,X_2,...X_k) \ . Var(u∣X1,X2,...,Xk)=g(X1,X2,...Xk) .
用协方差矩阵表示为:
V a r ( u ∣ X ) = [ σ 1 2 σ 2 2 ⋱ σ n 2 ] = σ 2 [ ω 1 ω 2 ⋱ ω n ] = σ 2 Ω . {\rm Var}(\boldsymbol{u}|\boldsymbol{X}) = \left[ \begin{array}{cccc} \sigma_1^2 & & & \\ & \sigma_2^2 & & \\ & & \ddots & \\ & & & \sigma_n^2 \\ \end{array} \right] = \sigma^2 \left[ \begin{array}{cccc} \omega_1 & & & \\ & \omega_2 & & \\ & & \ddots & \\ & & & \omega_n \\ \end{array} \right] = \sigma^2\boldsymbol\Omega \ . Var(u∣X)=⎣⎢⎢⎡σ12σ22⋱σn2⎦⎥⎥⎤=σ2⎣⎢⎢⎡ω1ω2⋱ωn⎦⎥⎥⎤=σ2Ω .
这里的 V a r ( u i ) = σ i 2 {\rm Var}(u_i) = \sigma_i^2 Var(ui)=σi2 ,下标 i i i 表示非常数,违背了 MLR.5。
用图形表示为:
异方差的产生原因
(1) 模型中遗漏了某些重要的解释变量
举个例子比较容易理解。假设正确的计量模型是:
Y i = β 0 + β 1 X i 1 + β 2 X i 2 + u i , Y_i=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+u_i \ , Yi=β0+β1Xi1+β2Xi2+ui ,
如果我们遗漏了解释变量 X i 2 X_{i2} Xi2 ,估计的模型为:
Y i = β 0 + β 1 X i 1 + v i , Y_i=\beta_0+\beta_1X_{i1}+v_i \ , Yi=β0+β1Xi1+vi ,
当被遗漏的 X 2 i X_{2i} X2i 与 X i 1 X_{i1} Xi1 具有呈现同方向或反方向的变化趋势时, X 2 i X_{2i} X2i 随 X i 1 X_{i1} Xi1 的有规律的变化会体现在随机干扰项 v i v_i vi 中。一般这种情况往往也会造成内生性的问题,我们在后面的章节进行介绍。
(2) 数据的测量误差
样本数据的观测误差有可能随研究范围的扩大而增加,或随时间的推移逐步积累,也可能随着观测技术的提高而逐步减小。
(3) 截面数据中总体各单位的差异
通常认为,截面数据较时间序列数据更容易产生异方差。这是因为同一时点不同对象的差异,一般说来会大于同一对象不同时间的差异。不过,在时间序列数据发生较大变化的情况下,也可能出现比截面数据更严重的异方差。
(4) 一个或多个回归解释变量的分布是偏态(skewness)
例如:收入、财富和受教育水平的总体分布都是不均匀的分布。具体体现在大部分的收入和财富被少数人所拥有,受高等教育的精英也是少数等等。
(5) 模型的函数形式存在设定误差
(6) 异常值
异方差的后果
-
不改变无偏性和一致性:参数估计的无偏性仅依赖于基本假定中的零均值假定,所以异方差的存在对无偏性的成立没有影响。
-
参数估计量非有效:同方差假定是 OLS 估计方差最小的前提条件,所以随机误差项是异方差时,将不能再保证最小二乘估计的方差最小。我们重新写一遍矩阵形式的推导过程就可以清楚的发现问题:
V a r ( β ^ ∣ X ) = V a r ( β + ( X T X ) − 1 X T μ ) = ( X T X ) − 1 X T ⋅ V a r ( μ ∣ X ) ⋅ X ( X T X ) − 1 = ( X T X ) − 1 X T ⋅ σ 2 Ω ⋅ X ( X T X ) − 1 = σ 2 ( X T X ) − 1 X T ⋅ Ω ⋅ X ( X T X ) − 1 ≠ σ 2 ( X T X ) − 1 . \begin{aligned} {\rm Var}(\hat{\boldsymbol\beta}|\boldsymbol{X})&={\rm Var}\left(\boldsymbol{\beta}+\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1}\boldsymbol{X}^{\rm T}\boldsymbol{\mu}\right) \\ &=\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1}\boldsymbol{X}^{\rm T}\cdot{\rm Var}(\boldsymbol\mu|\boldsymbol{X})\cdot\boldsymbol{X}\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1} \\ &=\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1}\boldsymbol{X}^{\rm T}\cdot\sigma^2\boldsymbol\Omega\cdot\boldsymbol{X}\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1} \\ &=\sigma^2\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1}\boldsymbol{X}^{\rm T}\cdot\boldsymbol\Omega\cdot\boldsymbol{X}\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1} \\ &\neq\sigma^2\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1} \ . \end{aligned} Var(β^∣X)=Var(β+(XTX)−1XTμ)=(XTX)−1XT⋅Var(μ∣X)⋅X(XTX)−1=(XTX)−1XT⋅σ2Ω⋅X(XTX)−1=σ2(XTX)−1XT⋅Ω⋅X(XTX)−1=σ2(XTX)−1 .
- V a r ( β j ^ ) {\rm Var}(\hat{\beta_j}) Var(βj^) 非有效会造成一系列的影响:
- 不能用来构造置信区间和 t t t 统计量,使用大样本容量也不能解决这个问题;
- 变量的显著性检验失去意义;
- 模型的预测失效。
在这里我们利用排除其他解释变量影响的方法简单回顾一下同方差条件下的 t t t 统计量:
t = β ^ j − β j s e ( β ^ j ) = β ^ j − β j σ ^ 2 S S T j ( 1 − R j 2 ) = β ^ j − β j σ ^ 2 ⋅ σ 2 S S T j ( 1 − R j 2 ) ⋅ σ 2 = β ^ j − β j s d ( β ^ j ) σ ^ 2 σ 2 , t=\frac{\hat\beta_j-\beta_j}{ {\rm se}(\hat\beta_j)}=\frac{\hat\beta_j-\beta_j}{\displaystyle\sqrt{\displaystyle\frac{\hat\sigma^2}{ {\rm SST}_j(1-R_j^2)}}}=\frac{\hat\beta_j-\beta_j}{\displaystyle\sqrt{\displaystyle\frac{\hat\sigma^2\cdot\sigma^2}{ {\rm SST}_j(1-R_j^2)\cdot\sigma^2}}}=\frac{\displaystyle\frac{\hat\beta_j-\beta_j}{ {\rm sd}(\hat\beta_j)}}{\displaystyle\sqrt{\displaystyle\frac{\hat\sigma^2}{\sigma^2}}} \ , t=se(β^j)β^j−βj=SSTj(1−Rj2)σ^2β^j−βj=SSTj(1−Rj2)⋅σ2σ^2⋅σ2β^j−βj=σ2σ^2sd(β^j)β^j−βj ,
其中分子服从标准正态分布,分母的平方乘以 n − k − 1 n-k-1 n−k−1 服从自由度为 n − k − 1 n-k-1 n−k−1 的 χ 2 \chi^2 χ2 分布。
关于异方差下的 OLS 估计量的方差,我们也利用排除其他解释变量影响的方法,通过如下推导可以发现问题:
V a r ( β ^ j ∣ X ) = V a r ( β j + ∑ i = 1 n r ^ i j u i ∑ i = 1 n r ^ i j 2 ∣ X ) = ∑ i = 1 n r ^ i j 2 ⋅ V a r ( u i ∣ X ) ( ∑ i = 1 n r ^ i j 2 ) 2 {\rm Var}(\hat\beta_j|\boldsymbol{X})={\rm Var}\left(\beta_j+\left.\frac{\sum\limits_{i=1}^n\hat{r}_{ij}u_i}{\sum\limits_{i=1}^n \hat{r}_{ij}^2}\right|\boldsymbol{X}\right)=\frac{\sum\limits_{i=1}^n\hat{r}_{ij}^2\cdot{\rm Var}\left(u_i|\boldsymbol{X}\right)}{\left(\sum\limits_{i=1}^n\hat{r}_{ij}^2\right)^2} Var(β^j∣X)=Var⎝⎜⎜⎛βj+i=1∑nr^ij2i=1∑nr^ijui∣∣∣∣∣∣∣∣X⎠⎟⎟⎞=(i=1∑nr^ij2)2i=1∑nr^ij2⋅Var(ui∣X)
由于违背了同方差假设, V a r ( β ^ i ∣ X ) {\rm Var}\left(\hat\beta_i|\boldsymbol{X}\right) Var(β^i∣X) 是一个很复杂的形式,无法得到准确的 OLS 估计量的方差。在这种情况下,原本用来计算 t t t 统计量的分子也不再服从标准正态分布,使得 t t t 检验失效。
异方差的检验方法
一般地,通过数理统计的方法检验异方差性,基本思路都是设原假设为不存在异方差性:
H 0 : E ( u 2 ∣ x 1 , x 2 , . . . , x k ) = σ 2 . H_0:{\rm E}(u^2|x_1,x_2,...,x_k)=\sigma^2 \ . H0:E(u2∣x1,x2,...,xk)=σ2 .
这一点很容易理解,当我们构造检验统计量时,同方差原假设下的检验统计量往往具有良好的统计分布,便于进行假设检验。下面我们提出几种检验异方差的方法。
图示检验法
- 做 Y Y Y 对 X X X 的散点图:方差描述的是随机变量的取值相对于其均值的离散程度。因为被解释变量 Y Y Y 与随机误差项 u u u 有相同的方差,所以利用分析 Y Y Y 与 X X X 的相关图形,可以初略地看到 Y Y Y 的离散程度与 X X X 之间是否有相关关系。如果随着 X X X 的增加, Y Y Y 的离散程度为逐渐增大(或减小)的变化趋势,则认为存在递增型(或递减型)的异方差现象。
- 做残差 e i 2 e_i^2 ei2 对 X X X 的散点图:适用于一元回归模型,
- 如果 e i 2 e_i^2 ei2 的离散程度不随 X i X_i Xi 变化,则表明不存在异方差;
- 如果 e i 2 e_i^2 ei2 的离散程度随 X i X_i Xi 变化,则表明存在异方差。
Breusch-Pagan 检验
B-P 检验是一种较为常见的异方差的检验方法。检验是否存在异方差,即检验随机误差项的方差是否与模型的解释变量相关。比较常见的就是和解释变量的一次项具有某种线性关系。
假设需要检验的模型为:
Y i = β 0 + β 1 X i 1 + β 2 X i 2 + ⋯ + β k X i k + u i , Y_i=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\cdots+\beta_kX_{ik}+u_i \ , Yi=β0+β1Xi1+β2Xi2+⋯+βkXik+ui ,
B-P 检验的步骤如下:
将 Y Y Y 对 X 1 , X 2 , ⋯ , X k X_1,X_2,\cdots,X_k X1,X2,⋯,Xk 回归,得到估计值并计算拟合值 Y ^ \hat{Y} Y^ 和残差 e i e_i ei :
Y ^ i = β ^ 0 + β ^ 1 X i 1 + β ^ 2 X i 2 + ⋯ + β ^ k X i k , \hat{Y}_i=\hat\beta_0+\hat\beta_1X_{i1}+\hat\beta_2X_{i2}+\cdots+\hat\beta_kX_{ik} \ , Y^i=β^0+β^1Xi1+β^2Xi2+⋯+β^kXik ,
e i = Y i − Y ^ i . e_i=Y_i-\hat{Y}_i \ . ei=Yi−Y^i .
将 OLS 估计后的 e i 2 e_i^2 ei2 对解释变量的一次项做辅助回归,得到估计值和可决系数 R e 2 2 R_{e^2}^2 Re22 。
e i 2 = δ 0 + δ 1 X i 1 + δ 2 X i 2 + . . . + δ k X i k + ε i , e_i^2=\delta_0+\delta_1X_{i1}+\delta_2X_{i2}+...+\delta_kX_{ik}+\varepsilon_i \ , ei2=δ0+δ1Xi1+δ2Xi2+...+δkXik+εi ,
检验联合假设 H 0 : δ 1 = δ 2 = . . . = δ k = 0 H_0:\delta_1=\delta_2=...=\delta_k=0 H0:δ1=δ2=...=δk=0 ,可通过在约束条件下的受约束回归检验或拉格朗日乘数检验进行:
计算 F F F 统计量,检验 p p p 值:
F = R e 2 2 / k ( 1 − R e 2 2 ) / ( n − k − 1 ) ∼ F ( k , n − k − 1 ) , F=\frac{R_{e^2}^2/k}{(1-R_{e^2}^2)/(n-k-1)} \sim F(k,\,n-k-1) \ , F=(1−Re22)/(n−k−1)Re22/k∼F(k,n−k−1) ,
计算 L M LM LM 统计量,检验 p p p 值:
L M = n ⋅ R e 2 2 ∼ χ 2 ( k ) . LM = n\cdot R_{e^2}^2 \sim \chi^2(k) \ . LM=n⋅Re22∼χ2(k) .
White 检验
White 检验可以看成 B-P 检验的一种拓展,不需要关于异方差的任何先验信息,只需要在大样本的情况下,将 OLS 估计后的残差平方 e i 2 e_i^2 ei2 对常数、解释变量、解释变量的平方项及其交叉项等所构成一个辅助回归,利用辅助回归建立相应的检验统计量来判断异方差性。 不仅能够检验异方差的存在性,同时在多变量的情况下,还能判断出是哪一个变量的何种函数形式引起的异方差。
我们以三元回归模型为例,设需要检验的模型为:
Y i = β 0 + β 1 X i 1 + β 2 X i 2 + β 3 X i 3 + u i , Y_i=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\beta_3X_{i3}+u_i \ , Yi=β0+β1Xi1+β2Xi2+β3Xi3+ui ,
将 Y Y Y 对 X 1 , X 2 , X 3 X_1,X_2,X_3 X1,X2,X3 回归,得到估计值并计算拟合值 Y ^ \hat{Y} Y^ 和残差 e i e_i ei 后,建立辅助回归模型:
e 2 = δ 0 + δ 1 X 1 + δ 2 X 2 + δ 3 X 3 + δ 4 X 1 2 + δ 5 X 2 2 + δ 6 X 3 2 + δ 7 X 1 X 2 + δ 8 X 1 X 3 + δ 9 X 2 X 3 + ε i . \begin{aligned} e^2=&\delta_0+\delta_1X_{1}+\delta_2X_{2}+\delta_3X_{3}\\ &+\delta_4X_{1}^2+\delta_5X_{2}^2+\delta_6X_{3}^2\\ &+\delta_7X_{1}X_{2}+\delta_8X_{1}X_{3}+\delta_9X_{2}X_{3}+\varepsilon_i \ . \end{aligned} e2=δ0+δ1X1+δ2X2+δ3X3+δ4X12+δ5X22+δ6X32+δ7X1X2+δ8X1X3+δ9X2X3+εi .
检验联合假设 H 0 : δ 1 = δ 2 = . . . = δ 9 = 0 H_0:\delta_1=\delta_2=...=\delta_9=0 H0:δ1=δ2=...=δ9=0 ,
计算 F F F 统计量,检验 p p p 值:
F = R e 2 2 / h ( 1 − R e 2 2 ) / ( n − h − 1 ) ∼ F ( h , n − h − 1 ) , F=\frac{R_{e^2}^2/h}{(1-R_{e^2}^2)/(n-h-1)} \sim F(h,\,n-h-1) \ , F=(1−Re22)/(n−h−1)Re22/h∼F(h,n−h−1) ,
计算 L M LM LM 统计量,检验 p p p 值:
L M = n ⋅ R e 2 2 ∼ χ 2 ( h ) LM = n\cdot R_{e^2}^2 \sim \chi^2(h) LM=n⋅Re22∼χ2(h)
其中 n n n 为样本容量, h h h 为辅助回归的解释变量个数(在三元回归模型中, h = 9 h=9 h=9)。
简化的 White 检验
我们在做 White 检验的时候需要跑一个很长的回归,且随着解释变量的增多,自由度的损失严重,因此 While 检验可以做以下简化:
e i 2 = δ 0 + δ 1 Y ^ i + δ 2 Y ^ i 2 + ε i e_i^2=\delta_0+\delta_1\hat{Y}_i+\delta_2\hat{Y}_i^2+\varepsilon_i ei2=δ0+δ1Y^i+δ2Y^i2+εi
将用拟合值及其多项式代替所有的解释变量,并检验联合假设 H 0 : δ 1 = δ 2 = 0 H_0:\delta_1=\delta_2=0 H0:δ1=δ2=0 ,同理可用 F F F 统计量和 L M LM LM 统计量进行假设检验。这样可以大大减少辅助回归的长度和自由度的损失。
Park 检验和 Glejser 检验
这两种检验的方式类似:由 OLS 法得到残差,分别取平方、绝对值以及绝对值的对数,然后将这些新的变量分别对某些解释变量回归,根据回归模型的显著性和拟合优度来判断是否存在异方差。
不仅能对异方差的存在进行判断,而且还能对异方差随某个解释变量变化的函数形式进行诊断。一旦发现异方差,即知道其形式。但缺点是计算量较大,且该检验要求变量的观测值为大样本。
Park 检验:
e i 2 = f ( X i j ) + ε i e_i^2=f(X_{ij})+\varepsilon_i ei2=f(Xij)+εi
Glejser 检验:
∣ e i ∣ = f ( X i j ) + ε i |e_i|=f(X_{ij})+\varepsilon_i ∣ei∣=f(Xij)+εi
ln ∣ e i ∣ = f ( X i j ) + ε i \ln|e_i|=f(X_{ij})+\varepsilon_i ln∣ei∣=f(Xij)+εi
这里的 e i e_i ei 仍然是原始回归模型的残差,函数 f ( ⋅ ) f(\cdot) f(⋅) 是部分解释变量 X X X 的某种最佳函数形式。检验方式仍然是 F F F 检验和 L M LM LM 检验。
Goldfeld-Quanadt 检验
该检验的基本思想为:将样本分为两部分,然后分别对两个样本进行回归,并计算两个子样的残差平方和所构成的比值,以此为统计量来判断是否存在异方差。但这一检验需要满足两个前提条件:
- 要求变量的观测值为大样本;
- 除了同方差假定不成立外,其它假定均满足。
检验的具体做法如下:
- 排序:假设随机扰动项的方差与某个解释变量正相关,把全部观测值按照此解释变量的取值从小到大排序。
- 数据分组:将排列在中间的约 1 / 4 1/4 1/4 的观察值删除掉,记为 c c c ,再将剩余的分为两个部分,每部分观察值的个数为 ( n − c ) / 2 (n-c)/2 (n−c)/2 。
- 分别 OLS 回归:用两个子样本分别估计回归直线,并计算残差平方和。分别用 n 2 n_2 n2 和 n 1 n_1 n1 表示两组样本,用 S S R 2 = ∑ i = 1 n 2 e 2 i 2 {\rm SSR}_2=\sum\limits_{i=1}^{n_2}e_{2i}^2 SSR2=i=1∑n2e2i2 和 S S R 1 = ∑ i = 1 n 1 e 1 i 2 {\rm SSR}_1=\sum\limits_{i=1}^{n_1}e_{1i}^2 SSR1=i=1∑n1e1i2 表示两组样本的残差平方和。这里的 n 2 = n 1 = ( n − c ) / 2 n_2=n_1=(n-c)/2 n2=n1=(n−c)/2 。
- 构造 F F F 统计量:在同方差假设下,两组样本方差应该相等,因此提出原假设 H 0 : σ 1 2 = σ 2 2 H_0:\sigma_1^2=\sigma_2^2 H0:σ12=σ22 ,并进行 F F F 检验:
F = S S R 2 / ( n 2 − k − 1 ) S S R 1 / ( n 1 − k − 1 ) = S S R 2 S S R 1 ∼ F ( n 2 − k − 1 , n 1 − k − 1 ) . F=\frac{ {\rm SSR}_2/(n_2-k-1)}{ {\rm SSR}_1/(n_1-k-1)}=\frac{ {\rm SSR}_2}{ {\rm SSR}_1}\sim F(n_2-k-1,\,n_1-k-1) \ . F=SSR1/(n1−k−1)SSR2/(n2−k−1)=SSR1SSR2∼F(n2−k−1,n1−k−1) .
该检验的缺点在于检验结果与选择数据删除的个数 c c c 的大小有关,且只能判断异方差是否存在。
异方差的修正措施
异方差稳健的标准误法
这里是我们第一次提出稳健的标准误的概念,事实上稳健的标准误有很多种,这里指的是 White 提出的针对异方差的情况采用的稳健的标准误。主要思想是:仍采用 OLS 估计量,但修正其方差。
原理是当我们修正了 OLS 估计量的方差时,在大样本条件下有:
t = β ^ j − β j r o b u s t _ s e ( β ^ j ) ∼ a N ( 0 , 1 ) , t=\frac{\hat\beta_j-\beta_j}{ {\rm robust\_se}(\hat\beta_j)}\overset{a}\sim \, N(0,\,1) \ , t=robust_se(β^j)β^j−βj∼aN(0,1) ,
这里 ∼ a \displaystyle\overset{a}\sim ∼a 表示渐进服从,此时我们可以构造出合理的 t t t 统计量。这里说明一下, t t t 分布在自由度很大的时候可以近似看作标准正态分布。
那么如何来构造稳健的标准误呢?White 提出用 OLS 估计的残差的平方 e i 2 e_i^2 ei2 作为相应 σ i 2 \sigma^2_i σi2 的代表。具体操作如下:
在计算一元回归模型的时候, β ^ 1 \hat\beta_1 β^1 的方差可以有如下的计算公式:
V a r ( β ^ 1 ) = ∑ i = 1 n ( X i − X ˉ ) 2 σ i 2 ( ∑ i = 1 n ( X i − X ˉ ) 2 ) 2 . {\rm Var}(\hat\beta_1)=\frac{\sum\limits_{i=1}^n\left(X_i-\bar{X}\right)^2\sigma_i^2}{\left(\sum\limits_{i=1}^n\left(X_i-\bar{X}\right)^2\right)^2} \ . Var(β^1)=(i=1∑n(Xi−Xˉ)2)2i=1∑n(Xi−Xˉ)2σi2 .
在同方差假定下, σ i 2 = σ 2 \sigma_i^2=\sigma^2 σi2=σ2 ,我们可以用 σ ^ 2 \hat\sigma^2 σ^2 代替 σ 2 \sigma^2 σ2 计算标准误。当出现异方差的情况下,我们用用 e i 2 e_i^2 ei2 作为 σ i 2 \sigma_i^2 σi2 的估计计算的到稳健的方差:
r o b u s t _ V a r ^ ( β ^ 1 ) = ∑ i = 1 n ( X i − X ˉ ) 2 e i 2 ( ∑ i = 1 n ( X i − X ˉ ) 2 ) 2 . {\rm robust}\_\widehat{\rm Var}(\hat\beta_1)=\frac{\sum\limits_{i=1}^n\left(X_i-\bar{X}\right)^2e_i^2}{\left(\sum\limits_{i=1}^n\left(X_i-\bar{X}\right)^2\right)^2} \ . robust_Var (β^1)=(i=1∑n(Xi−Xˉ)2)2i=1∑n(Xi−Xˉ)2ei2 .
进而开方得到即可得到稳健的标准误。多元回归模型中,我们可以使用排除其他变量影响的方法计算 OLS 估计量的方差,利用同样的处理方式也可以得到稳健的标准误。
一般地,在小样本下需要检验是否存在异方差性,在大样本下直接汇报稳健的标准误。
加权最小二乘法 WLS / 广义最小二乘法 GLS
笔记的开篇我们假设了出现异方差情况时,随机干扰项的方差-协方差矩阵的结构:
V a r ( u ∣ X ) = σ 2 [ ω 1 ω 2 ⋱ ω n ] = σ 2 Ω . {\rm Var}(\boldsymbol{u}|\boldsymbol{X}) = \sigma^2 \left[ \begin{array}{cccc} \omega_1 & & & \\ & \omega_2 & & \\ & & \ddots & \\ & & & \omega_n \\ \end{array} \right] = \sigma^2\boldsymbol\Omega \ . Var(u∣X)=σ2⎣⎢⎢⎡ω1ω2⋱ωn⎦⎥⎥⎤=σ2Ω .
若 Ω \boldsymbol\Omega Ω 已知,我们可以对原模型进行变换,使之变成一个新的不存在异方差的模型,然后采用 OLS 估计其参数,变化过程如下:
W = Ω − 1 = [ 1 ω 1 1 ω 2 ⋱ 1 ω n ] = [ 1 ω 1 1 ω 2 ⋱ 1 ω n ] 2 = P T P , \boldsymbol W = \boldsymbol\Omega^{-1} = \left[ \begin{array}{cccc} \dfrac{1}{\omega_1} & & & \\ & \dfrac{1}{\omega_2} & & \\ & & \ddots & \\ & & & \dfrac{1}{\omega_n} \\ \end{array} \right] = \left[ \begin{array}{cccc} \dfrac{1}{\sqrt{\omega_1}} & & & \\ & \dfrac{1}{\sqrt{\omega_2}} & & \\ & & \ddots & \\ & & & \dfrac{1}{\sqrt{\omega_n}} \\ \end{array} \right]^2= \boldsymbol{P}^{\rm T}\boldsymbol{P} \ , W=Ω−1=⎣⎢⎢⎢⎢⎢⎢⎡ω11ω21⋱ωn1⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡ω11ω21⋱ωn1⎦⎥⎥⎥⎥⎥⎥⎥⎤2=PTP ,
其中 W \boldsymbol W W 是 Ω \boldsymbol{\Omega} Ω 的逆矩阵,是一个对称正定矩阵,因此存在一可逆矩阵 P \boldsymbol P P 使得 W = P T P \boldsymbol{W} = \boldsymbol{P}^{\rm T}\boldsymbol{P} W=PTP。利用该可逆矩阵 P \boldsymbol{P} P 将模型变换为:
P Y = P X β + P μ ⟶ Y ∗ = X ∗ β + μ ∗ \boldsymbol{PY} = \boldsymbol{PX\beta} + \boldsymbol{P}\boldsymbol\mu \ \ \ \ \boldsymbol\longrightarrow \ \ \ \ \boldsymbol{Y}^{*} = \boldsymbol{X}^{*}\boldsymbol\beta + \boldsymbol{\mu}^{*} PY=PXβ+Pμ ⟶ Y∗=X∗β+μ∗
用 OLS 估计新模型
β ~ = ( X ∗ T X ∗ ) − 1 X ∗ T Y ∗ = ( X T P T P X ) − 1 X T P T P Y = ( X T W X ) − 1 X T W Y . \tilde{\boldsymbol\beta} = ({\boldsymbol{X}^{*}}^{\rm T}{\boldsymbol{X}^{*}})^{-1}{\boldsymbol{X}^{*}}^{\rm T}\boldsymbol{Y}^{*}=(\boldsymbol{X}^{\rm T}\boldsymbol{P}^{\rm T}\boldsymbol{P\boldsymbol{X}})^{-1}\boldsymbol{X}^{\rm T}\boldsymbol{P}^{\rm T}\boldsymbol{P}\boldsymbol{Y}=(\boldsymbol{X}^{\rm T}\boldsymbol{W}\boldsymbol{X})^{-1}\boldsymbol{X}^{\rm T}\boldsymbol{W}\boldsymbol{Y} \ . β~=(X∗TX∗)−1X∗TY∗=(XTPTPX)−1XTPTPY=(XTWX)−1XTWY .
这就是原模型的 WLS 估计量, 是无偏且有效的估计量。
可行的广义最小二乘法 FGLS
若 Ω \boldsymbol\Omega Ω 未知,需要先估计 σ i 2 \sigma^2_i σi2 ,然后利用 σ i 2 \sigma^2_i σi2 的估计值 σ ^ i 2 \hat\sigma^2_i σ^i2 建立加权的新模型,再用 OLS 估计新模型。假设部分解释变量造成异方差,记为 Z 1 , Z 2 , ⋯ , Z p Z_1, Z_2,\cdots,Z_p Z1,Z2,⋯,Zp ,我们一般设定如下可能的计量模型:
σ i 2 = α 0 + α 1 Z i 1 + α 2 Z i 2 + . . . + α p Z i p + ν i , \sigma_i^2=\alpha_0+\alpha_1Z_{i1}+\alpha_2Z_{i2}+...+\alpha_pZ_{ip}+\nu_i \ , σi2=α0+α1Zi1+α2Zi2+...+αpZip+νi ,
σ i = α 0 + α 1 Z i 1 + α 2 Z i 2 + . . . + α p Z i p + ν i , \sigma_i=\alpha_0+\alpha_1Z_{i1}+\alpha_2Z_{i2}+...+\alpha_pZ_{ip}+\nu_i \ , σi=α0+α1Zi1+α2Zi2+...+αpZip+νi ,
ln σ i 2 = α 0 + α 1 Z i 1 + α 2 Z i 2 + . . . + α p Z i p + ν i , ( 常 见 ) \ln\sigma_i^2=\alpha_0+\alpha_1Z_{i1}+\alpha_2Z_{i2}+...+\alpha_pZ_{ip}+\nu_i \ , \ \ \ \ (常见) lnσi2=α0+α1Zi1+α2Zi2+...+αpZip+νi , (常见)
用回归的残差 e i e_i ei 代替 σ i \sigma_i σi 进行上述 OLS 估计,获得估计残参数并计算出拟合值,将 e i 2 e_i^2 ei2 的拟合值 e ^ i 2 \hat{e}_i^2 e^i2 作为 σ i 2 \sigma_i^2 σi2 的估计值 σ ^ i 2 \hat\sigma_i^2 σ^i2 :
σ ^ i 2 = α ^ 0 + α ^ 1 Z i 1 + α ^ 2 Z i 2 + . . . + α ^ p Z i p , \hat{\sigma}_i^2=\hat{\alpha}_0+\hat{\alpha}_1Z_{i1}+\hat{\alpha}_2Z_{i2}+...+\hat{\alpha}_pZ_{ip} \ , σ^i2=α^0+α^1Zi1+α^2Zi2+...+α^pZip ,
σ ^ i 2 = ( α ^ 0 + α ^ 1 Z i 1 + α ^ 2 Z i 2 + . . . + α ^ p Z i p ) 2 , \hat{\sigma}_i^2=\left(\hat{\alpha}_0+\hat{\alpha}_1Z_{i1}+\hat{\alpha}_2Z_{i2}+...+\hat{\alpha}_pZ_{ip}\right)^2 \ , σ^i2=(α^0+α^1Zi1+α^2Zi2+...+α^pZip)2 ,
σ ^ i 2 = exp ( α ^ 0 + α ^ 1 Z i 1 + α ^ 2 Z i 2 + . . . + α ^ p Z i p ) , \hat{\sigma}_i^2=\exp\left(\hat{\alpha}_0+\hat{\alpha}_1Z_{i1}+\hat{\alpha}_2Z_{i2}+...+\hat{\alpha}_pZ_{ip}\right) \ , σ^i2=exp(α^0+α^1Zi1+α^2Zi2+...+α^pZip) ,
之后便可以利用 WLS 估计原模型的系数:
Y i σ ^ i = β 0 1 σ ^ i + β 1 X i 1 σ ^ i + β 2 X i 2 σ ^ i + . . . + β k X i k σ ^ i + u i . \frac{Y_i}{\hat{\sigma}_i}=\beta_0\frac{1}{\hat{\sigma}_i}+\beta_1\frac{X_{i1}}{\hat{\sigma}_i}+\beta_2\frac{X_{i2}}{\hat{\sigma}_i}+...+\beta_k\frac{X_{ik}}{\hat{\sigma}_i}+u_i \ . σ^iYi=β0σ^i1+β1σ^iXi1+β2σ^iXi2+...+βkσ^iXik+ui .